
原文來自安全客,作者:imbeee、iswin@360觀星實驗室
原文鏈接:https://www.anquanke.com/post/id/157175?from=groupmessage&isappinstalled=0
簡介
機器學習目前已經在安全領域有很多的應用,例如Threat Hunting、攻防對抗、UEBA以及金融反欺詐等方面,本文將以Windows RDP服務為例子,詳細闡述機器學習在后門檢測、精準的服務版本檢測等方面的應用,本文所涉及的相關檢測思路和方法已經應用在觀星實驗室內部的自動化滲透測試平臺(Gatling)以及互聯網資產發現平臺中,當然在年底我們實驗室發布的國內首款針對域安全分析的工具—觀域中也有很多機器學習的應用,后續的文章我們會詳細給大家介紹。
背景
本文中所提到的幾個問題其實是來自于我們日常工作中實際面臨的問題以及實驗室內部的幾次討論。在一次給客戶(某部委)做互聯網資產發現的時候,我們發現一個奇怪的端口,最后經過驗證發現這個是RDP的端口,當時Nmap顯示的服務器版本是Windows 2008,但是當我們登錄進去之后發現是Windows 2003,這是我們面臨的第一個問題:如何提高Windows RDP版本識別的準確率?
然后實驗室其它小伙伴習慣性的按了5下shift 突然冒出一個黑框,經分析發現是一個shift后門。當時我們遇到的另一個問題就是:如何檢測shift后門?
由于我們的客戶數量非常多,互聯網側的資產更是不在少數,一臺一臺登錄去檢測顯然是不可能的,所以第三個問題就是如何自動化的批量檢測互聯網的shift后門?
基于上面的三個問題,我們進行了一些研究,發現機器學習在自動化RDP版本和shift后門檢測方面有一定的應用場景,能幫助我們解決一些實際問題。
實現思路
針對上面提出的3個問題,我們從實現上做了一些摸索,也大膽的設想了一下,下面就這兩個問題進行分別討論。
