
作者:Koalr
原文鏈接:https://koalr.me/posts/core-concept-of-yarx/
xray 得益于 Go 語言本身的優勢,沒有那么多不安全的動態特性,唯一動態是一個表達式引擎(CEL),用的時候也加了各種類型校驗,和靜態代碼沒有什么區別了,因此基本不可能實現 RCE 之類的反制效果。那么我們換個思路,有沒有辦法讓 xray 直接無法使用呢。
無法使用有兩個表現,一個是讓其直接崩潰掉,效果就是如果用 xray 掃描一個惡意 server,xray 直接 panic 退出。xray 0.x.x 之前的某些版本確實有這種 bug,我當時耗費了很大的精力去這個定位問題然后開心的修掉了,這里就不細說這個點了,因為版本太老說了也沒有太大意義。
另一方面呢,想想之前比較熱門的 CobaltStrike 反制,做法是設法取得 CS 的通信密鑰然后模擬其上線流量,Server 端會瞬間上線無數機器,使得 CS 無法正常使用。那么我們能否給 xray 喂屎,使得它能瞬間掃出無數漏洞來讓正常的掃描失效呢,我順著這個思路做了一些探索,這篇文章就來說下我在編寫這樣一個”反制“工具的過程中遇到的困難以及我是如何解決的。
入手
想讓掃描器能掃出漏洞,只需要滿足掃描器對一個漏洞的規則定義即可。xray 的 poc 部分是開源的,意味著我們可以知道 xray 在掃描時是怎么發的包,以及什么樣的響應會被定義為漏洞存在。那么我們只要能定義一個 server ,讓 server 按照 poc 中定義的的響應去返回數據,就可以欺騙 xray 讓其認為漏洞存在!看一個最簡單的例子:
rules:
r0:
request:
method: GET
path: /app/kibana
expression: response.status == 200 && response.body.bcontains(b".kibanaWelcomeView")
expression: r0()在這個例子中,只要讓 /app/kibana 這個路由返回.kibanaWelcomeView 并且狀態碼是 200,就能掃出 poc-yaml-kibana-unauth 這個漏洞。這太簡單了,我們只需要批量解析一下所有 poc,然后基于規則構建一下返回的數據就可以了,事實的確如此,不過過程可能稍顯曲折。來看下另一個例子:
set:
rand1: randomLowercase(10)
rules:
r0:
request:
method: GET
path: /enc?md5={{rand1}}
expression: response.body.bcontains(bytes(md5(rand1)))
output:
search: 'test_yarx_(?P<group_id>\w+)".bsubmatch(response.body)'
group_id: search["group_id"]
r1:
request:
method: GET
path: /groups/{{group_id}}
expression: response.headers["Set-Cookie"].contains(group_id, 0, 8)
expression: r0() && r1()這個例子復雜了億點,其復雜性主要來自于這幾方面:
- 整體存在兩條規則
r0() && r1(),且兩條規則都滿足才行 - path 中存在變量,無法直接將 path 作為路由使用
- 第二條規則的
group_id來自于第一條規則的響應進行匹配得到的值,即兩條規則存在聯系 - 對響應的判斷沒有使用常量,而是需要將變量經過部分運算后返回給掃描器才有效
可能有同學會問,實際的 poc 真有這么復雜嗎,答案是有過之而無不及。這種邏輯復雜還有層級關系的 poc 極大的阻礙了我們上面一把梭的想法。我們需要重新整理一下思路,尋找一下破局的方法。
破局
yaml poc 中的 expression 部分用于漏洞存在性判斷,它是一條規則在執行過程最終的終點,從這里出發去尋找解決方案是一個不錯的思路。 expression 部分是由 CEL 標準定義的表達式,下面這些形式都是合法且常見的:
reponse.status != 201
response.header["token"] == "lwq"
reponse.body.bcontains(bytes(md5("yarx")))需要反連的漏洞先不談,宏觀來講一個響應我們可以控制的點只有4個:
- 狀態碼
- 響應頭
- 響應體
- 響應時間
