
作者:Spoock
來源:https://blog.spoock.com/2019/05/26/netstat-learn/
說明
估計平時大部分人都是通過netstat來查看網絡狀態,但是事實是netstat已經逐漸被其他的命令替代,很多新的Linux發行版本中很多都不支持了netstat。以ubuntu 18.04為例來進行說明:
~ netstat
zsh: command not found: netstat按照difference between netstat and ss in linux?這篇文章的說法,
NOTE This program is obsolete. Replacement for netstat is ss. Replacement for netstat -r is ip route. Replacement for netstat -i is ip -s link. Replacement for netstat -g is ip maddr.
中文含義就是:netstat已經過時了,netstat的部分命令已經被ip這個命令取代了,當然還有更為強大的ss。
ss命令用來顯示處于活動狀態的套接字信息。ss命令可以用來獲取socket統計信息,它可以顯示和netstat類似的內容。但ss的優勢在于它能夠顯示更多更詳細的有關TCP和連接狀態的信息,而且比netstat更快速更高效。netstat的原理顯示網絡的原理僅僅只是解析/proc/net/tcp,所以如果服務器的socket連接數量變得非常大,那么通過netstat執行速度是非常慢。而ss采用的是通過tcp_diag的方式來獲取網絡信息,tcp_diag通過netlink的方式從內核拿到網絡信息,這也是ss更高效更全面的原因。
下圖就展示了ss和nestat在監控上面的區別。
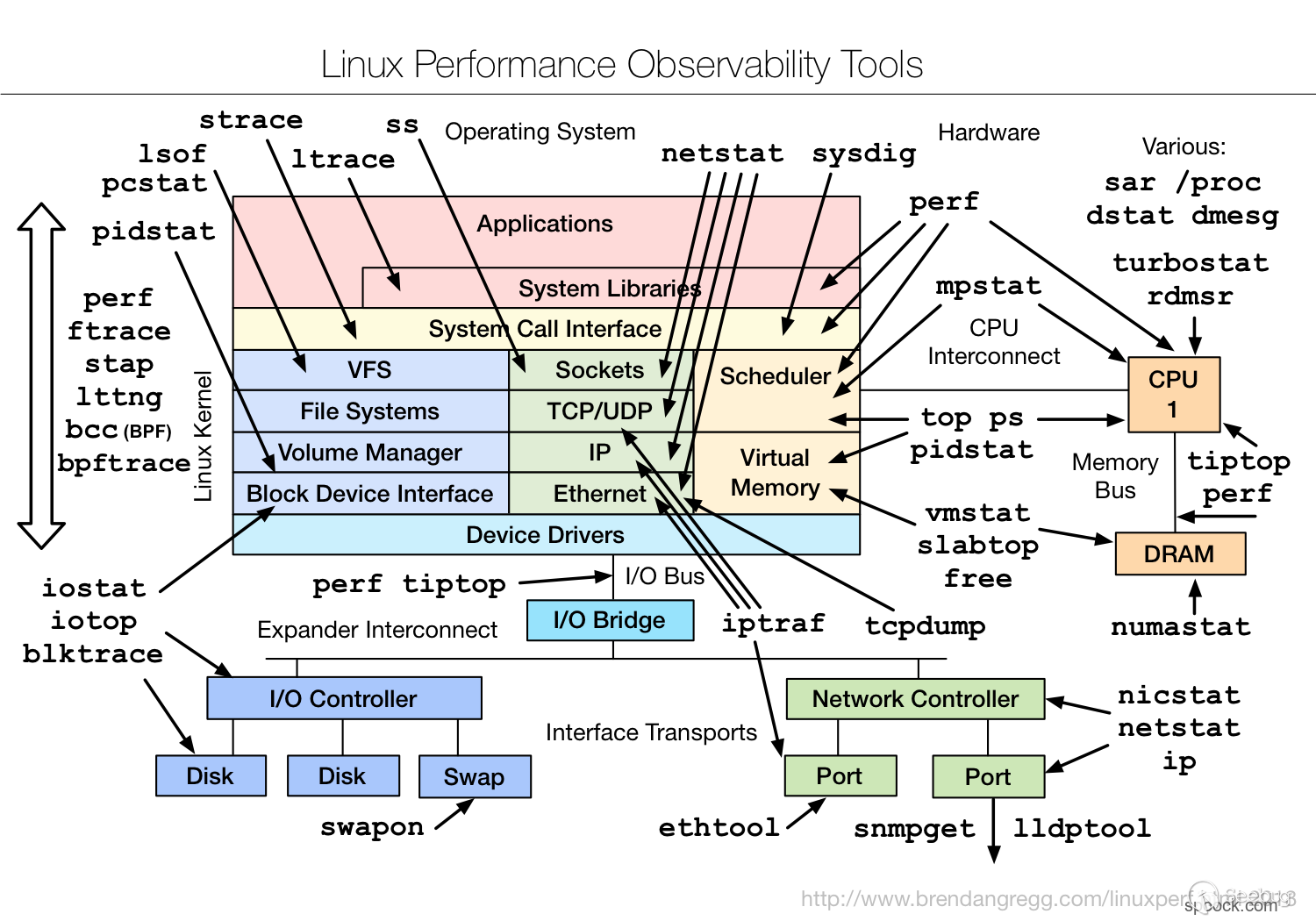
ss是獲取的socket的信息,而netstat是通過解析/proc/net/下面的文件來獲取信息包括Sockets,TCP/UDP,IP,Ethernet信息。
netstat和ss的效率的對比,找同一臺機器執行:
time ss
........