當前RDP版本識別存在的問題
我們無法直接從RDP協議中取得系統版本,雖然特定版本的Windows系統默認會使用某個版本的RDP協議,比如Windows 7默認使用RDP 7協議,但是也可以通過安裝補丁升級到RDP 8.1或者更高版本。所以通過RDP協議版本推斷系統版本也不是很準確。
如何高效自動化的檢測RDP后門(不止shift后門)?
自動化檢測RDP后門,關鍵在于觸發相關程序,如按5次shift鍵觸發sethc.exe,或者win+u觸發放大鏡等,這部分操作在RDP協議里都是簡單鍵盤事件,并沒有使用特定的報文。而對于不同版本的Windows系統,在登錄界面觸發輔助程序的按鍵序列也不一樣,所以需要先判斷Windows版本,使用對應的按鍵序列來觸發粘滯鍵等程序,然后截圖供后續檢測。
經過我們調研發現Github上有個Python實現的RDP客戶端項目rdpy,這個項目解決了基礎的截圖問題,在后面RDP后門的檢測中,也遇到一些坑,比如穩定截圖問題,這個會在后面具體提。
所以我們的整體解決方案就是使用rdpy來實現截圖邏輯,版本識別使用機器學習技術,用原始圖片樣本固定位置截圖進行訓練,RDP后門檢測則基于版本識別的結果(不同版本服務器shift后門彈框位置不一樣)訓練樣本進行識別,關鍵信息提取直接用原始圖片進行關鍵位置的文字識別即可。
Windows RDP截圖
在截圖的實現中,為了避免重復造輪子,我們直接使用了上面提到的rdpy庫,其支持Classic RDP Protocol、SSL和CredSSP全部三種安全層協議,同時實現了不同圖片格式(即RDP遠程會話的顏色深度)的處理方法,基本滿足我們的需求。
RDP穩定截圖的難點在于我們無法從協議上得到“停止”反饋。由于RDP協議是將畫面切割后分塊傳輸的,且只傳輸畫面變動的部分,所以在整個會話過程中,我們無法確定在哪張圖片之后畫面已經繪制完畢。
