
出處:2017 IEEE Symposium on Security and Privacy (SP)
作者:Najmeh Miramirkhani, Mahathi Priya Appini, Nick Nikiforakis, Michalis Polychronakis
單位:Stony Brook University
資料:Paper
譯者:Z3R0YU
譯者博客:http://zeroyu.xyz/
1.Abstract & INTRODUCTION
動態惡意代碼分析系統通過將每個樣本加載到稱為沙箱的大量儀器環境中來操作,并以不同的粒度級別(例如,I/O活動,系統調用,機器指令)監視其操作。 惡意軟件沙箱通常使用API hooking機制、CPU仿真器、虛擬機、甚至是專用的裸機主機來構建。
攻擊者角度:
- 使用打包、多態以及其他代碼混淆技術規避基于靜態代碼分析的惡意軟件掃描技術;
- 在惡意軟件中加入一定的“環境感知能力”來規避惡意軟件沙箱環境的分析(在發現身處沙箱環境后采用直接崩潰或者展示“良性”行為)。
防御者角度:
- 一般而言用實際值替換分析環境的特有屬性并隱藏檢測工具,來嘗試避免被惡意軟件感知;
- 針對使用仿真或者虛擬技術的產品而言,使用清除特定的驅動程序、進程以及其它虛擬技術指示器來實現防規避;
- 使用裸機(在進行一定的隔離后,直接使用物理計算機)。
防御者角度的問題缺陷:
- 用于分析的操作系統幾乎是原始狀態的;
- 每次進行過二進制分析之后就會將系統回滾至最初狀態(瀏覽器記錄、系統日志等信息均被回滾)。
PS:以上內容之所以說是缺陷,是因為真實環境中用戶不可能主動去將”緩存”(廣義緩存,泛指日志、注冊表等)的記錄進行回滾或者初始化。
因此在本文中作者提出了一種利用操作系統“wear and tear”(使用痕跡的含義,后文簡稱為磨損)和“aging”(使用年份的含義,后文簡稱為老化)的特征來規避sandbox(惡意軟件沙箱環境)的方法。
本文的兩項研究成果:
- 構建決策樹模型,使惡意軟件穩定地避免所有經過測試的沙箱的準確率提升至92.86%;
- 構建的統計模型可以根據系統使用指標預測系統的年齡,并可用于將現有的人造沙箱“老化”到所需的年限范圍。
