SciPy-數值計算庫?
SciPy函數庫在NumPy庫的基礎上增加了眾多的數學、科學以及工程計算中常用的庫函數。例如線性代數、常微分方程數值求解、信號處理、圖像處理、稀疏矩陣等等。由于其涉及的領域眾多、本書沒有能力對其一一的進行介紹。作為入門介紹,讓我們看看如何用SciPy進行插值處理、信號濾波以及用C語言加速計算。
最小二乘擬合?
假設有一組實驗數據(x[i], y[i]),我們知道它們之間的函數關系:y = f(x),通過這些已知信息,需要確定函數中的一些參數項。例如,如果f是一個線型函數f(x) = k*x+b,那么參數k和b就是我們需要確定的值。如果將這些參數用 p 表示的話,那么我們就是要找到一組 p 值使得如下公式中的S函數最小:
![S(\mathbf{p}) = \sum_{i=1}^m [y_i - f(x_i, \mathbf{p}) ]^2](_images/math/8da054a2d9fb73326f9fc0a3141cea13d49db11f.png)
這種算法被稱之為最小二乘擬合(Least-square fitting)。
scipy中的子函數庫optimize已經提供了實現最小二乘擬合算法的函數leastsq。下面是用leastsq進行數據擬合的一個例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | # -*- coding: utf-8 -*-
import numpy as np
from scipy.optimize import leastsq
import pylab as pl
def func(x, p):
"""
數據擬合所用的函數: A*sin(2*pi*k*x + theta)
"""
A, k, theta = p
return A*np.sin(2*np.pi*k*x+theta)
def residuals(p, y, x):
"""
實驗數據x, y和擬合函數之間的差,p為擬合需要找到的系數
"""
return y - func(x, p)
x = np.linspace(0, -2*np.pi, 100)
A, k, theta = 10, 0.34, np.pi/6 # 真實數據的函數參數
y0 = func(x, [A, k, theta]) # 真實數據
y1 = y0 + 2 * np.random.randn(len(x)) # 加入噪聲之后的實驗數據
p0 = [7, 0.2, 0] # 第一次猜測的函數擬合參數
# 調用leastsq進行數據擬合
# residuals為計算誤差的函數
# p0為擬合參數的初始值
# args為需要擬合的實驗數據
plsq = leastsq(residuals, p0, args=(y1, x))
print u"真實參數:", [A, k, theta]
print u"擬合參數", plsq[0] # 實驗數據擬合后的參數
pl.plot(x, y0, label=u"真實數據")
pl.plot(x, y1, label=u"帶噪聲的實驗數據")
pl.plot(x, func(x, plsq[0]), label=u"擬合數據")
pl.legend()
pl.show()
|
這個例子中我們要擬合的函數是一個正弦波函數,它有三個參數 A, k, theta ,分別對應振幅、頻率、相角。假設我們的實驗數據是一組包含噪聲的數據 x, y1,其中y1是在真實數據y0的基礎上加入噪聲的到了。
通過leastsq函數對帶噪聲的實驗數據x, y1進行數據擬合,可以找到x和真實數據y0之間的正弦關系的三個參數: A, k, theta。下面是程序的輸出:
>>> 真實參數: [10, 0.34000000000000002, 0.52359877559829882]
>>> 擬合參數 [-9.84152775 0.33829767 -2.68899335]
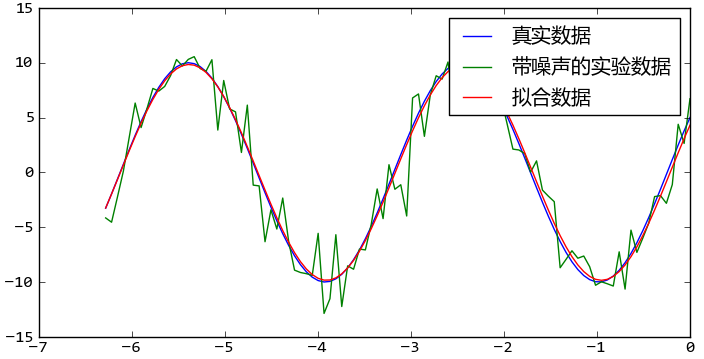
調用leastsq函數對噪聲正弦波數據進行曲線擬合
我們看到擬合參數雖然和真實參數完全不同,但是由于正弦函數具有周期性,實際上擬合參數得到的函數和真實參數對應的函數是一致的。
函數最小值?