剛開始我們嘗試了一些比較臟的方法,包括rdpy自己的截圖腳本rdpy-rdpscreenshot.py里面也用到的一個方法,那就是設定一個時間閾值,從建立RDP鏈接開始,等待一段時間后截圖然后關閉鏈接。這個方法的缺點很明顯,那就是受網絡質量影響,導致效率低下。對于鏈接質量好的目標,可能很短時間就完成了登錄界面的傳輸與繪制,但是卻浪費了大量時間在等待截圖;而對于鏈接質量差的目標,可能在時間結束時還沒有繪制完成,造成截圖失敗。
通過嘗試,最后我們確定了一個比較合理的截圖邏輯:建立鏈接后,每接收一張圖片并繪制后,將當前時間記錄為最后繪制時間,并且使用一個獨立的線程每隔一定時間檢查最后繪制時間與當前時間的時間差,如果時間差超過某個值,則認為當前畫面已經穩定,可以進行下一步操作(如截圖、發送按鍵觸發后續事件),如果需要觸發事件后截圖,則使用相同的邏輯判斷畫面是否穩定,然后再次截圖。這樣的截圖流程符合實際操作邏輯,后續可以通過其他手段判斷鏈接質量,并動態調整等待時間,最終獲得比較穩定的截圖效果。
Windows版本檢測
Windows Server的主流版本大致分為這么5個版本,Windows 7、Windows Server 2003、Windows Server 2008 R[1|2]、Windows Server 2012 R2、Windows 10,從我們在shodan的采樣數據數據來看,除了Windows 10非常少之外,開3389的基本上就4個主流版本,所以本文將重點以這4個版本為主。
我們先來幾張RDP登錄界面的圖片
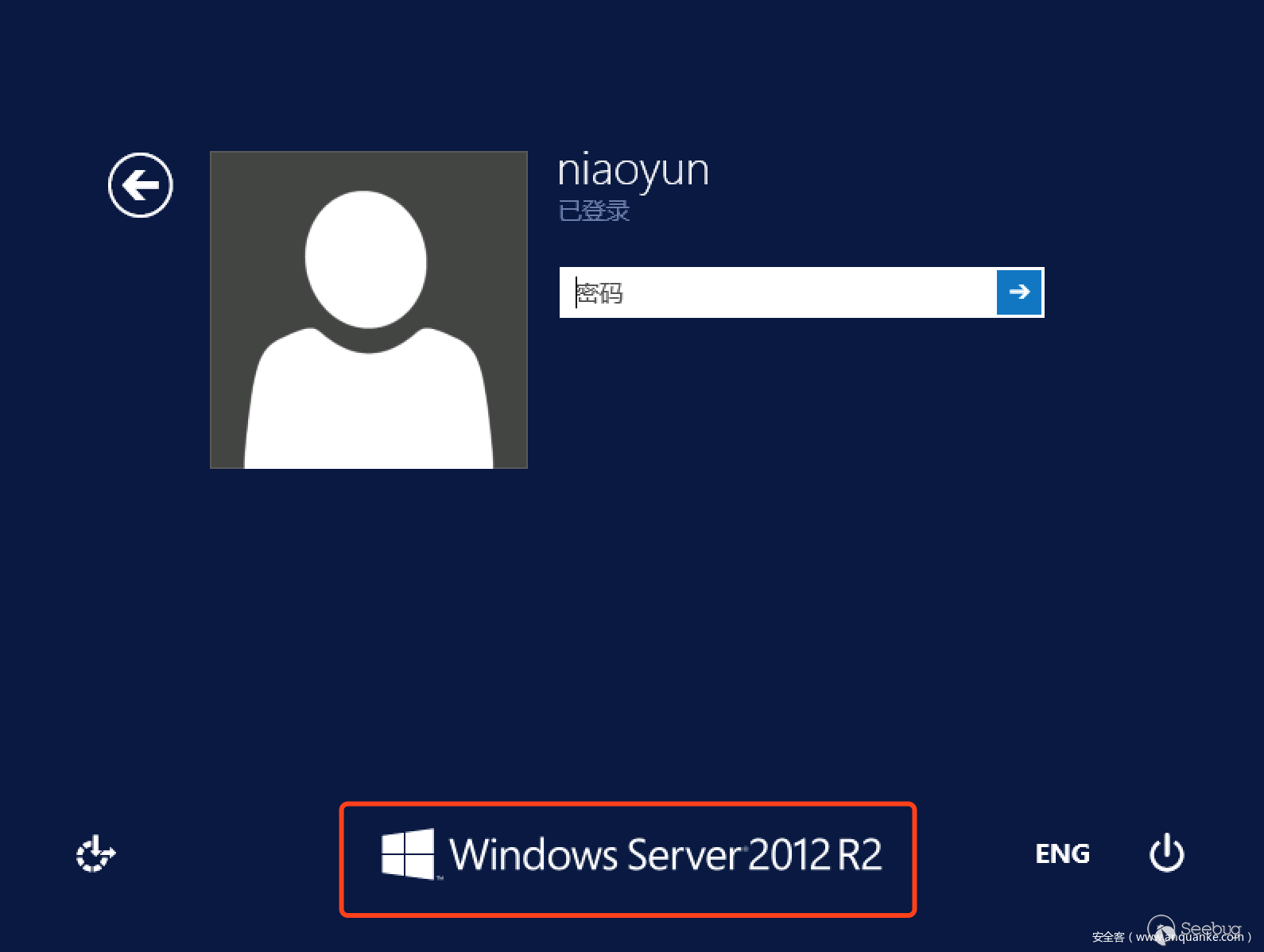
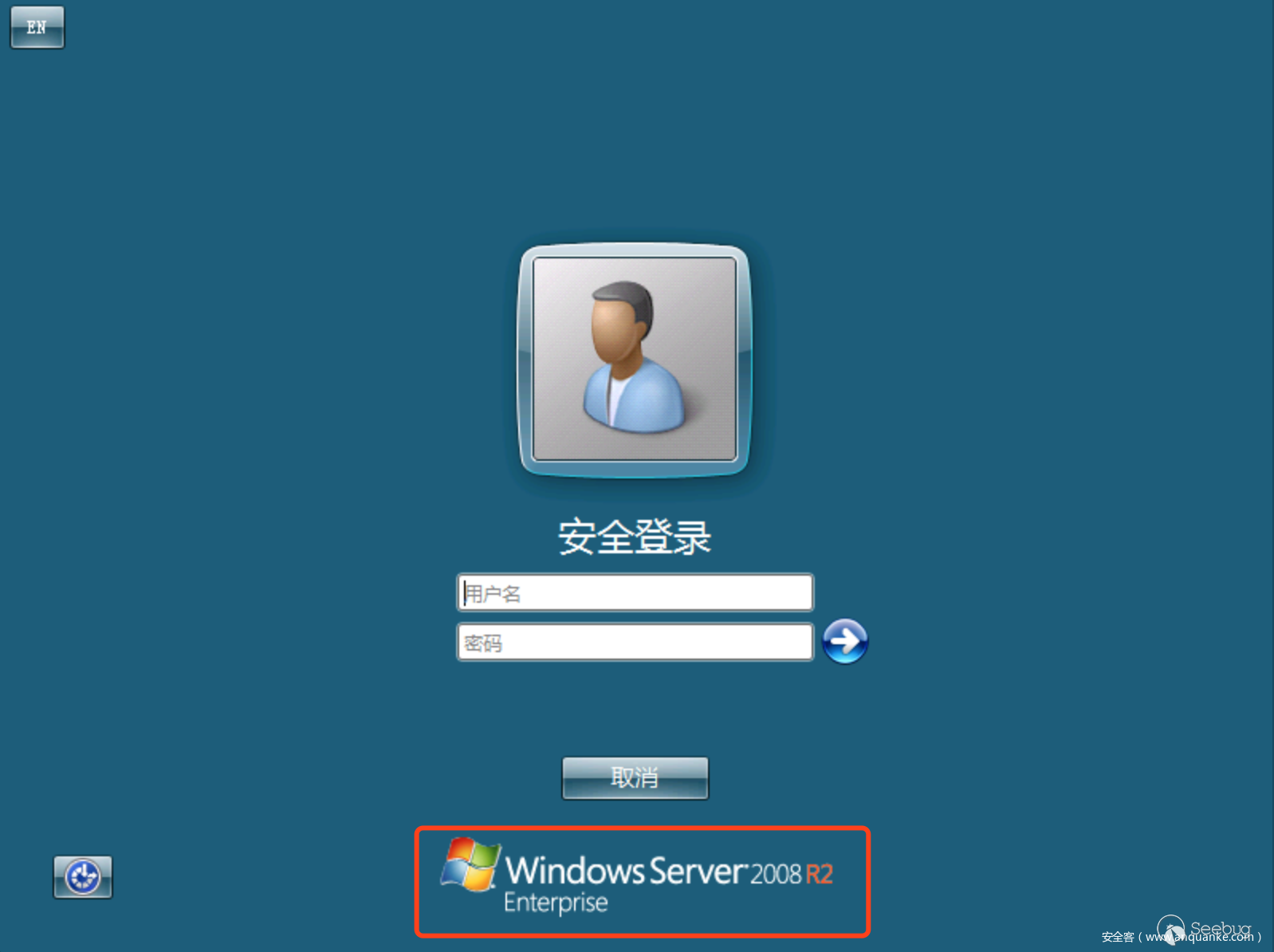
