
作者:云鼎實驗室
互聯網最激烈的對抗戰場,除了安全專家與黑客之間,大概就是爬蟲與反爬蟲領域了。據統計,爬蟲流量早已超過了人類真實訪問請求流量。互聯網充斥著形形色色的爬蟲,云上、傳統行業都有不同規模的用戶被爬蟲愛好者盯上,這些爬蟲從哪里來?爬取了誰的數據?數據將被用于何處?
近日,騰訊云發布2018上半年安全專題系列研究報告,該系列報告圍繞云上用戶最常遭遇的安全威脅展開,用數據統計揭露攻擊現狀,通過溯源還原攻擊者手法,讓企業用戶與其他用戶在應對攻擊時有跡可循,并為其提供可靠的安全指南。本篇報告中,云鼎實驗室通過部署的威脅感知系統,捕獲到大量爬蟲請求流量以及真實來源 IP,且基于2018年上半年捕獲的數億次爬蟲請求,對互聯網爬蟲行為進行分析。
一、基本概念
1. 爬蟲是什么?
爬蟲最早源于搜索引擎,它是一種按照一定的規則,自動從互聯網上抓取信息的程序。
搜索引擎是善意的爬蟲,它爬取網站的所有頁面,提供給其他用戶進行快速搜索和訪問,給網站帶來流量。為此,行業還達成了 Robots 君子協議,讓互聯網上的搜索與被搜索和諧相處。
原本雙贏的局面,很快就被一些人破壞了,如同其他技術,爬蟲也是一把雙刃劍,變得不再「君子」。尤其是近年來「大數據」的概念,吸引了許多公司肆意爬取其他公司的數據,于是「惡意爬蟲」開始充斥互聯網。
本篇報告主要聚焦于「惡意爬蟲」,不討論搜索引擎爬蟲及合法爬蟲等。
2. 爬蟲的分類
按爬蟲功能,可以分為網頁爬蟲和接口爬蟲。
- 網頁爬蟲:以搜索引擎爬蟲為主,根據網頁上的超鏈接進行遍歷爬取。
- 接口爬蟲:通過精準構造特定 API 接口的請求數據,而獲得大量數據信息。
按授權情況,可以分為合法爬蟲和惡意爬蟲。
- 合法爬蟲:以符合 Robots 協議規范的行為爬取網頁,或爬取網絡公開接口,或購買接口授權進行爬取,均為合法爬蟲,該類爬蟲通常不用考慮反爬蟲等對抗性工作。
- 惡意爬蟲:通過分析并自行構造參數對非公開接口進行數據爬取或提交,獲取對方本不愿意被大量獲取的數據,并有可能給對方服務器性能造成極大損耗。此處通常存在爬蟲和反爬蟲的激烈交鋒。
3. 數據從哪來?
爬蟲不生產數據,它們只是數據的搬運工。要研究爬蟲,就得先研究數據的來源。尤其是對小型公司來說,往往需要更多外部數據輔助商業決策。如何在廣袤的互聯網中獲取對自己有價值的數據,是許多公司一直考慮的問題。通常來說,存在以下幾大數據來源:
- 企業產生的用戶數據
如 BAT 等公司,擁有大量用戶,每天用戶都會產生海量的原始數據。
另外還包括 PGC (專業生產內容)和 UGC (用戶生產內容)數據,如新聞、自媒體、微博、短視頻等等。
- 政府、機構的公開數據
如統計局、工商行政、知識產權、銀行證券等公開信息和數據。
- 第三方數據庫購買
市場上有很多產品化的數據庫,包括商業類和學術類,比如 Bloomberg、 CSMAR、 Wind、知網等等,一般以公司的名義購買數據查詢權限,比如咨詢公司、高等院校、研究機構都會購買。
- 爬蟲獲取網絡數據
使用爬蟲技術,進行網頁爬取,或通過公開和非公開的接口調用,獲得數據。
- 公司間進行數據交換
不同公司間進行數據交換,彼此進行數據補全。
- 商業間諜或黑客竊取數據
通過商業間諜獲取其他公司用戶數據,或者利用黑客等非常規手段,通過定制入侵獲取數據或地下黑市購買其他公司數據。此處商業間諜泄漏遠多于黑客竊取。
二、惡意爬蟲的目標
從前面總結的數據來源看,第三方數據庫購買或數據竊取的渠道都不涉及爬蟲,真正屬于惡意爬蟲目標的,主要是互聯網公司和政府相關部門的數據。
行業總體分布
通過對捕獲的海量惡意爬蟲流量進行標注,整理出惡意爬蟲流量最大的行業 TOP 10 排行,詳情如下:?
