
作者:fate0
來源:小米安全中心
相關閱讀:
《爬蟲基礎篇[Web 漏洞掃描器]》
《爬蟲調度篇[Web 漏洞掃描器]》
《漏洞掃描技巧篇 [Web 漏洞掃描器]》
0x00 前言
上一篇主要講了如何通過修改 Chromium 代碼為 Web 漏洞掃描器的爬蟲打造一個穩定可靠的 headless 瀏覽器。這篇我們從瀏覽器底層走到上層,從 C++ 切換到 JavaScript,講一下如何通過向瀏覽器頁面注入 JavaScript 代碼來盡可能地獲取頁面上的鏈接信息。
0x01 注入 JavaScript 的時間點
首先我們要解決的第一個問題是:在什么時間點向瀏覽器頁面注入 JavaScript 代碼?
答案非常簡單, 在頁面加載前,我們希望能夠注入一段 JavaScript 代碼以便于能夠 Hook、備份各種未被污染的函數, 在頁面加載后,我們希望能夠注入一段 JavaScript 代碼以便于能夠進行遍歷各個元素、觸發各種事件、獲取鏈接信息等操作。
那么下一個問題又來了:怎么定義頁面加載前、頁面加載后?
頁面加載前的定義非常簡單,只要能在用戶代碼執行前執行我們注入的 JavaScript 代碼即可,也就是在頁面創建之后、用戶代碼執行之前的時間段對于我們來說都算是頁面加載前,CDP 剛好提供了這么一個 API Page.addScriptToEvaluateOnNewDocument 能夠讓我們在頁面加載前注入 JavaScript 代碼。
接下來考慮一下該如何定義頁面加載后。最簡單的方法就是不管三七二一,每個頁面都加載 30s (即便是空白的頁面),隨后再注入我們的代碼,但很明顯這會浪費很多資源,我們需要根據每個頁面的復雜度來控制加載時間。可能會有同學說我們可以監聽 load 事件,等待頁面加載結束之后再注入代碼,那我們考慮一個比較常見的場景,在某個頁面上剛好有那么一兩個圖片字體資源加載速度特別慢,導致 load 遲遲未被觸發(甚至不觸發),但這些資源其實我們并不在乎,完全可以直接注入我們代碼,所以只等待 load 事件也并不是一個特別好的選擇。
我們先看一下加載一個頁面的過程,除了會觸發 load 事件之外還會觸發什么事件:
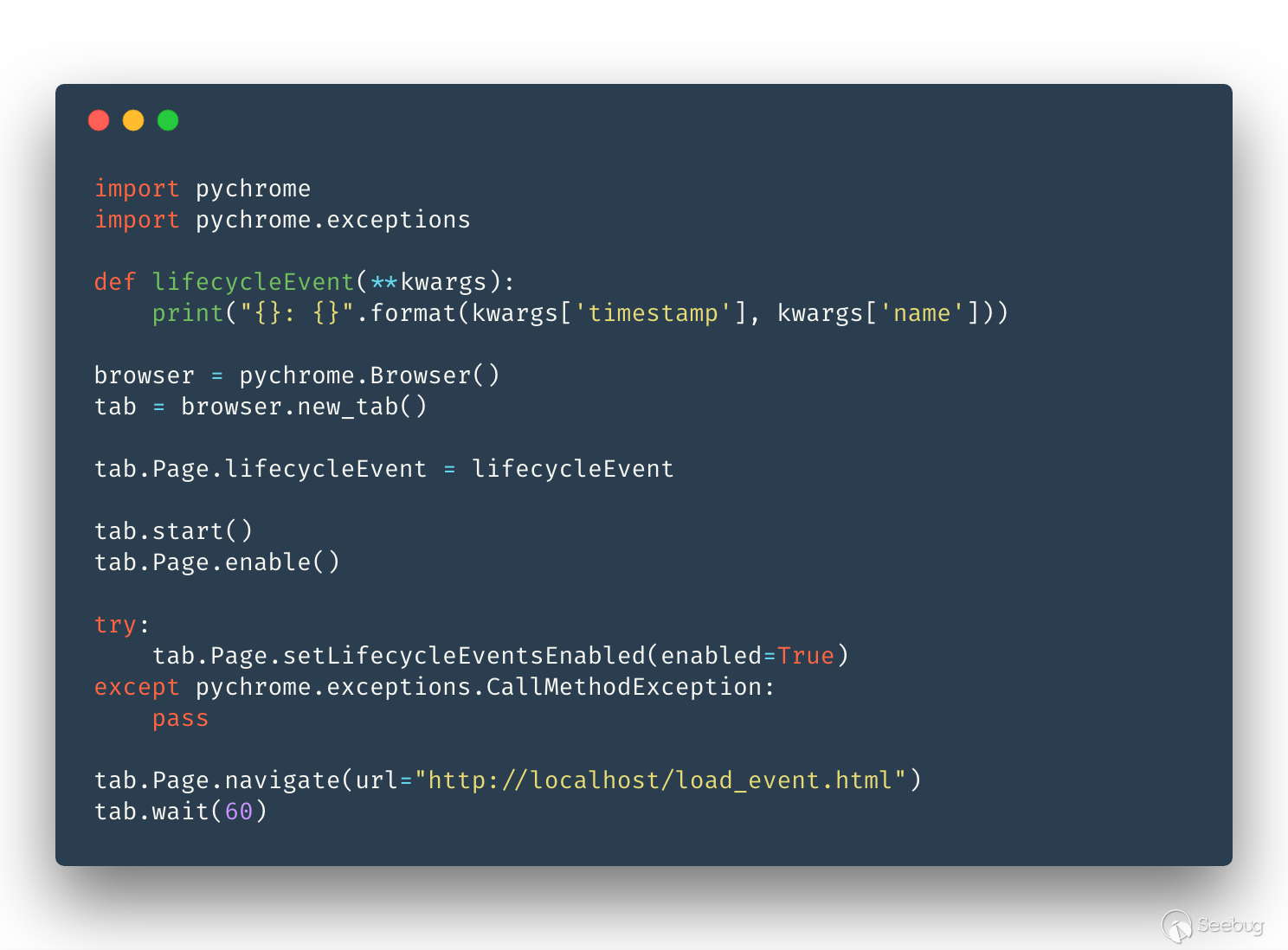