BACKGROUND AND RELATED WORK
A. Virtualization and Instrumentation Artifacts
- 防御者D: 使用系統仿真器和虛擬機構建惡意軟件沙箱十分方便
- 攻擊者A: 使用靜態啟發式檢查某些系統屬性,例如特定于VM的設備驅動程序和硬件配置,固定標識符(包括MAC地址),IMEI(用于移動惡意軟件分析系統),用戶/主機名,VM特定加載的模塊和流程(例如VMware的VMware Tools)和注冊表項等
- 防御者D: 配置動態分析系統時以避免出現期望值和配置
- 攻擊者A: 這對虛擬化指令的時序屬性、運行時使用小代碼片段等底層屬性作用不大
B. Environmental and User Interaction Artifacts
防御者D: 我的兩種方案:
- 在多個不同的分析系統上運行每個樣本來檢測惡意軟件的“分裂個性”;
- 避免完全使用仿真或虛擬化,并選擇“裸機”系統來保持分析環境的真實性。
攻擊者A: 目前虛擬化技術的廣泛使用,應當認為VM和非VM是具有同樣的感染價值的,從而減少對VM檢測技巧的使用,轉而采取如下幾種啟發式方法:
- 檢查鼠標光標是否在屏幕中央保持靜止;
- 是否存在“最近打開文件”;
- 異常低數量的進程;
- 不受限制的互聯網連接,并嘗試解析已知的不存在的域名(比如WannaCry)。
防御者D: 我的兩種對策:
- 模擬用戶行為;
- 暴露更真實的網絡環境
防御者D對策的缺陷: 系統正常使用而預計會發生磨損和老化特征未被考慮。
C. Sandbox Fingerprinting
SandFinger: 使用移動設備屬性來作為沙箱指紋來規避Google的Bouncer沙箱。
AVLeak: 使用側信道的方式捕獲AV引擎中的指紋。
SandPrint: 提取Windows沙箱中的硬件配置參數,惡意軟件樣本調用機制的特征,可執行文件的文件名等特征進行聚類分析,進而識別沙箱。
如果沙箱操作員將沙箱的特征值進行多樣化處理,致使是指紋失效。那么攻擊者下一步會考慮怎么方法進行規避? 這種方式就是本文中所提到的真實系統才具有的“磨損”和“老化”特征。
III. WEAR AND TEAR ARTIFACTS