optimize庫提供了幾個求函數最小值的算法:fmin, fmin_powell, fmin_cg, fmin_bfgs。下面的程序通過求解卷積的逆運算演示fmin的功能。
對于一個離散的線性時不變系統h, 如果它的輸入是x,那么其輸出y可以用x和h的卷積表示:
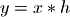
現在的問題是如果已知系統的輸入x和輸出y,如何計算系統的傳遞函數h;或者如果已知系統的傳遞函數h和系統的輸出y,如何計算系統的輸入x。這種運算被稱為反卷積運算,是十分困難的,特別是在實際的運用中,測量系統的輸出總是存在誤差的。
下面用fmin計算反卷積,這種方法只能用在很小規模的數列之上,因此沒有很大的實用價值,不過用來評價fmin函數的性能還是不錯的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | # -*- coding: utf-8 -*-
# 本程序用各種fmin函數求卷積的逆運算
import scipy.optimize as opt
import numpy as np
def test_fmin_convolve(fminfunc, x, h, y, yn, x0):
"""
x (*) h = y, (*)表示卷積
yn為在y的基礎上添加一些干擾噪聲的結果
x0為求解x的初始值
"""
def convolve_func(h):
"""
計算 yn - x (*) h 的power
fmin將通過計算使得此power最小
"""
return np.sum((yn - np.convolve(x, h))**2)
# 調用fmin函數,以x0為初始值
h0 = fminfunc(convolve_func, x0)
print fminfunc.__name__
print "---------------------"
# 輸出 x (*) h0 和 y 之間的相對誤差
print "error of y:", np.sum((np.convolve(x, h0)-y)**2)/np.sum(y**2)
# 輸出 h0 和 h 之間的相對誤差
print "error of h:", np.sum((h0-h)**2)/np.sum(h**2)
print
def test_n(m, n, nscale):
"""
隨機產生x, h, y, yn, x0等數列,調用各種fmin函數求解b
m為x的長度, n為h的長度, nscale為干擾的強度
"""
x = np.random.rand(m)
h = np.random.rand(n)
y = np.convolve(x, h)
yn = y + np.random.rand(len(y)) * nscale
x0 = np.random.rand(n)
test_fmin_convolve(opt.fmin, x, h, y, yn, x0)
test_fmin_convolve(opt.fmin_powell, x, h, y, yn, x0)
test_fmin_convolve(opt.fmin_cg, x, h, y, yn, x0)
test_fmin_convolve(opt.fmin_bfgs, x, h, y, yn, x0)
if __name__ == "__main__":
test_n(200, 20, 0.1)
|
下面是程序的輸出:
fmin
ーーーーーーーーーーー
error of y: 0.00568756699607
error of h: 0.354083287918
fmin_powell
ーーーーーーーーーーー
error of y: 0.000116114709857
error of h: 0.000258897894009
fmin_cg
ーーーーーーーーーーー
error of y: 0.000111220299615
error of h: 0.000211404733439
fmin_bfgs
ーーーーーーーーーーー
error of y: 0.000111220251551
error of h: 0.000211405138529
非線性方程組求解?