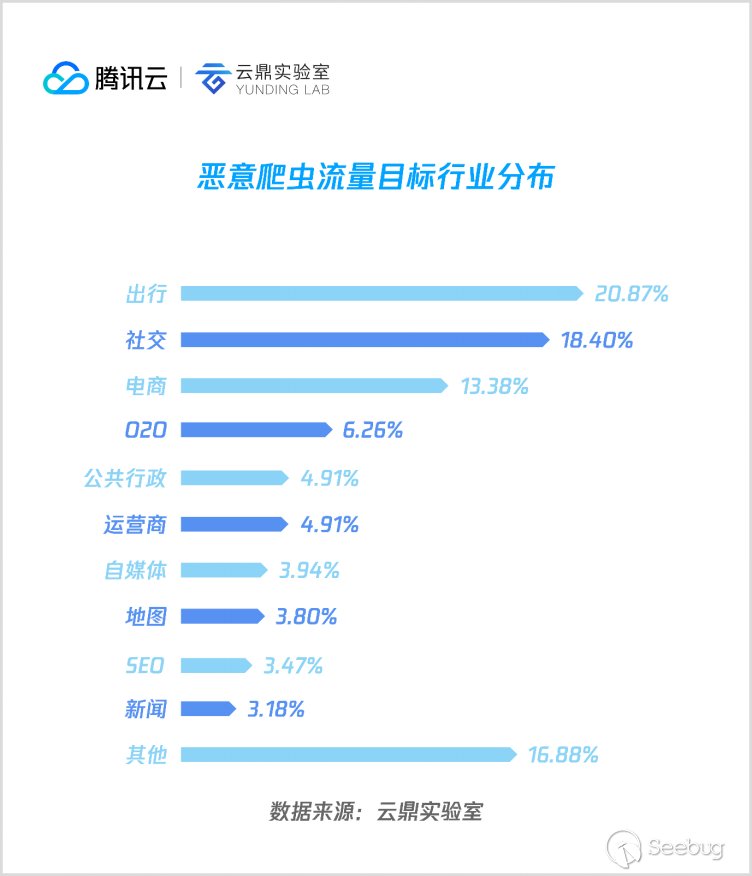
由統計可見,出行類惡意爬蟲流量占比高于電商與社交行業,居首位,其次是點評、運營商、公共行政等。接下來逐個行業進行分析:
1. 出行
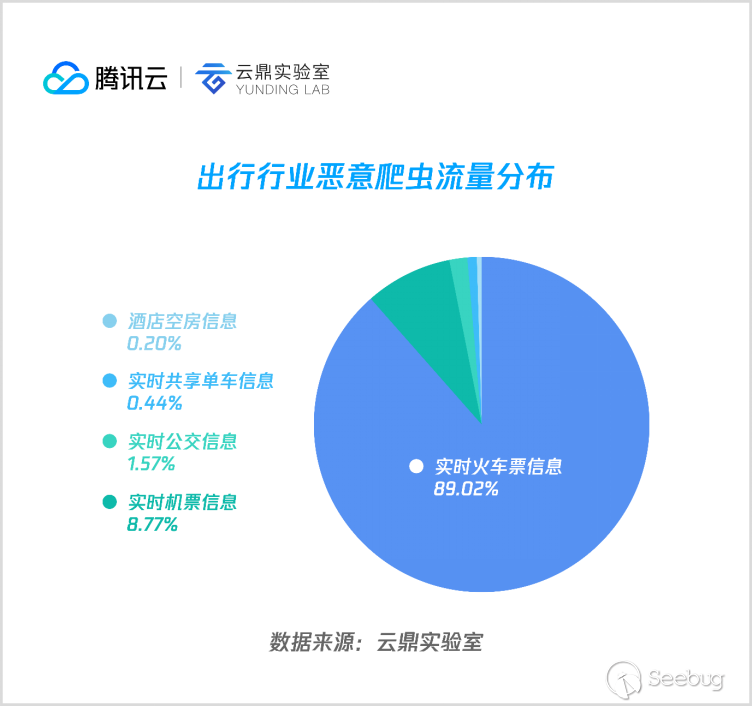
- 實時火車票信息
對火車購票平臺的惡意爬蟲訪問占據了出行行業近90%的流量,淺析可知其實比較合理,幾百個城市,幾千趟列車構成國內鐵路網,火車站與車次排列組合后是一個非常大的數據集,隨著人工購票快速向互聯網購票過渡,第三方代購和搶票服務商便越來越多,而任意一家要做到數據實時刷新,都需要不小的爬蟲集群,因此導致火車票購買站點成為爬蟲光顧最頻繁的業務。
- 實時機票信息