文中選用的artifact的特點: 惡意軟件可以輕松探測
artifact的選擇策略: 哪些在系統的正常使用中會被影響
A. Probing for Artifacts while Preserving User Privacy
從artifact地選擇上來看可以分為兩種:一種是直接源于用戶活動;另一種是來自系統活動(用戶活動的間接表現)。
直接來源是針對用戶行為的定性指標:
- 文檔文件夾是否包含具有預期文件擴展名的合理數量的文件;
- 檢查流行文檔查看應用程序中最近打開的文檔;
- 最近鍵入的在線搜索引擎查詢;
- 系統范圍的搜索查詢
- 即時消息;
- 電子郵件消息內容 但是這些將會對用戶的隱私造成侵犯,所以本文的方案將使用間接來源(比如:統計cookie、訪問的URL數量等方式)
B. Artifact Categories
本文主要針對Windows操作系統進行研究,所以采用的artifact類別集合如下表所示:
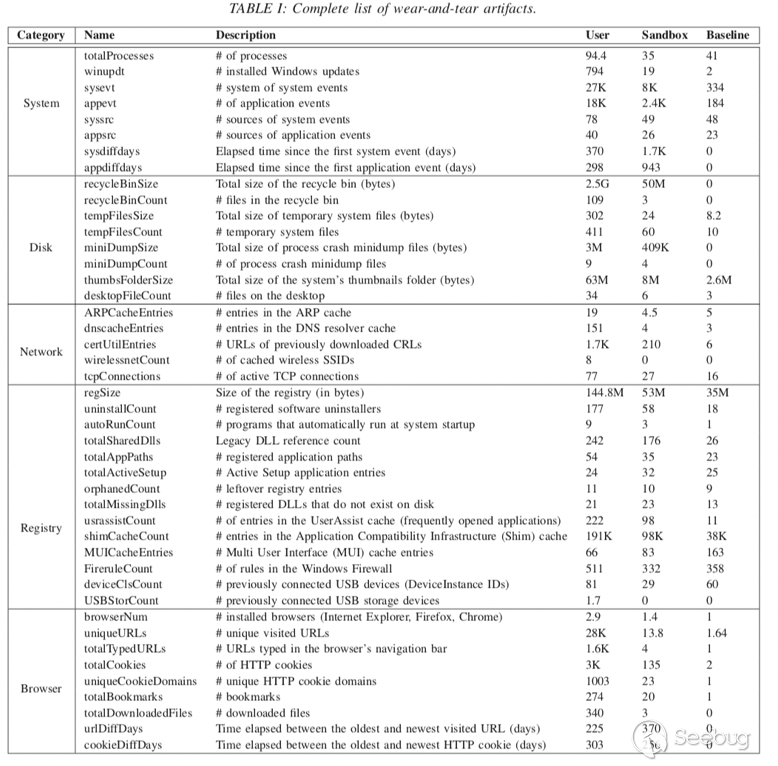
IV. DATA COLLECTION
A. Probe Tool Implementation
為了從真實用戶系統和惡意軟件沙箱中收集以上類別的artifact數據集,作者實現了一個只使用系統API、不需要安裝并且兼容Windows XP到Windows 10的探針程序。這個程序主要有以下幾個特點:
- 使用HTTPS信道傳輸收集到的artifact數據防止沙箱攔截請求;
- 收集一些BIOS供應商等其他信息用于VM啟發式檢測,來去除用戶集中可能存在的VM結果集;
- 唯一的嵌入式ID來識別同一供應商的多次提交(一些砂箱會將程序放在多個不同的環境中進行動態分析,進而檢測其行為);
- 基于操作系統安裝日期,Windows版本,BIOS供應商等信息的組合來區分不同的操作系統。
B. IRB Approval and User Involvement
這部分主要講述作者在申請IRB批準,從而讓真實用戶參與進這個項目中。
C. Data Collection
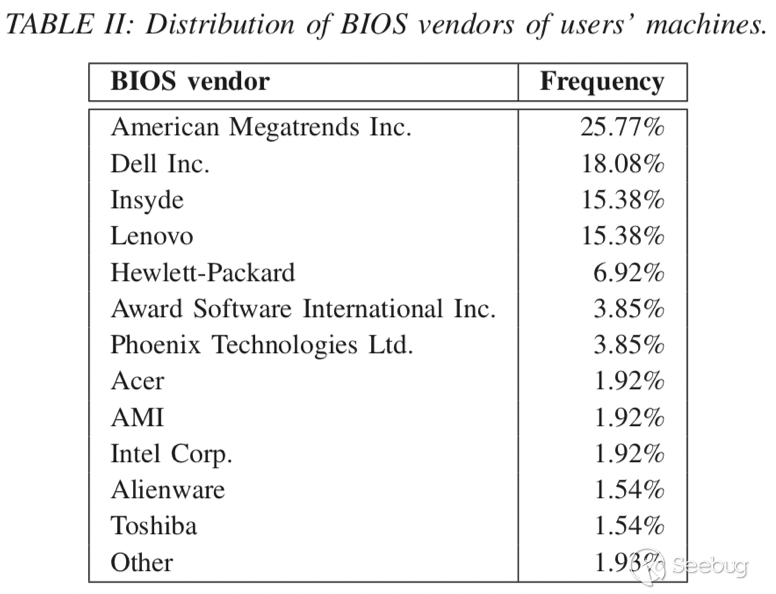