下面我們簡單地介紹一下上面幾個我們會用到的事件

之前解釋過 load 事件可能對我們來說太晚了,但是現在 DOMContentLoaded 事件對我們來說又太早了,因為用戶代碼也可能會綁定這個事件然后操作 DOM,我們肯定是希望能夠在頁面穩定之后再注入我們的代碼,所以在 load 和 DOMContentLoaded 之間某個時間點對我們來說比較合適,可惜并沒有這樣一個特別的事件存在,所以我個人覺得比較好的方案是將上面各個事件結合一起使用。
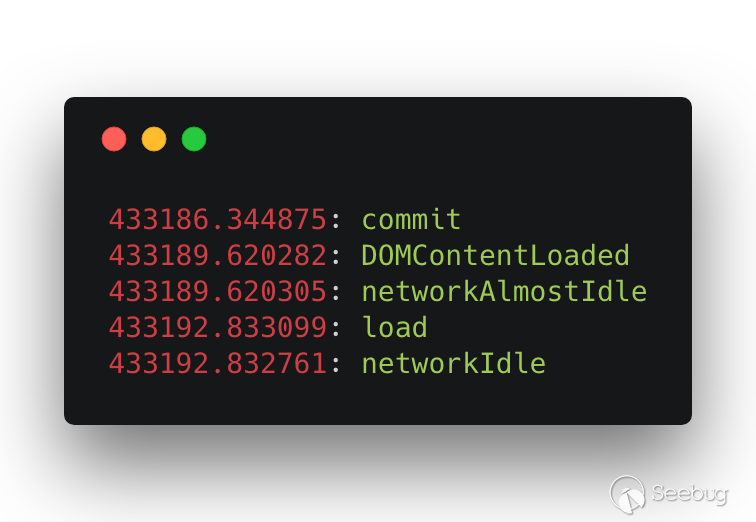
我們先說一下這幾個事件的觸發順序,首先這幾個事件觸發順序不一定,例如觸發時間 load 事件不一定比 DOMContentLoaded 晚,load 也不一定比 networkAlmostIdle 晚。唯一能確定的就是 networkAlmostIdle 一定比 networkIdle 晚。在一般的情況下時間順序是 DOMContentLoaded -> networkAlmostIdle -> networkIdle -> load。
所以一般的解決方案:
-
等待
load,同時設定等待超時時間,load超時直接注入代碼,同時等待DOMContentLoaded事件 -
DOMContentLoaded事件觸發,接著等待networkAlmostIdle,同時設定等待超時時間,超時直接注入代碼 -
networkAlmostIdle事件觸發,接著等待networkIdle同時設定等待超時時間,超時直接注入代碼
如果 load 事件在其他事件前觸發,那就直接注入代碼。
0x02 DOM 構建前
解決了在什么時候注入 JavaScript 代碼的問題,接下來我們該開始考慮第一階段該注入什么代碼了。
由于在第一階段的時間點,DOM 樹還未構建,所以我們所注入的代碼均不能操作 DOM,能干的事情也就只有 Hook、備份 BOM 中的函數。
basic
我們先把一些會導致頁面阻塞、關閉的函數給 Hook 了,例如:

同時也需要在 CDP 中處理 Page.javascriptDialogOpening 事件,因為還有類似 onbeforeunload 這樣的彈窗。
location