real 0m0.016s
user 0m0.001s
sys 0m0.001s
--------------------------------
time netstat
real 0m0.198s
user 0m0.009s
sys 0m0.011sss明顯比netstat更加高效.
netstat簡介
netstat是在net-tools工具包下面的一個工具集,net-tools提供了一份net-tools的源碼,我們通過net-tools來看看netstat的實現原理。
netstat源代碼調試
下載net-tools之后,導入到Clion中,創建CMakeLists.txt文件,內容如下:
cmake_minimum_required(VERSION 3.13)
project(test C)
set(BUILD_DIR .)
#add_executable()
add_custom_target(netstat command -c ${BUILD_DIR})修改根目錄下的Makefile中的59行的編譯配置為:
CFLAGS ?= -O0 -g3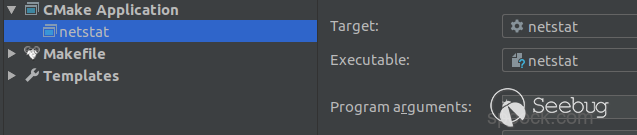
按照如上圖設置自己的編譯選項
以上就是搭建netstat的源代碼調試過程。
tcp show
在netstat不需要任何參數的情況,程序首先會運行到2317行的tcp_info()
#if HAVE_AFINET
if (!flag_arg || flag_tcp) {
i = tcp_info();
if (i)
return (i);
}
if (!flag_arg || flag_sctp) {
i = sctp_info();
if (i)
return (i);
}
.........跟蹤進入到tcp_info():
static int tcp_info(void)
{
INFO_GUTS6(_PATH_PROCNET_TCP, _PATH_PROCNET_TCP6, "AF INET (tcp)",
tcp_do_one, "tcp", "tcp6");
}參數的情況如下:
-
_PATH_PROCNET_TCP,在
lib/pathnames.h中定義,是#define _PATH_PROCNET_TCP "/proc/net/tcp" -
_PATH_PROCNET_TCP6, 在
lib/pathnames.h中定義, 是#define _PATH_PROCNET_TCP6 "/proc/net/tcp6" -
tcp_do_one,函數指針,位于1100行,部分代碼如下:
static void tcp_do_one(int lnr, const char *line, const char *prot)
{
unsigned long rxq, txq, time_len, retr, inode;
int num, local_port, rem_port, d, state, uid, timer_run, timeout;
char rem_addr[128], local_addr[128], timers[64];
const struct aftype *ap;
struct sockaddr_storage localsas, remsas;
struct sockaddr_in *localaddr = (struct sockaddr_in *)&localsas;
struct sockaddr_in *remaddr = (struct sockaddr_in *)&remsas;
......tcp_do_one()就是用來解析/proc/net/tcp和/proc/net/tcp6每一行的含義的,關于/proc/net/tcp的每一行的含義可以參考之前寫過的osquery源碼解讀之分析process_open_socket中的擴展章節。
INFO_GUTS6
#define INFO_GUTS6(file,file6,name,proc,prot4,prot6) \
char buffer[8192]; \
int rc = 0; \
int lnr = 0; \
if (!flag_arg || flag_inet) { \
INFO_GUTS1(file,name,proc,prot4) \
} \
if (!flag_arg || flag_inet6) { \
INFO_GUTS2(file6,proc,prot6) \
} \