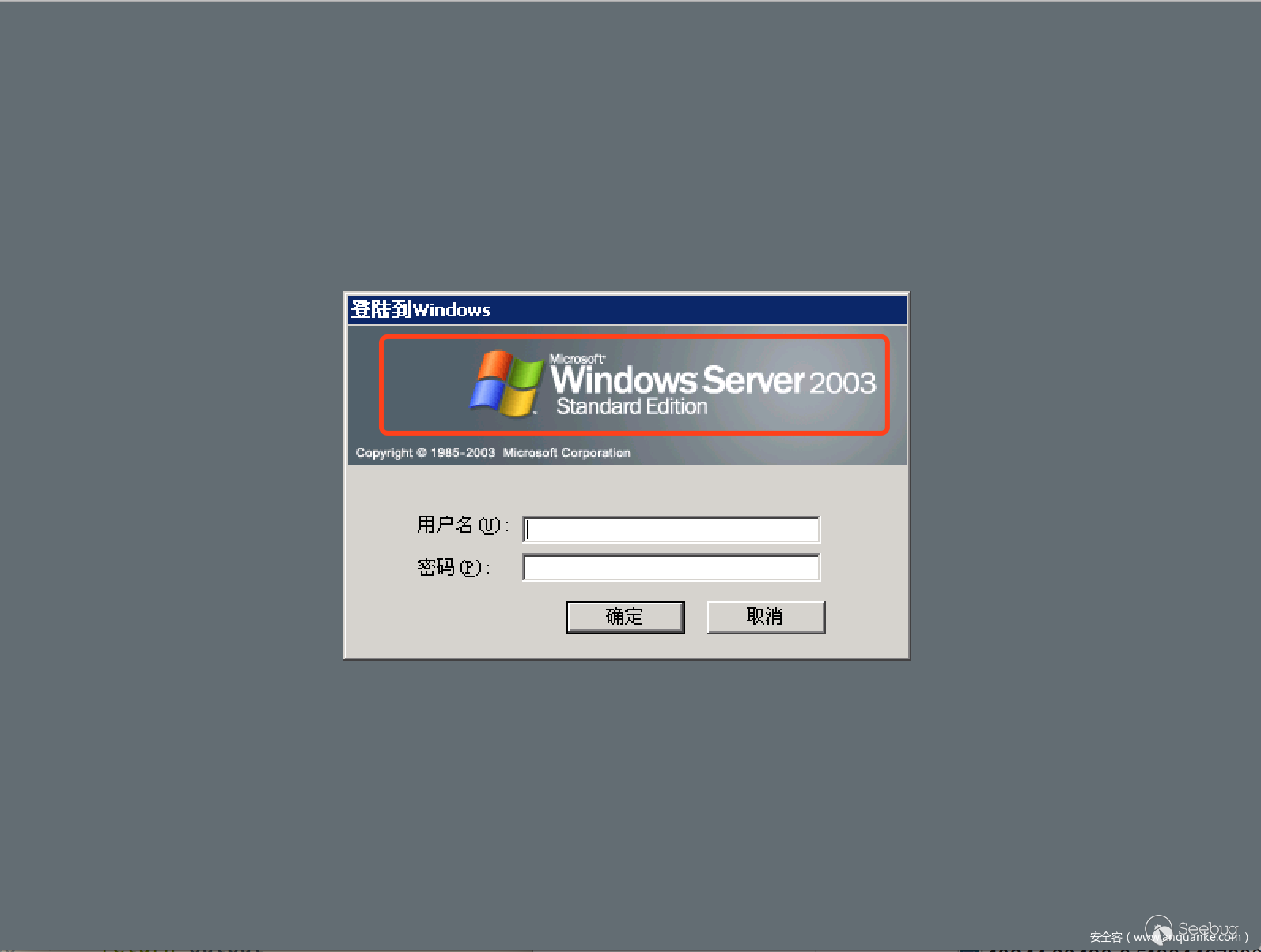
從上面幾張圖片標紅的部分我們大致可以看到RDP的版本標識主要出現的位置在兩個地方,所以我們的版本識別主要分為兩種,Windows 2003 及以上版本,然后針對這兩種類型的關鍵位置(標紅部分)進行圖片裁剪進行訓練,當然有人可能說了其實不用裁剪直接來訓練也行,這種辦法不是說不行,只不過在處理效率上有點低,除了標紅位置之外的地方主要占了整個圖片的80%左右,如果整張圖進行訓練,在特征提取的時候你的維度就會特別大,而且這這部分基本上不會有變化。
按照關鍵位置剪切圖片后,圖片非常小,效果如下




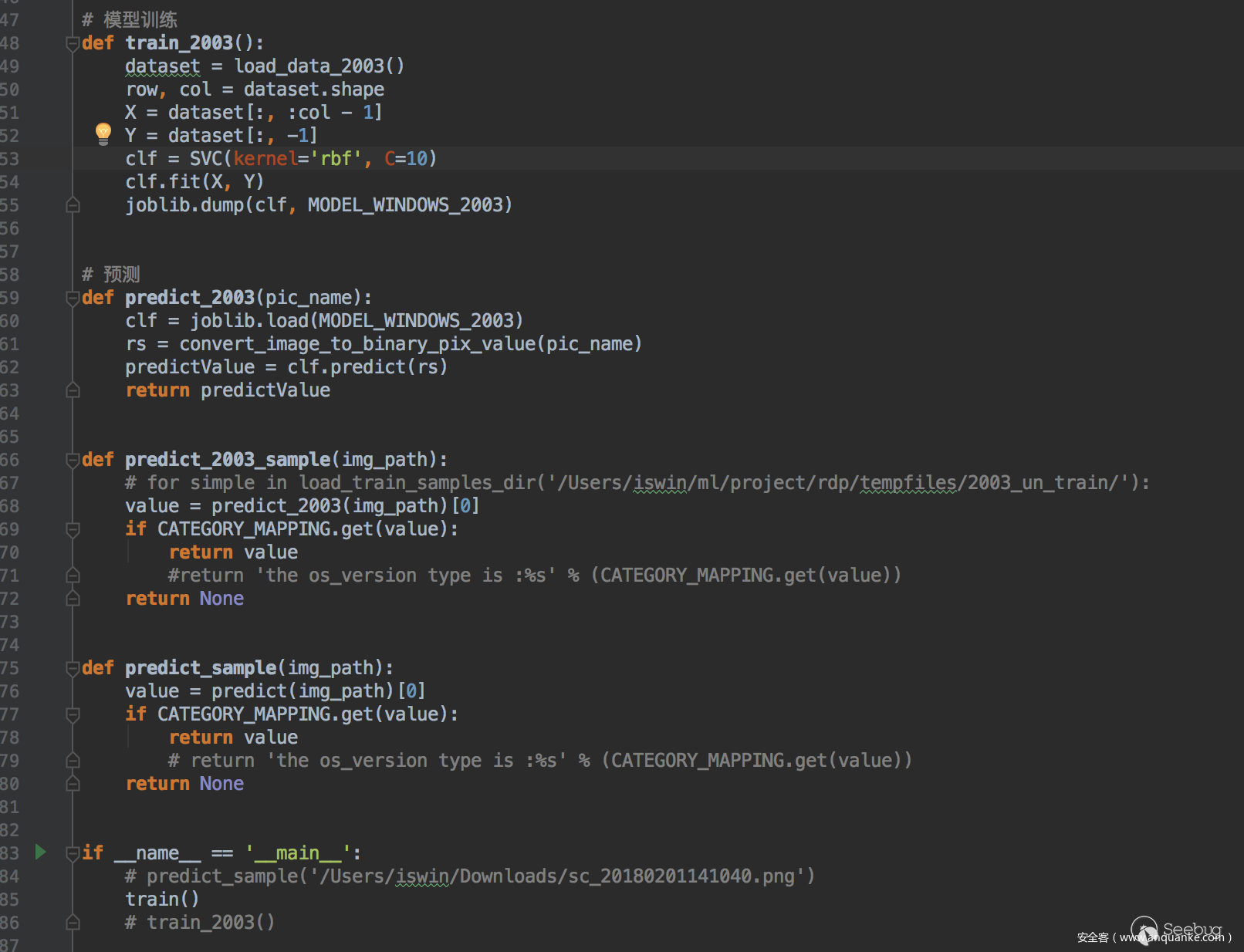
處理完之后其實對于2003來說就是個二分類問題,即是不是2003版本,對于2003以上版本就是個多分類問題,這里主要是區分圖片里面的關鍵元素,一般在實際處理的時候可以不用考慮圖片的顏色,即將圖片二值化,然后根據圖片的Length*Width來作為特征向量的維度,用0和1表示黑白兩種顏色,這樣就可以將圖片轉換為可以用于計算的數學上的值,當然如果你直接用ocr去識別圖片中的文字,當然也是可以的,不過效率和效果很一般,為了提高效率和識別效果我們采用Scikit-learn中的SVM算法來進行有監督的學習,這樣在工程化的時候也比較好嵌入到我們已有的項目中。
整體的識別流程如下:

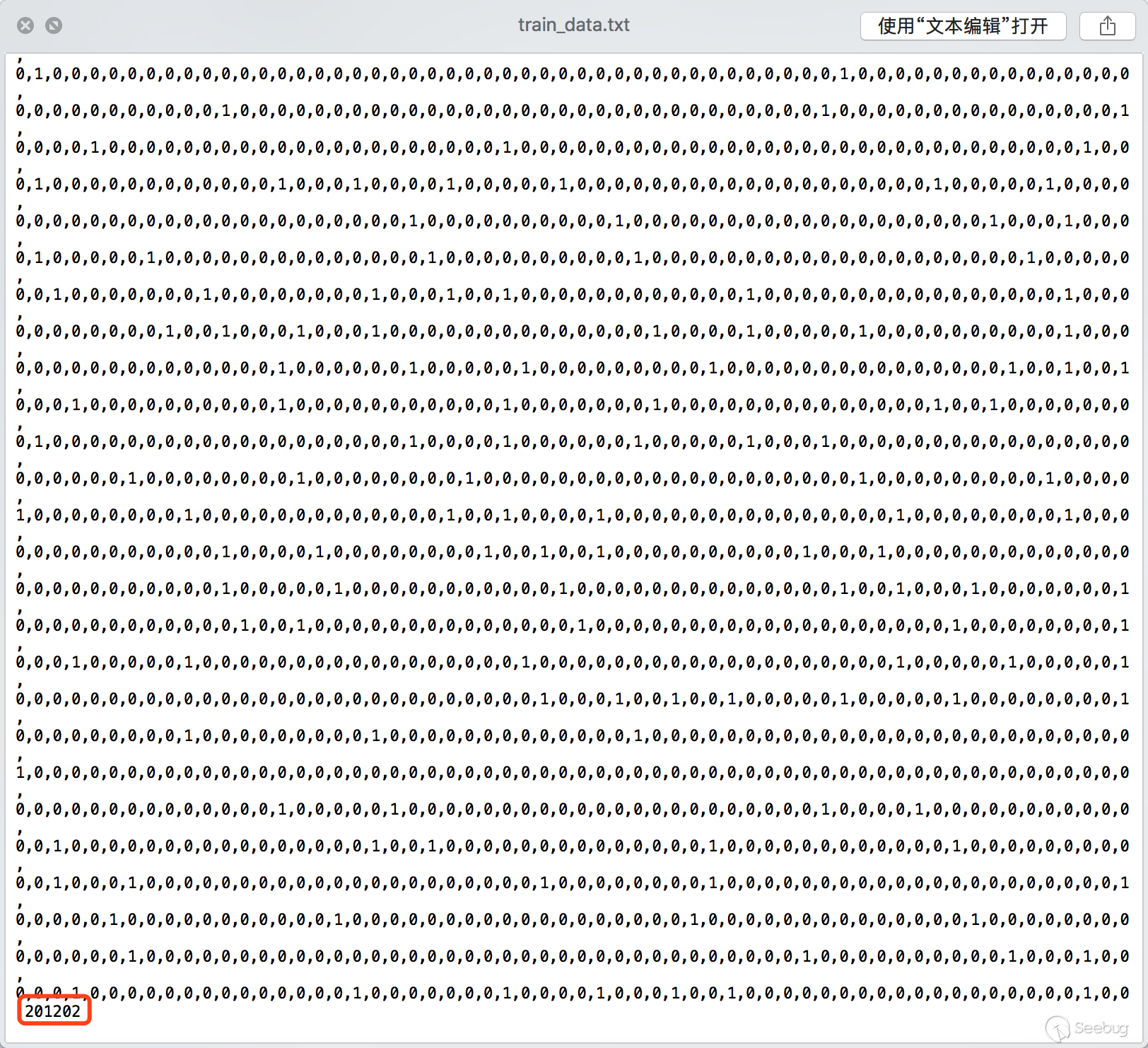
訓練樣本大家可以從shodan上去提取,然后截圖之后手工分類下,按照如下文件夾的形式存放樣本圖片
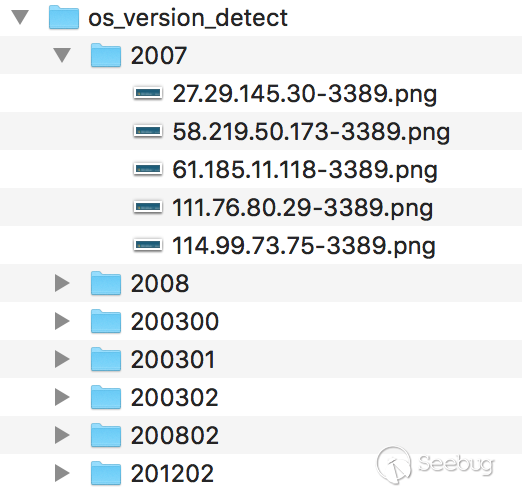
由于有監督學習需要給每個樣本打上標簽,所以這里我們用數值來標識不同的操作系統版本,映射關系如下:

針對2003的系統需要注意下,這里是二分類,需要一些負樣本進行訓練對應圖中的200300和200301,特征提取關鍵代碼如下:
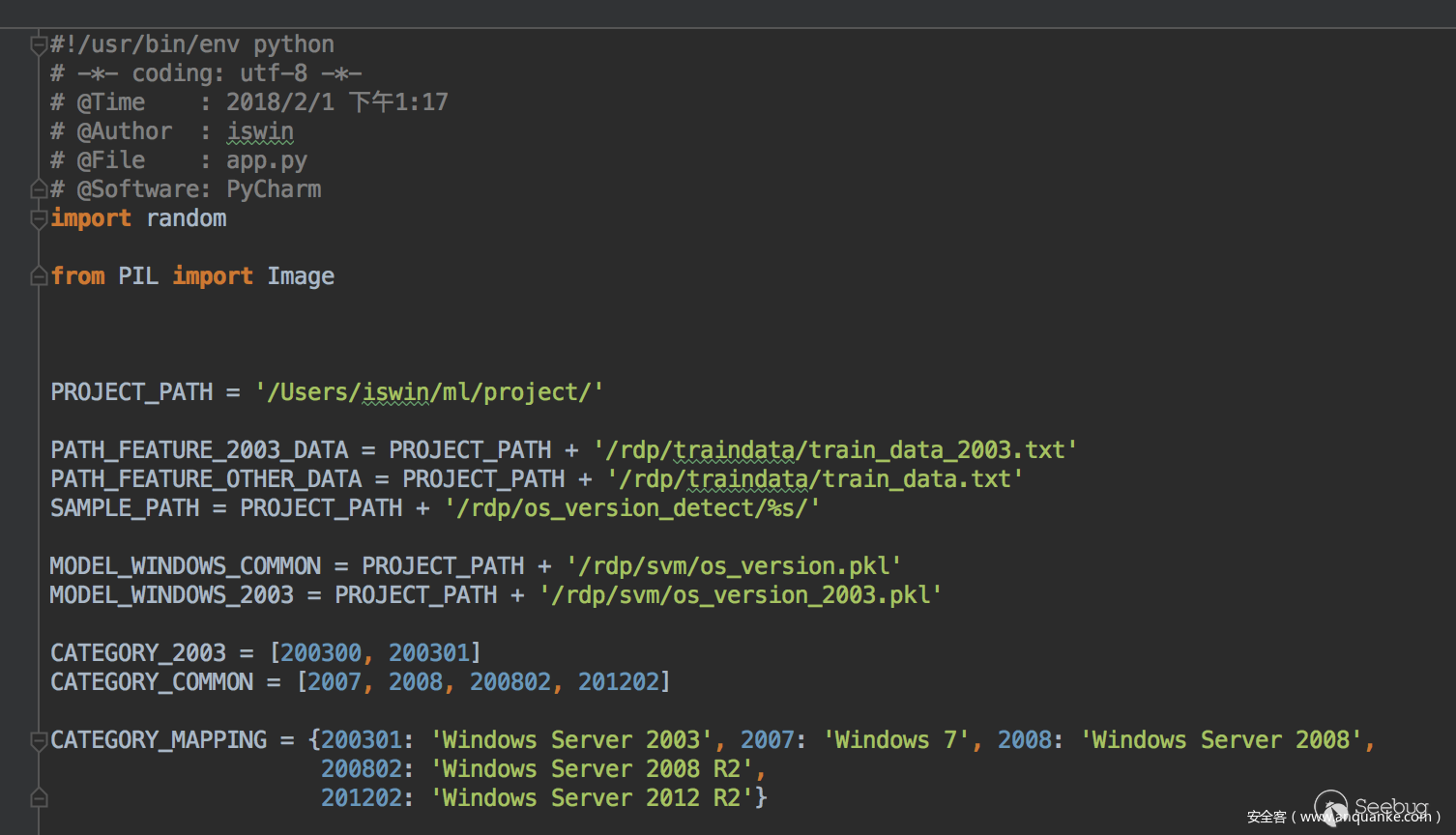
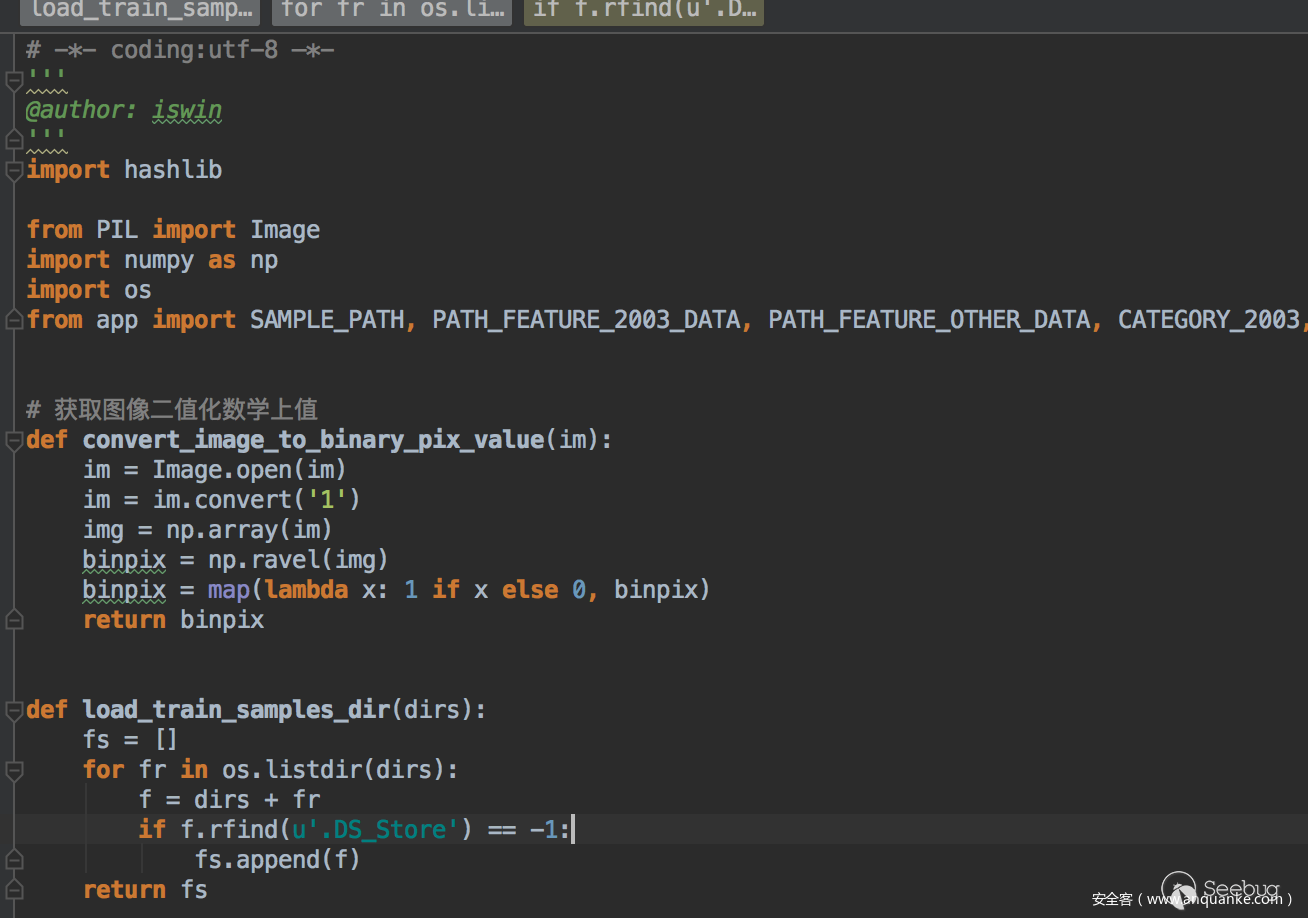
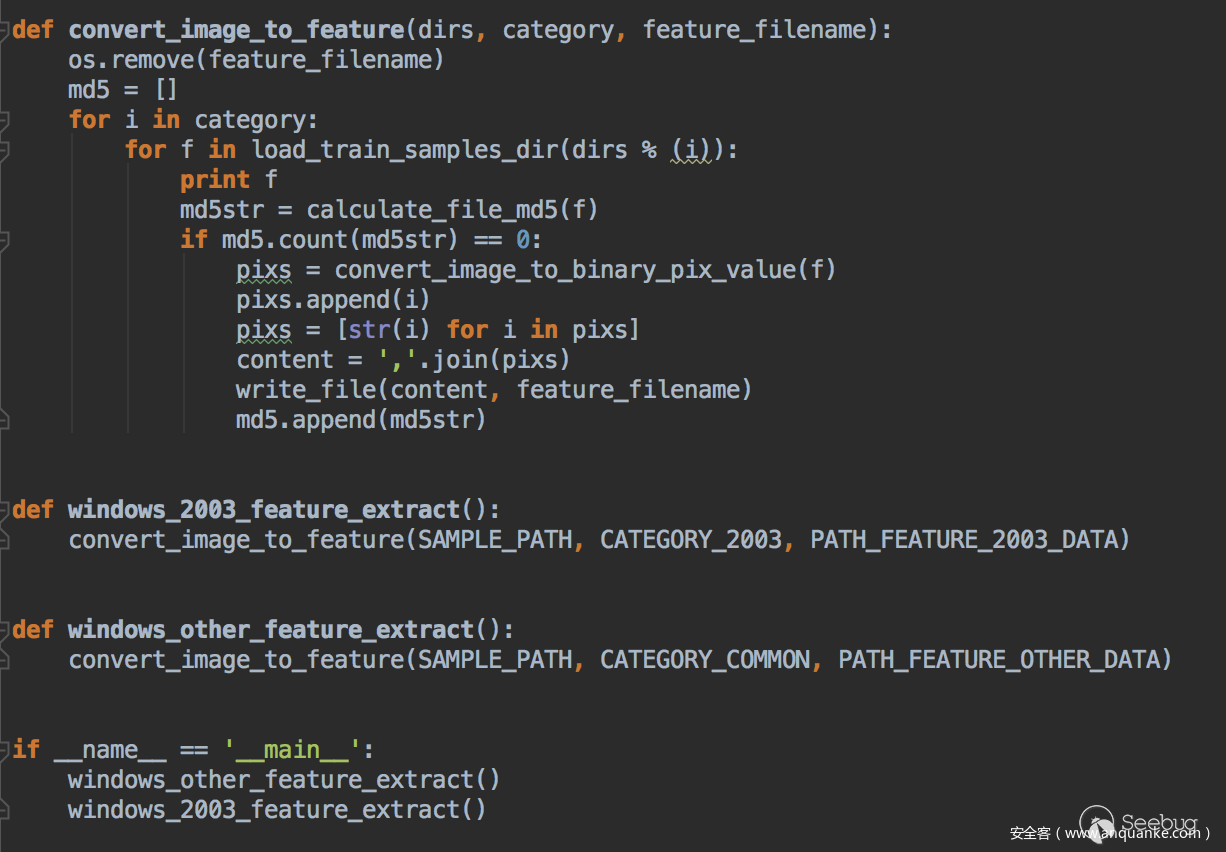
最后會在traindata里面產生兩個文件
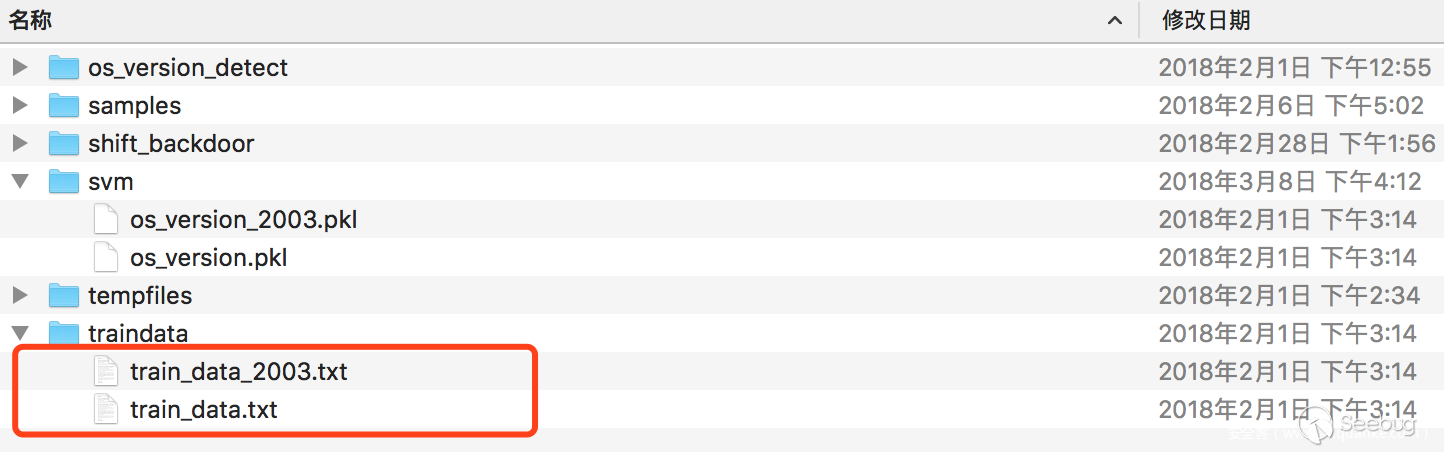
每條數據最后一列表示對應的標簽
訓練這塊直接用Scikit-Learn 中的svm算法進行訓練即可,關于SVM具體的算法原理這里不做介紹,網上有更專業的paper來進行介紹。
訓練部分的代碼如下
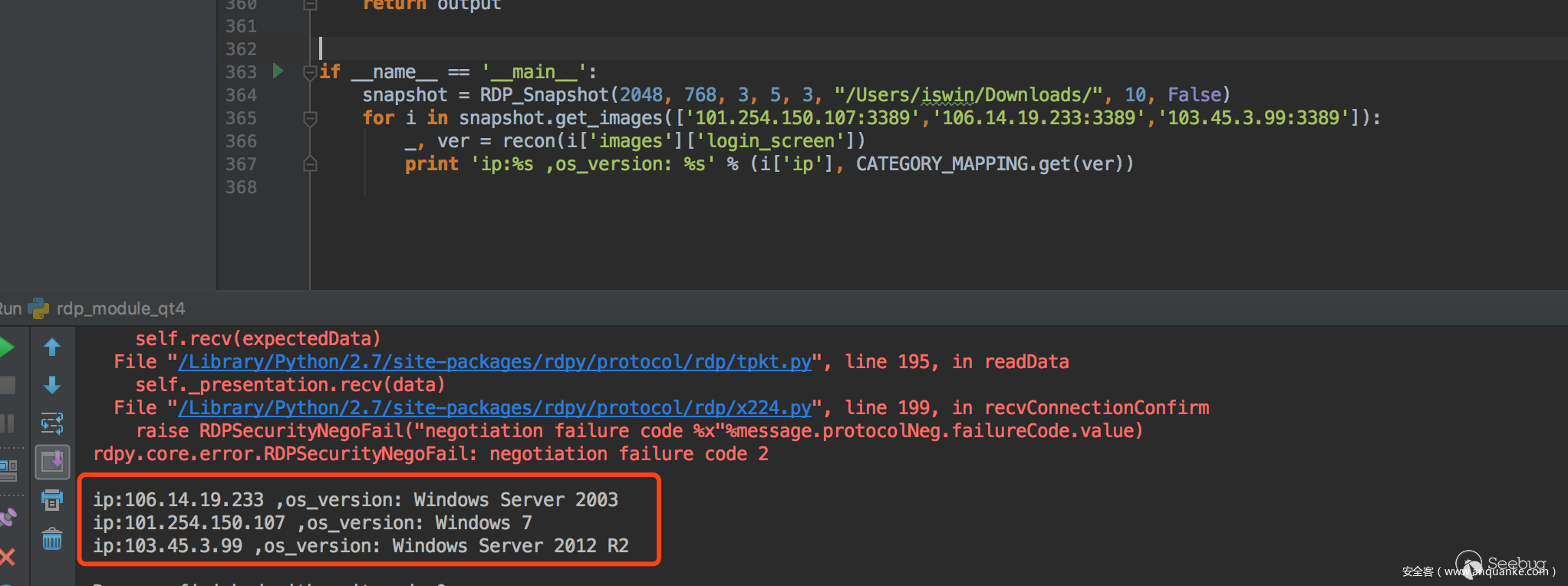
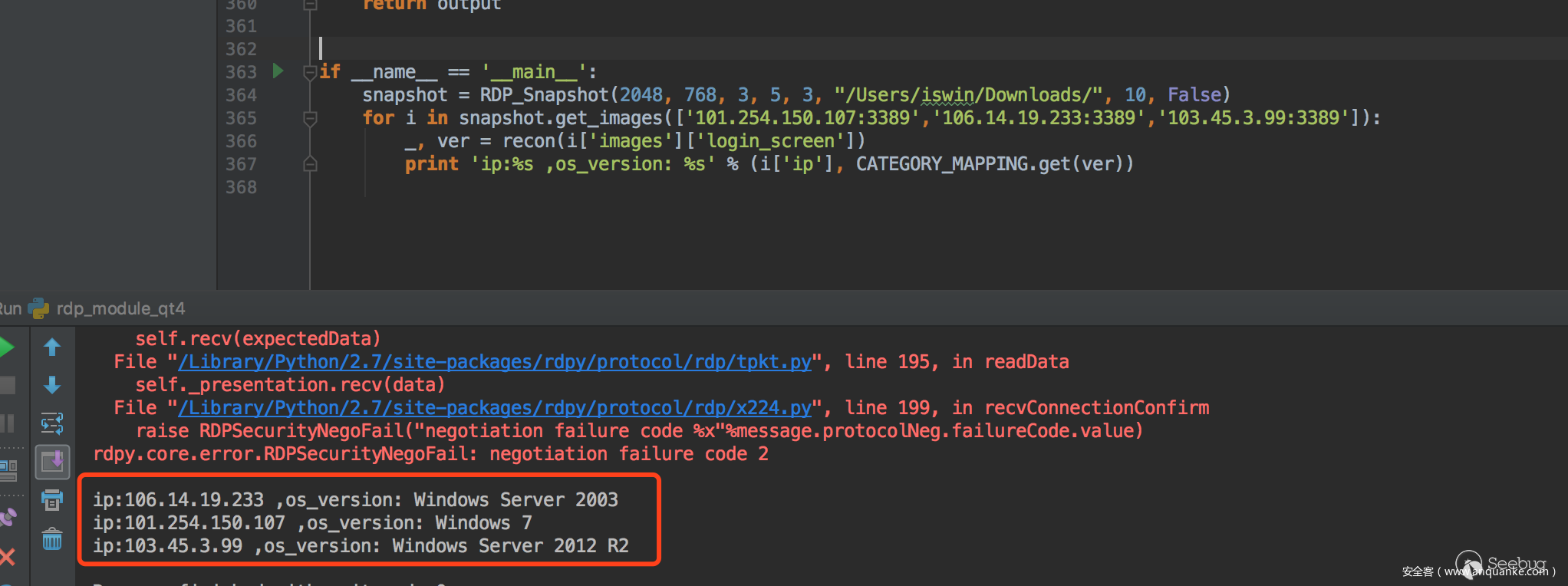
我們將測試集分為兩組,80%作為訓練,20%作為測試,目前就版本檢測來說,準確接近100%,看以下4個版本例子
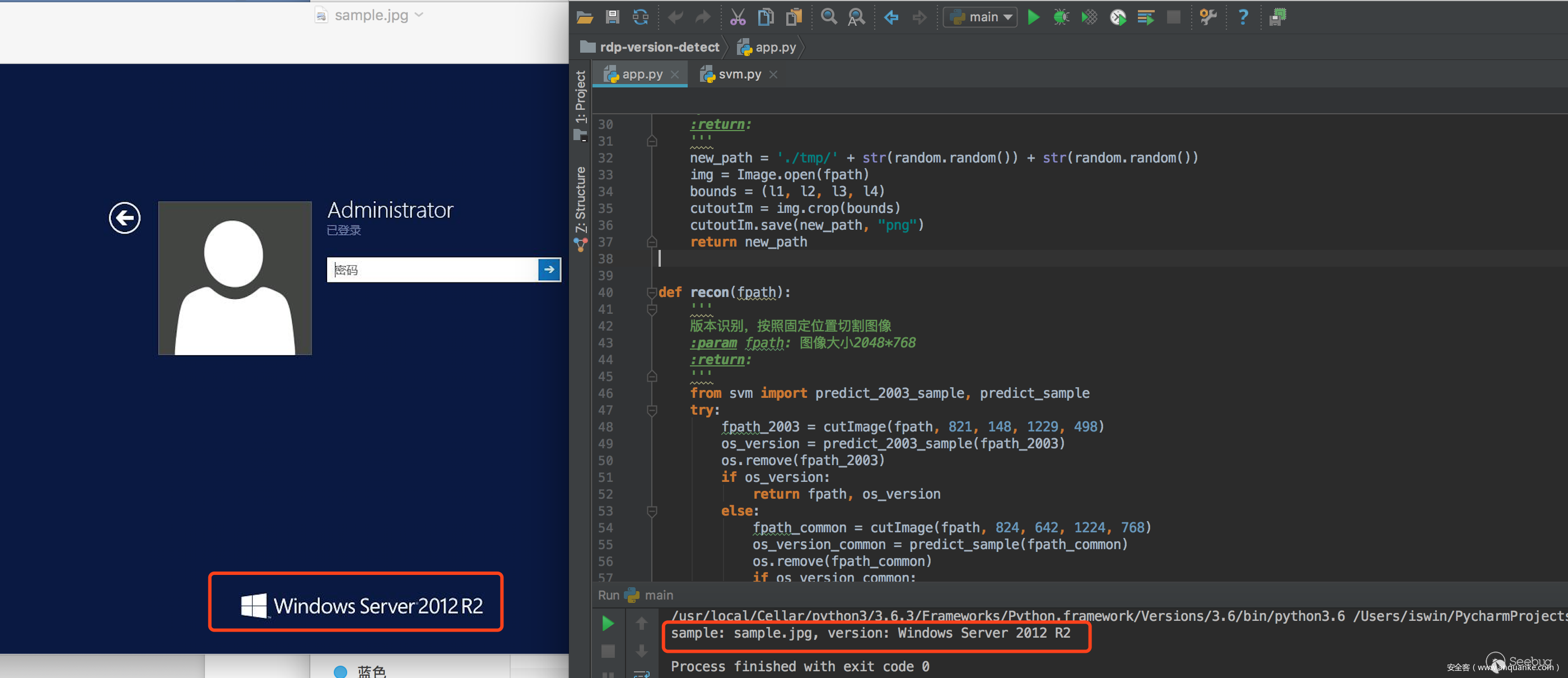
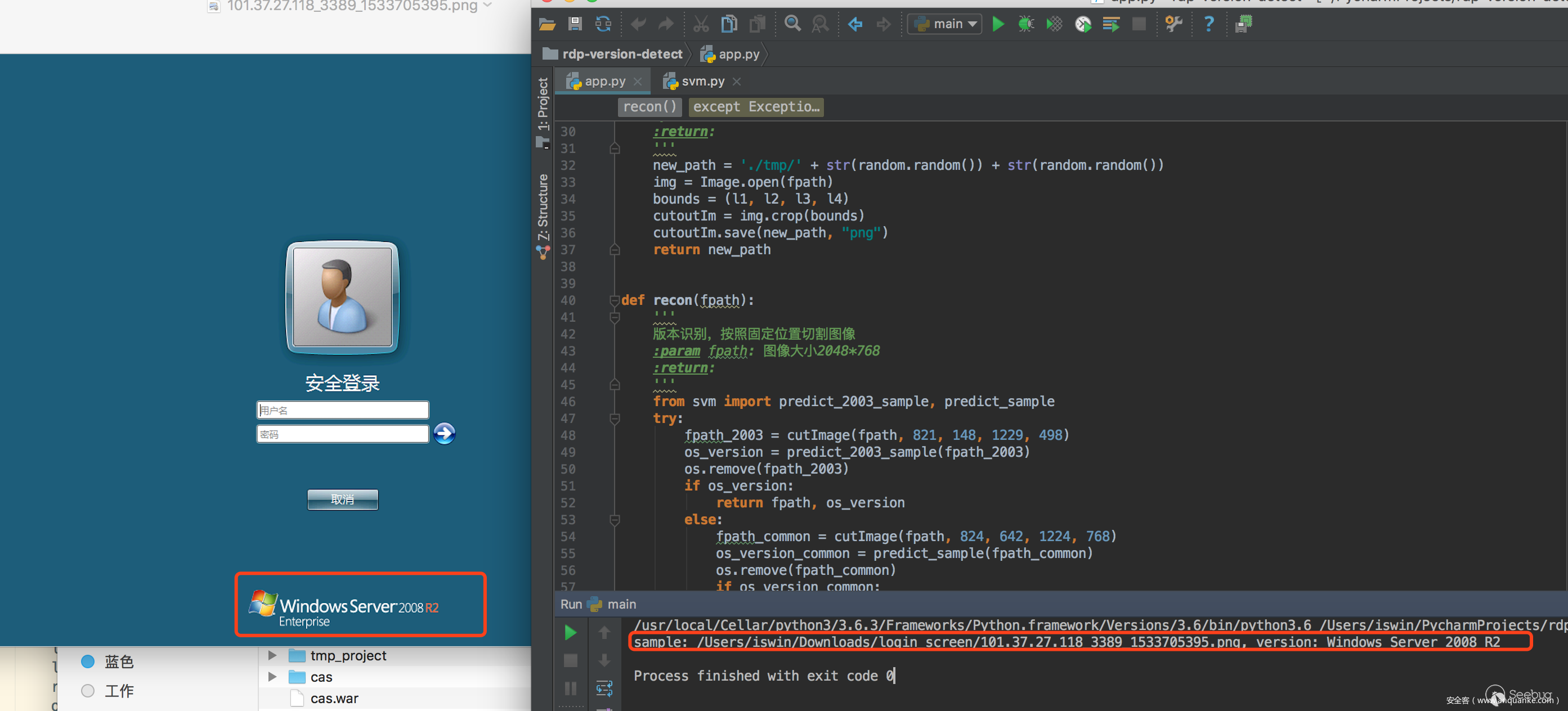
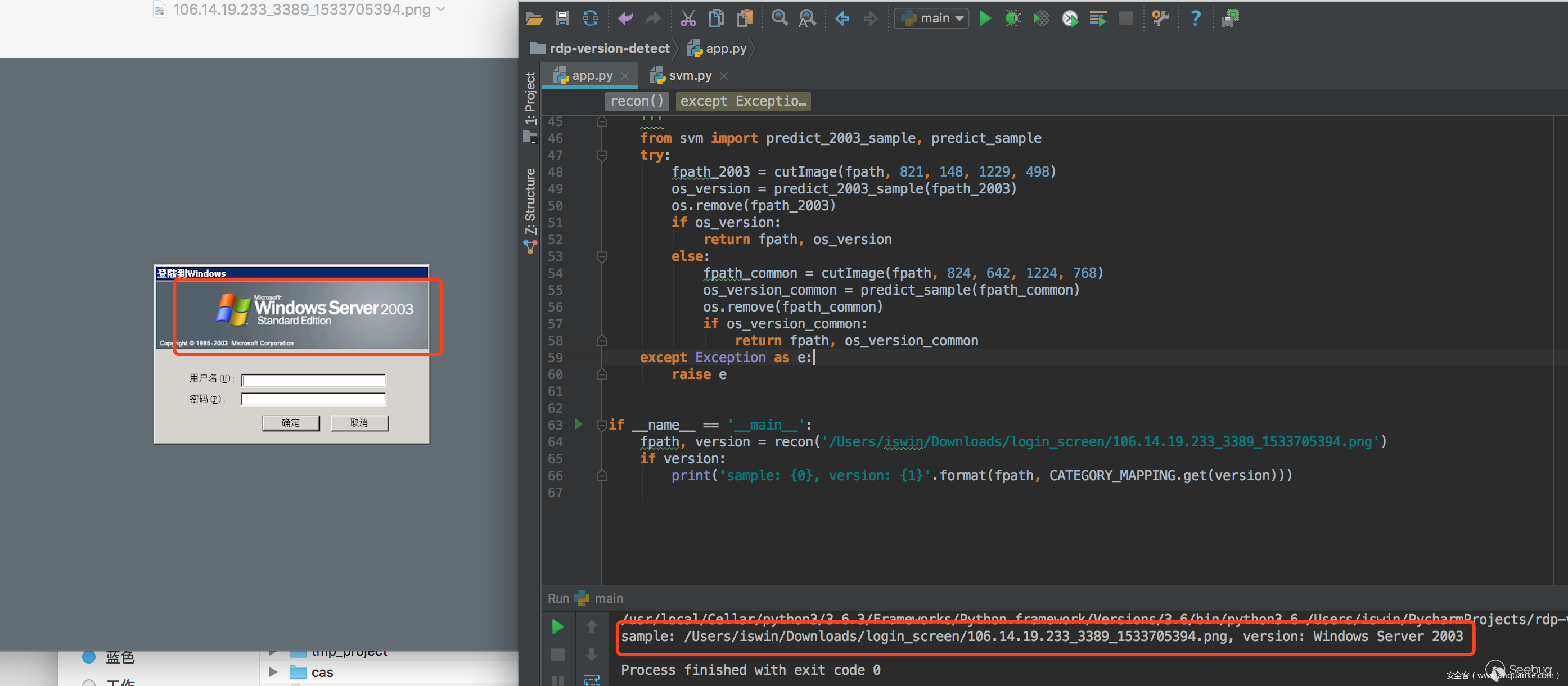
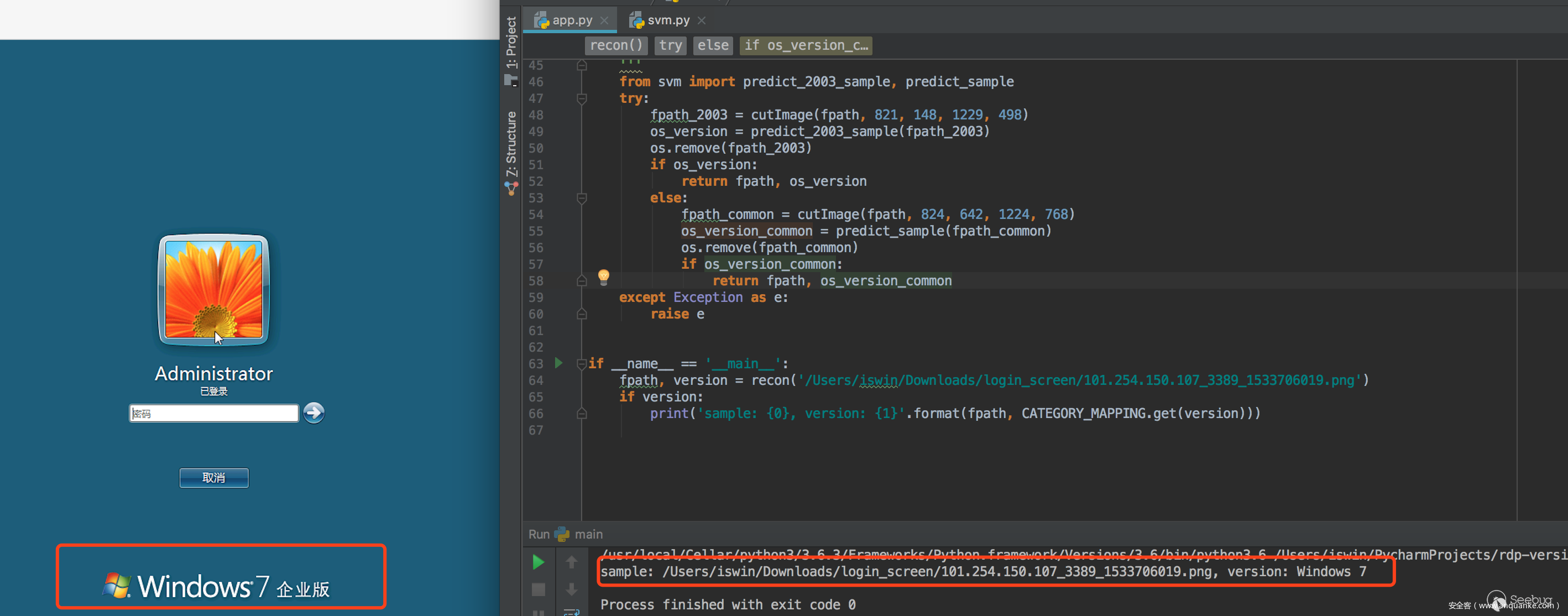
一條龍效果:
RDP后門檢測
上面簡單介紹了下RDP版本識別的一些內容,那么接下來將介紹下本文的重點內容,RDP版本識別實現的方式也比較多,而且效果比較好,利用的分析模型也都是大家平時都了解的。
關于RDP后門的識別,本文主要以shift后門為例,其它的放大鏡之類的和shift原理類似.
