
作者:fate0
作者博客:http://blog.fatezero.org/2018/04/15/web-scanner-crawler-03/
相關閱讀:
《爬蟲基礎篇[Web 漏洞掃描器]》
《爬蟲 JavaScript 篇[Web 漏洞掃描器]》
《漏洞掃描技巧篇 [Web 漏洞掃描器]》
0x00 前言
上一篇主要如何通過向瀏覽器頁面注入 JavaScript 代碼來盡可能地獲取頁面上的鏈接信息,最后完成一個穩定可靠的單頁面鏈接信息抓取組件。這一篇我們跳到一個更大的世界,看一下整個漏掃爬蟲的運轉流程,這一篇會著重描寫爬蟲架構設計以及調度部分。
0x01 設計
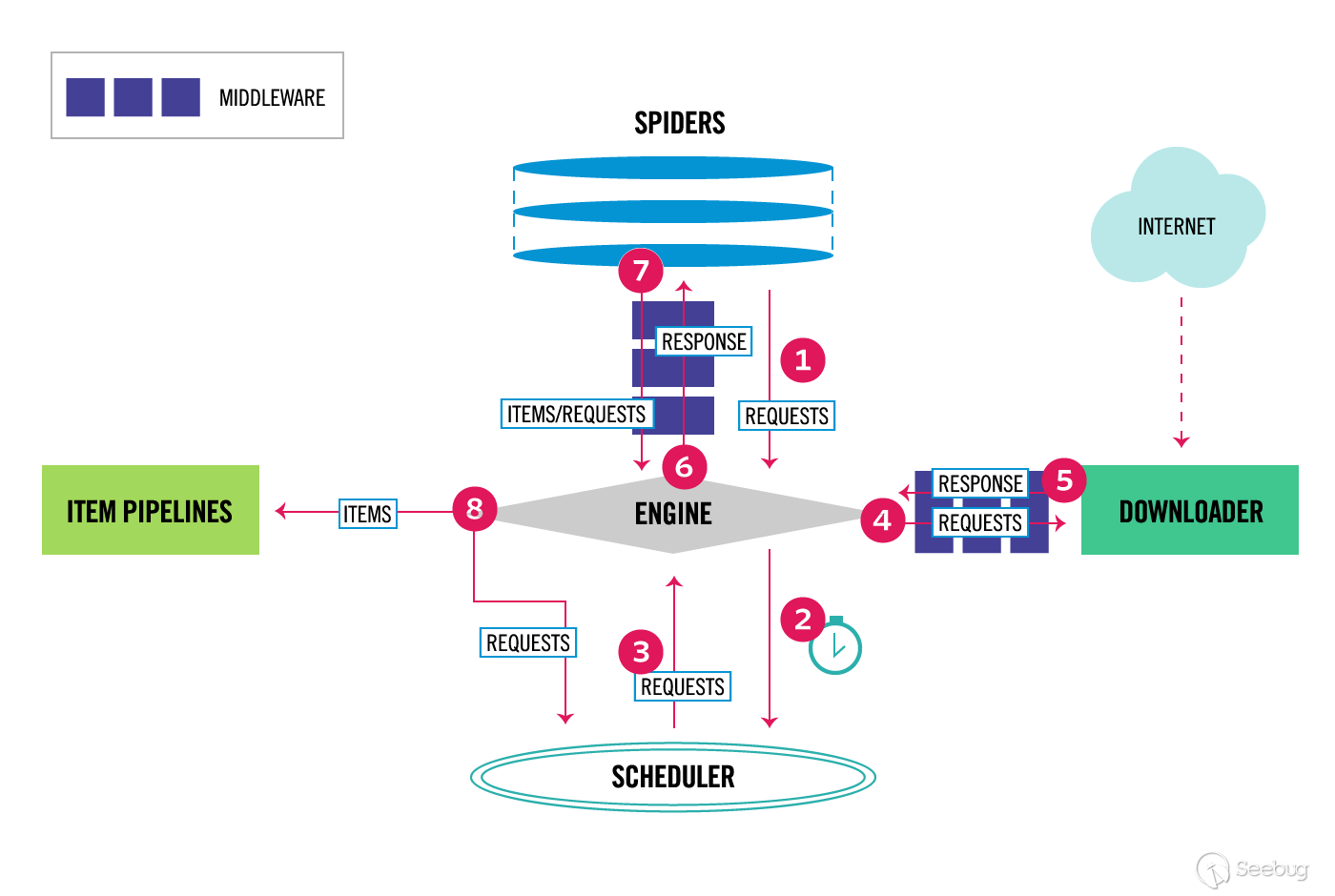
這張圖片是不是很熟悉,其實這就是 Scrapy 的架構設計圖,我們簡單看一下這張圖的流程:
Engine拿到RequestsEngine將Requests丟到Scheduler中,并向Scheduler請求下一個準備抓取的RequestScheduler返回下一個準備抓取的RequestEngine將Request丟到Downloader中,中途經過Downloader Middlewares處理Downloader處理Request產生Response返回給Engine,中途經過Downloader Middlewares處理Engine將Response丟到Spider中,中途經過Spider Middleware處理Spider處理Response產生出item和新的Requests返回給Engine,中途經過Spider Middleware處理Engine將item丟到Item Pipelines處理,同時將Requests丟到Scheduler中- 重復 1-8 步驟,直到
Scheduler沒有新的Requests
在整體架構上我直接參考了 Scrapy 的設計,只不過我實在受不了 Twisted 那種扭曲的寫法, 所以直接換了個網絡庫重新造了個和 Scrapy 差不多的輪子,新的架構圖如下:
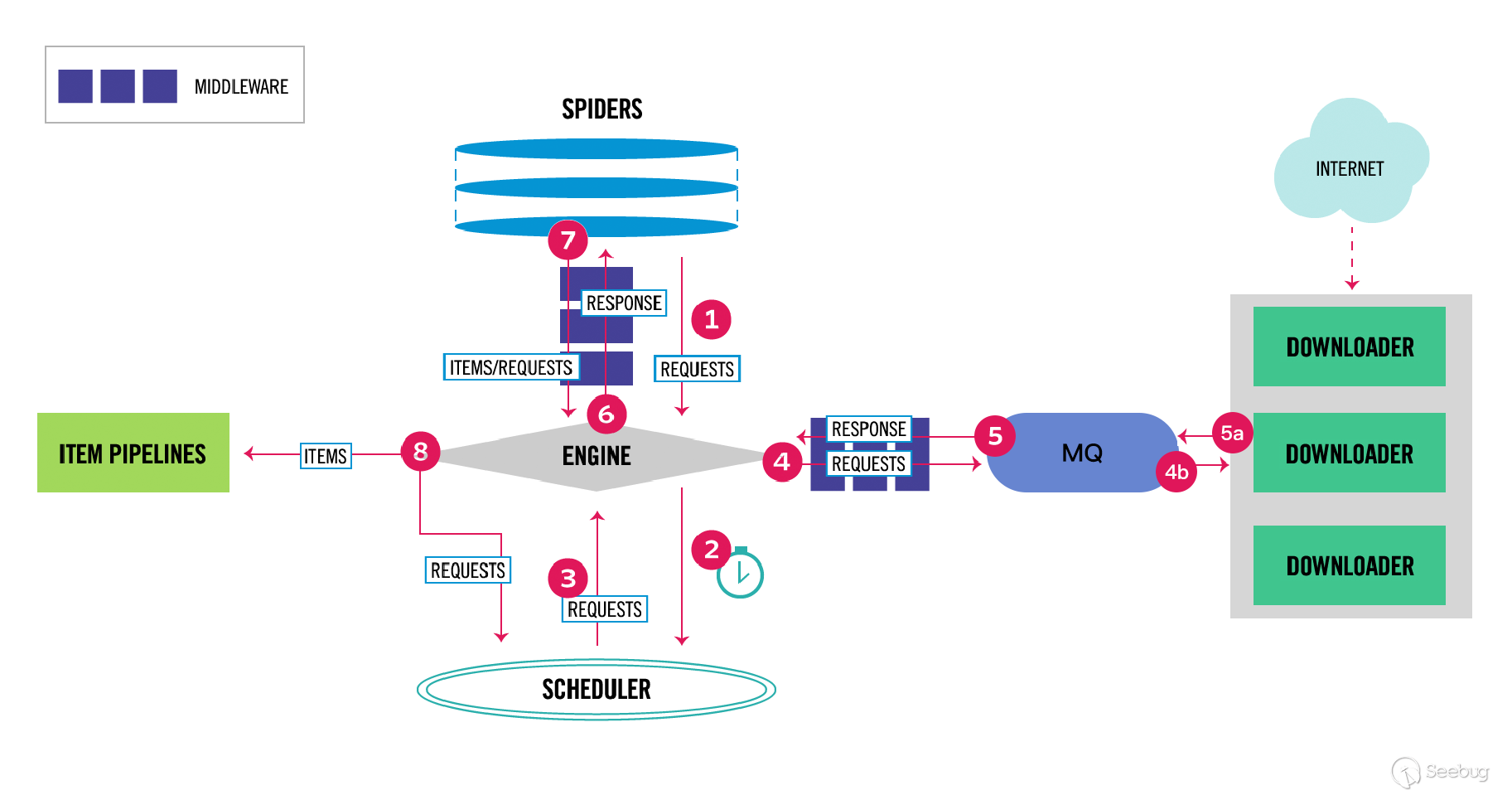
上面架構圖中消息隊列(MQ)左邊的內部名為 CasterPy,右邊的內部名為 CasterJS, 我們前兩篇主要介紹的單頁面鏈接信息抓取組件(CasterJS)就是上面的架構設計中的 Downloader, 我們的架構設計和 Scrapy 的區別是:
- 我們的
Downloader直接返回鏈接信息而不是返回響應內容 - 我們的
Downloader是分布式的,可部署在不同的服務器上 - 我們的
Engine通過消息隊列與Downloader通信 - 我們的
Downloader針對同一個站點并發數始終為 1 - 我們的
CasterPy使用協程同時處理多個站點,可同時和多個Downloader進行通信
我們的 Spider 組件也只是簡單的解析鏈接信息返回相對應的 item 和新的 Request,這部分沒什么好講的, 我們的 Engine 組件和 Scrapy 的也差不多,就是 Item、Request、Response 的搬運工,這部分也不用細講, 至于 Item Pipelines,最后數據怎么存儲、存儲到哪里去,每家公司都有自己的想法(每家公司的想法差距都挺大的),這個就仁者見仁, 剩下就只有 Scheduler 了。