INFO_GUTS3INFO_GUTS6采用了#define的方式進行定義,最終根據是flag_inet(IPv4)或者flag_inet6(IPv6)的選項分別調用不同的函數,我們以INFO_GUTS1(file,name,proc,prot4)進一步分析。
INFO_GUTS1
#define INFO_GUTS1(file,name,proc,prot) \
procinfo = proc_fopen((file)); \
if (procinfo == NULL) { \
if (errno != ENOENT && errno != EACCES) { \
perror((file)); \
return -1; \
} \
if (!flag_noprot && (flag_arg || flag_ver)) \
ESYSNOT("netstat", (name)); \
if (!flag_noprot && flag_arg) \
rc = 1; \
} else { \
do { \
if (fgets(buffer, sizeof(buffer), procinfo)) \
(proc)(lnr++, buffer,prot); \
} while (!feof(procinfo)); \
fclose(procinfo); \
}rocinfo = proc_fopen((file))獲取/proc/net/tcp的文件句柄fgets(buffer, sizeof(buffer), procinfo)解析文件內容并將每一行的內容存儲在buffer中(proc)(lnr++, buffer,prot),利用(proc)函數解析buffer。(proc)就是前面說明的tcp_do_one()函數
tcp_do_one
以" 14: 020110AC:B498 CF0DE1B9:4362 06 00000000:00000000 03:000001B2 00000000 0 0 0 3 0000000000000000這一行為例來說明tcp_do_one()函數的執行過程。
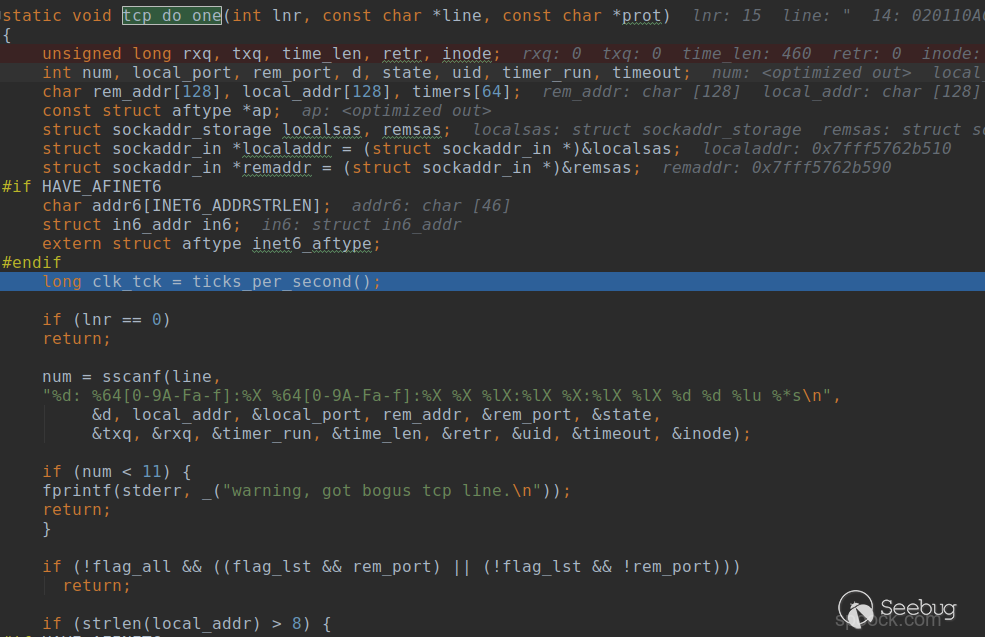
由于分析是Ipv4,所以會跳過#if HAVE_AFINET6這段代碼。之后執行:
num = sscanf(line,
"%d: %64[0-9A-Fa-f]:%X %64[0-9A-Fa-f]:%X %X %lX:%lX %X:%lX %lX %d %d %lu %*s\n",
&d, local_addr, &local_port, rem_addr, &rem_port, &state,
&txq, &rxq, &timer_run, &time_len, &retr, &uid, &timeout, &inode);
if (num < 11) {
fprintf(stderr, _("warning, got bogus tcp line.\n"));
return;
}解析數據,并將每一列的數據分別填充到對應的字段上面。分析一下其中的每個字段的定義:
char rem_addr[128], local_addr[128], timers[64];
struct sockaddr_storage localsas, remsas;
struct sockaddr_in *localaddr = (struct sockaddr_in *)&localsas;
struct sockaddr_in *remaddr = (struct sockaddr_in *)&remsas;在Linux中sockaddr_in和sockaddr_storage的定義如下:
struct sockaddr {
unsigned short sa_family; // address family, AF_xxx
char sa_data[14]; // 14 bytes of protocol address
};
struct sockaddr_in {
short int sin_family; /* Address family */
unsigned short int sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
unsigned char sin_zero[8]; /* Same size as struct sockaddr */
};
/* Internet address. */
struct in_addr {
uint32_t s_addr; /* address in network byte order */