機票類占據出行類8.77%的惡意爬蟲流量,主要是爬取各大航空公司實時票價。
- 實時公交信息
主要爬取市內公交 GPS 信息。
- 實時共享單車信息
主要爬取特定區域周邊的實時共享單車信息。
- 酒店空房信息
酒店爬取占比較少,主要是刷酒店房價,與交通類比較可忽略不計。
2. 社交
由于國內的社交平臺多數以純 APP 為主,部分社交平臺并不支持網頁功能,因此捕獲到的社交類爬蟲主要集中在微博類平臺,以爬取用戶信息和所發布的內容為主。
3. 電商
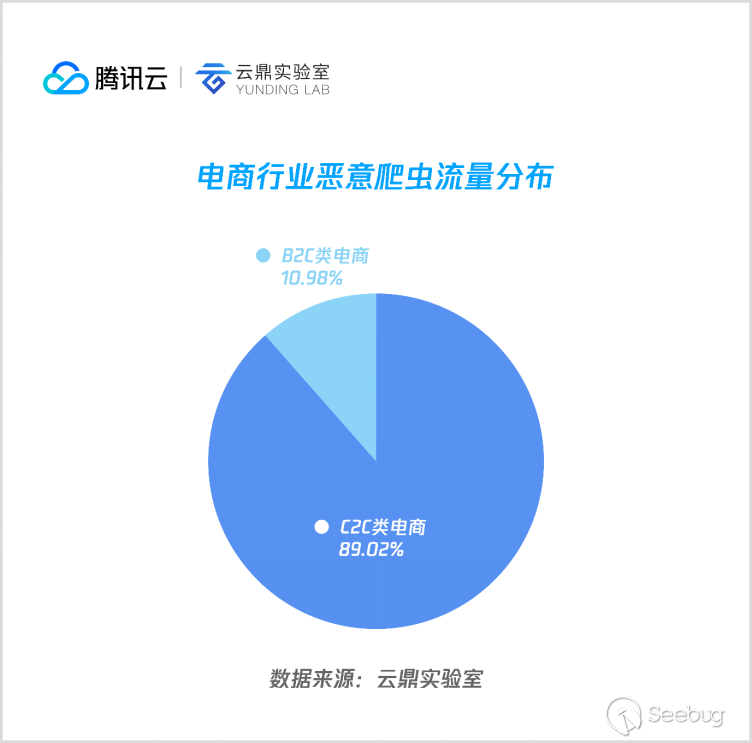
電商行業爬蟲主要是爬取商品信息和價格等數據,由于商業模式的差異,C2C 類電商由于中小賣家眾多,商品數量遠多于 B2C 類電商,支撐了電商類惡意爬蟲近90%流量, B2C 類電商加起來占一成左右。