0x02 調度
Scheduler 決定了 Request 的優先級、去留,漏掃爬蟲的 Scheduler 和普通爬蟲的 Scheduler 最大的區別是如何決定 Request 的去留,也就是爬蟲的去重問題。
去重真的是我在寫漏掃爬蟲除了 QtWebkit 之外最頭疼的事情了。針對漏掃爬蟲的去重,完全就沒有什么比較好的公開的策略去處理, 老生常談的 Bloom Filter 在漏掃爬蟲中毫無用武之地。
普通爬蟲一般來說只會丟棄非目標、已爬取的 Request,但在漏掃爬蟲中完全不能只做這些, 因為這樣不僅會浪費爬蟲的資源,也會浪費后續檢測的資源,所以我們需要自己造一個去重策略對 Request 進行更深層次的去重。
資源去重
我們在使用 Chromium 加載一個頁面的時候,Chromium 會對網絡資源做分類,這些分類主要有:

我們在之前注入的 JavaScript 代碼在獲取鏈接信息的時候也采取了這樣的分類(雖然我之前沒講=。=),那很明顯,我們只需要對 Doc 類型的 Request 進行再入 download 隊列,其他資源都沒必要再使用瀏覽器再下載渲染一遍。
鏈接去重
在最初的幾年前在頭疼去重這個問題的時候,劍心和我討論的結果是可以把 request 中的參數分為 action 類型和 data 類型:
action類型: 對代碼邏輯產生影響的參數data類型: 在代碼中作為數據使用,一般不會影響到代碼邏輯的參數
簡單的講,action 類型的參數就是語言 vm 中 opcode,data 類型就是語言 vm 中的操作數, 我們就是希望能夠從 request 數據中分析出哪些是 action 類型的參數,哪些是 data 類型的參數,然后再進行去重。
我們看個簡單的例子:
if ($_GET['a'] == 'create') {
mysql_query("INSERT INTO test VALUES ('$_GET['b']')", $conn);
}其中 a 就是屬于 action 類型的參數,因為 a 的值必須是 create 才會有數據庫操作的邏輯。 b 屬于 data 類型的參數,因為 b 的值無關緊要,不會影響到代碼執行邏輯。
從代碼中很容易分析出參數的類型,可是僅僅從 url 中怎么區別參數類型呢? 這個時候我們就需要從開發人員寫代碼的心理去推測參數類型了。
首先一般開發人員不會使用中文作為 action 類型參數的值,很難想象會有人這樣寫代碼:
if ($_GET['a'] == '創建') { /* do create stuff */}所以帶中文字符的參數,可以直接被認為是 data 類型的參數。
其次一般開發人員的不會使用超過 2 位的純數字作為 action 類型的值:
if ($_GET['a'] == '87') { /* do create stuff */ }