};
struct sockaddr_storage {
sa_family_t ss_family; // address family
// all this is padding, implementation specific, ignore it:
char __ss_pad1[_SS_PAD1SIZE];
int64_t __ss_align;
char __ss_pad2[_SS_PAD2SIZE];
};之后代碼繼續執行:
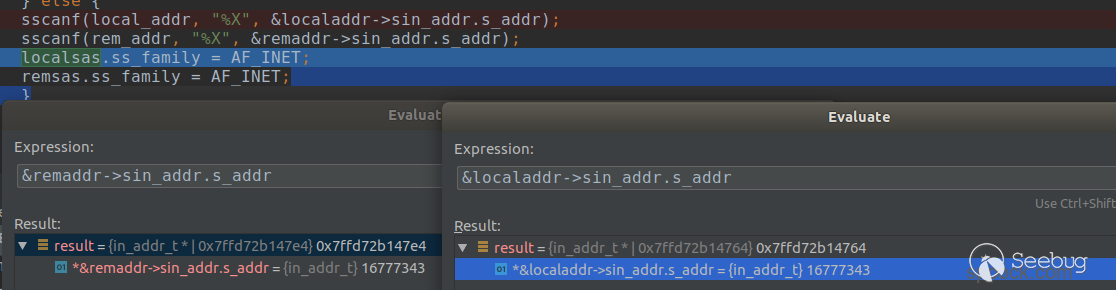
sscanf(local_addr, "%X", &localaddr->sin_addr.s_addr);
sscanf(rem_addr, "%X", &remaddr->sin_addr.s_addr);
localsas.ss_family = AF_INET;
remsas.ss_family = AF_INET;將local_addr使用sscanf(,"%X")得到對應的十六進制,保存到&localaddr->sin_addr.s_addr(即in_addr結構體中的s_addr)中,同理&remaddr->sin_addr.s_addr。運行結果如下所示:
addr_do_one
addr_do_one(local_addr, sizeof(local_addr), 22, ap, &localsas, local_port, "tcp");
addr_do_one(rem_addr, sizeof(rem_addr), 22, ap, &remsas, rem_port, "tcp");程序繼續執行,最終會執行到addr_do_one()函數,用于解析本地IP地址和端口,以及遠程IP地址和端口。
static void addr_do_one(char *buf, size_t buf_len, size_t short_len, const struct aftype *ap,
const struct sockaddr_storage *addr,
int port, const char *proto
)
{
const char *sport, *saddr;
size_t port_len, addr_len;
saddr = ap->sprint(addr, flag_not & FLAG_NUM_HOST);
sport = get_sname(htons(port), proto, flag_not & FLAG_NUM_PORT);
addr_len = strlen(saddr);
port_len = strlen(sport);
if (!flag_wide && (addr_len + port_len > short_len)) {
/* Assume port name is short */
port_len = netmin(port_len, short_len - 4);
addr_len = short_len - port_len;
strncpy(buf, saddr, addr_len);
buf[addr_len] = '\0';
strcat(buf, ":");
strncat(buf, sport, port_len);
} else
snprintf(buf, buf_len, "%s:%s", saddr, sport);
}saddr = ap->sprint(addr, flag_not & FLAG_NUM_HOST);這個表示是否需要將addr轉換為域名的形式。由于addr值是127.0.0.1,轉換之后得到的就是localhost,其中FLAG_NUM_HOST的就等價于--numeric-hosts的選項。sport = get_sname(htons(port), proto, flag_not & FLAG_NUM_PORT);,port無法無法轉換,其中的FLAG_NUM_PORT就等價于--numeric-ports這個選項。!flag_wide && (addr_len + port_len > short_len這個代碼的含義是判斷是否需要對IP和PORT進行截斷。其中flag_wide的等同于-W, --wide don't truncate IP addresses。而short_len長度是22.snprintf(buf, buf_len, "%s:%s", saddr, sport);,將IP:PORT賦值給buf.