optimize庫中的fsolve函數可以用來對非線性方程組進行求解。它的基本調用形式如下:
fsolve(func, x0)
func(x)是計算方程組誤差的函數,它的參數x是一個矢量,表示方程組的各個未知數的一組可能解,func返回將x代入方程組之后得到的誤差;x0為未知數矢量的初始值。如果要對如下方程組進行求解的話:
- f1(u1,u2,u3) = 0
- f2(u1,u2,u3) = 0
- f3(u1,u2,u3) = 0
那么func可以如下定義:
def func(x):
u1,u2,u3 = x
return [f1(u1,u2,u3), f2(u1,u2,u3), f3(u1,u2,u3)]
下面是一個實際的例子,求解如下方程組的解:
- 5*x1 + 3 = 0
- 4*x0*x0 - 2*sin(x1*x2) = 0
- x1*x2 - 1.5 = 0
程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from scipy.optimize import fsolve
from math import sin,cos
def f(x):
x0 = float(x[0])
x1 = float(x[1])
x2 = float(x[2])
return [
5*x1+3,
4*x0*x0 - 2*sin(x1*x2),
x1*x2 - 1.5
]
result = fsolve(f, [1,1,1])
print result
print f(result)
|
輸出為:
[-0.70622057 -0.6 -2.5 ]
[0.0, -9.1260332624187868e-14, 5.3290705182007514e-15]
由于fsolve函數在調用函數f時,傳遞的參數為數組,因此如果直接使用數組中的元素計算的話,計算速度將會有所降低,因此這里先用float函數將數組中的元素轉換為Python中的標準浮點數,然后調用標準math庫中的函數進行運算。
在對方程組進行求解時,fsolve會自動計算方程組的雅可比矩陣,如果方程組中的未知數很多,而與每個方程有關的未知數較少時,即雅可比矩陣比較稀疏時,傳遞一個計算雅可比矩陣的函數將能大幅度提高運算速度。筆者在一個模擬計算的程序中需要大量求解近有50個未知數的非線性方程組的解。每個方程平均與6個未知數相關,通過傳遞雅可比矩陣的計算函數使計算速度提高了4倍。
雅可比矩陣
雅可比矩陣是一階偏導數以一定方式排列的矩陣,它給出了可微分方程與給定點的最優線性逼近,因此類似于多元函數的導數。例如前面的函數f1,f2,f3和未知數u1,u2,u3的雅可比矩陣如下:
![\begin{bmatrix}
\dfrac{\partial f1}{\partial u1} & \dfrac{\partial f1}{\partial u2} & \dfrac{\partial f1}{\partial u3} \\[9pt]
\dfrac{\partial f2}{\partial u1} & \dfrac{\partial f2}{\partial u2} & \dfrac{\partial f2}{\partial u3} \\[9pt]
\dfrac{\partial f3}{\partial u1} & \dfrac{\partial f3}{\partial u2} & \dfrac{\partial f3}{\partial u3} \\
\end{bmatrix}](_images/math/0e0589610ac2875dcd7d12db88259d4076bd8fe7.png)
使用雅可比矩陣的fsolve實例如下,計算雅可比矩陣的函數j通過fprime參數傳遞給fsolve,函數j和函數f一樣,有一個未知數的解矢量參數x,函數j計算非線性方程組在矢量x點上的雅可比矩陣。由于這個例子中未知數很少,因此程序計算雅可比矩陣并不能帶來計算速度的提升。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # -*- coding: utf-8 -*-
from scipy.optimize import fsolve
from math import sin,cos
def f(x):
x0 = float(x[0])
x1 = float(x[1])
x2 = float(x[2])
return [
5*x1+3,
4*x0*x0 - 2*sin(x1*x2),
x1*x2 - 1.5
]
def j(x):
x0 = float(x[0])
x1 = float(x[1])
x2 = float(x[2])
return [
[0, 5, 0],
[8*x0, -2*x2*cos(x1*x2), -2*x1*cos(x1*x2)],
[0, x2, x1]
]
result = fsolve(f, [1,1,1], fprime=j)
print result
print f(result)
|
B-Spline樣條曲線?