第一個數據集(Dreal)-> 270個真實用戶機器,其中有89.4%是Amazon Mechanical Turk workers。國家分布為美國(44%),印度(18%),GB(10%),CA(8%),NL(1%),PK (1%),RU(1%)和其他28個頻率低于1%的國家/地區(這種國家分析代表了從發達國家到發展中國家的計算機使用磨損特性)。表II中顯示了用戶系統的BIOS供應商分布。
PS:后面作者發現Amazon Mechanical Turk workers是一種跟搜索引擎相結合的沙箱,因此將這一部分的數據標記為“crawlers”并合并到后面的沙箱數據集中。
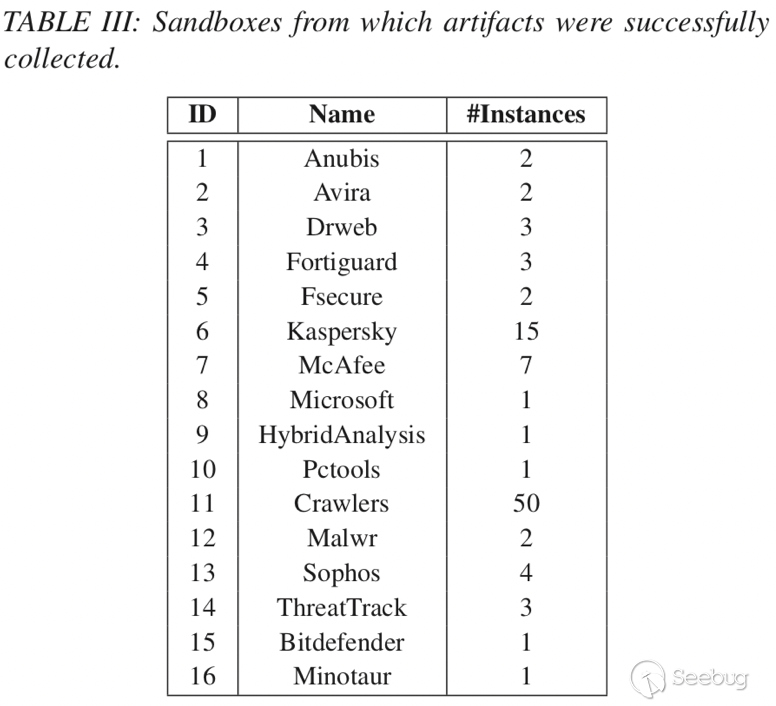
第二個數據集(Dsand)-> 來自15個可以收集到信息的惡意軟件沙箱,表III是沙箱與對應探針回收的信息。
PS:有的沙箱環境會在底層使用不同版本的操作系統來分別進行分析。
第三個數據集(Dbase)-> 基準數據集,數據來自多個全新安裝的Microsoft Windows版本(包括Azure和AWS提供的云Windows服務器)。
D. Dataset Statistics
表IV顯示了我們三個收集的數據集中不同Microsoft Windows版本的數量。(可以看出沙箱的系統分布與真實用戶的是不相同的)。
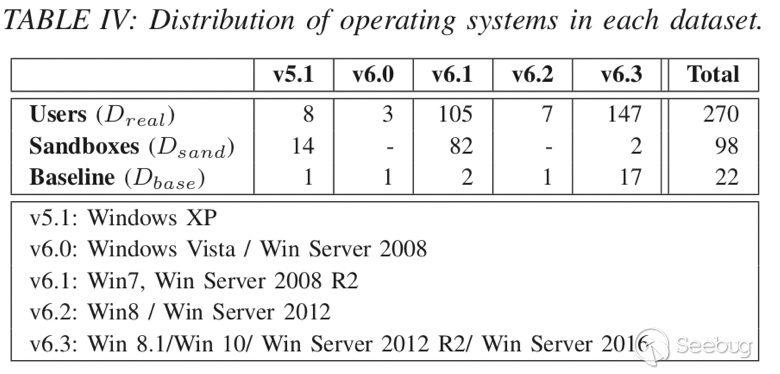
圖1顯示了三個數據集(Dreal,Dsand和Dbase)中每個磨損artifact值的分布。從中可以看到:1.大多數artifact在真實用戶系統中的值大于沙箱和基線中的值,因此可以用來區分真實用戶和沙箱;2.真實用戶的artifact值分布更寬,因此可以用來預測系統年齡。
PS: 可以看到沙箱的appdiffdays和sysdiffdays值比真實用戶高很多,因此沙箱系統一般比真實用戶系統“老化”程度更高。
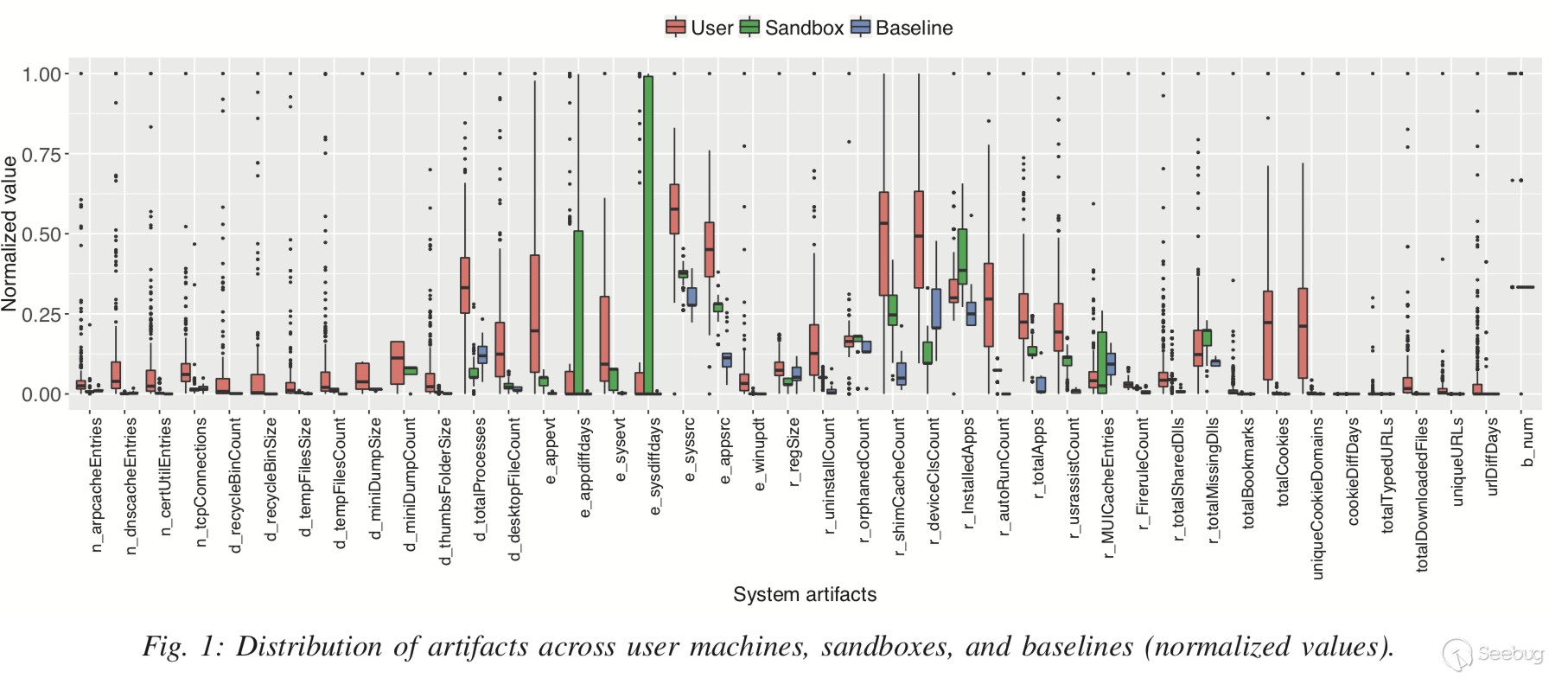
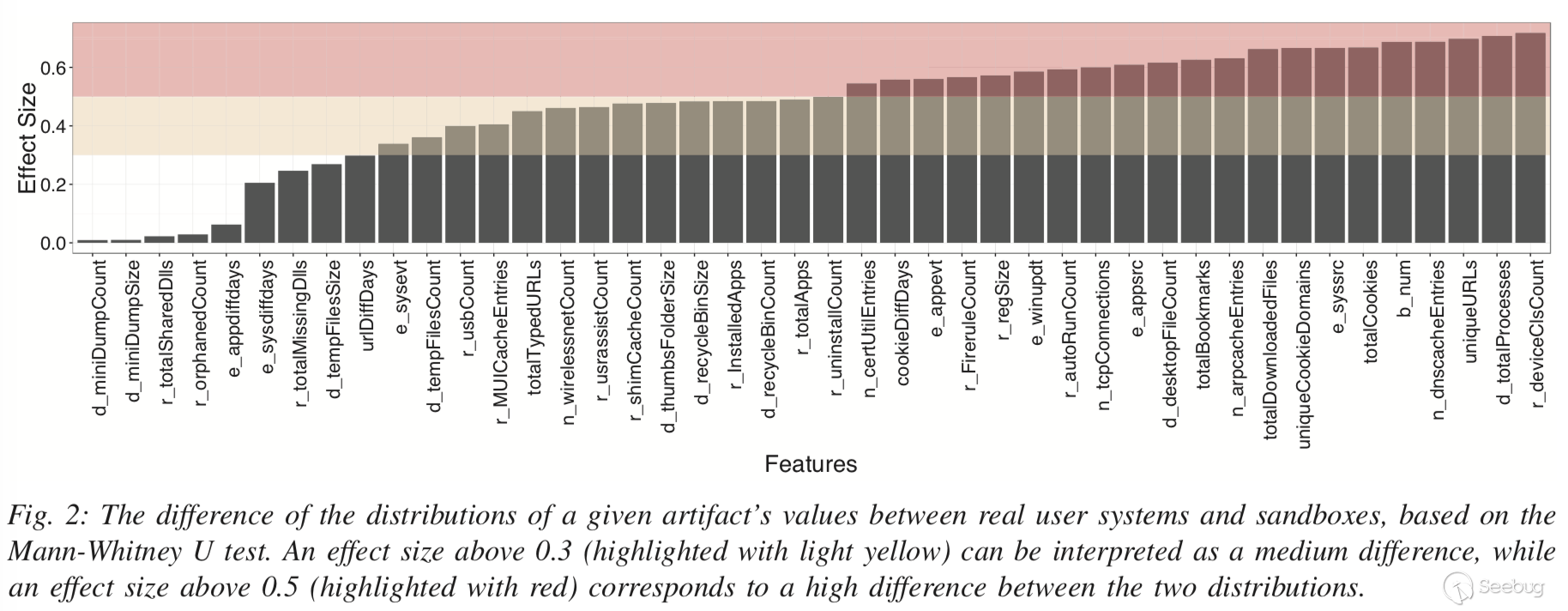
圖2顯示了Mann-Whitney U檢驗顯示的Dreal和Dsand分布之間差異的影響大小。0.3和0.5之間的效果被認為是“中等”效應的特征,而高于0.5的效應被認為是“強”效應。