最后一個一般用于盲注檢測的指標也暫時不看,其余三個就可以涵蓋絕大部分的 yaml poc 的判定規則。因此對于一條 expression,我們只需要確定下列三點就可以做自動化構建:
- 修改的位置(status,body,header)
- 修改方式(contains, matches, equals)
- 修改的值(body 或 header value 等)
那么如何對每條 expression 確定這三點呢?也許簡單的 case 我們可以直接用正則匹配實現,但正則解決不了諸如 reponse.body.bcontains(bytes(md5("yarx")))的情況,而這樣的情況有很多,因此為了降低復雜度。我從 AST 層面入手解決了這個問題。老生常談的做法這里就不展開了,經過一坨的遍歷和分析之后,可以把表達式解析成下面的形式:

可以發現前兩個的規則其實是靜態的,這種靜態規則我們可以在分析的時候就計算出正確的數據,然后在響應返回即可。比較棘手的是第三個例子的情況,判斷條件種包含了 r1這樣一個變量,這個變量由 xray 生成,在請求的某個角落被發送過來。換句話說,我們需要先獲取到這個變量的值,然后才能代入到表達式中計算獲取最終的結果,那么怎么獲取這個變量呢?舉個栗子
set:
rand1: randomLowercase(8)
rules:
...
request:
path: /?a=md5({{rand1}})
expression: response.body.bcontains(bytes(md5(rand1)))當上述 poc 被加載運行時,作為服務端會收到一個類似這樣的 path: /?a=md5(abcdefgh) 這里的 abcdefgh 就是我們要獲取的變量的值。聰明的你不難想到,我們只需要做一個正則轉換就可以實現這個目標(別忘了正則需要轉義):
Origin: /?a=md5({{rand1}})
Regexp: /\?a=md5\((?P<rand1>\w+)\)甚至基于randomLowercase(8) 這個上下文,我們可以寫出一個更完美的正則:
Origin: /?a=md5({{rand1}})
Regexp: /\?a=md5\((?P<rand1>[a-zA-Z]{8})\)基于這個思想,我們可以把請求的各個位置都變成正則表達式,這些正則將在收到對應的請求時被執行,并將提取出的變量儲存起來供表達式使用。可是,如何使用這些變量?
變量
變量是 poc 的利器,也是我們的絆腳石。不如就 ”以變制變“ 來解決變量帶來的一系列問題。我在解析表達式的時候沒有分析到底,而是以下面的這些函數或者運算符作為終止條件,并記下他們的參數。
=、!=contains、bcontainsmatches、bmatches
這樣有什么好處呢,就是可以借助表達式的部分執行 (PartialEval) 來簡化分析流程。比如 contains 的參數可能是這些
"SQL Admin"
md5("koalr")
substr(md5(r1), 0, 8)如果我頭鐵去解析到底,這復雜度和重寫一個表達式語言差不多了。我發現這些參數實際都是合法的 CEL 表達式,當相關變量成功獲取后,它們也可以被 CEL 正常執行。當表達式被執行后,它便成為了我們最喜歡的常量類型,這種只執行參數的操作就被我定義為 PartialEval 。
"SQL Admin" => "SQL Admin"
md5("koalr") => "f2ebd1b28583a579fe12966d8f7c6d4b"
substr(md5(r1),0,8) => "210cf7aa" # if r1 = 'admin'接下來,我們可以將每種函數或是運算符視為一種匹配模式。比如 contains 就是讓參數直接包含在響應里;再比如 matches 的參數應被視為一個正則,我們需要根據正則去生成一個假數據再填充到響應里。
"response.header['token'] == 'yarx'" => resp.Header().Set('token', 'yarx')
"'ad[m]{2}in'.bmatches(resp.body)" => resp.Body.Write([]byte("admmin"))這樣每種模式都可以寫成一個處理函數,其邏輯基本都是這樣的流程:
- 從多個地方獲取變量的值
- 把參數作為表達式執行,獲取執行結果
- 將參數做對應處理然后寫入到響應
經過上面這些處理,我們就有了一堆分析好的處理函數, 離 xray poc 的逆解析又近了一步!