4. O2O
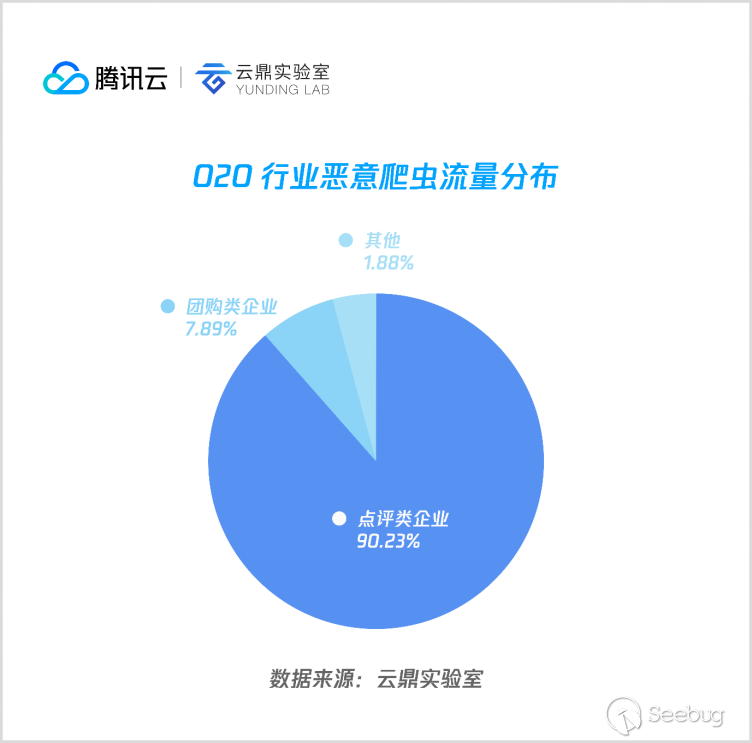
O2O 行業惡意爬蟲主要集中在點評類和團購類公司,其中以爬取商鋪動態信息和星級評分信息的點評類數據為主,占總數的90%以上。
5. 公共行政
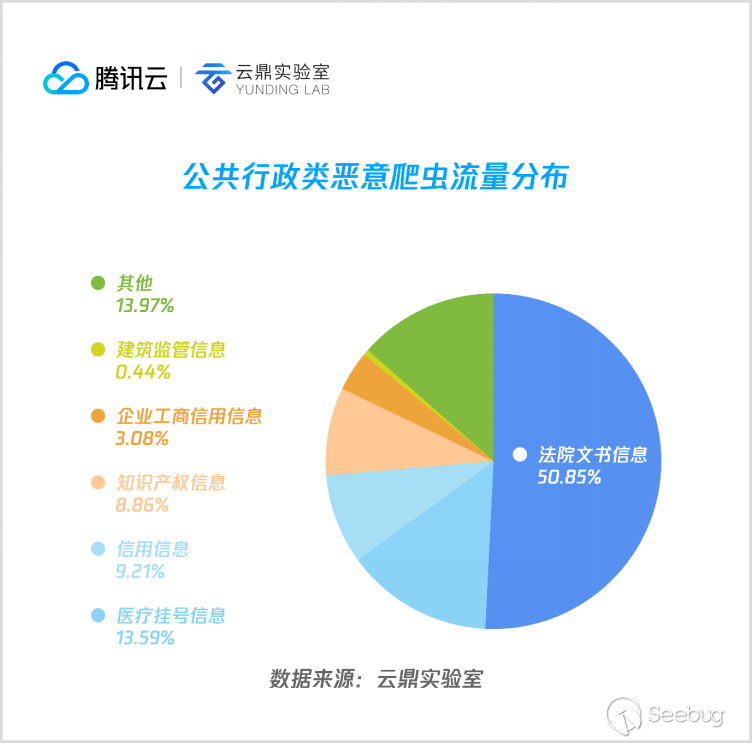
公共行政類惡意爬蟲主要集中在法院文書、知識產權、企業信息、信用信息等常規商業信息領域,而另一個受爬蟲青睞的是掛號類平臺,從數據來看應該是一些代掛號平臺提供的搶號服務。
6. 運營商
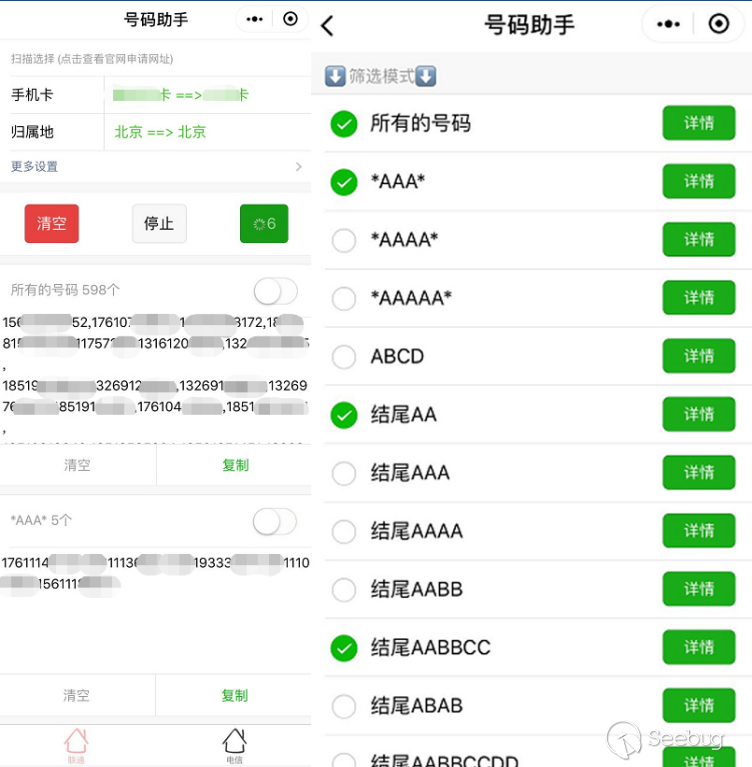