output
最終程序執行
printf("%-4s %6ld %6ld %-*s %-*s %-11s",
prot, rxq, txq, (int)netmax(23,strlen(local_addr)), local_addr, (int)netmax(23,strlen(rem_addr)), rem_addr, _(tcp_state[state]));按照制定的格式解析,輸出結果
finish_this_one
最終程序會執行finish_this_one(uid,inode,timers);.
static void finish_this_one(int uid, unsigned long inode, const char *timers)
{
struct passwd *pw;
if (flag_exp > 1) {
if (!(flag_not & FLAG_NUM_USER) && ((pw = getpwuid(uid)) != NULL))
printf(" %-10s ", pw->pw_name);
else
printf(" %-10d ", uid);
printf("%-10lu",inode);
}
if (flag_prg)
printf(" %-" PROGNAME_WIDTHs "s",prg_cache_get(inode));
if (flag_selinux)
printf(" %-" SELINUX_WIDTHs "s",prg_cache_get_con(inode));
if (flag_opt)
printf(" %s", timers);
putchar('\n');
}(1) flag_exp 等同于-e的參數。-e, --extend display other/more information.舉例如下:
netstat -e
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode
tcp 0 0 localhost:6379 172.16.1.200:46702 ESTABLISHED redis 437788048
netstat
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 localhost:6379 172.16.1.200:46702 ESTABLISHED發現使用-e參數會多顯示User和Inode號碼。而在本例中還可以如果用戶名不存在,則顯示 uid
getpwuid
(2) flag_prg等同于-p, --programs display PID/Program name for sockets。舉例如下:
netstat -pe
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 localhost:6379 172.16.1.200:34062 ESTABLISHED redis 437672000 6017/redis-server *
netstat -e
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode
tcp 0 0 localhost:6379 172.16.1.200:46702 ESTABLISHED redis 437788048可以看到是通過prg_cache_get(inode),inode來找到對應的PID和進程信息;
(3) flag_selinux等同于-Z, --context display SELinux security context for sockets
prg_cache_get
對于上面的通過inode找到對應進程的方法非常的好奇,于是去追蹤prg_cache_get()函數的實現。
#define PRG_HASH_SIZE 211
#define PRG_HASHIT(x) ((x) % PRG_HASH_SIZE)
static struct prg_node {
struct prg_node *next;
unsigned long inode;
char name[PROGNAME_WIDTH];
char scon[SELINUX_WIDTH];
} *prg_hash[PRG_HASH_SIZE];
static const char *prg_cache_get(unsigned long inode)
{
unsigned hi = PRG_HASHIT(inode);
struct prg_node *pn;
for (pn = prg_hash[hi]; pn; pn = pn->next)
if (pn->inode == inode)
return (pn->name);
return ("-");
}在prg_hash中存儲了所有的inode編號與program的對應關系,所以當給定一個 inode 編號時就能夠找到對應的程序名稱。那么prg_hash又是如何初始化的呢?
prg_cache_load
我們使用 debug 模式,加入-p的運行參數:
程序會運行到 2289 行的prg_cache_load(); 進入到prg_cache_load()函數中.
由于整個函數的代碼較長,拆分來分析.