else if ($_GET['a'] == '9527') { /*do delete stuff */ }再次一般開發人員也不會使用 HASH/UUID 值作為 action 類型的值:
if ($_GET['a'] == 'f95df1d4d3c89392f1fd920787bb7303') {}
else if ($_GET['a'] == 'f95df1d4-d3c8-9392-f1fd-920787bb7303') {}還記得上一篇我們提到自動化填寫表單的時候,最好能夠自定義輸入的地方都填上帶 casterjs 字符嗎? 就是為了能夠在這里直接區分出帶 casterjs 值的參數都是 data 類型參數。
最后一般開發人員也不會使用 … (自由想象、發揮、總結規律)
其實我們這個過程就是在猜,猜測一個正常的開發人員的編碼規范。 前期通過各種猜測,我們可以對下面這些類型的 url 簡單去重:
http://fatezero.org/test?a=create&b=你好
http://fatezero.org/test?a=create&b=3721
http://fatezero.org/test?a=create&b=casterjs@gmail.com
http://fatezero.org/test?a=create&b=f95df1d4d3c89392f1fd920787bb7303因為上面的參數 b 被識別成 data 類型參數,所以理論上 b 的值被替換成什么都無所謂, 我們將 data 類型參數的值替換成 { { data }} 得到 “臨時規則”:
http://fatezero.org/test?a=create&b={{data}}上面這些去重步驟僅僅是第一步,接下來我們還要考慮下面這種情況:
http://fatezero.org/test?a=create&b=halo
http://fatezero.org/test?a=create&b=hello
http://fatezero.org/test?a=create&b=你好
http://fatezero.org/test?a=create&b=3721
http://fatezero.org/test?a=create&b=casterjs@gmail.com
http://fatezero.org/test?a=create&b=f95df1d4d3c89392f1fd920787bb7303
...通過第一步簡單替換之后,得到 “臨時規則”:
1. http://fatezero.org/test?a=create&b=halo
2. http://fatezero.org/test?a=create&b=hello
3. http://fatezero.org/test?a=create&b={{data}}
...這樣的結果我們并不是特別滿意,但通過第一步簡單替換也只能得到這樣的結果了。但隨著第三條 “臨時規則” 命中的 url 越來越多, 我們就越有理由相信參數 b 就是 data 類型的參數,參數 a 就是 action 類型的參數, 所以剛剛得到的 “臨時規則” 在命中次數達到我們所設定的一個閾值后,還可以變成 “最后規則” :
