
作者:果勝
本文為作者投稿,Seebug Paper 期待你的分享,凡經采用即有禮品相送!
投稿郵箱:paper@seebug.org
威脅情報在攻防中的地位
在IoT,云計算,基于容器的彈性計算大量鋪開的趨勢面前,目前的信息資產和相關漏洞出現了爆炸式的增長。基于人工的告警響應-審計已經不可能滿足安全防御的需要。由于必須將有限的資源和工時向易于受到攻擊的薄弱環節集中。當前的安全工作已經開始逐步向情報驅動的智能安全發展。同時,對于紅隊和滲透測試人員來說,獲取更多的漏洞情報,將自己的基礎設施和工具鏈條隱藏在已知威脅情報之外也是提高行動成功率的重要措施。故而具備更強的威脅情報和反情報能力是攻防活動中的一個重點。
威脅情報的本地生產
在當前的安全市場中,國內外都已經出現了大量的威脅情報平臺和軟件供應商,整個市場已經頗為繁榮。但是在實際的安全工作中,威脅情報的應用仍然存在很多困難,許多產品難以快速的轉化為實際工作中的生產力,而往往只具備酷炫的面板。目前的實踐中,國內許多中小型企業直接放棄了威脅情報在安全中的應用,而大型互聯網公司則更傾向于自建威脅情報運營平臺。這實際上也指向了一個結論:如果不能在本地結合自身業務對互聯網威脅情報平臺的海量數據進行提取,則威脅情報的對安全工作的指導意義會大幅下降。
具體來說,威脅情報的本地生產主要包含以下內容:
-
獲取與自身資產相關的IOC(hash,ip,url....)
互聯網上有海量的IOC信息,但是其中絕大多數都與實際面臨的威脅無關,在本地生產威脅情報的第一步在于通過將安全設備中的告警信息(或其他渠道獲取的信息,如社交媒體,SRC等)匯總,并提煉其中的IOC指標,這些IOC將作為安全人員生產威脅情報的原始材料 -
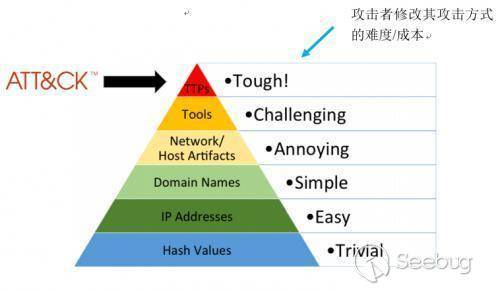
基于痛苦金字塔(Pyramid of Pain)逐步擴張IOC
痛苦金字塔是一個用于描述IOC價值的模型,該模型以從塔基到塔尖的形式,表現了IOC指標的價值高低。一般情況下,安全分析的初始階段只能獲得ip地址一類較低價值的IOC指標,并通過人工或自動分析系統(如沙箱)逐步豐富作為原始材料的IOC信息,獲取更多關聯的IOC指標
- 基于標準分享格式(MISP/STIX等)集成威脅情報
目前已經存在MISP,STIX等多個威脅情報共享標準,最終的威脅情報信息可以轉換為此類標準導入MISP等威脅情報平臺進入流通環節。
基于開源工具建立環境
當前已經存在大量開源的威脅情報工具,github提供了一個很好的源對此進行匯總,如下:
https://github.com/hslatman/awesome-threat-intelligence
但是目前大部分的開源工具的水平距離商業平臺仍有較大差距,只能滿足某一特定步驟的情報收集和處理,故而開源工具+少量開發是較為合理的輕量級方案,一般使用于以下情況:
- 資源有限的組織和企業(例如一個人的安全部)
- 獨立的安全研究人員(威脅獵人/威脅情報獎勵計劃參與者等)
- 紅隊的威脅情報采集人員
在此處使用threatingestor+cortex做一個演示
-
threatingestor
threatingestor是inquest實驗室推出的一個威脅情報采集框架,該框架可以從社交媒體,消息隊列,博客,自定義插件等渠道采集可用于威脅情報的IOC信息,并以編排劇本的方式靈活的配置采集和處理信息的具體步驟 -
cortex
cortex是大名鼎鼎的開源威脅情報分析平臺thehive項目的組成部分,該項目作為thehive平臺的后端分析引擎,可以自動的對IOC信息進行處理分析,方便安全分析人員實施其工作。目前cortex比主項目thehive具有更好的API SDK和文檔支持,更加方便與第三方代碼集成。如已經與thehive有很完善的對接方案,也可以考慮通過thehive調用cortex分析IOC。
快速安裝cortex
目前官方提供了docker鏡像方便快速的搭建cortex引擎及其依賴環境,docker-compose.yml文件如下:
version: "2"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.0
environment:
- http.host=0.0.0.0
- transport.host=0.0.0.0