V. EVADING MALWARE SANDBOXES
以上的統計信息說明了作者所選用的artifact是可以作為特征來分辨沙箱的,因此接下來將使用有監督機器學習方式,訓練決策樹模型來進一步完成對沙箱的規避工作。
A. Setup and Classifier
- 使用決策樹模型。因為決策樹模型可以表現為一系列的if-else語句,從而將惡意軟件的整體足跡保持在最小。
- 計算皮爾森相關系數(r)來檢查特征對的相關性。雖然有4對特征具有很強的相關性(r> 0.7),但是為了盡可能的規避所有沙箱,作者還是采用了所有的特征。
- 訓練集:49個沙箱環境實例,22個新安裝操作系統的實例,71個真實用戶實例;測試集:剩余的49個沙箱環境實例,49個真實用戶隨機樣本。
- 使用10-trial adaptive boosting算法(創建多個樹,每個樹專注改進前一棵樹的結果)和adaptive boosting決策樹算法(覆蓋單棵樹不能到達的邊界)來提升分類器準確性。
- 指定成本矩陣減少漏報的出現(原則是寧可不感染到某些真實用戶,也盡量不能被沙箱捕獲)。
PS: FP 誤報->沒有感染真實用戶主機;FN 漏報->嘗試感染沙箱
B. Evaluation
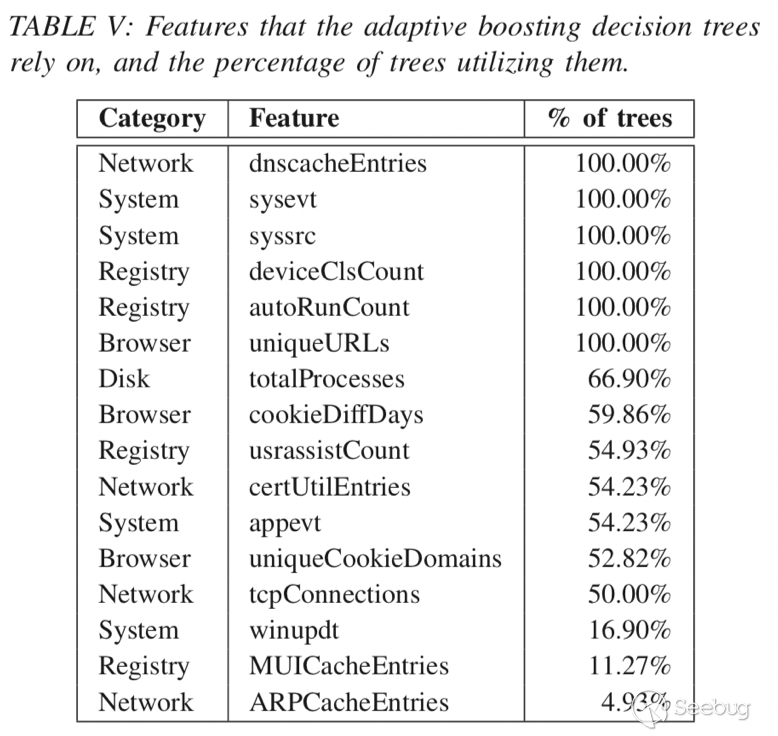
模型在測試集上達到了92.86%的準確率,假陰性率(FNR)為4.08%,假陽性率(FPR)為10.20%。 十個構建的樹的平均樹大小為4.6分裂,最短的樹具有3個分裂,最長的樹分裂為5個。 表V顯示了對算法最有用的功能,以及使用任何給定功能的樹的百分比。
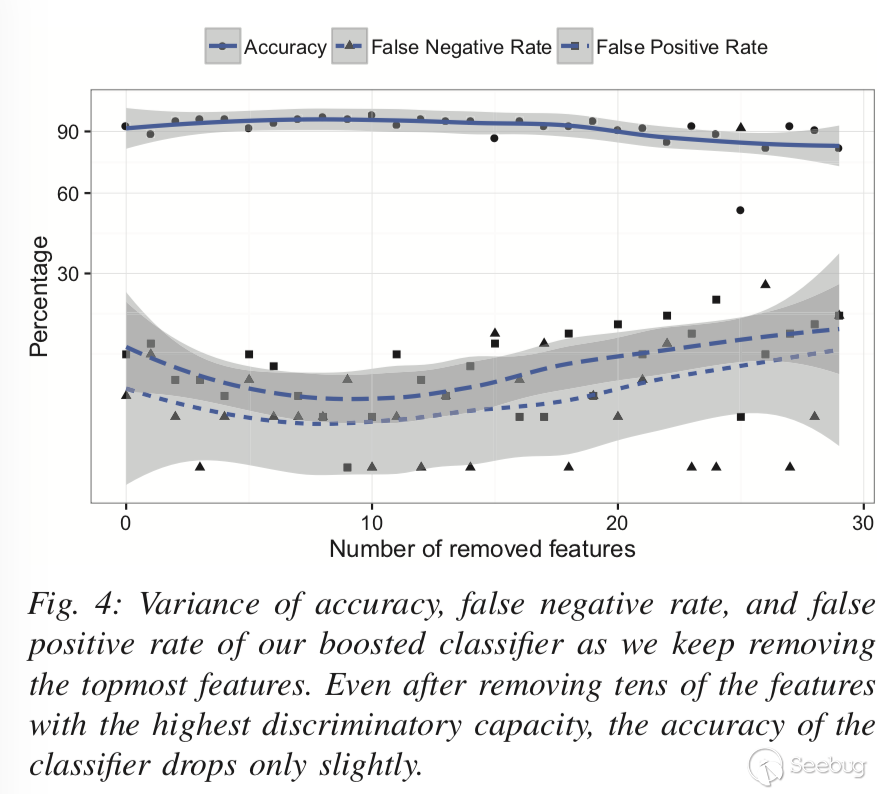
之后作者從兩個思路出發:
一、評估我們的算法對沙盒環境中增量變化的穩健性
方法: 每次只刪除一個特征,將以上分類器訓練過程重復30次。
目的: 對于攻擊者而言量化惡意軟件區分沙箱和真實用戶的能力;對于防御者而言可以使用在此處識別的最有價值的artifact磨損程度來模仿真實的用戶系統。
效果: 圖4顯示了準確性,誤報率和漏報率如何變化。可以看到即使刪除多達20個特征,分類器的整體準確性仍高于90%。