流程
新版的 xray 規則在最外層增加了一個 expression,可以借助它自定義執行流程,比如假設在 rules 部分定義了 4 個規則,那么 expression 可以任意的去構造:
rules:
r1: ...
r2: ...
r3: ...
r4: ...
expression: r1() && r2() && r3() && r4()
expression: (r1() && r2()) || (r3() && r4())
expression: r1() || (r2() && (r3() || r4()))我們在編寫 server 時也要符合這個定義才行,比如第一個要順序執行4條規則且全部滿足才可以。而后面兩個我們可以取個最短路徑來簡化邏輯,比如最后一個我們可以只滿足 r1 即可,這其實就是大家都學過的二叉樹的深度問題,取最淺的一條能到達葉子節點的路徑即可。
和執行流程相關的還有動態變量的問題,就是下面的這種情況:
rules:
r0:
request:
method: GET
path: /
expression: response.status == 200
output:
search: 'test_yarx_(?P<id>\w+)".bsubmatch(response.body)'
yarx_id: search["id"]
r1:
request:
method: GET
path: /{{yarx_id}}
expression: response.status == 200
expression: r0() && r1()在這個例子中 r1 會用到 r0 的響應中的變量。這個乍看很復雜,不過稍加思考就會發現,服務端的響應我們是完全可控的,因此我們可以將 r0 的響應在解析的時候就固定下來,xray 收到響應一定會提取出和我們一樣的變量值,所以后面用到該變量的地方也可以被直接替換成常量。