interpolate庫提供了許多對數據進行插值運算的函數。下面是使用直線和B-Spline對正弦波上的點進行插值的例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # -*- coding: utf-8 -*-
import numpy as np
import pylab as pl
from scipy import interpolate
x = np.linspace(0, 2*np.pi+np.pi/4, 10)
y = np.sin(x)
x_new = np.linspace(0, 2*np.pi+np.pi/4, 100)
f_linear = interpolate.interp1d(x, y)
tck = interpolate.splrep(x, y)
y_bspline = interpolate.splev(x_new, tck)
pl.plot(x, y, "o", label=u"原始數據")
pl.plot(x_new, f_linear(x_new), label=u"線性插值")
pl.plot(x_new, y_bspline, label=u"B-spline插值")
pl.legend()
pl.show()
|
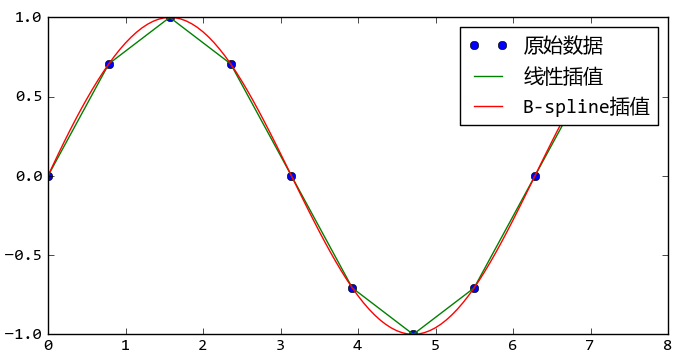
使用interpolate庫對正弦波數據進行線性插值和B-Spline插值
在這段程序中,通過interp1d函數直接得到一個新的線性插值函數。而B-Spline插值運算需要先使用splrep函數計算出B-Spline曲線的參數,然后將參數傳遞給splev函數計算出各個取樣點的插值結果。
數值積分?
數值積分是對定積分的數值求解,例如可以利用數值積分計算某個形狀的面積。下面讓我們來考慮一下如何計算半徑為1的半圓的面積,根據圓的面積公式,其面積應該等于PI/2。單位半圓曲線可以用下面的函數表示:
def half_circle(x):
return (1-x**2)**0.5
下面的程序使用經典的分小矩形計算面積總和的方式,計算出單位半圓的面積:
>>> N = 10000
>>> x = np.linspace(-1, 1, N)
>>> dx = 2.0/N
>>> y = half_circle(x)
>>> dx * np.sum(y[:-1] + y[1:]) # 面積的兩倍
3.1412751679988937
利用上述方式計算出的圓上一系列點的坐標,還可以用numpy.trapz進行數值積分:
>>> import numpy as np
>>> np.trapz(y, x) * 2 # 面積的兩倍
3.1415893269316042
此函數計算的是以x,y為頂點坐標的折線與X軸所夾的面積。同樣的分割點數,trapz函數的結果更加接近精確值一些。
如果我們調用scipy.integrate庫中的quad函數的話,將會得到非常精確的結果:
>>> from scipy import integrate
>>> pi_half, err = integrate.quad(half_circle, -1, 1)
>>> pi_half*2
3.1415926535897984
多重定積分的求值可以通過多次調用quad函數實現,為了調用方便,integrate庫提供了dblquad函數進行二重定積分,tplquad函數進行三重定積分。下面以計算單位半球體積為例說明dblquad函數的用法。
單位半球上的點(x,y,z)符合如下方程:
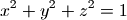
因此可以如下定義通過(x,y)坐標計算球面上點的z值的函數:
def half_sphere(x, y):
return (1-x**2-y**2)**0.5
X-Y軸平面與此球體的交線為一個單位圓,因此積分區間為此單位圓,可以考慮為X軸坐標從-1到1進行積分,而Y軸從 -half_circle(x) 到 half_circle(x) 進行積分,于是可以調用dblquad函數:
>>> integrate.dblquad(half_sphere, -1, 1,
lambda x:-half_circle(x),
lambda x:half_circle(x))
>>> (2.0943951023931988, 2.3252456653390915e-14)
>>> np.pi*4/3/2 # 通過球體體積公式計算的半球體積
2.0943951023931953
dblquad函數的調用方式為:
dblquad(func2d, a, b, gfun, hfun)
對于func2d(x,y)函數進行二重積分,其中a,b為變量x的積分區間,而gfun(x)到hfun(x)為變量y的積分區間。
半球體積的積分的示意圖如下:
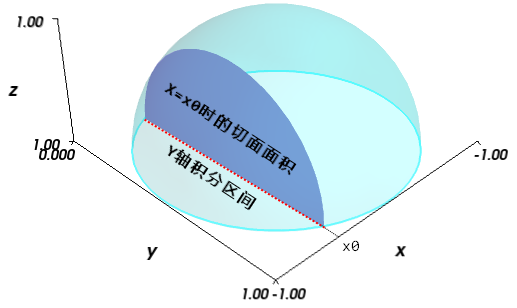
半球體積的雙重定積分示意圖
X軸的積分區間為-1.0到1.0,對于X=x0時,通過對Y軸的積分計算出切面的面積,因此Y軸的積分區間如圖中紅色點線所示。
解常微分方程組?