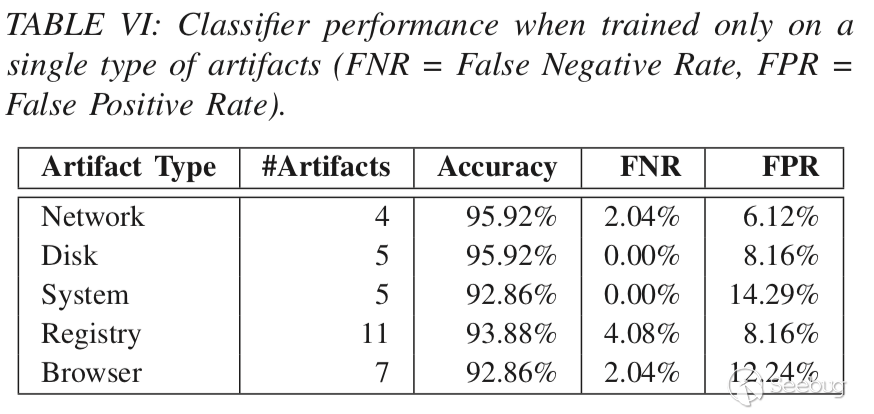
二、每種類型的工件如何影響分類器的準確性
方法: 一次僅使用一種類型的工件重新訓練我們的模型。
目的: 讓惡意軟件作者可以選擇他們想要關注的artifact類別,但這種選擇不會影響惡意軟件的規避能力。
效果: 表VI顯示了每個類別的artifact數量以及每個分類器在測試數據集上的性能。
VI. ESTIMATING ACTUAL SYSTEM AGE
在之前的數據分析中,可以發現沙箱環境的“老化”程度與用戶的真實環境是截然不同的。而且理論上“磨損”程度和“老化”程度應該是相匹配的,如果不匹配那么是沙箱的概率則很大。對于攻擊者可以使用者一特點進行沙箱規避;對于防御者則可以對沙箱做更好的調整。
A. Correlation Between Age and Artifacts
目的: 得出artifact的磨損與系統年齡之間的關系
圖5顯示了用戶系統和惡意軟件沙箱“年齡”的累積分布函數。可以看到平均而言用戶系統比沙箱更“新”。
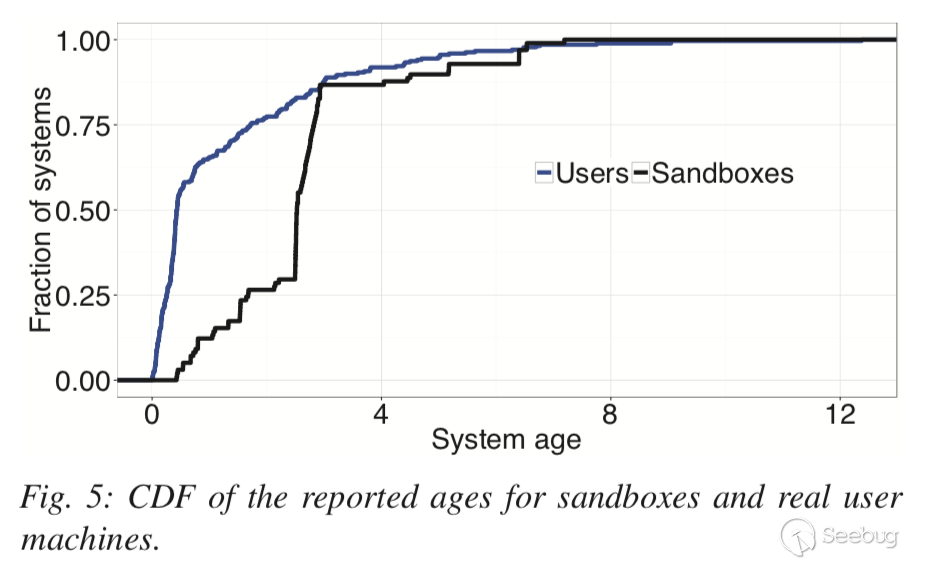
圖6顯示了報告的年齡與真實用戶系統的每個artifact磨損程度之間的皮爾森相關系數。此處假設從真實用戶系統收集的報告年齡是準確的。
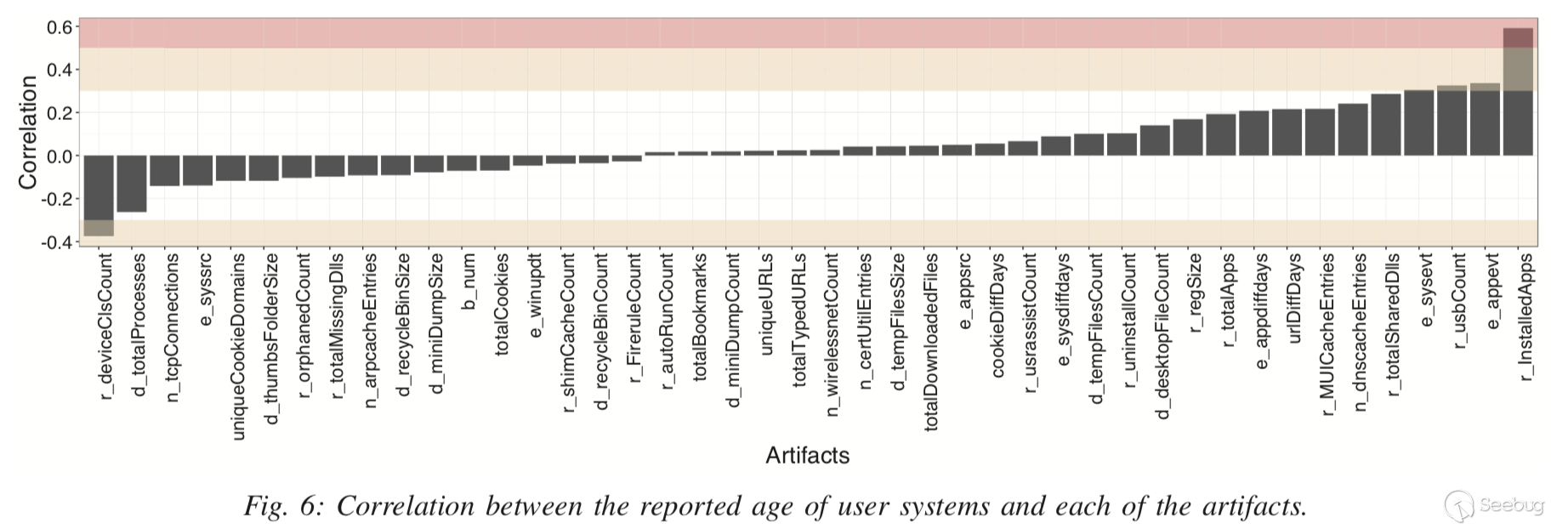
觀測結果分析:
- 許多非常成功地區分真實機器和沙箱的工件實際上與機器的年齡無關;
- 一些與用戶活動直接相關的artifact不能很好的反映系統的年齡,比如cookie的數量(用戶可以主動清除);
- 一些不太容易被用戶修改的artifact將跟系統年齡成正相關,比如連接過的USB數量。
B. Regression
目的: 確定組合它們的原始值來估計系統的實際年齡的合適方法。
數據集處理:
- 刪除具有缺失值的artifact;
- 刪除丟失率超過80%的artifact。
(1) Linear Regression:
- 公式: Y =β0+β1X1+β2X2+ … +ε (Xi是給定的artifact值,βi是對應的權重,Y是預測的年齡)