對于這個例子,如果固定生成的 id 是 deadbeef ,那么這個規則實際上變成了下面的寫法,這樣做不僅簡單了,還對減少下面要說到的路由沖突的問題有很大幫助。
rules:
r0:
request:
method: GET
path: /
expression: response.status == 200
r1:
request:
method: GET
path: /deadbeef
expression: response.status == 200
expression: r0() && r1()縫合
經過了前面這么多的準備工作,我們終于可以開始著手編寫服務端邏輯了,這其實就是把一堆的處理邏輯縫合在一起的過程。縫合的方式很簡單,就是基于路由去調用。路由信息在 poc 中已經標明了,我們只需要將規則中的 method、path、header 等提取成一個唯一的特征,利用這個唯一的特征可以映射到上面寫的處理函數,進而走通流程。我起初以為這個很簡單,沒想到這個點耗費了我編寫這個項目最多的時間,其難點在于處理路由沖突,即有些情況下沒法提取出唯一的特征。
比如下面這兩個 poc,他們請求部分完全相同僅僅是表達式的判斷不同,請求可能會命中其中任意一個規則進行處理,這就導致只能掃出其中的某一個漏洞。
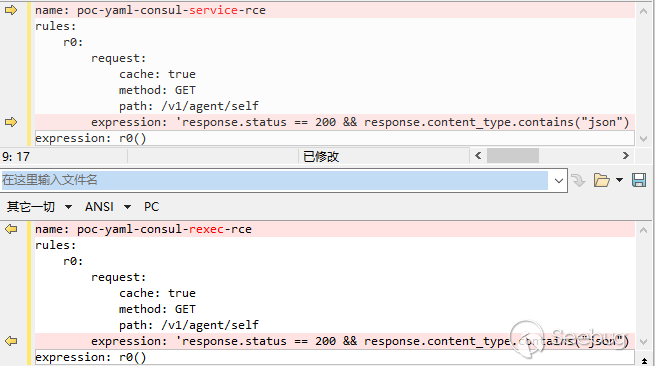
我對這類情況的處理是做一次合并,合并后的規則會包含原有的兩個規則的響應處理。由于 poc 中基本都是 contains 相關的處理,因此這種合并基本都是兼容的。當然,也有不兼容的情況,比如:
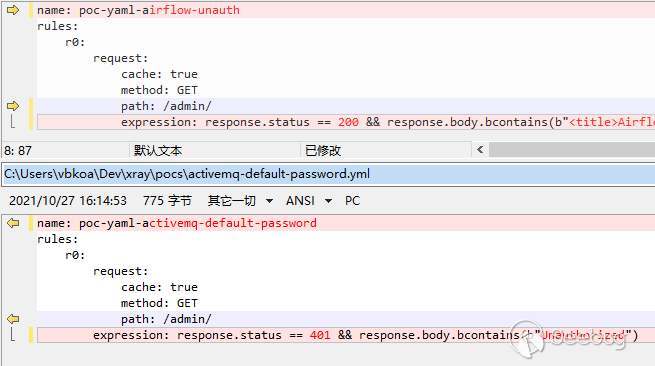