scipy.integrate庫提供了數值積分和常微分方程組求解算法odeint。下面讓我們來看看如何用odeint計算洛侖茲吸引子的軌跡。洛侖茲吸引子由下面的三個微分方程定義:
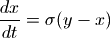
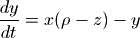
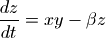
洛侖茲吸引子的詳細介紹: http://bzhang.lamost.org/website/archives/lorenz_attactor
這三個方程定義了三維空間中各個坐標點上的速度矢量。從某個坐標開始沿著速度矢量進行積分,就可以計算出無質量點在此空間中的運動軌跡。其中 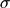 ,
, 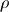 ,
, 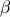 為三個常數,不同的參數可以計算出不同的運動軌跡: x(t), y(t), z(t)。 當參數為某些值時,軌跡出現餛飩現象:即微小的初值差別也會顯著地影響運動軌跡。下面是洛侖茲吸引子的軌跡計算和繪制程序:
為三個常數,不同的參數可以計算出不同的運動軌跡: x(t), y(t), z(t)。 當參數為某些值時,軌跡出現餛飩現象:即微小的初值差別也會顯著地影響運動軌跡。下面是洛侖茲吸引子的軌跡計算和繪制程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # -*- coding: utf-8 -*-
from scipy.integrate import odeint
import numpy as np
def lorenz(w, t, p, r, b):
# 給出位置矢量w,和三個參數p, r, b計算出
# dx/dt, dy/dt, dz/dt的值
x, y, z = w
# 直接與lorenz的計算公式對應
return np.array([p*(y-x), x*(r-z)-y, x*y-b*z])
t = np.arange(0, 30, 0.01) # 創建時間點
# 調用ode對lorenz進行求解, 用兩個不同的初始值
track1 = odeint(lorenz, (0.0, 1.00, 0.0), t, args=(10.0, 28.0, 3.0))
track2 = odeint(lorenz, (0.0, 1.01, 0.0), t, args=(10.0, 28.0, 3.0))
# 繪圖
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure()
ax = Axes3D(fig)
ax.plot(track1[:,0], track1[:,1], track1[:,2])
ax.plot(track2[:,0], track2[:,1], track2[:,2])
plt.show()
|
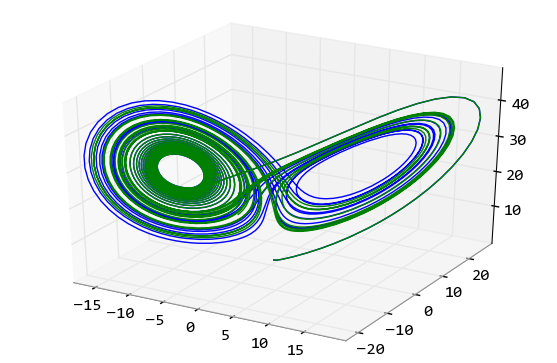
用odeint函數對洛侖茲吸引子微分方程進行數值求解所得到的運動軌跡
我們看到即使初始值只相差0.01,兩條運動軌跡也是完全不同的。
在程序中先定義一個lorenz函數,它的任務是計算出某個位置的各個方向的微分值,這個計算直接根據洛侖茲吸引子的公式得出。然后調用odeint,對微分方程求解,odeint有許多參數,這里用到的四個參數分別為:
- lorenz, 它是計算某個位移上的各個方向的速度(位移的微分)
- (0.0, 1.0, 0.0),位移初始值。計算常微分方程所需的各個變量的初始值
- t, 表示時間的數組,odeint對于此數組中的每個時間點進行求解,得出所有時間點的位置
- args, 這些參數直接傳遞給lorenz函數,因此它們都是常量
濾波器設計?