- 數據集: 訓練(60%),測試(40%)
- 評估: 十折交叉驗證
- 結果: 真實系統的預測年齡的最終均方誤差(MSE)是1.88,而沙箱的MSE非常高,為6.25。
- 結論: 使用artifact的磨損程度來預測系統年齡是可行的,也就是說使用預測年齡和系統的生成年齡的對比來識別沙箱是可行的。
PS: 十折交叉驗證,英文名叫做10-fold cross-validation,用來測試算法準確性。是常用的測試方法。將數據集分成十份,輪流將其中9份作為訓練數據,1份作為測試數據,進行試驗。
表VII中報告了模型的系數及其p值。 我們看到13種artifact磨損程度與機器的年齡相關,具有統計學意義。
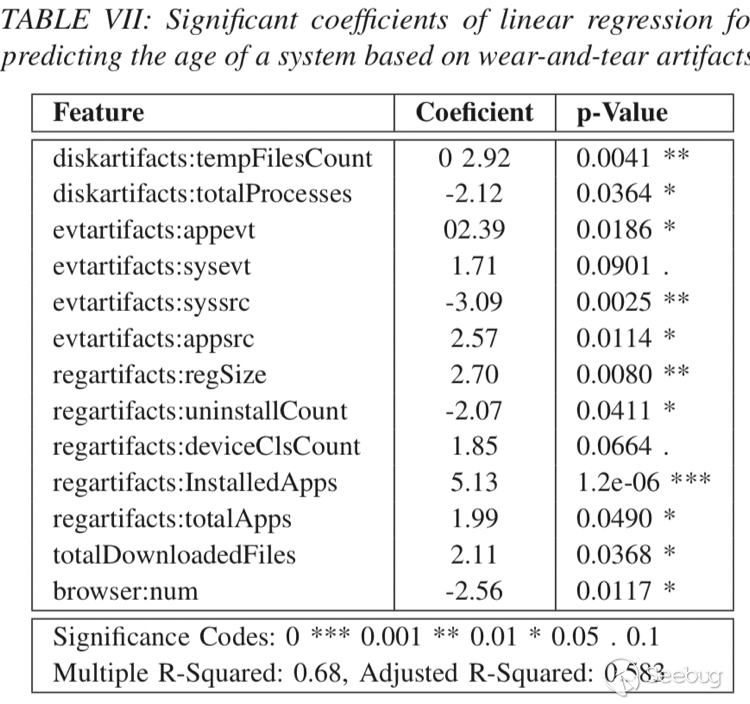
圖7顯示了在Dreal和Dsand系統上應用線性回歸模型時殘差值的累積分布函數(CDF)。可以看到在嘗試預測沙箱年齡時的殘差值是非常高的。
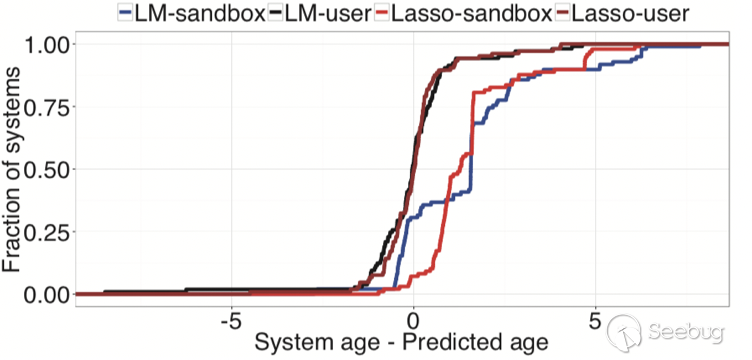
(2) Lasso Regression
- 目的: 驗證復雜的回歸模型是否會帶來更好的預測準確性
- 套索回歸的優點: 比線性回歸使用更少的預測變量,這降低了整體模型的復雜性。 對于惡意軟件,較小的功能集意味著對底層操作系統的API調用較少,從而減少了觸發可疑活動監視器的機會。
- 數據集: 訓練集,評估集和測試集
- 方法: 交叉驗證來找到最佳的λ值
- 結果: Dreal集的MSE為0.749,Dsand集上的MSE為4.45,優于線性回歸
- 結論: Lasso模型可以更好地辨別沙箱。
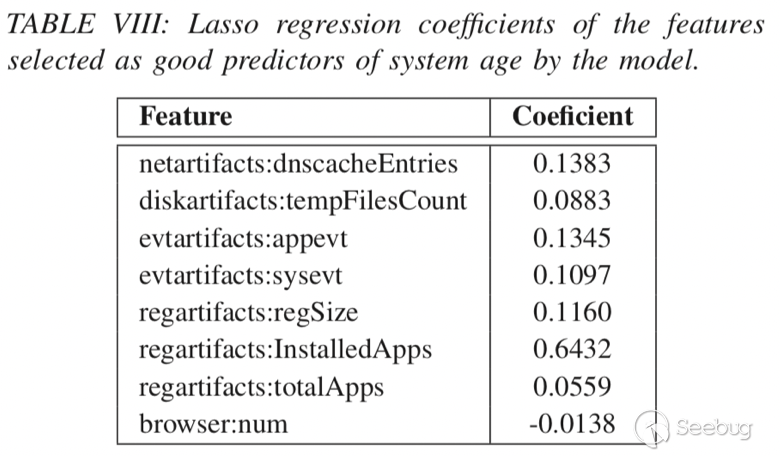
表VIII顯示了Lasso模型選擇的八個特征,它們是系統年齡及其相應系數的良好預測因子。
小結: 使用artifact磨損程度來預測系統年齡是可行的,這一方面可以用于辨識沙箱;另一方面是可以幫助sandbox開發人員創建系統年齡相符的沙箱環境
VII. DISCUSSION
A. Ethical Considerations and Coordinated Disclosure