這里的 status 就是不兼容的,我們不可能讓一個響應既是 200 又是 401。除此之外,還有更棘手的動態路由問題:

這些 poc 的路徑過于簡單又包含變量,導致諸如 /admin.php 的路徑可能被任意一個匹配到,這顯然是不合理的。上面的兩個問題困擾了我好久,我最開始是計劃支持所有 xray poc 的檢測的,這個問題猶如心頭刺讓我很難受,掙扎幾日之后最終承認當前版本下這是一個無解的問題。在此過程中我嘗試減少沖突的思路有:
-
動態變量的靜態化
就是上面說到的 output 的處理過程 -
變量值的再確認
同一個變量在 poc 的一次運行中是不變的值,而變量可能在不同的規則中匹配出多次 -
調整路由順序
我寫了一個巨大的排序規則來讓 server 運行前把路由排個序,比如沒有變量的要好于有變量的,path 長的好于 path 短的,包含 header 的好于不包含的以此來讓靜態路徑優先匹配 -
添加層級判斷
就是給 poc 的運行添加狀態,比如第一個請求之后應該是第二個請求,如果第二個請求沒來那么第一個請求就不應該被處理
這些方法除了最后一個我都實現了,而且確實是有效。相比之下最后一點并非實現不了,而是由于其不可避免的會影響并發掃描的效率被我去掉了。盡管用了這么多的 trick,但依然無法支持所有的 poc 同時掃描,后面我也不再鉆牛角,我決定將一些過于靈活的 poc 直接去掉不加載,這個策略反而大幅提升了整體的檢出率。
把上面的思想包裝成代碼,再稍微踩點坑就誕生了 https://github.com/zema1/yarx 這個項目。截至到這篇文章寫完時已經可以單端口瞬間檢測出 280+ 漏洞(官方約 340個 poc),這個數據伴隨著后期的優化升級還會不斷增加。