- xpack.security.enabled=false
- cluster.name=hive
- script.inline=true
- thread_pool.index.queue_size=100000
- thread_pool.search.queue_size=100000
- thread_pool.bulk.queue_size=100000
cortex:
image: thehiveproject/cortex:latest
depends_on:
- elasticsearch
ports:
- "0.0.0.0:9001:9001"使用docker-compose up命令即可安裝和啟動環境,之后訪問 http://127.0.0.1
:9001 更新數據庫之后即可進入登錄頁面:

在建立非admin帳號后使用新賬戶重新登錄,開始配置分析器。在賬戶的Analyzers選項卡下配置和啟動任務所需的分析器,如圖:
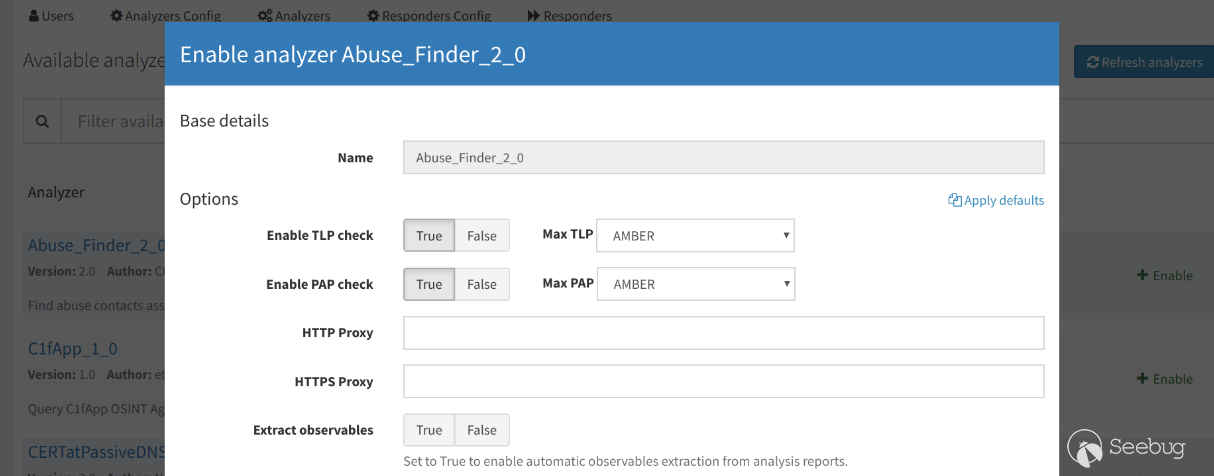
配置成功后即可在New Analysis下建立分析任務,或使用為賬戶生成的API KEY調用API進行分析任務。
備注:
主項目thehive提供的官方docker-compose.yml文件無法正常的啟動,由于主項目thehive連接cortex需要提供可用的apikey,故通過docker-compose啟動的環境thehive將無法正常連接cortex,需人工在cortex中生成key之后修改thehive容器內的配置文件并重啟服務,或者將apikey作為手工啟動thehive容器的參數才可以正常使用平臺
編寫基于消息隊列的分析服務
thehive項目官方提供了cortex4py作為cortex平臺的客戶端SDK,基于該SDK和輕量級消息隊列beanstalkd可以建立一個自動化分析服務,概念代碼如下:
python
import json
import greenstalk
from cortex4py.api import Api
from cortex4py.query import *
#連接cortex
api = Api('http://127.0.0.1:9001', '**APIKEY**')
def analyzeIOC(ipaddress):
# 獲取可用的ip分析器
ip_analyzers = api.analyzers.get_by_type('ip')
jobs = []
# 執行分析器
for analyzer in ip_analyzers:
job = api.analyzers.run_by_name(analyzer.name, {
'data': ipaddress,
'dataType': 'ip',
'tlp': 1,
'message': 'honeypot',
}, force=1)
jobs.append(job)
count = 0
while True:
#等待所有任務執行完畢(成功或失敗)
for job in jobs:
if api.jobs.get_by_id(job.id).status == 'Success':
count = count + 1
elif api.jobs.get_by_id(job.id).status == 'Failure':
count = count + 1
else:
pass
if count == len(jobs):
break
else:
count = 0
results = []
for job in jobs:
#獲取分析結果
report = api.jobs.get_report(job.id).report)
results.append(report.get('full', {}))
return results
# 待分析任務消息隊列
task_queue = greenstalk.Client('127.0.0.1', 11300,watch='cortex-task')
# 分析結果消息隊列
result_queue = greenstalk.Client('127.0.0.1', 11300,use='cortex-result')
while True:
#讀取消息隊列中等待分析的ip