獲取fd
#define PATH_PROC "/proc"
#define PATH_FD_SUFF "fd"
#define PATH_FD_SUFFl strlen(PATH_FD_SUFF)
#define PATH_PROC_X_FD PATH_PROC "/%s/" PATH_FD_SUFF
#define PATH_CMDLINE "cmdline"
#define PATH_CMDLINEl strlen(PATH_CMDLINE)
if (!(dirproc=opendir(PATH_PROC))) goto fail;
while (errno = 0, direproc = readdir(dirproc)) {
for (cs = direproc->d_name; *cs; cs++)
if (!isdigit(*cs))
break;
if (*cs)
continue;
procfdlen = snprintf(line,sizeof(line),PATH_PROC_X_FD,direproc->d_name);
if (procfdlen <= 0 || procfdlen >= sizeof(line) - 5)
continue;
errno = 0;
dirfd = opendir(line);
if (! dirfd) {
if (errno == EACCES)
eacces = 1;
continue;
}
line[procfdlen] = '/';
cmdlp = NULL;(1) dirproc=opendir(PATH_PROC);errno = 0, direproc = readdir(dirproc) 遍歷/proc拿到所有的 pid
(2) procfdlen = snprintf(line,sizeof(line),PATH_PROC_X_FD,direproc→d_name); 遍歷所有的/proc/pid拿到所有進程的 fd
(3) dirfd = opendir(line); 得到/proc/pid/fd的文件句柄
獲取inode
while ((direfd = readdir(dirfd))) {
/* Skip . and .. */
if (!isdigit(direfd->d_name[0]))
continue;
if (procfdlen + 1 + strlen(direfd->d_name) + 1 > sizeof(line))
continue;
memcpy(line + procfdlen - PATH_FD_SUFFl, PATH_FD_SUFF "/",
PATH_FD_SUFFl + 1);
safe_strncpy(line + procfdlen + 1, direfd->d_name,
sizeof(line) - procfdlen - 1);
lnamelen = readlink(line, lname, sizeof(lname) - 1);
if (lnamelen == -1)
continue;
lname[lnamelen] = '\0'; /*make it a null-terminated string*/
if (extract_type_1_socket_inode(lname, &inode) < 0)
if (extract_type_2_socket_inode(lname, &inode) < 0)
continue;(1) memcpy(line + procfdlen - PATH_FD_SUFFl, PATH_FD_SUFF "/",PATH_FD_SUFFl + 1);safe_strncpy(line + procfdlen + 1, direfd->d_name, sizeof(line) - procfdlen - 1); 得到遍歷之后的fd信息,比如 /proc/pid/fd
(2) lnamelen = readlink(line, lname, sizeof(lname) - 1); 得到 fd 所指向的 link,因為通常情況下 fd 一般都是鏈接,要么是 socket 鏈接要么是 pipe 鏈接.如下所示:
$ ls -al /proc/1289/fd
total 0
dr-x------ 2 username username 0 May 25 15:45 .
dr-xr-xr-x 9 username username 0 May 25 09:11 ..
lr-x------ 1 username username 64 May 25 16:23 0 -> 'pipe:[365366]'
l-wx------ 1 username username 64 May 25 16:23 1 -> 'pipe:[365367]'
l-wx------ 1 username username 64 May 25 16:23 2 -> 'pipe:[365368]'
lr-x------ 1 username username 64 May 25 16:23 3 -> /proc/uptime(3) 通過extract_type_1_socket_inode獲取到 link 中對應的 inode 編號.
#define PRG_SOCKET_PFX "socket:["
#define PRG_SOCKET_PFXl (strlen(PRG_SOCKET_PFX))
static int extract_type_1_socket_inode(const char lname[], unsigned long * inode_p) {
/* If lname is of the form "socket:[12345]", extract the "12345"
as *inode_p. Otherwise, return -1 as *inode_p.