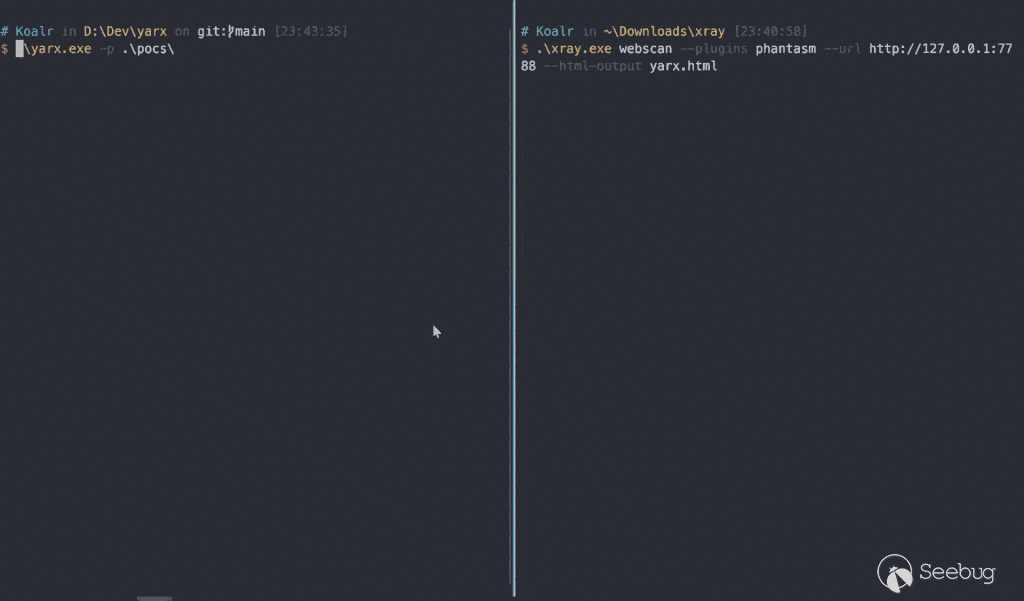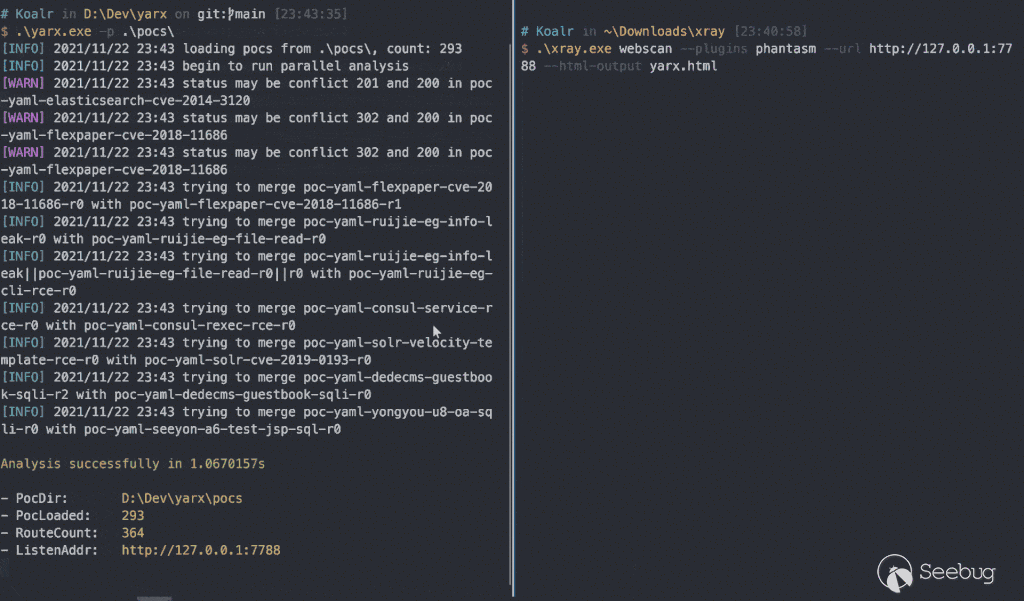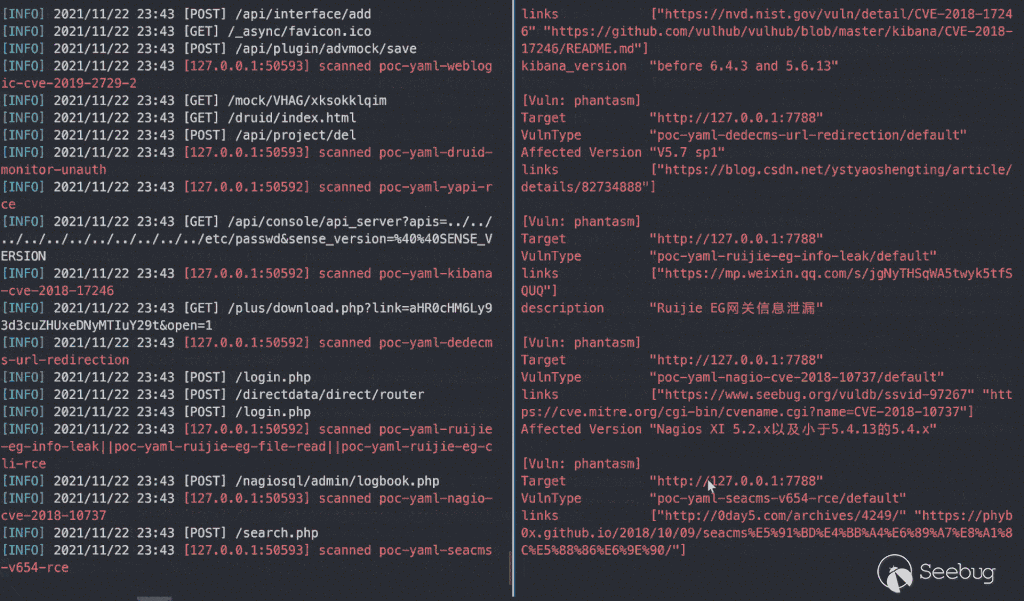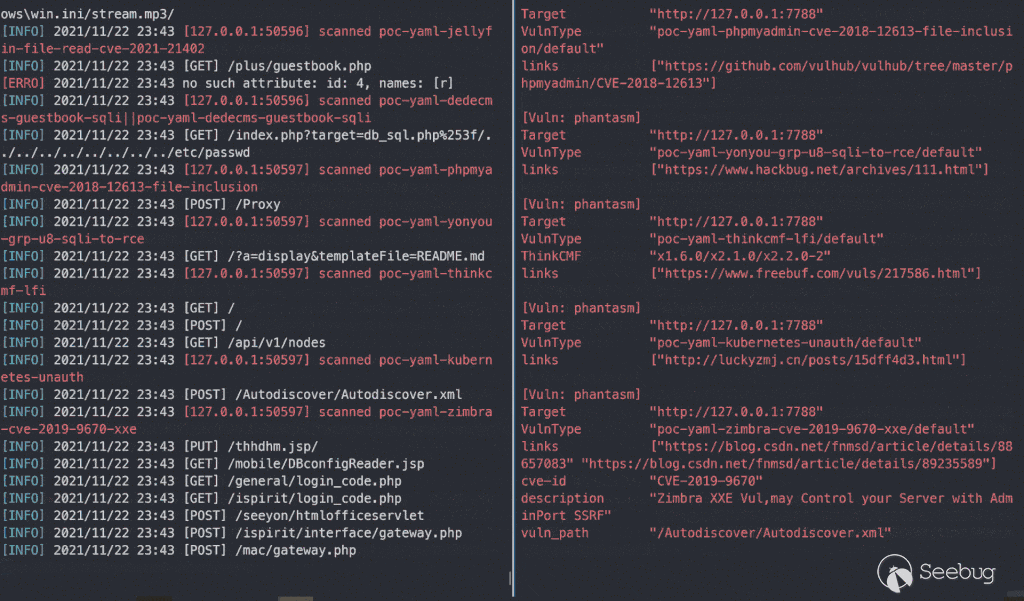
總結
我作為曾經的 xray 核心開發者做反制 xray 這種事看似有點過河拆橋,但其實 yarx 這反而有利于 xray 的發展。除了通過污染漏洞報告來 “反制” xray 外,還有至少這樣兩個有趣的用途:
-
做 xray-like 的漏掃的集成測試
可以檢查集成了 xray 的漏掃產品從 yaml 輸入到掃描出漏洞的整個流程是否按預期工作。借助 yarx 我還真發現了幾個 xray 的陳年老 bug,提了個 issue 詳情在這 Issue 1493 -
做 xray 相關的蜜罐
蜜罐類產品可以添加一個類別叫 xray-sensor,精準探測 xray 用了哪個 poc 發了什么包,感覺做成產品整個界面還挺好玩的。還有一種可行的情況是在網關處針對 xray 的掃描流量做一下轉發,網關處的流量識別可以做的粗一點,比如只支持靜態類型的 url 匹配,識別后再轉到 yarx 進行處理,這樣可以迷惑一下攻擊者。
雖然這不是真正意義上的 xray 反制,但也算是填補了常見安全工具反制的一塊拼圖,這波是利好藍隊了。另外,文中的思路其實適用于任何掃描器,比如 nuclei 之類的也都可以用類似思路。甚至如果有同學樂意可以比社區常見的掃描器都搞一搞,掃描器沒法用了才是腳本小子真正的末日(
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1773/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1773/
暫無評論