還記得我們上一篇通過修改 Chromium 代碼將 location 變成可偽造的事情了嗎?就是為了能夠在這里對 location 直接 Hook,直接看代碼:
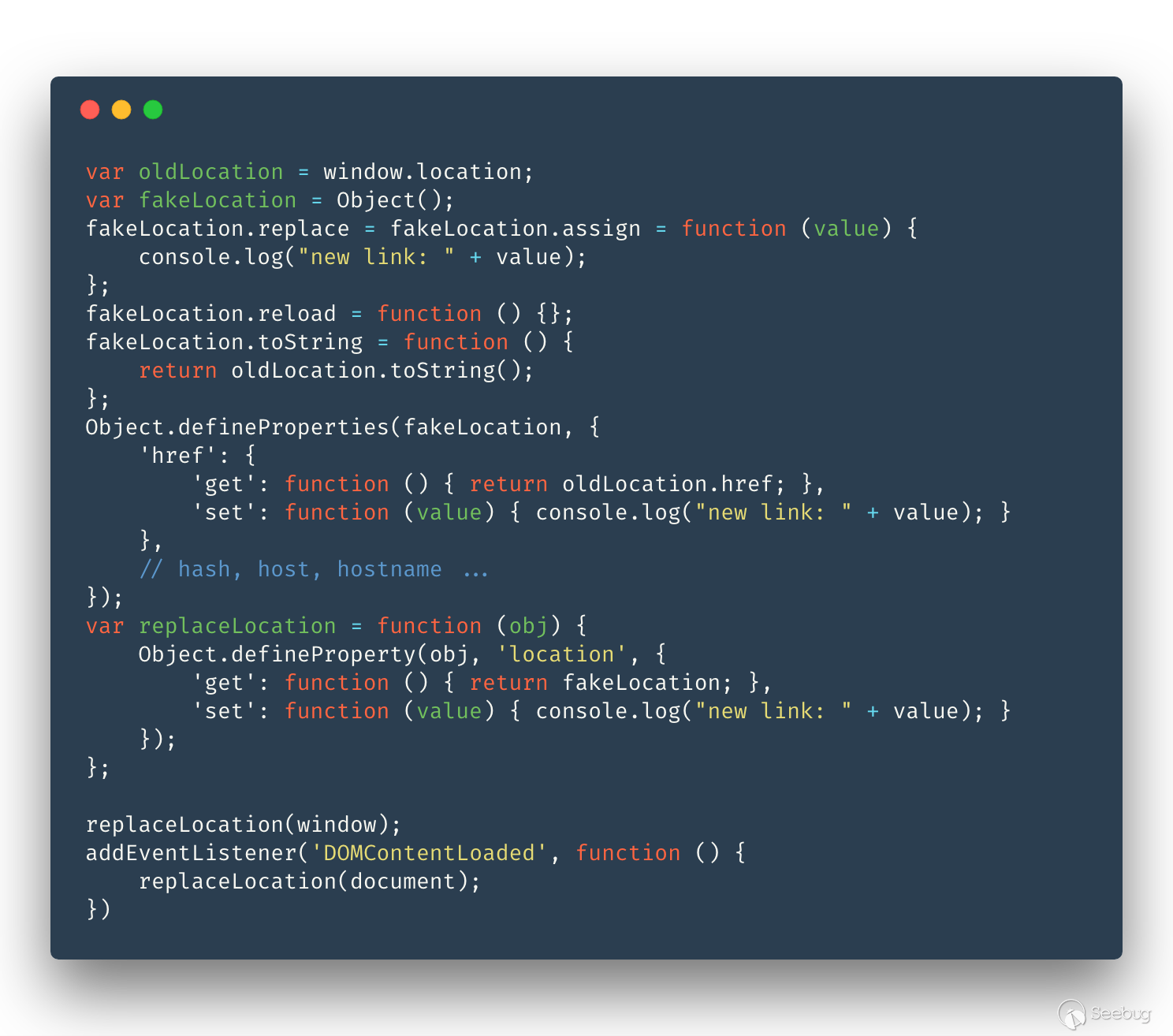
這里還需要注意的是 doucment.location 需要等待 DOM 構建結束之后才能 hook, 所以需要注冊 DOMContentLoaded 事件來 hook document.location。
網絡
因為之前我們修改了 Chromium 代碼使得 window.open 無法新建窗口,這樣在 CDP 中也沒法獲取 window.open 想打開的鏈接信息,所以我們還需要在代碼中 Hook window.open 函數:
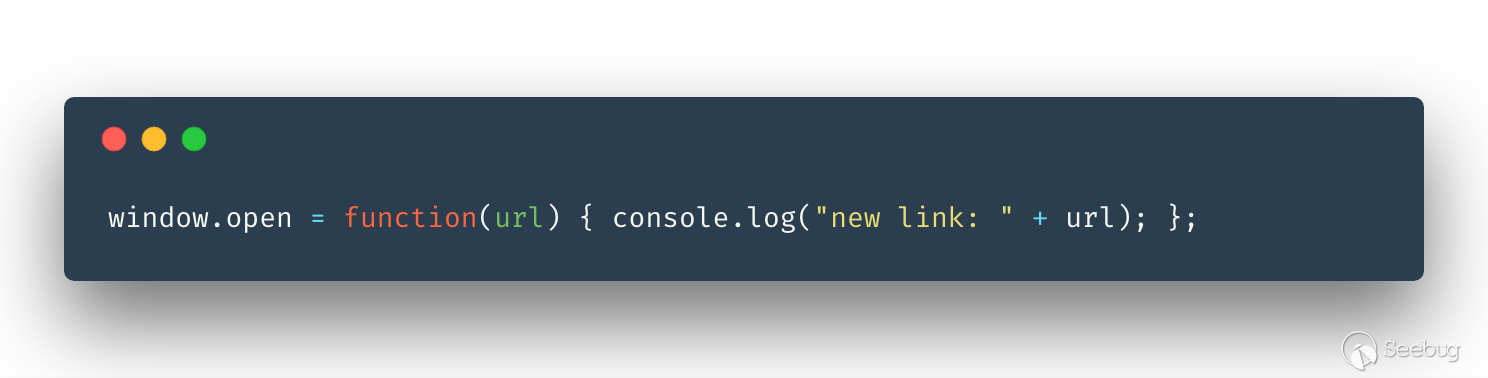
還有我們比較常用的 AJAX:
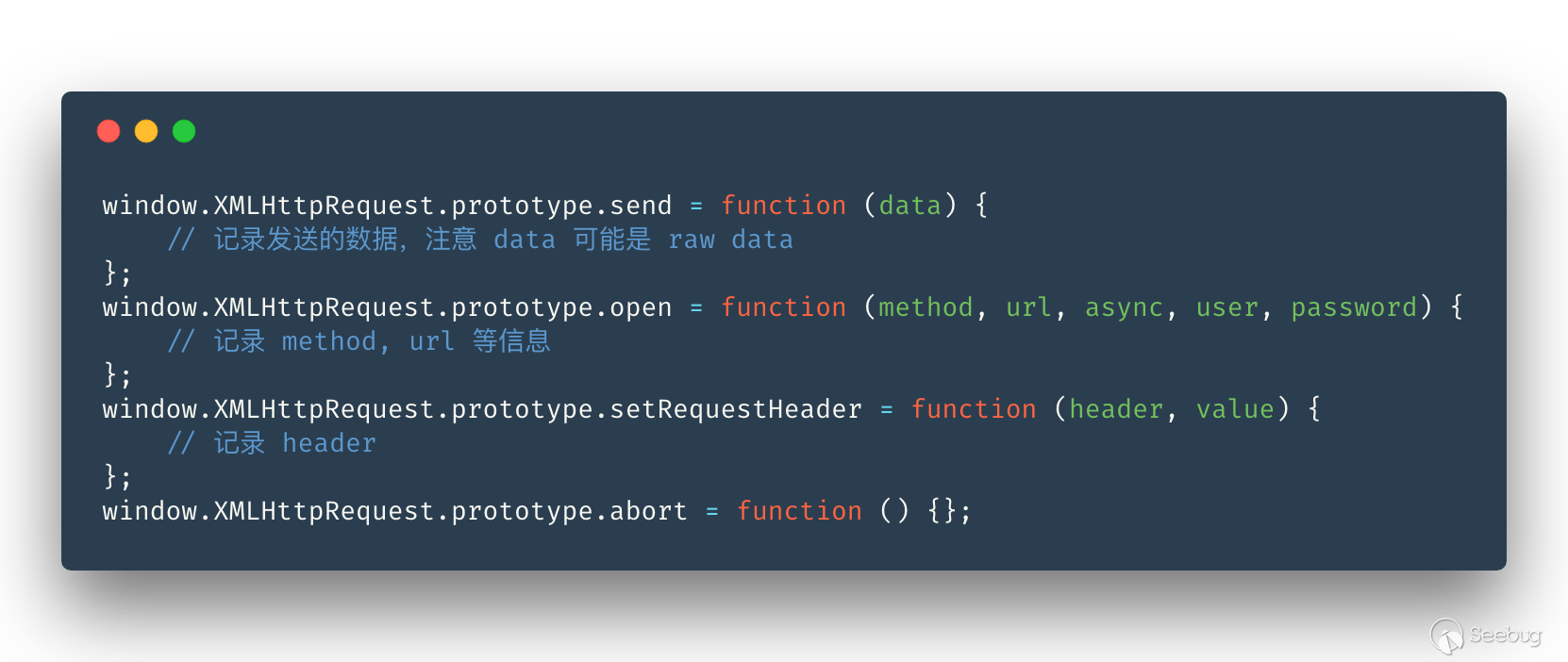
hook XHR 時要考慮的問題就是在 XHR 正在發送請求的時候,需不需要暫停我們的其他操作(如觸發事件)? 我們注入的代碼的下一個操作可能會中斷正在發送的 XHR 請求,導致更多鏈接的丟失, 比較典型的例子就是:AJAX Demo,這個問題沒有標準答案。
WebSocket、EventSource、fetch 和 XHR 差不多:
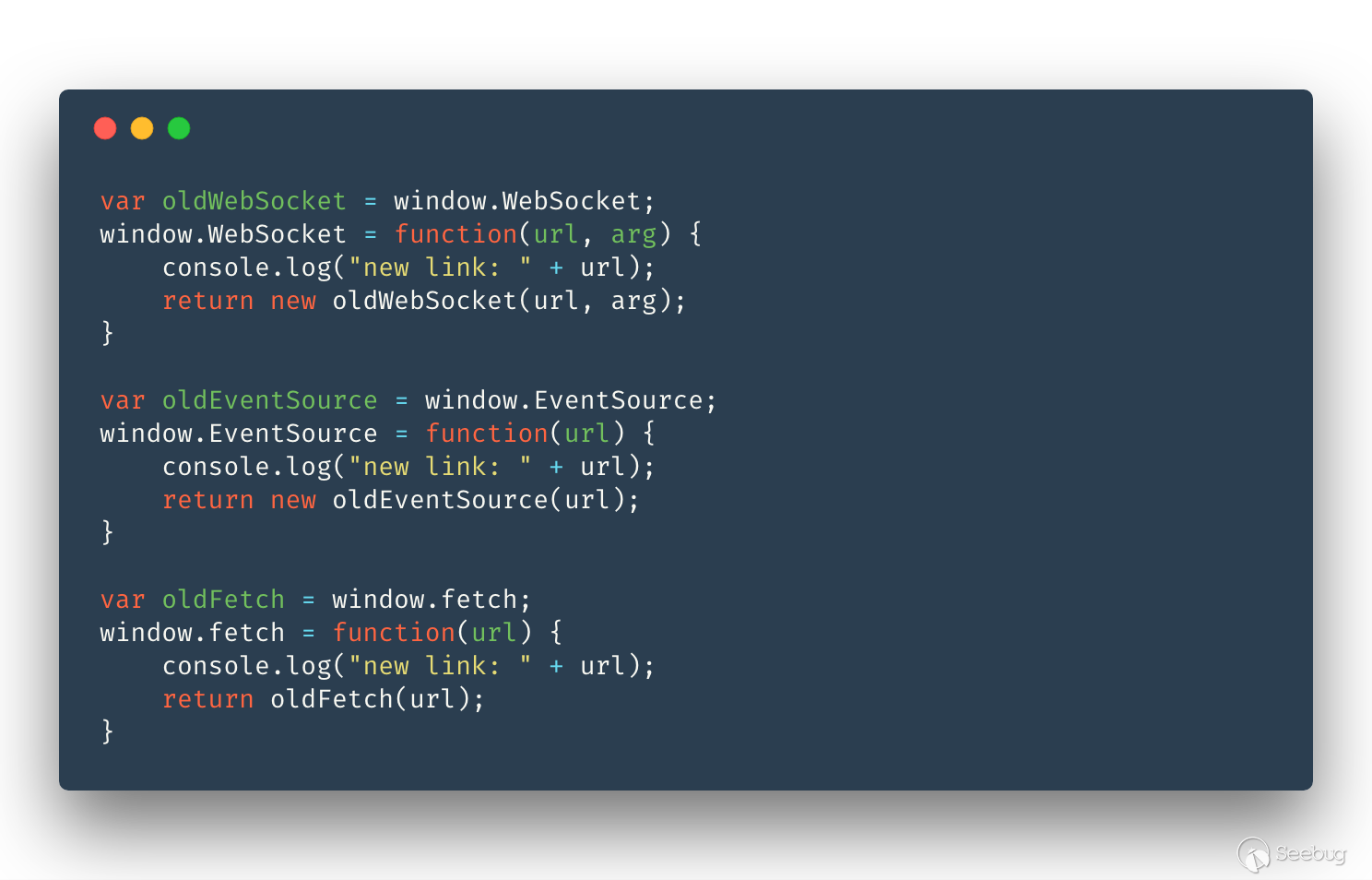
時間
我們還需要 hook 兩個定時器函數:
-
setTimeout -
setInterval
因為可能用戶代碼會延遲或者定期做一些操作,我們可能等不來那么長的時間,所以我們要給這些定時器做一個加速, 也就是 Hook 之后修改相對應的 delay 為更小的值,同時加速之后也要 hook Date 類來同步時間。
鎖定
我們可以 hook 這些函數,那么其他人也可以繼續 hook 這些函數,但一般對這些函數進行 hook 的人都不是什么好人, 被別人繼續 hook 之后可能會影響到我們的代碼,所以我們還需要鎖定這些基礎函數。
例子:
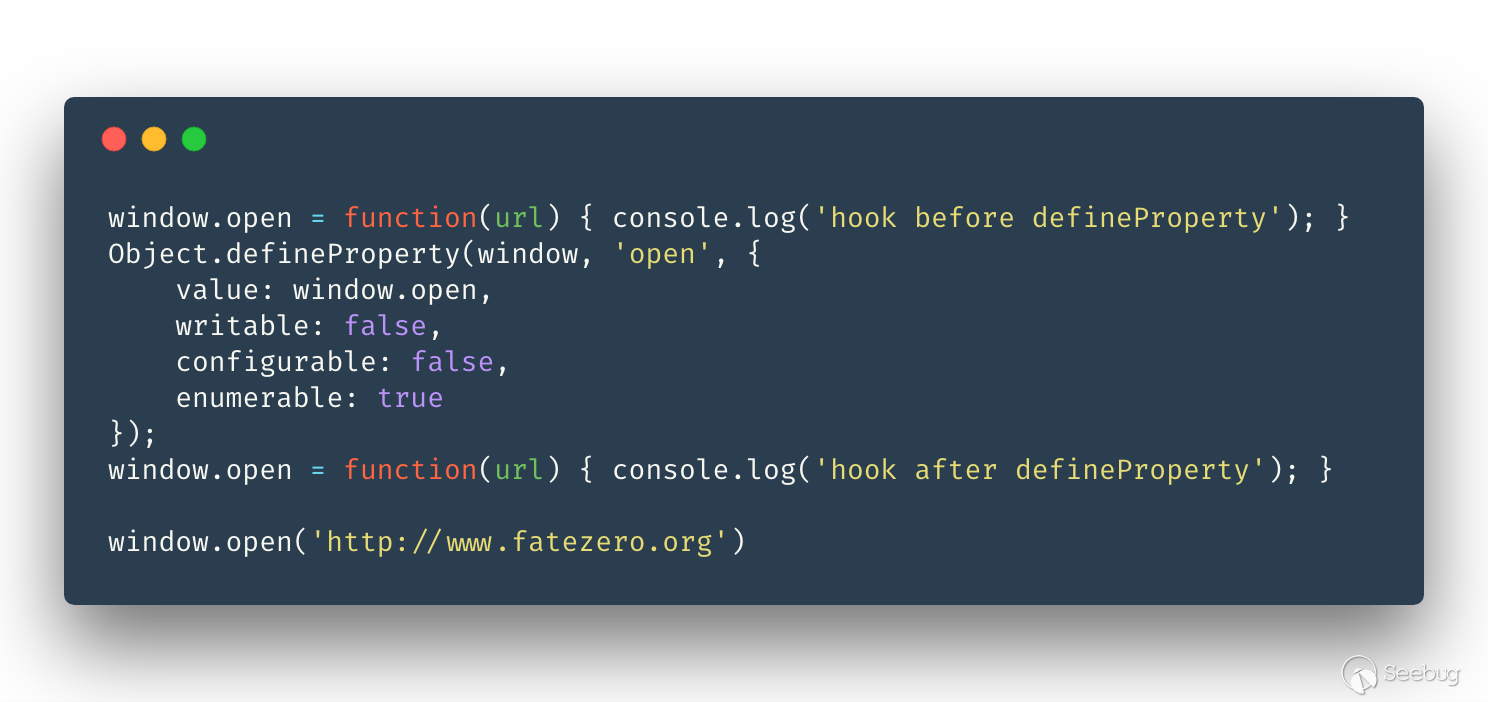
結果:

第一階段我們能做的事情也做得差不多了,剩下的事情就交給第二階段的代碼干了。
0x03 遍歷節點
第二階段,也就是頁面穩定后,我們肯定是要先遍歷 DOM 中的各個節點, 然后才能獲取節點上的鏈接信息,以及觸發節點上綁定的事件,所以這里我們看一下獲取 DOM 中所有的節點,有哪些方法:
-
CDP 的
DOM.querySelectorAll -
document.all
-
document.querySelectorAll
-
TreeWalker
我們一個一個的排除, 首先排除 CDP,因為如果使用 CDP 遍歷各個節點,那就意味著后續的對節點的操作也要繼續使用 CDP 才能進行,其速度遠沒有在一個 Context 內的代碼操作 DOM 快。 接著排除 document.all(HTMLAllCollection,動態元素集合) 和 document.querySelectorAll(NodeList, 靜態元素集合),因為這兩個都只是元素集合,而不是節點集合, 并不包含 text, comment 節點。最后就剩下 TreeWalker 了。
TreeWalker 也有兩種玩法,一種是先獲取所有的節點,然后在觸發各個節點上的事件,另外一種是邊遍歷節點,邊觸發事件。
可能會有同學覺得第二種方法比較優雅,我們看一下使用第二種方法的一種情況:
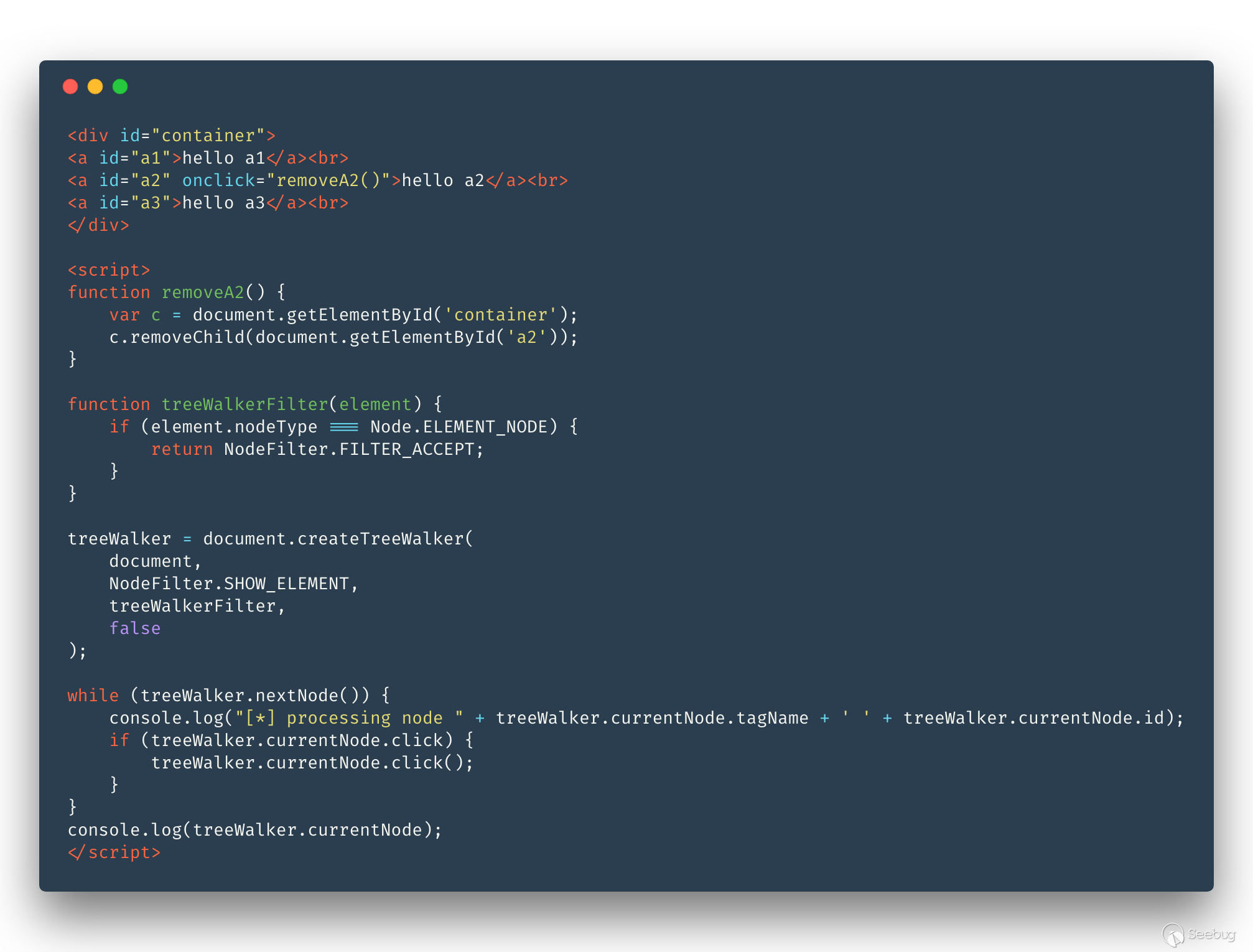
結果:
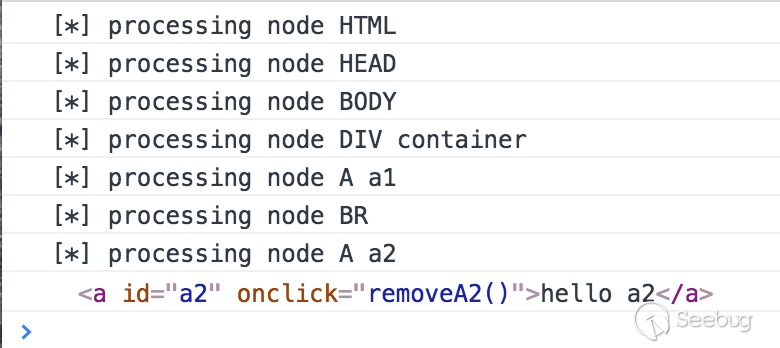
是的,如果 TreeWalker 剛好走到一個節點,觸發了事件使得該節點離開了 DOM 樹,那 TreeWalker 就走不下去了, 所以比較保險的方法就是在頁面穩定后收集一份靜態的節點列表,再觸發事件,也就是使用 TreeWalker 的第一種玩法。
0x04 事件觸發
在收集到一份靜態節點列表,獲取靜態節點列表的鏈接信息之后,我們就該考慮一下如何觸發各個節點上的事件了。
首先,我們來談一下如何觸發鼠標、鍵盤相關的事件,主要方法有兩:
-
dispatchEvent
-
CDP 的 Input.dispatchMouseEvent
我們使用一個簡單的例子看一下兩者最大的差別:
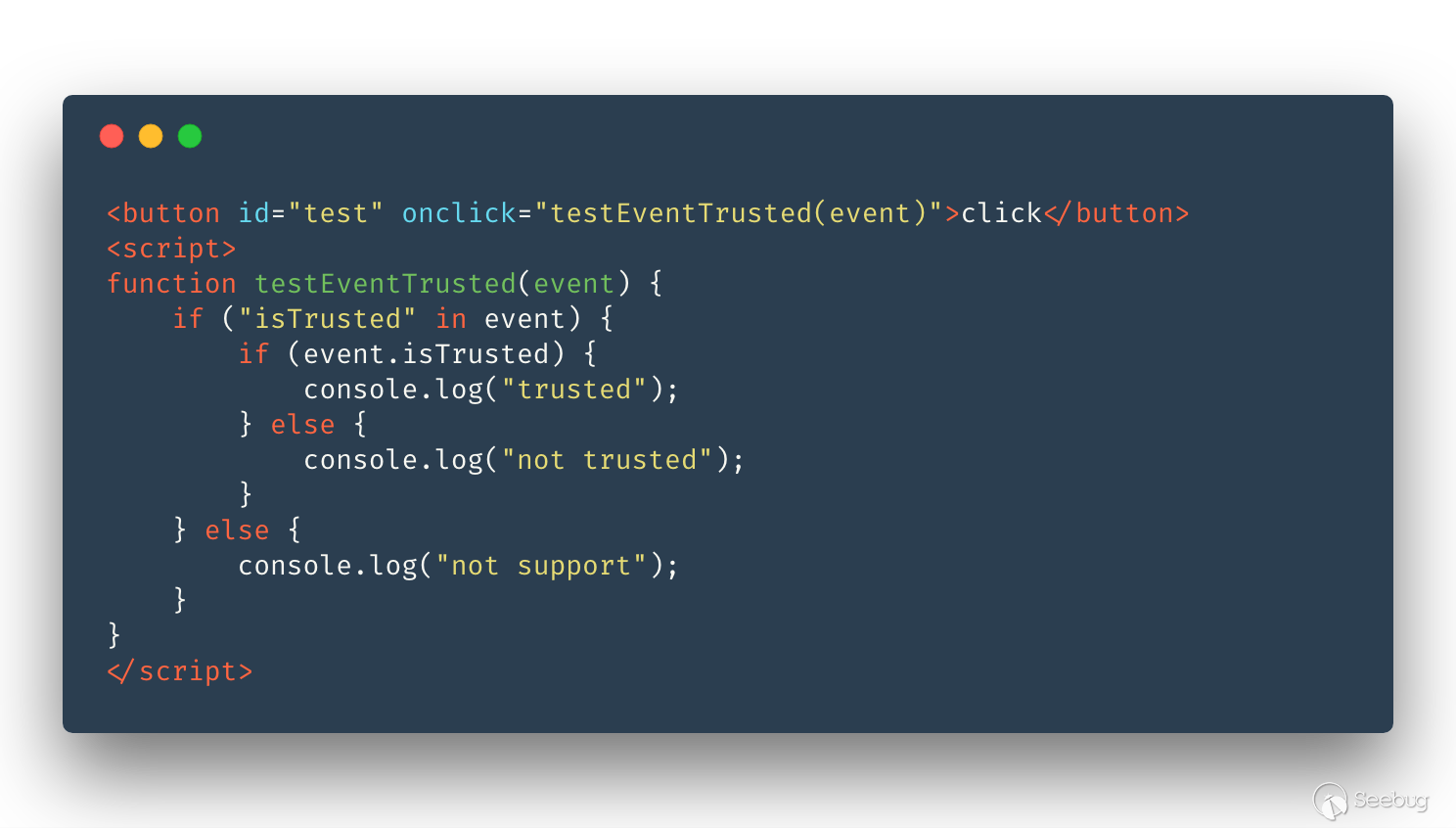
使用 CDP 測試兩者區別:
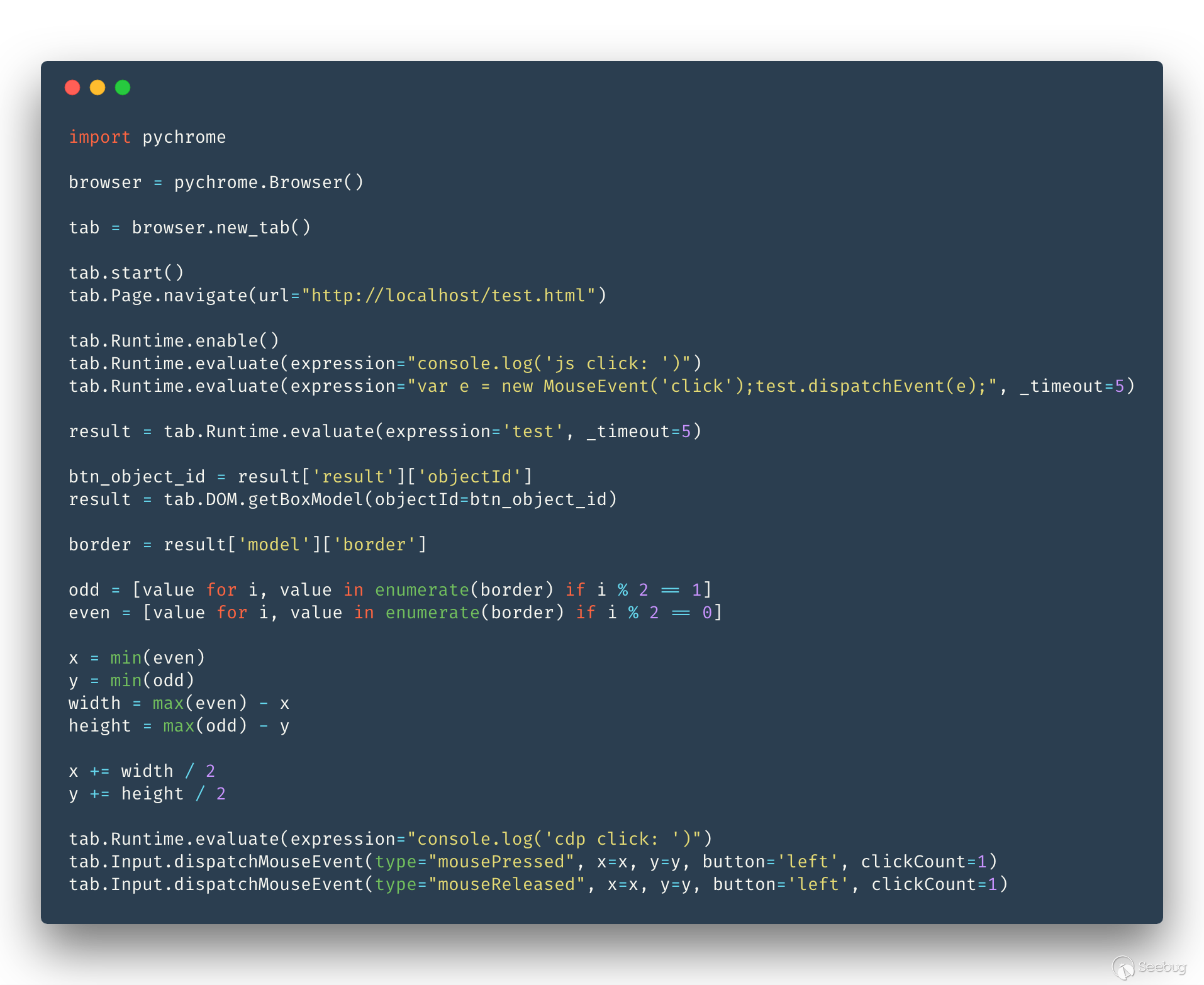
結果:

dispatchEvent 和 Input.dispatchMouseEvent 這兩者最大的區別就是事件來源是否是真實的用戶點擊, 雖說 isTrusted 也就是一個改 Chromium 代碼就能解決的問題,但我們也沒法保證還有沒有其他黑科技來檢測是否事件是否來自真實用戶。 然而我還是覺得 CDP 實在太慢,所以還是繼續選擇使用 dispatchEvent 來觸發各種事件。
接下來我們要考慮一下如何使用 dispatchEvent 觸發事件, 可能有些同學覺得,我們可以掃描所有元素節點,收集內聯事件,對于動態添加的事件,可以 Hook addEventListener 獲取到, 最后再挨個觸發元素相對應的事件,其實這樣做是有問題的。
我們還是先看看一個例子:
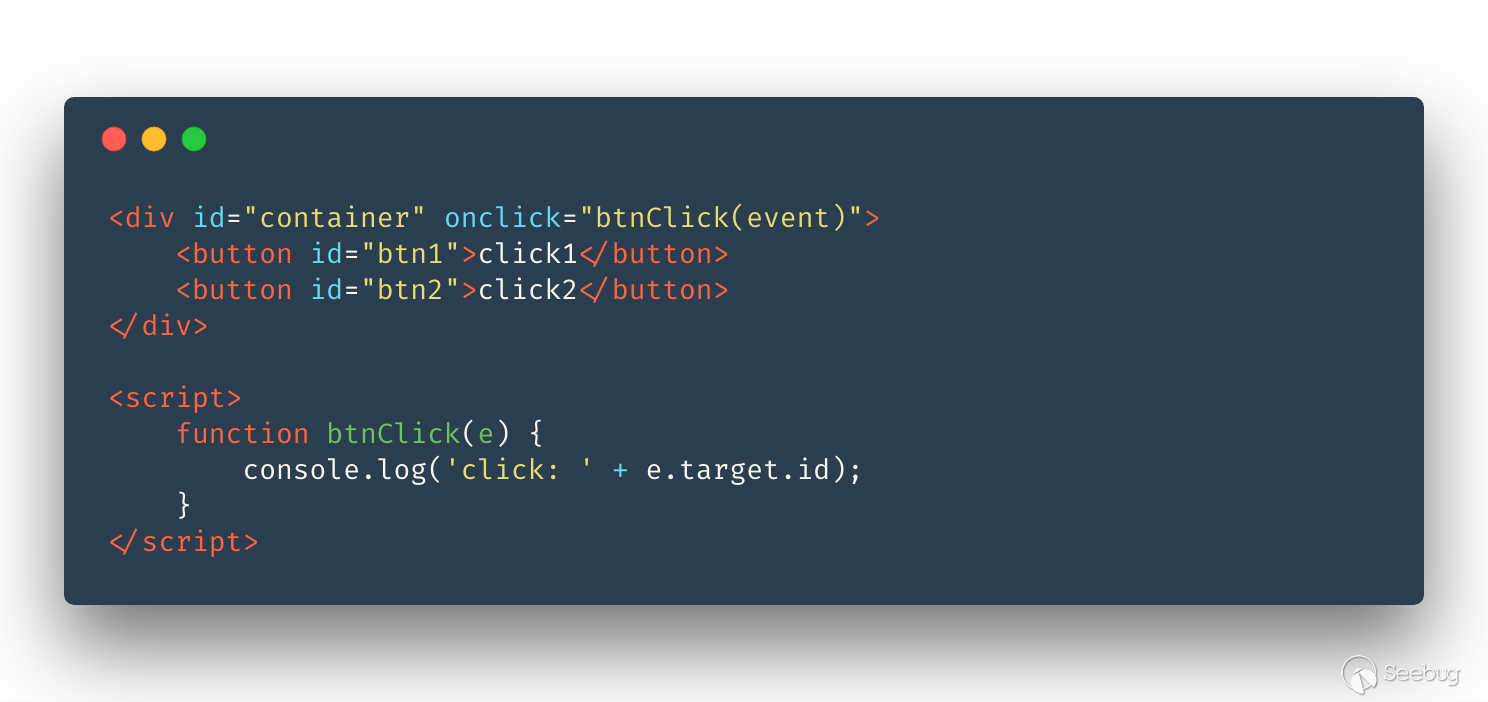
例子將事件綁定在 container 內,等事件冒泡到 container,再通過 event.target 區分元素。 如果按照之前的思路,我們的代碼將會在 container 中觸發一個點擊事件,而忽略了 container 下的兩個按鈕,所以之前的思路并不合理。
我個人的想法是,每個元素都只觸發常用的事件,比如說 click、dbclick、mouseover 等事件,忽略一些非主流事件。 只觸發常見的鍵盤、鼠標事件讓我們的行為更像是一個正常人類的行為,這樣也減少了被反爬蟲機制帶入坑的可能性。 另外,說到爬蟲行為做到和正常人類類似,還有一個小細節,那就是元素是否在可見區域, 以前都是直接將瀏覽器的 viewpoint 設置最大,現在我們使用 element.scrollIntoViewIfNeeded 將滾動條滾動到元素的位置,然后再觸發事件。
0x05 新節點
那么問題又來了,由于我們各種點擊、敲擊鍵盤、嘗試觸發各種操作而產生新的節點,我們該怎么辦? 肯定還是要繼續處理這些新節點,但是怎么找到這些新節點,難道還要重新再掃一遍 DOM 查找新節點? 有沒有一個方法可以獲取到變化的屬性和節點?