job = task_queue.reserve()
task_queue.delete(job)
#開始分析任務
results = analyzeIOC(json.loads(job.body)["ip"])
for result in results:
#將結果寫入消息隊列
result_queue.put(json.dumps({'data':str(result)}))通過該樣例服務,即可從消息隊列中讀取蜜罐等安全設備或其他來源采集到的IOC,并將其提交到cortex。由cortex平臺的插件自動化的通過shodan/virustotal/Robext等多種OSINT技術豐富ip地址等較低價值的IOC,并將這些OSINT平臺的數據采集結果寫入到結果消息隊列中,通過后續步驟提取DOMAIN/URL等更高級的IOC,完成痛苦金字塔的攀爬。
建立threatingestor工作流
為了在本地自動化生產威脅情報,我們需要通過threatingestor建立一個自動化的工作流。threatingestor是一個易于配置和擴展的框架,可以通過配置文件快速自定義一個任意的工作流,可以設計一個如下的工作流:
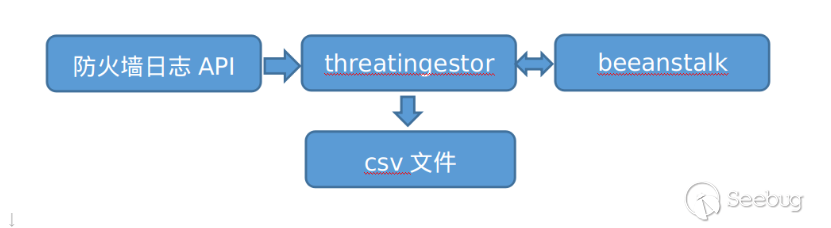
即防火墻日志->通過thretingestor提取IOC寫入beanstalk->通過自定義服務使用cortex豐富IOC->將結果寫入消息隊列->通過thretingestor分析OSINT結果并寫入csv文件。實現這個工作流的配置文件如下:
general:
#基本配置
daemon: true
sleep: 3600 #每3600s執行一次采集任務
state_path: state.db
sources:
#通過firewall采集IOC
#web模塊通過http協議采集數據并自動提取IOC
- name: firewall_source
module: web
url: http://172.17.0.3:9001/api/v1/get/data?key=********
#從beanstalk消息隊列讀取cortex平臺采集的結果
#通過OSINT豐富IOC
- name: cortex-result
module: beanstalk
paths: [data]
host: 127.0.0.1
port: 11300
queue_name: cortex-result
operators:
#制定處理cortex-result插件采集的IOC
#將結果寫入csv文件中
- name: csv
module: csv
allowed_sources: [cortex-result]
filename: output.csv
#讀取firewall提供的IOC并寫入消息隊列中
- name: cortex-task
module: beanstalk
host: 127.0.0.1
port: 11300
queue_name: cortex-task
allowed_sources: [firewall_source]
filter: is_ip #只允許ip類的IOC進入下一步流程
ip: {ipaddress}運行
threatingestor test.yml
即可使得threatingestor驅動起預先設計的工作流,部分結果如下:
IPAddress,116.*.*.186,...
Hash,0636e1e6dd371760aeaf808ed839236e73a9e74d,...
URL,http://***.xyz/,... Domain,***.xyz,...
可見整個采集-分析-存儲流程被自動化完成,cortex平臺挖掘出的IOC可用于生成安全規則或用于更多的安全分析
總結
寫作本文的目的是拋磚引玉,即證明通過開源工具建立一個輕量級的自動化威脅情報生產方案是可能的。實際上還有很多可擴展的玩法,例如基于CuckooSandbox API自動化分析蜜罐樣本,基于networkX自動繪制IOC的關聯關系等,限于篇幅在此不詳細敘述。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1210/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1210/
暫無評論