本文主要講述了這種新的規避技術的有效性,并且目前已經出現了此類相關工作的惡意軟件。但是本文主要是為了幫助創建更強大的惡意軟件分析系統。
B. Probing Stealthiness
- 總是存在不受監控的artifact集;
- 雖然最小特權原則造成的系統API調用限制,可訪問的環境限制,但是依舊可以從其他不受限制的artifact集獲取大量信息;
C. OS Dependability
文章雖然是基于Windows平臺在進行artifact的分析,但其中的一些artifact并不是其特有的,在其它系統例如Linux,Mac,Android等也同樣適用。如果想適用Java等編寫跨平臺的惡意軟件,就可以去關注那些不依賴于特定系統而存在的artifact。
D. Defenses
-
克隆真實用戶系統并將其用作惡意軟件沙箱的基礎。
缺點:
i) 隱私問題(如何在克隆之前或之后擦除所有私人信息,但保留磨損工件完整?);
ii) artifact的老化問題(攻擊者可以使用我們提出的統計模型來檢測聲稱的年齡與磨損程度不匹配的情況)。
-
從新安裝的操作系統映像開始,通過自動模擬用戶操作人為地使其老化。
缺點:尚不清楚這種人工老化在多大程度上會產生與真實系統相似的artifact情況。
VIII. CONCLUSION AND FUTURE WORK
本文主要做了兩個方面工作:
- 攻擊者角度:將Windows系統的一些不涉及用戶隱私的artifact作為特征,使用決策樹分類器進行訓練,最終可以在92.86%的準確度上來識別沙箱環境。
- 防御者角度:將系統的artifact特征與系統的年齡進行聯系并提出統計模型,從而幫助沙箱操作人員對系統進行微調,使其具有更逼真的磨損特性。
未來工作:
- 克隆真實用戶系統并將其用作惡意軟件沙箱的基礎。
- 自動模擬用戶操作人為地使系統其老化到所需程度。
- 不同的桌面操作系統以及移動設備中評估基于artifact磨損特性的沙盒規避的有效性。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/864/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/864/
暫無評論