在 HTML5 中就剛好有這么一個類 MutationObserver,我們看看例子:
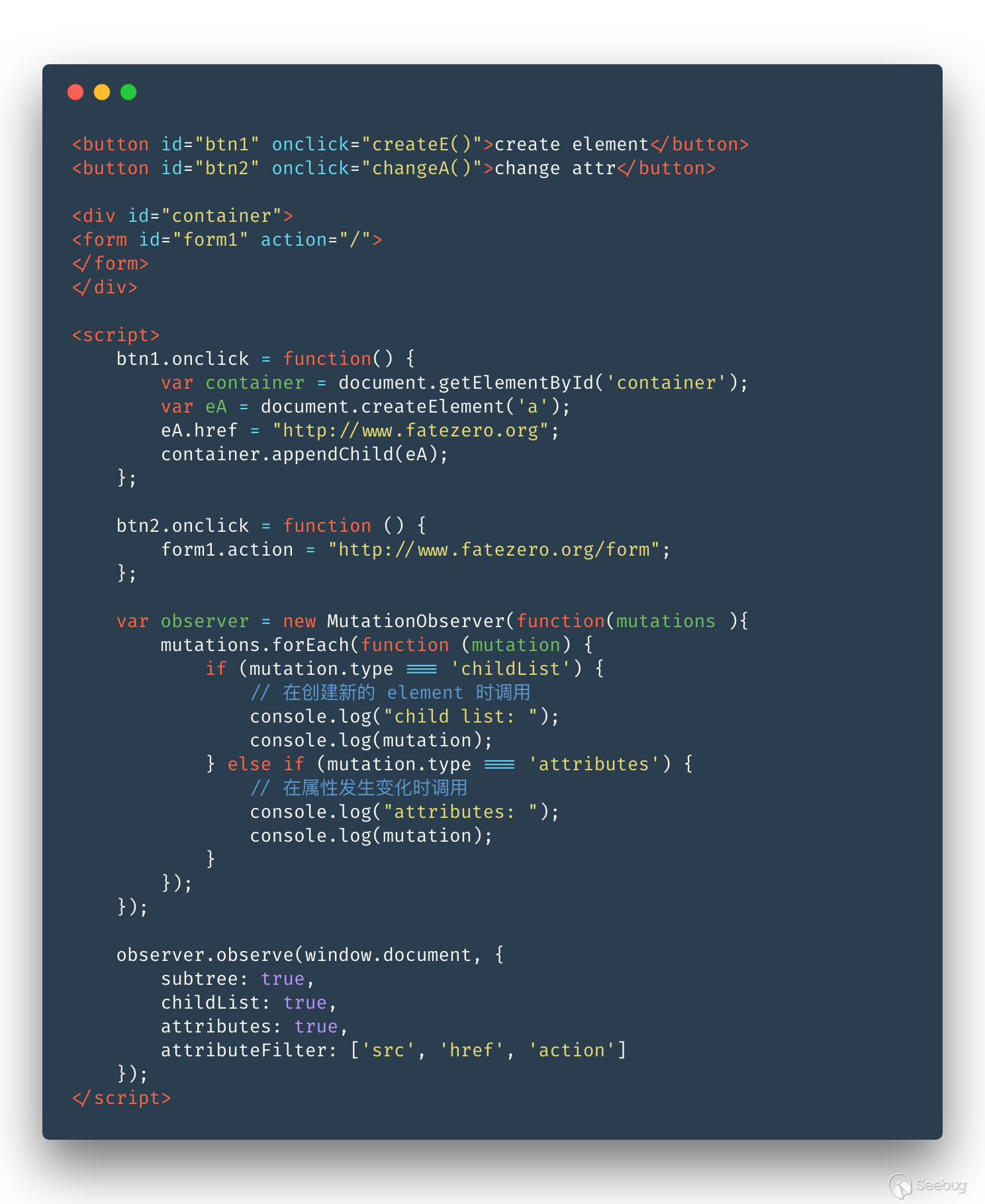
按順序點擊 btn1 和 btn2 的結果:

所以我們完全可以利用 MutationObserver 作深度優先的掃描,如果彈出新的節點,那就優先處理新的節點。每次都是先靜態掃描新的節點列表,然后再嘗試觸發新增節點列表的事件。
但是值得注意的是 MutationObserver 并不會實時將變更元素傳回來,而是收集一個時間段的元素再傳回來,所以未能及時切換到新的節點繼續觸發事件也是正常的事情。
0x06 自動填寫表單
OK,事件我們觸發了,新節點我們也處理了,這里我們還需要對一些元素進行特殊處理,比如說自動填寫表單內的輸入元素。
這一小節沒什么難度,主要是判定哪些地方該填名字,哪些地方該填郵箱,哪些地方該填號碼, 需要根據不同情況輸入對應的數據。另外還要注意的是在填寫數據的時候還要觸發對應的事件,例如填寫 <input type="text"> 的時候, 我們需要把鼠標移動到 input 元素上,對應觸發 mouseover、mouseenter、mousemove 消息, 接著要鼠標點擊一下輸入點,對應 mousedown、mouseup、click 消息, 然后鼠標移開轉到其他元素去,對應 mousemove、mouseout、mouseleave 消息。
這里還有個小建議,所有的用戶輸入都帶上一個可識別的詞, 例如我們自定義詞為 CasterJS,email 處就填寫 casterjs @gmail.com, addr 處就寫 casterjs road, 至于為什么下一篇再說。
0x07 CDP
這一個小結主要和 CDP 相關的 TIP ,使用什么語言操控 CDP 都行,在這里我選擇我比較熟悉的 Python 作為解釋。
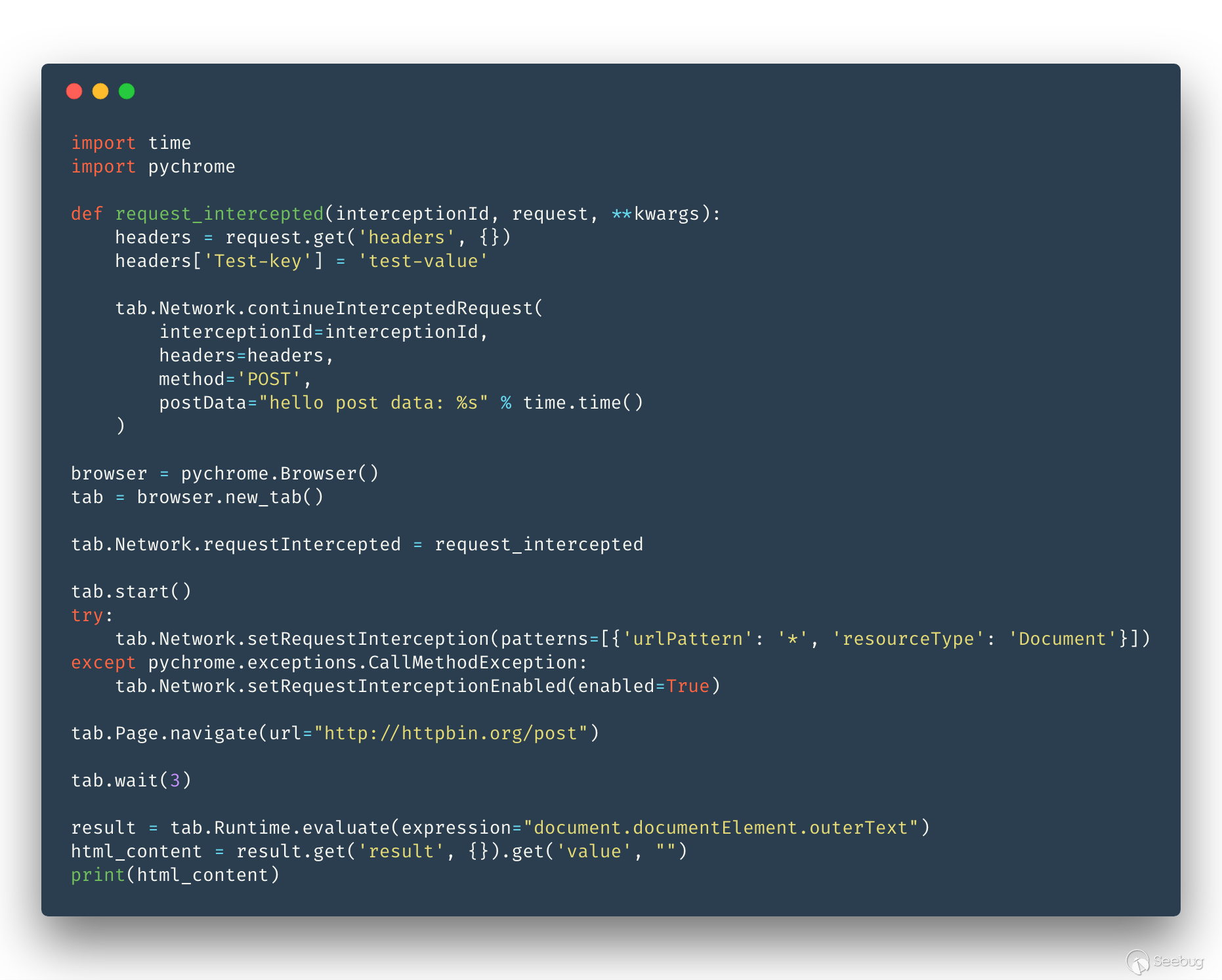
自定義 request
CDP 在 navigate 的時候并不能直接自定義 request,通俗的講就是在 navigate 的時候并不能設置 method 和 headers 等信息, 但很明顯這個功能對我們的掃描器來說非常重要。幸運的是,雖然 CDP 沒有直接支持這樣的功能,但可以通過 Network.requestIntercepted 變向實現這樣的功能。