*/
// 判斷長度是否小于 strlen(socket:[)+3
if (strlen(lname) < PRG_SOCKET_PFXl+3) return(-1);
//函數說明:memcmp()用來比較s1 和s2 所指的內存區間前n 個字符。
// 判斷lname是否以 socket:[ 開頭
if (memcmp(lname, PRG_SOCKET_PFX, PRG_SOCKET_PFXl)) return(-1);
if (lname[strlen(lname)-1] != ']') return(-1); {
char inode_str[strlen(lname + 1)]; /* e.g. "12345" */
const int inode_str_len = strlen(lname) - PRG_SOCKET_PFXl - 1;
char *serr;
// 獲取到inode的編號
strncpy(inode_str, lname+PRG_SOCKET_PFXl, inode_str_len);
inode_str[inode_str_len] = '\0';
*inode_p = strtoul(inode_str, &serr, 0);
if (!serr || *serr || *inode_p == ~0)
return(-1);
}(4) 獲取程序對應的 cmdline
if (!cmdlp) {
if (procfdlen - PATH_FD_SUFFl + PATH_CMDLINEl >=sizeof(line) - 5)
continue;
safe_strncpy(line + procfdlen - PATH_FD_SUFFl, PATH_CMDLINE,sizeof(line) - procfdlen + PATH_FD_SUFFl);
fd = open(line, O_RDONLY);
if (fd < 0)
continue;
cmdllen = read(fd, cmdlbuf, sizeof(cmdlbuf) - 1);
if (close(fd))
continue;
if (cmdllen == -1)
continue;
if (cmdllen < sizeof(cmdlbuf) - 1)
cmdlbuf[cmdllen]='\0';
if (cmdlbuf[0] == '/' && (cmdlp = strrchr(cmdlbuf, '/')))
cmdlp++;
else
cmdlp = cmdlbuf;
}由于cmdline是可以直接讀取的,所以并不需要像讀取fd那樣借助與readlink()函數,直接通過read(fd, cmdlbuf, sizeof(cmdlbuf) - 1)即可讀取文件內容。
(5) snprintf(finbuf, sizeof(finbuf), "%s/%s", direproc->d_name, cmdlp); 拼接 pid 和 cmdlp,最終得到的就是類似與 6017/redis-server * 這樣的效果
(6) 最終程序調用 prg_cache_add(inode, finbuf, "-"); 將解析得到的inode和finbuf 加入到緩存中.
prg_cache_add
#define PRG_HASH_SIZE 211
#define PRG_HASHIT(x) ((x) % PRG_HASH_SIZE)
static struct prg_node {
struct prg_node *next;
unsigned long inode;
char name[PROGNAME_WIDTH];
char scon[SELINUX_WIDTH];
} *prg_hash[ ];
static void prg_cache_add(unsigned long inode, char *name, const char *scon)
{
unsigned hi = PRG_HASHIT(inode);
struct prg_node **pnp,*pn;
prg_cache_loaded = 2;
for (pnp = prg_hash + hi; (pn = *pnp); pnp = &pn->next) {
if (pn->inode == inode) {
/* Some warning should be appropriate here
as we got multiple processes for one i-node */
return;
}
}
if (!(*pnp = malloc(sizeof(**pnp))))
return;
pn = *pnp;
pn->next = NULL;
pn->inode = inode;
safe_strncpy(pn->name, name, sizeof(pn->name));
{
int len = (strlen(scon) - sizeof(pn->scon)) + 1;
if (len > 0)
safe_strncpy(pn->scon, &scon[len + 1], sizeof(pn->scon));
else
safe_strncpy(pn->scon, scon, sizeof(pn->scon));
}
}unsigned hi = PRG_HASHIT(inode);使用 inode 整除 211 得到作為 hash 值for (pnp = prg_hash + hi; (pn = *pnp); pnp = &pn->next)由于prg_hash是一個鏈表結構,所以通過 for 循環找到鏈表的結尾;pn = *pnp;pn->next = NULL;pn->inode = inode;safe_strncpy(pn->name, name, sizeof(pn→name));為新的 inode 賦值并將其加入到鏈表的末尾;
所以prg_node是一個全局變量,是一個鏈表結果,保存了 inode 編號與pid/cmdline之間的對應關系;
prg_cache_get
static const char *prg_cache_get(unsigned long inode)
{
unsigned hi = PRG_HASHIT(inode);
struct prg_node *pn;
for (pn = prg_hash[hi]; pn; pn = pn->next)
if (pn->inode == inode)
return (pn->name);
return ("-");
}分析完畢 prg_cache_add() 之后,看 prg_cache_get() 就很簡單了.
unsigned hi = PRG_HASHIT(inode);通過 inode 號拿到 hash 值for (pn = prg_hash[hi]; pn; pn = pn->next)遍歷 prg_hash 鏈表中的每一個節點,如果遍歷的 inode 與目標的 inode 相符就返回對應的信息。
總結
通過對 netstat 的一個簡單的分析,可以發現其實 netstat 就是通過遍歷 /proc 目錄下的目錄或者是文件來獲取對應的信息。如果在一個網絡進程頻繁關閉打開關閉,那么使用 netstat 顯然是相當耗時的。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/934/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/934/
暫無評論