scipy.signal庫提供了許多信號處理方面的函數。在這一節,讓我們來看看如何利用signal庫設計濾波器,查看濾波器的頻率響應,以及如何使用濾波器對信號進行濾波。
假設如下導入signal庫:
>>> import scipy.signal as signal
下面的程序設計一個帶通IIR濾波器:
>>> b, a = signal.iirdesign([0.2, 0.5], [0.1, 0.6], 2, 40)
這個濾波器的通帶為0.2*f0到0.5*f0,阻帶為小于0.1*f0和大于0.6*f0,其中f0為1/2的信號取樣頻率,如果取樣頻率為8kHz的話,那么這個帶通濾波器的通帶為800Hz到2kHz。通帶的最大增益衰減為2dB,阻帶的最小增益衰減為40dB,即通帶的增益浮動在2dB之內,阻帶至少有40dB的衰減。
iirdesgin返回的兩個數組b和a, 它們分別是IIR濾波器的分子和分母部分的系數。其中a[0]恒等于1。
下面通過調用freqz計算所得到的濾波器的頻率響應:
>>> w, h = signal.freqz(b, a)
freqz返回兩個數組w和h,其中w是圓頻率數組,通過w/pi*f0可以計算出其對應的實際頻率。h是w中的對應頻率點的響應,它是一個復數數組,其幅值為濾波器的增益,相角為濾波器的相位特性。
下面計算h的增益特性,并轉換為dB度量。由于h中存在幅值幾乎為0的值,因此先用clip函數對其裁剪之后,再調用對數函數,避免計算出錯。
>>> power = 20*np.log10(np.clip(np.abs(h), 1e-8, 1e100))
通過下面的語句可以繪制出濾波器的增益特性圖,這里假設取樣頻率為8kHz:
>>> pl.plot(w/np.pi*4000, power)
在實際運用中為了測量未知系統的頻率特性,經常將頻率掃描波輸入到系統中,觀察系統的輸出,從而計算其頻率特性。下面讓我們來模擬這一過程。
為了調用chirp函數以產生頻率掃描波形的數據,首先需要產生一個等差數組代表取樣時間,下面的語句產生2秒鐘取樣頻率為8kHz的取樣時間數組:
>>> t = np.arange(0, 2, 1/8000.0)
然后調用chirp得到2秒鐘的頻率掃描波形的數據:
>>> sweep = signal.chirp(t, f0=0, t1 = 2, f1=4000.0)
頻率掃描波的開始頻率f0為0Hz,結束頻率f1為4kHz,到達4kHz的時間為2秒,使用數組t作為取樣時間點。
下面通過調用lfilter函數計算sweep波形經過帶通濾波器之后的結果:
>>> out = signal.lfilter(b, a, sweep)
lfilter內部通過如下算式計算IIR濾波器的輸出:
通過如下算式可以計算輸入為x時的濾波器的輸出,其中數組x代表輸入信號,y代表輸出信號:
![y[n] & = b[0] x[n] + b[1] x[n-1] + \cdots + b[P] x[n-P] \\
& - a[1] y[n-1] - a[2] y[n-2] - \cdots - a[Q] y[n-Q]](_images/math/8c429be55d6571ecd8bf39cf20455defe09eadcd.png)
為了和系統的增益特性圖進行比較,需要獲取輸出波形的包絡,因此下面先將輸出波形數據轉換為能量值:
>>> out = 20*np.log10(np.abs(out))
為了計算包絡,找到所有能量大于前后兩個取樣點(局部最大點)的下標:
>>> index = np.where(np.logical_and(out[1:-1] > out[:-2], out[1:-1] > out[2:]))[0] + 1
最后將時間轉換為對應的頻率,繪制所有局部最大點的能量值:
>>> pl.plot(t[index]/2.0*4000, out[index] )
下圖顯示freqz計算的頻譜和頻率掃描波得到的頻率特性,我們看到其結果是一致的。
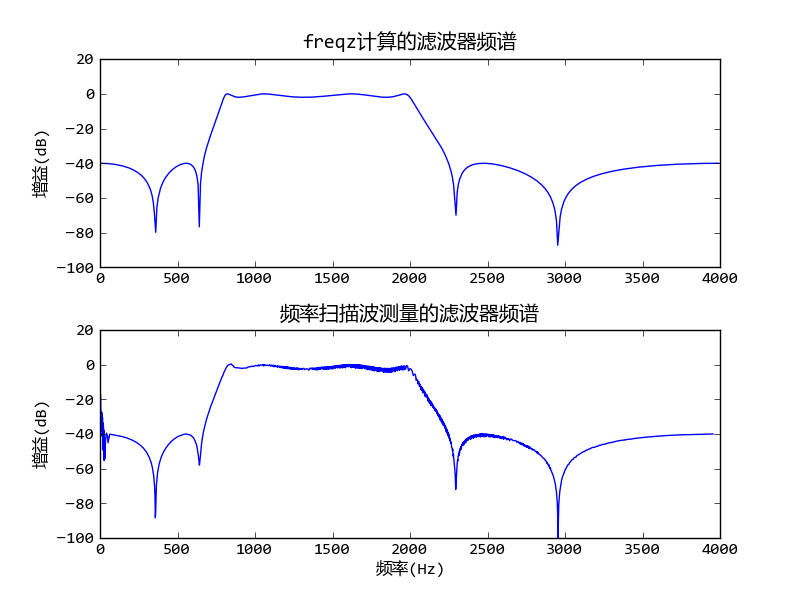
帶通IIR濾波器的頻率響應和頻率掃描波計算的結果比較
計算此圖的完整源程序請查看附錄中的 帶通濾波器設計 。
用Weave嵌入C語言?