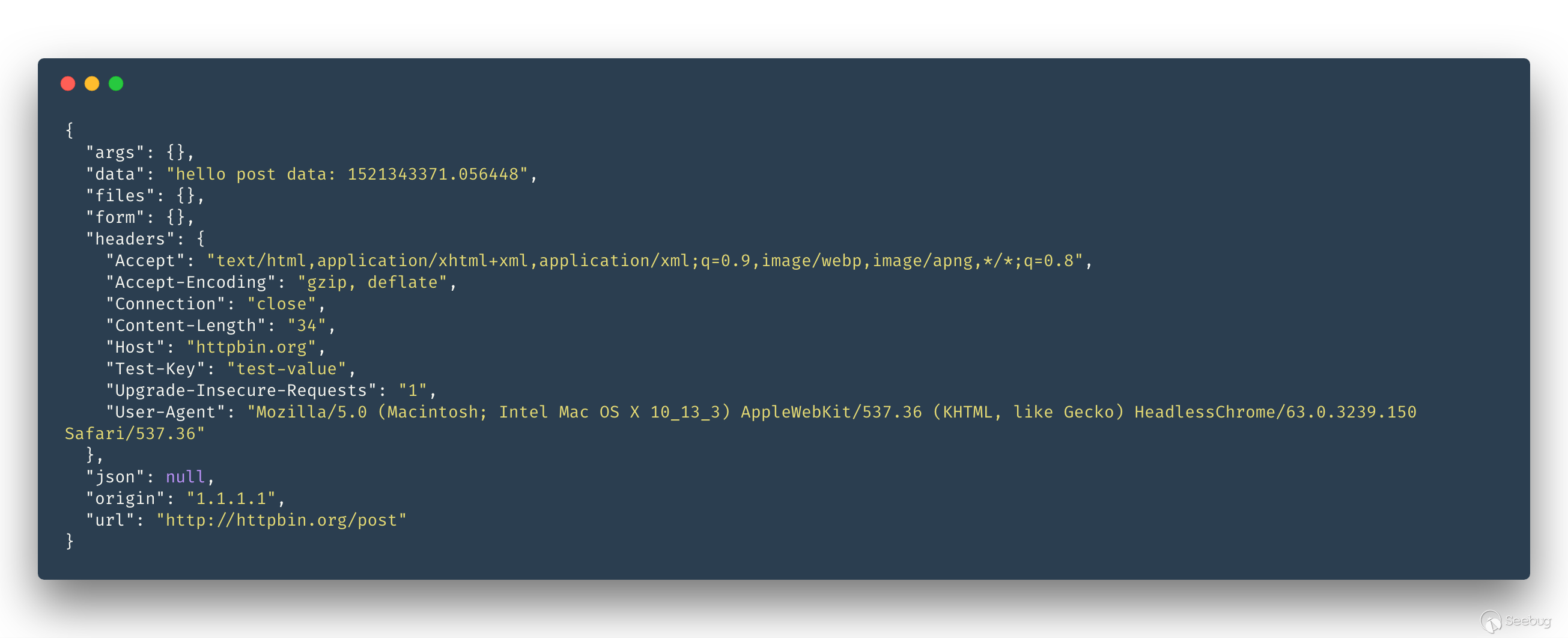
代碼如下:
結果:
網絡優化
我們的瀏覽器是肯定需要加載 css 和 js 的,那其他網絡資源如圖片、視頻等媒體資源是不是可以直接禁止加載? 其實這樣做并不合理,直接禁用圖片等資源可能會影響到用戶代碼執行邏輯,例如我們常見的 <img src=1 onerror=alert(1)>, 所以比較好的解決方法就是返回假的媒體資源。
代碼如下:
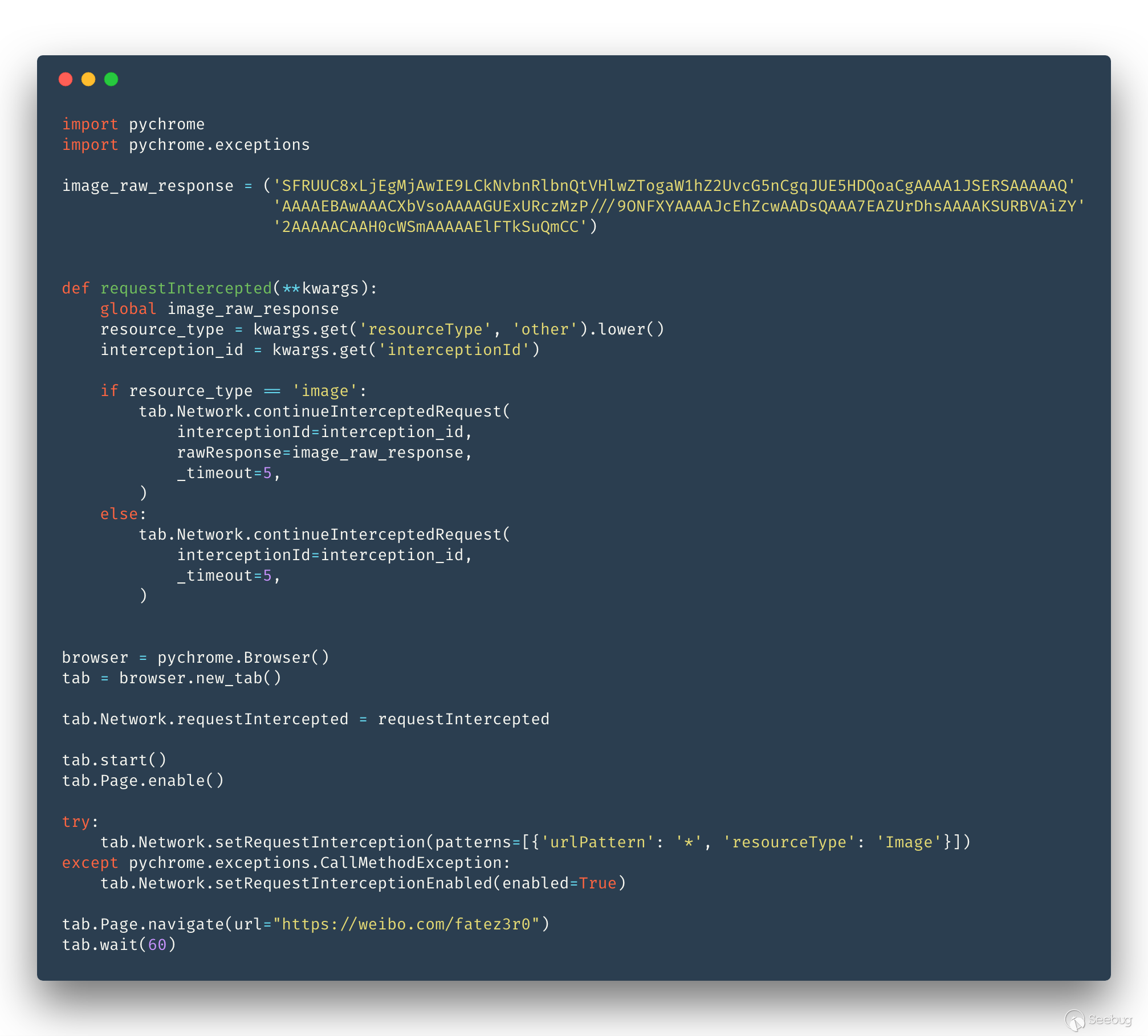
session isolate
我們的掃描器可能會有使用不同用戶信息掃描同一個域名的情況, 我們肯定不希望在同一個 browser 下,不同 tab 的 Cookie 信息等串在一起, 我們希望每個 tab 都有一個隱身模式,每個 tab 都資源互不影響, 比較走運的是 Headless Chrome 剛好有這么一個功能,叫 session isolate ,也是 Headless 模式下獨有的功能。
我們看一下 Headless 模式的 session isolate 功能的簡單例子:
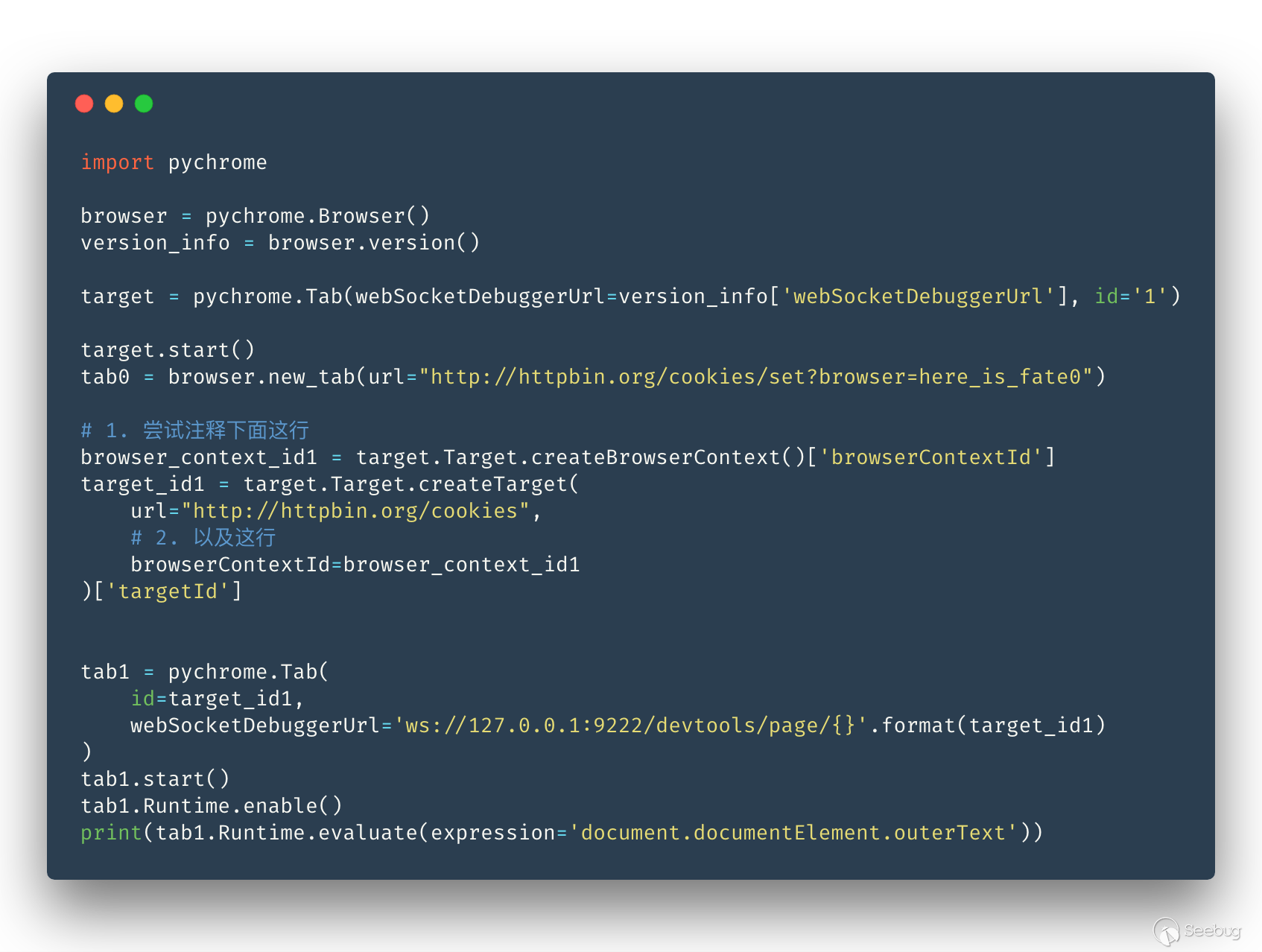
運行結果:

如果注釋 1、2 兩行,運行結果:

所以只要每個 tab 都新建一個 BrowserContext 就可以做到互不干擾了, 這也就相當于每個 tab 都是一個獨立的隱身模式,能夠做到每個 tab 互不影響, 也可以共用一個 BrowserContext 達到共享 cache、cookie 之類信息的功能。
安全問題
從 chromium 62 開始存在一個安全問題,在使用 remote-debugging-port 參數的時候可以系統上任意寫文件, 我已經提交安全 issue 給 chromium, 可惜撞洞了,有人比我早了一個月提交了相關漏洞, 所以在選定 chromium 版本的時候要注意跳過這些版本或者自行修復這些問題。
0x08 結合
講了那么多,是時候該把所有的東西結合在一起,我們先簡單捋一下執行過程:
-
注入 Hook 相關的 JavaScript 代碼
-