http://fatezero.org/test?a=create&b={%data%}上面這條就是去重過程中生成的去重 “最后規則”,根據這條 “最后規則” 我們又可以直接對下面的鏈接直接去重:
http://fatezero.org/test?a=create&b=nihao
http://fatezero.org/test?a=create&b=world
http://fatezero.org/test?a=create&b=create“臨時規則” 只有統計的作用,并不能參與去重復步驟,但是 “最后規則” 可以參與去重。就如同剛才所示,”臨時規則” 可以發展成 “最后規則”。 在 Scheduler 去重中,我們最希望拿到的并不是 url,而是實時在變化的去重規則,通過越來越多的 url 生成越來越精準的去重規則, 再通過越來越精準的規則反過來再對以后以及之前的 url 進行去重,得到重復度越來越低的 url,這就是我們造的去重策略。
URL Rewrite 去重
前面我們根據猜測開發人員心理去制定去重策略,這里我們還需要繼續猜測 URL Rewrite 配置人員的心理去完善我們的去重策略。
我們先看一下幾種常規的 URL Rewrite 之后 url 的樣子:
http://fatezero.org/view/123.html
http://fatezero.org/view-123.html
http://fatezero.org/view_123.html
...我們先假設上面的 view 就是我們所說的 action 類型參數,123 就是 data 類型參數, 針對 URL Rewrite 之后的 url,我們首先應該找到各個參數之間的間隔符號是什么,上面的例子中參數間隔符號分別是 /、-、_, 然后以根路徑開始,用 1、2、3 順序作為 key,對應 path 深度的值作為 value,最終還是可以直接轉換成 key-value 格式:
http://fatezero.org/?1=view&2=123最后還是通過之前的去重策略進行去重,發現了么,漏掃去重這塊大多數時候都只能猜測,并沒有一個萬能的解決方法。
0x03 測試
經過簡單的測試,在 2 核 4G 內存服務器上能同時跑 50 個 Chromium Tab, 在 4 核 8G 內存服務器上一個 CasterPy 能夠同時跑 1000 個任務, 也就是說一臺 CasterPy 服務器可以和 20 臺 CasterJS 服務器構成一個小規模的爬蟲。 如果任務并發數增加,那也得相對應增加 CasterPy 服務器的資源以及 CasterJS 服務器的數量了。
0x04 總結
至此,掃描器中爬蟲部分就算簡單地過了一遍,雖然講得比較粗略,但不管怎么樣也得切到下一個話題了。
下一篇我們講一下 Web 漏洞掃描器中漏洞檢測技巧部分。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/730/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/730/
暫無評論