Python作為動態語言其功能雖然強大,但是在數值計算方面有一個最大的缺點:速度不夠快。在Python級別的循環和計算的速度只有C語言程序的百分之一。因此才有了NumPy, SciPy這樣的函數庫,將高度優化的C、Fortran的函數庫進行包裝,以供Python程序調用。如果這些高度優化的函數庫無法實現我們的算法,必須從頭開始寫循環、計算的話,那么用Python來做顯然是不合適的。因此SciPy提供了快速調用C++語言程序的方法-- Weave。下面是對NumPy的數組求和的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | # -*- coding: utf-8 -*-
import scipy.weave as weave
import numpy as np
import time
def my_sum(a):
n=int(len(a))
code="""
int i;
double counter;
counter =0;
for(i=0;i<n;i++){
counter=counter+a(i);
}
return_val=counter;
"""
err=weave.inline(
code,['a','n'],
type_converters=weave.converters.blitz,
compiler="gcc"
)
return err
a = np.arange(0, 10000000, 1.0)
# 先調用一次my_sum,weave會自動對C語言進行編譯,此后直接運行編譯之后的代碼
my_sum(a)
start = time.clock()
for i in xrange(100):
my_sum(a) # 直接運行編譯之后的代碼
print "my_sum:", (time.clock() - start) / 100.0
start = time.clock()
for i in xrange(100):
np.sum( a ) # numpy中的sum,其實現也是C語言級別
print "np.sum:", (time.clock() - start) / 100.0
start = time.clock()
print sum(a) # Python內部函數sum通過數組a的迭代接口訪問其每個元素,因此速度很慢
print "sum:", time.clock() - start
|
此例子在我的電腦上的運行結果為:
my_sum: 0.0294527349146
np.sum: 0.0527649547638
sum: 9.11022322669
可以看到用Weave編譯的C語言程序比numpy自帶的sum函數還要快。而Python的內部函數sum使用數組的迭代器接口進行運算,因此速度是Python語言級別的,只有Weave版本的1/300。
weave.inline函數的第一個參數為需要執行的C++語言代碼,第二個參數是一個列表,它告訴weave要把Python中的兩個變量a和n傳遞給C++程序,注意我們用字符串表示變量名。converters.blitz是一個類型轉換器,將numpy的數組類型轉換為C++的blitz類。C++程序中的變量a不是一個數組,而是blitz類的實例,因此它使用a(i)獲得其各個元素的值,而不是用a[i]。最后我們通過compiler參數告訴weave要采用gcc為C++編譯器。如果你安裝的是python(x,y)的話,gcc(mingw32)也一起安裝好了,否則你可能需要手工安裝gcc編譯器或者微軟的Visual C++。
Note
在我的電腦上,雖然安裝了Visual C++ 2008 Express,但仍然提示找不到合適的Visual C++編譯器。似乎必須使用編譯Python的編譯器版本。因此還是用gcc來的方便。
本書的進階部分還會對weave進行詳細介紹。這段程序先給了我們一個定心丸:你再也不必擔心Python的計算速度不夠快了。