我們從shodan上面的采樣的結果來看,shift后門主要的幾種形式,如下圖
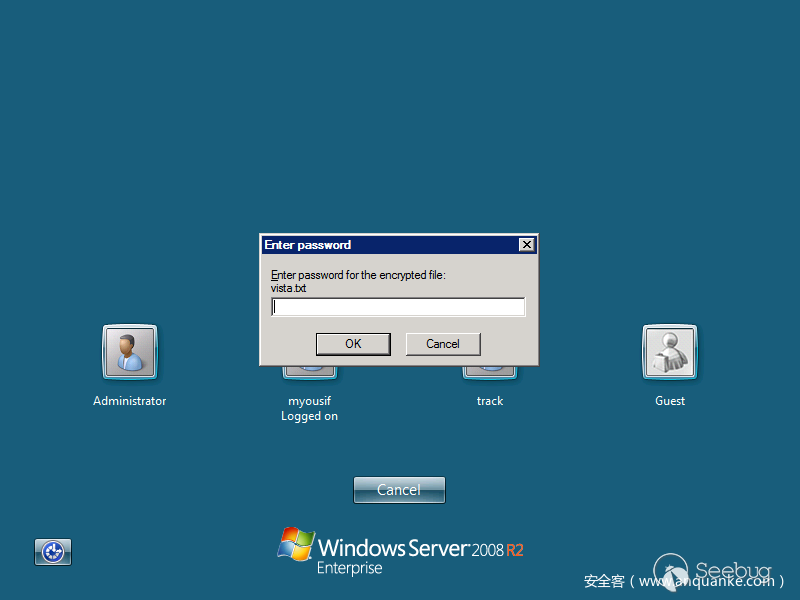
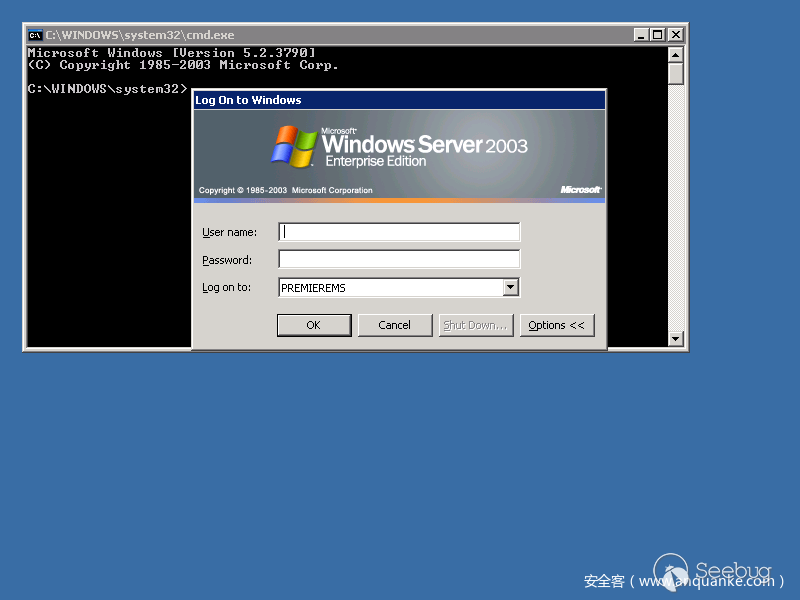
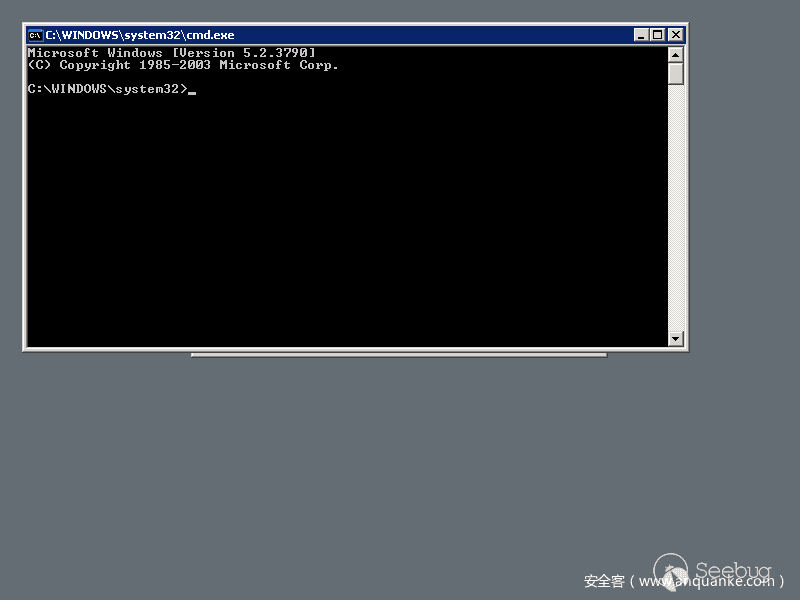

所以這里面面臨的問題就是shift后門位置不固定,大小不一樣,顏色不一樣,不同版本的彈框也不一樣。所以用圖像識別、固定位置截圖識別,或者說將圖片二值化后看黑白區域所占的比例(cmd框黑色占比比較大),包括利用之前的SVM進行標記訓練,都是不行的,識別效果太差了,例如shift框位置稍微變動下、大小稍微變動下,識別準確率就非常低。
在我們經過一段時間的調研之后,發現目標檢測算法(Object Detection)比較適用于我們當前的項目,目標識別的算法主要有R-CNN、Faster-R-CNN、YOLO等,這個算法目前以被tensorflow、keras、Caffe等框架實現,關于目標檢測算法的原理之類的,建議大家先從卷積神經網絡(CNN)去看相關paper,本文也只是目標檢測算法在安全上的一些應用的探索。
綜合幾個方面的因素,我們選擇了YOLO-V2來進行樣本訓練和識別(目前最新版本是YOLO-V3,但是測試的時候老是有GPU內存不足的問題,調整了訓練的batch_size還是不行,所以就回退到V2),YOLO主要是做目標識別以及實時圖像目標識別,由于YOLO 是屬于深度學習的范疇,最好你要有GPU的計算環境,否則用CPU來訓練的時候會非常慢。
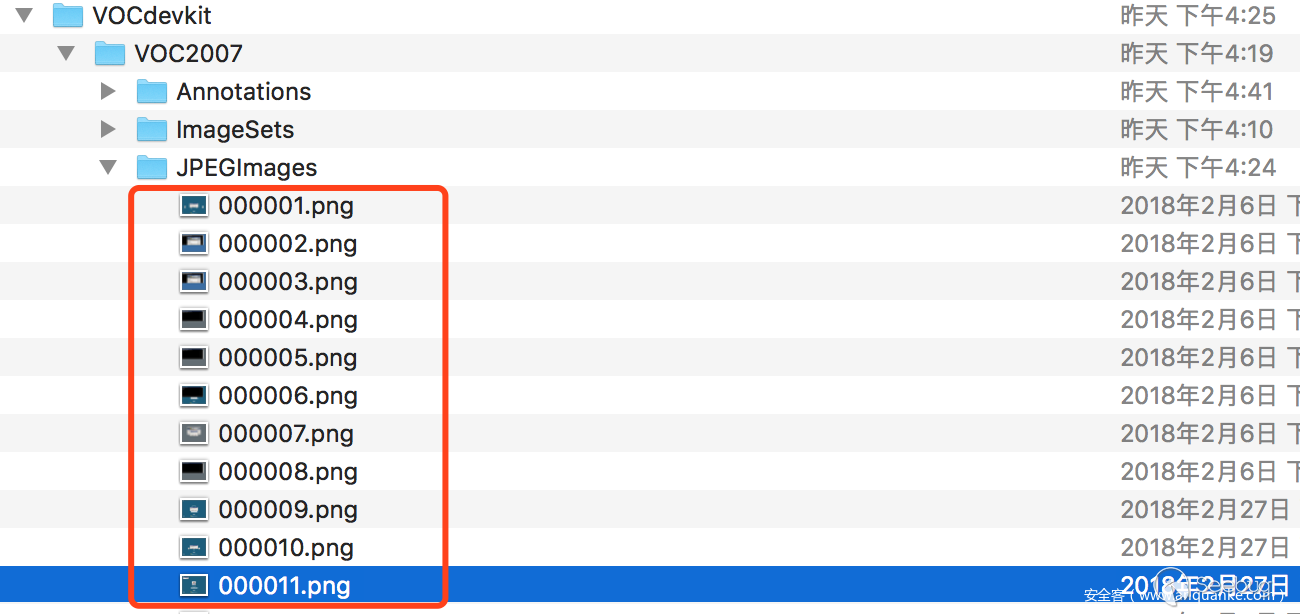
YOLO的使用大家可以參考作者的博客https://pjreddie.com/darknet/ ,這里有相關的原理Paper,當然還有一些訓練好的模型可以直接用,安裝過程就不詳細解釋了,包括GPU環境的編譯,作者博客上都有詳細的說明,YOLO是一個目標檢測框架,作者提供了兩種類型(PASCAL VOC、COCO)的數據集來進行模型的訓練,我們可以根據這兩種類型來定制自己的數據集來訓練自己的模型,本文采用PASCAL VOC2007類型來指定自己的數據集,PASCAL VOC2007數據集的目錄結構如下:

JPEGImages:包含了PASCAL VOC所提供的所有的圖片信息。
Annotations:存放對應圖片的xml格式的標簽文件。