使用 TreeWalker 遍歷節點,收集節點鏈接信息,獲取靜態的節點列表
-
觸發各個節點的相關操作,自動填寫表單
-
MutationObserver 監控動態節點創建,優先處理新節點
我們以 http://testphp.vulnweb.com/AJAX/index.php 作為例子跑一遍,看一下我們代碼的執行狀況, 為了更方便的展示,我將每個節點(觸發事件)的處理時間都額外增加了 0.1s,同時也給所有節點都加上了邊框,藍色邊框表示正在處理的節點。
測試視頻:http://static.fatezero.org/blog/video/web-scanner-crawler-02/vulnweb_test.mov
通過加邊框和打 log 的方式,我們完全可以一步一步的看著爬蟲的操作是否符合我們的預期。這個例子的結果證明了:
-
xhr 的 hook(不被其他 xhr 中斷)
-
事件的觸發(新節點的產生)
-
MutationObserver 的監控(正確處理新節點)
-
圖片資源的處理(原始圖片被替換)
-
窗口的處理(沒有彈 alert 窗)
上面的行為是符合我們的預期的。
目前第一篇和第二篇的內容總算是組合在了一起,成為了一個能夠獨立運行、測試的組件,該組件所提供的功能就是輸入一個 request 相關的信息,返回 response 中所有的鏈接信息, 如果我們的爬蟲存在鏈接信息漏抓,那很可能就是這部分出問題,所以也只需要調試這部分代碼即可,非常方便。
該組件可以通過stdin/stdout、RPC、消息隊列等方式傳遞任務和結果。 可以通過在單臺機器上多開 tab 達到縱向擴展,也可以在多臺機器上啟多個 browser 達到橫向擴展,這部分各自有自個的想法,不會就這個方向繼續寫下去了。
0x09 總結
至此,Web 漏洞掃描器爬蟲中的 Downloader 這部分我已經簡單地介紹了一遍, 對照一下我自己的代碼,也深知這部分我并沒有講全,因為這部分坑多,內容也亂且多,但是再寫下去就真的沒完沒了,看著累,寫著更累,得趕緊切到下一個話題。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/570/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/570/
暫無評論