ImageSets:主要是Main目錄下txt文件,存儲訓練樣本的文件名(不帶后綴)。
Labels:標記樣本的類型等信息。
其它文件夾在YOLO中沒有使用,感興趣的自己去查下。
首先我們將shift后門的樣本放在JPEGImages目錄,按照如下編號進行保存
圖片標記使用https://github.com/tzutalin/labelImg ,然后對每張圖片進行標記,我們目前只有兩個分類:normal_shift、shift_backdoor,例如
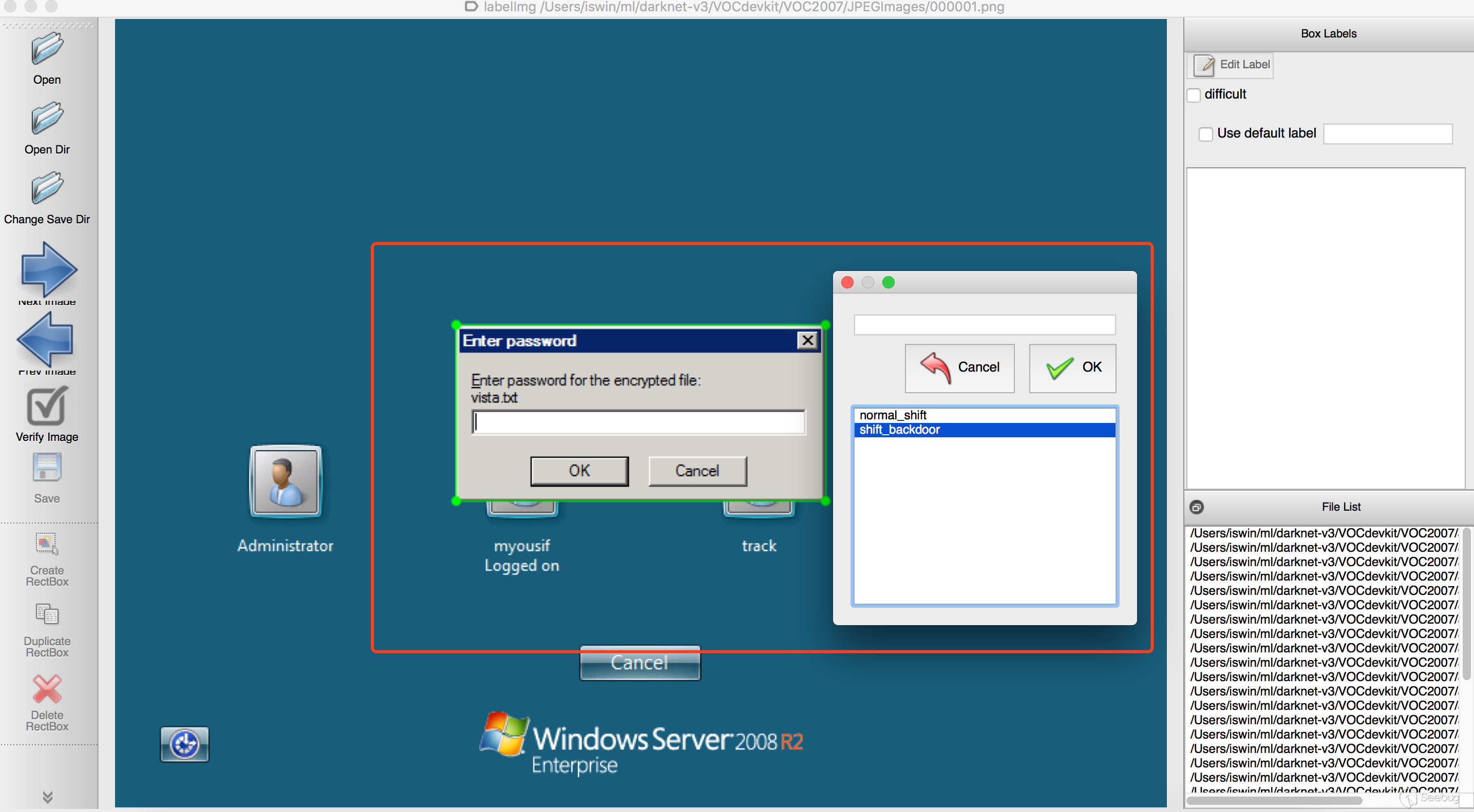
按照類似的方法將所有樣本進行標記,然后用voc_label.py 將標記好的xml信息轉換成相應格式的文件即可,這里這個工具在標注的xml文件中可能會出現width和height為0的情況,需要在標注后統一修正下圖片的大小。
修改YOLO的訓練的參數,這里主要涉及YOLO的三個文件cfg/voc.data、cfg/tiny-yolo-voc.cfg、data/voc.names,具體的參數信息大家可以根據自己的類別來設置,這里以兩個類別為例子。
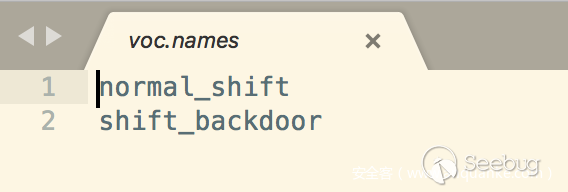
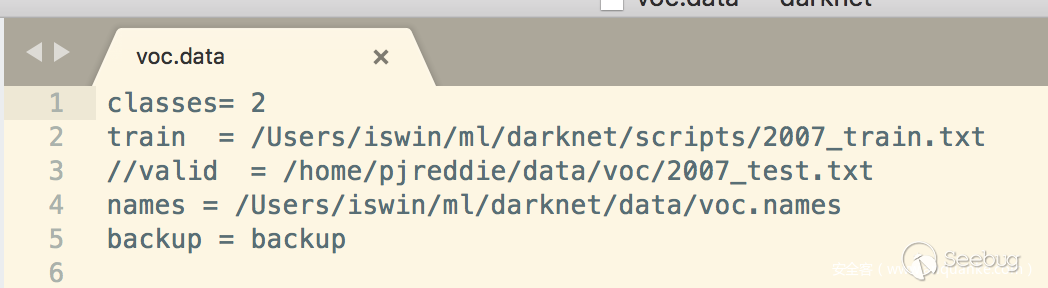
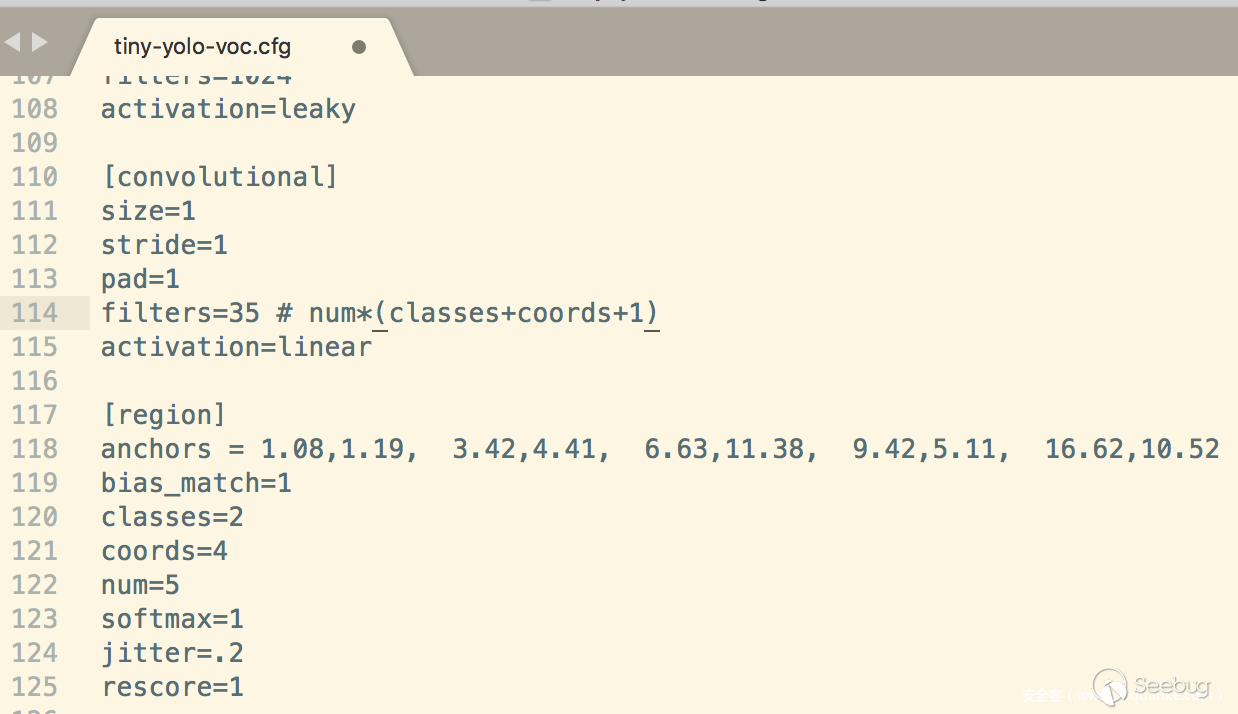
所有數據都準備好之后,我們就可以開始進行訓練,先看看裝備
注:訓練的初始權重可以在作者博客進行下載。
./darknet detector train cfg/voc.data cfg/tiny-yolo-voc.cfg darknet19_448.conv.23 -gpus 0,1,2,3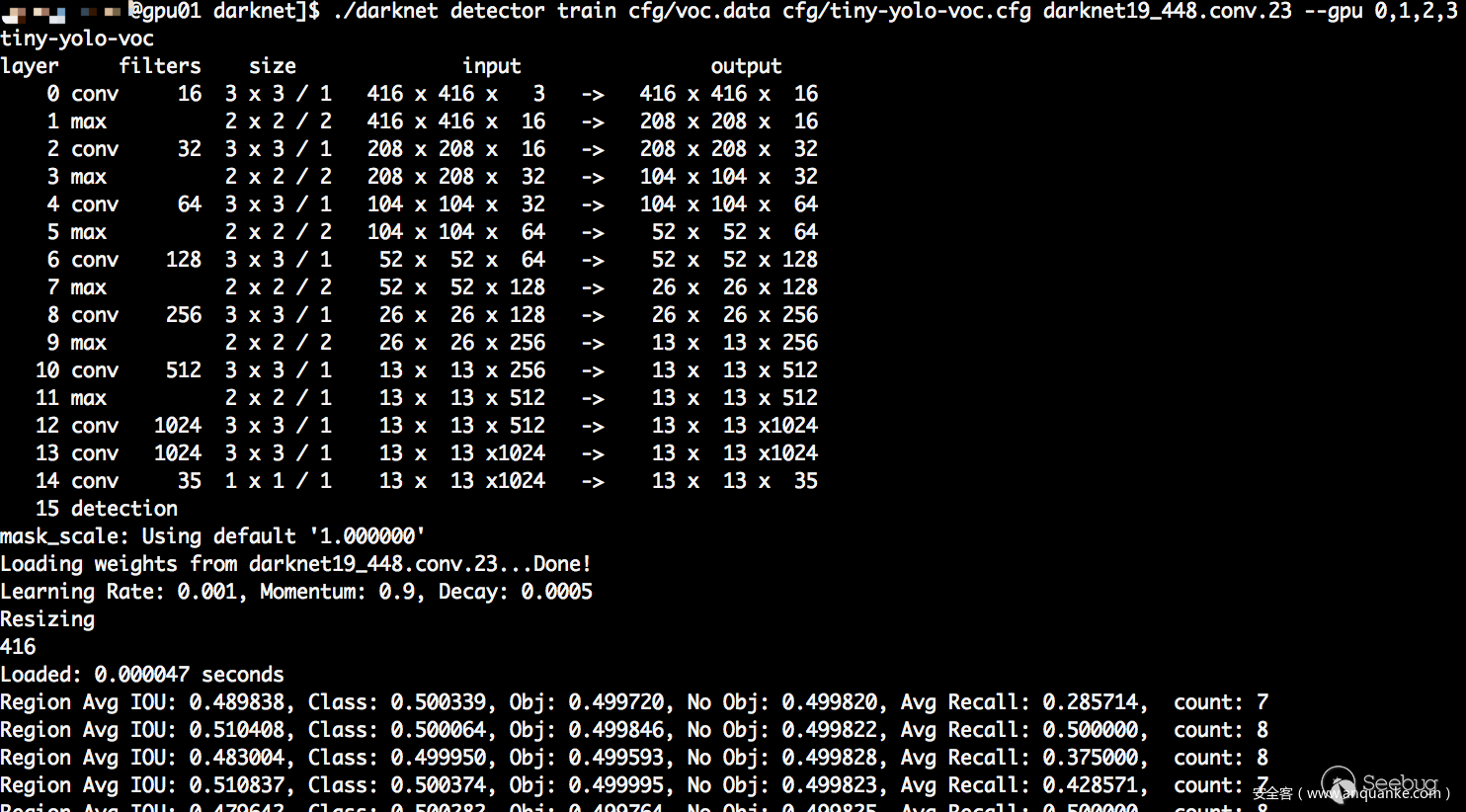
大約幾個小時之后(CPU的話大概1周左右,看性能),經過40000多次迭代直至收斂,在backup目錄下面會生成最終的權重文件:tiny-yolo-voc_final.weights,至此整個過程的標注和訓練工作已經完成。
識別的話我們項目用的是python,這里直接用 pip install darknetpy ,然后將最終的權重文件以及相關的配置文件按照要求正常調用就行了。
我們看看最終效果:
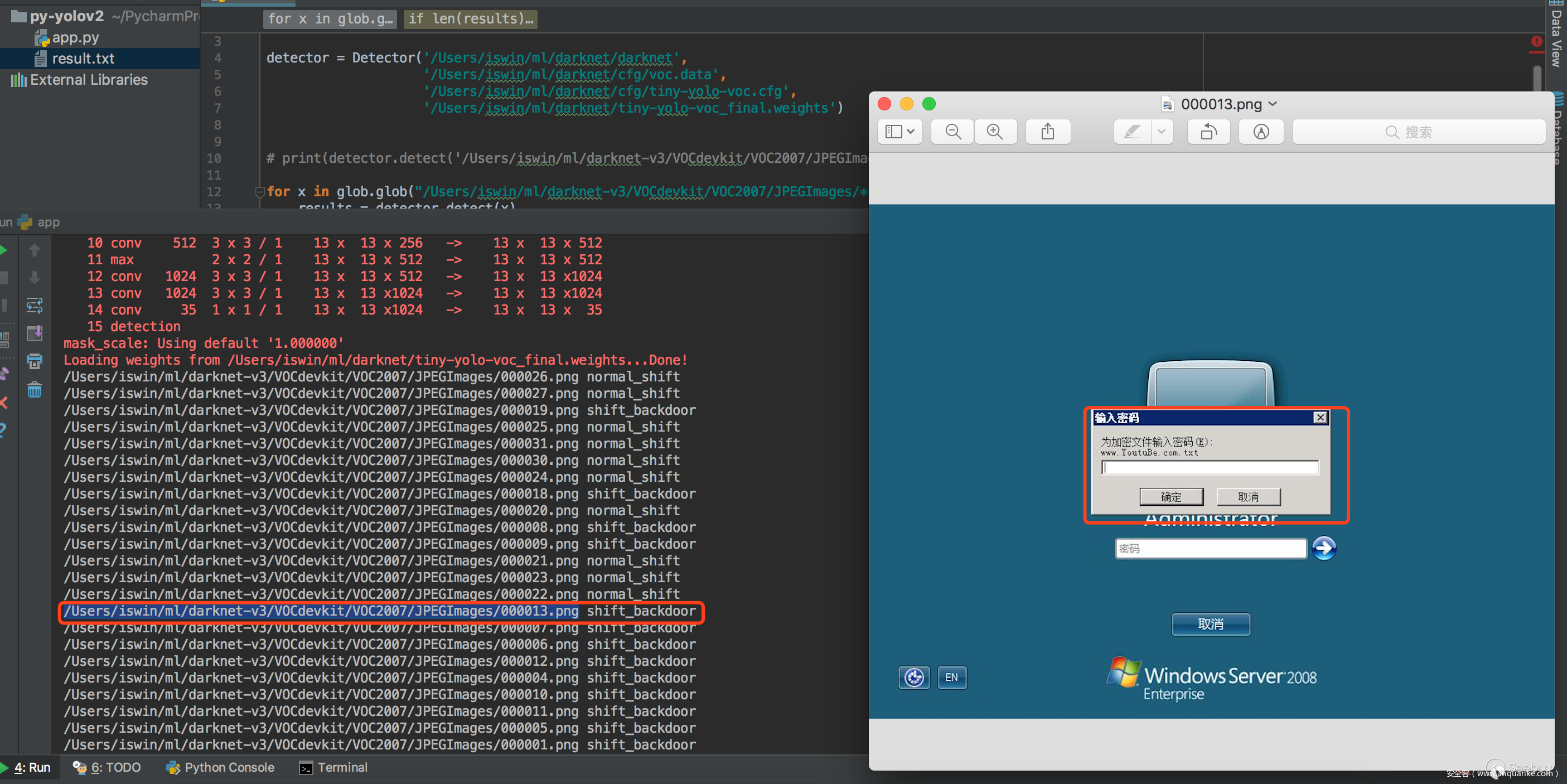
我們用于訓練的圖片大小是800600,我們這里用2048768的圖片來進行識別看看準確率如何。
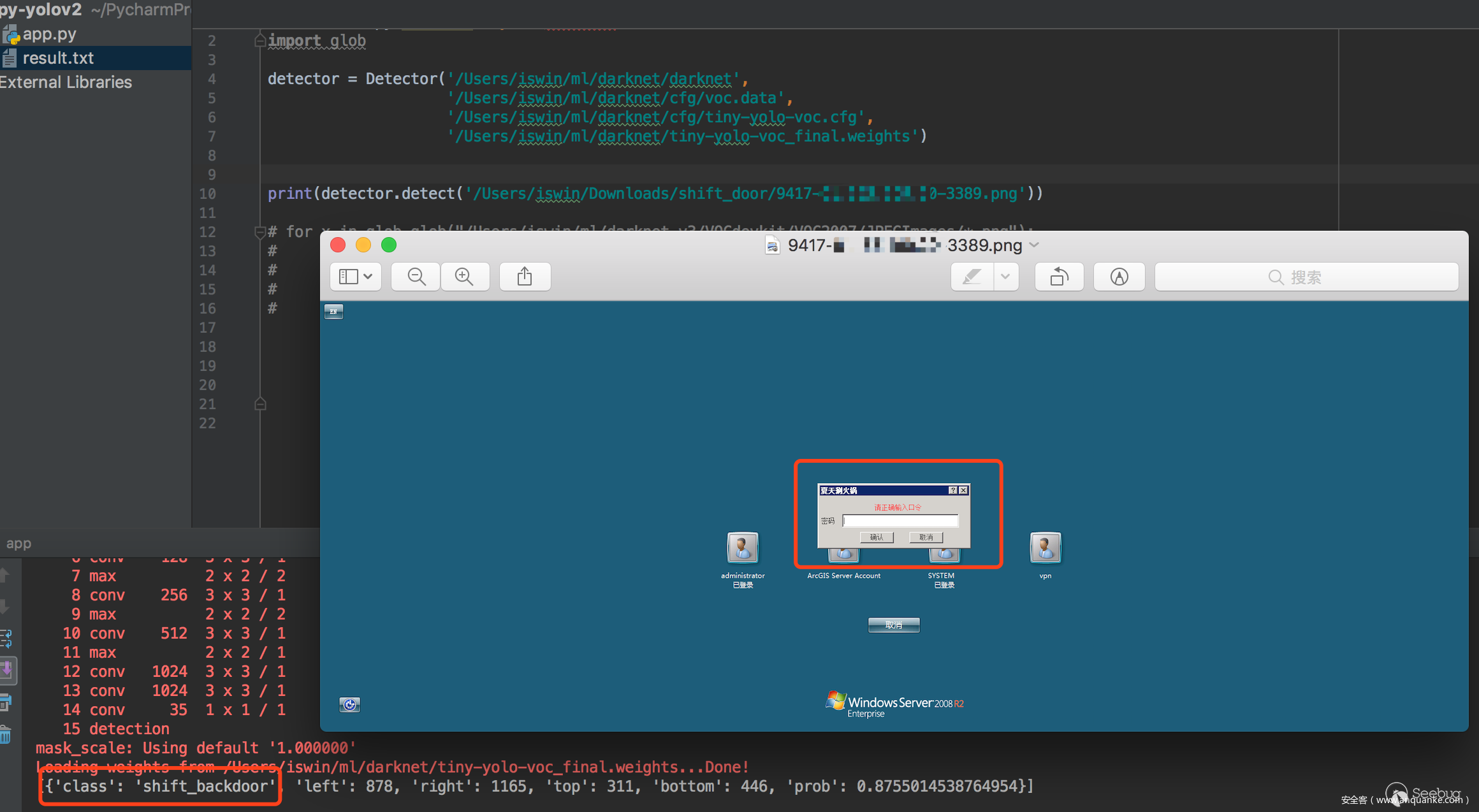
當然識別率這塊還有很多可以提高的地方,比如訓練的樣本集、圖片的進一步處理等。
RDP版本、后門全國分布
我們對中國互聯網側暴露的130w(數據來源:https://opendata.rapid7.com/sonar.tcp/ )開放3389端口的IP進行了分析,確定Windows開放遠程桌面的服務器大約為31W左右,通過對這31W的數據進行了分析研究,得出以下結論:
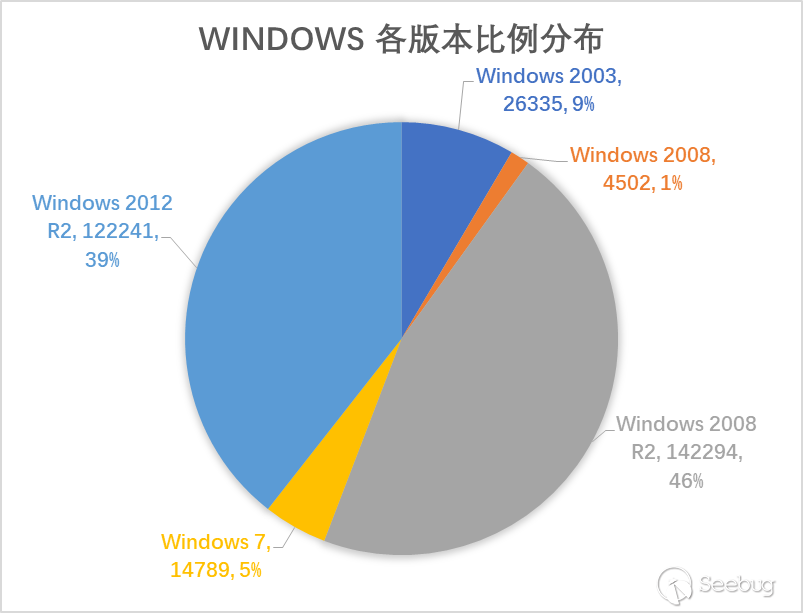
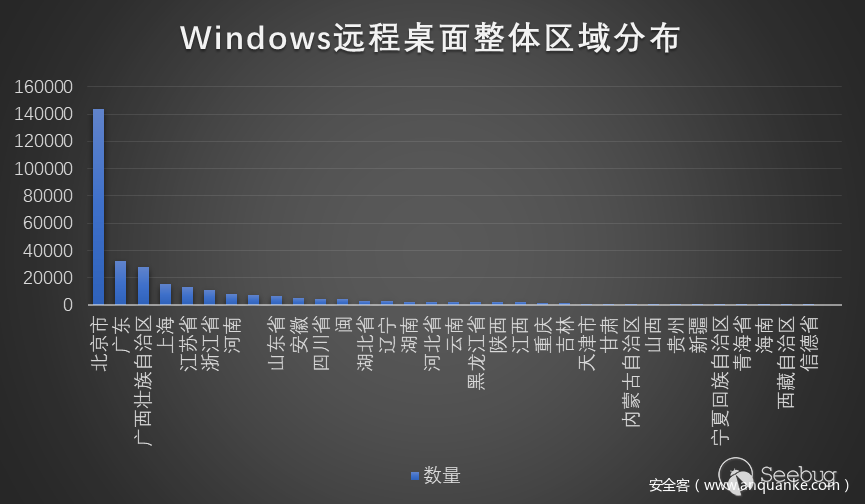
通過對31W開放的Windows遠程桌面服務器進行分析識別,發現了4500+ Shift后門,具體的shift后門分布如下:
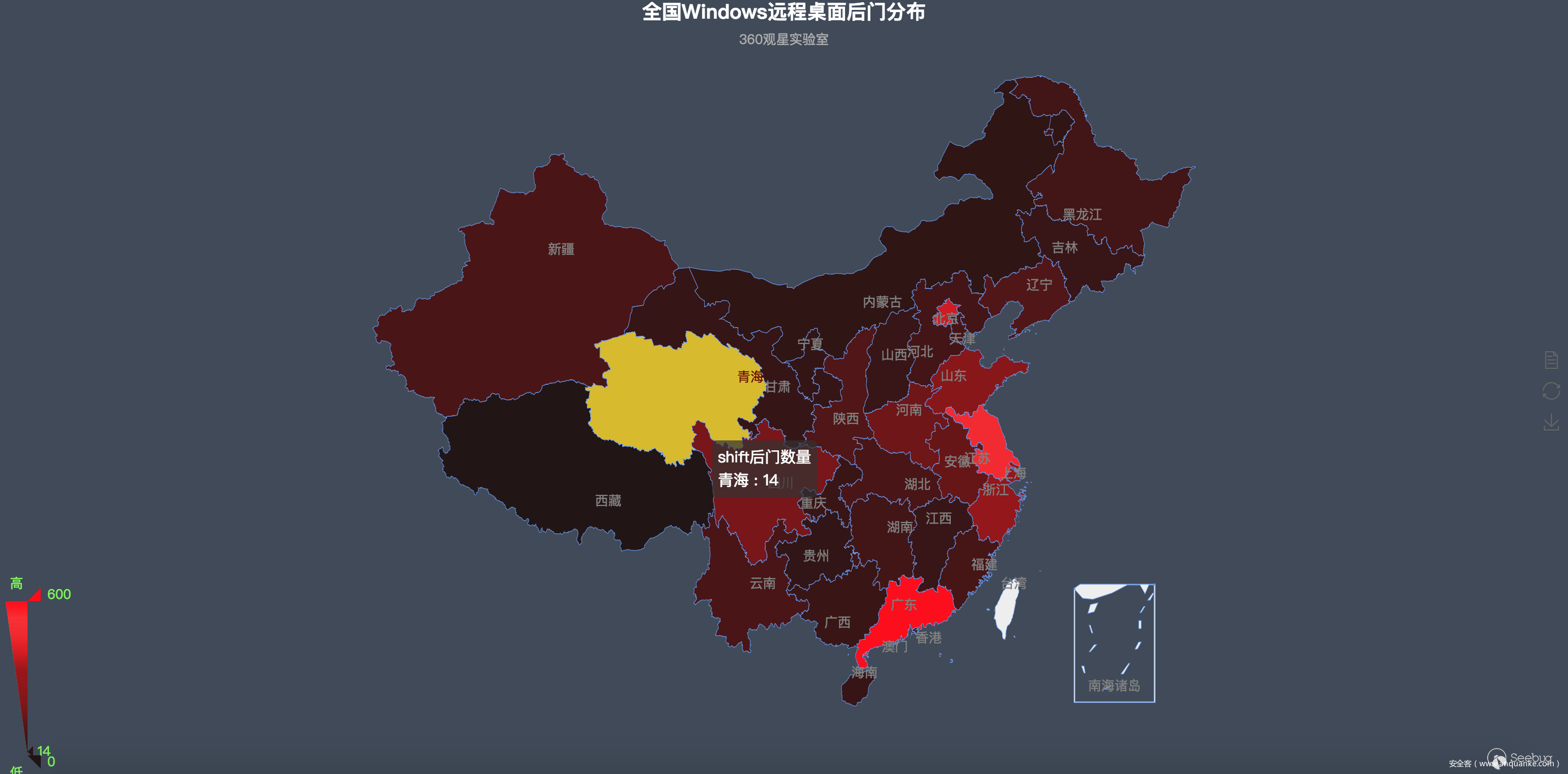
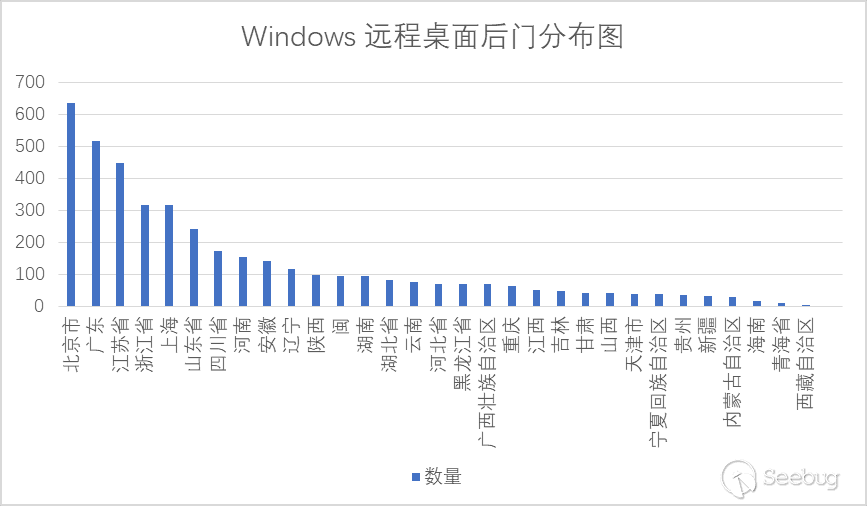
其中廣東、江蘇、北京、浙江、上海、山東是重災區,具體數量如下:
總結
Windows RDP 的后門變種是非常多的,本文提供的檢測方式只是最基礎的一種,這些后門也只是冰山一角。
對于那些非常隱蔽的后門的檢測我們還在探索之中,作為一個服務于廣大客戶的廠商來說,大規模、自動化的安全檢測還有很長一段路需要走,接下來我們也會結合新的技術去探索更具挑戰的威脅檢測。
當然如果你愿意同我們一起進行安全技術的研究和探索,請發送簡歷到 lab@360.net,我們期望你的加入。
參考鏈接
- https://pjreddie.com/darknet/yolo/
- https://github.com/citronneur/rdpy
- https://github.com/tzutalin/labelImg
- https://github.com/rbgirshick/py-faster-rcnn
- https://opendata.rapid7.com/sonar.tcp/
本文經安全客授權發布,轉載請聯系安全客平臺。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/678/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/678/
暫無評論