運營商的惡意爬蟲流量主要集中在運營商各種互聯網套餐手機卡的查詢。由于互聯網套餐手機卡存在較高的性價比,因此網絡上形成了相關的刷靚號、搶號、代購等產業鏈。
網絡上存在多種通過爬蟲技術進行靚號手機號搜索的工具,選擇手機卡類型,再不斷爬取待售手機號,尋找到符合理想靚號規則的號碼。下圖為某掃號工具截圖,可選擇數十種不同的互聯網套餐卡:
7. 自媒體
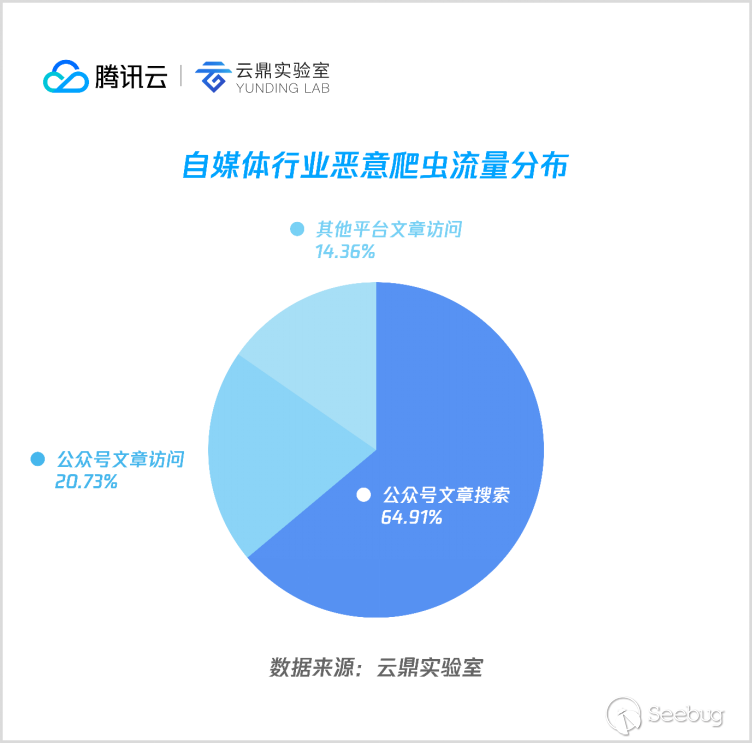
根據本次統計,自媒體類爬蟲主要集中于微信訂閱號關鍵詞搜索和文章訪問,分別占總量的64.91%和20.73%,其他自媒體平臺約占14.36%。
8. 地圖
地圖類爬蟲比較常規,主要是爬取地理位置周邊商戶詳細信息為主。
9. SEO
SEO 類惡意爬蟲通常是頻繁搜索相關詞匯,來影響搜索引擎的排名。
10. 新聞
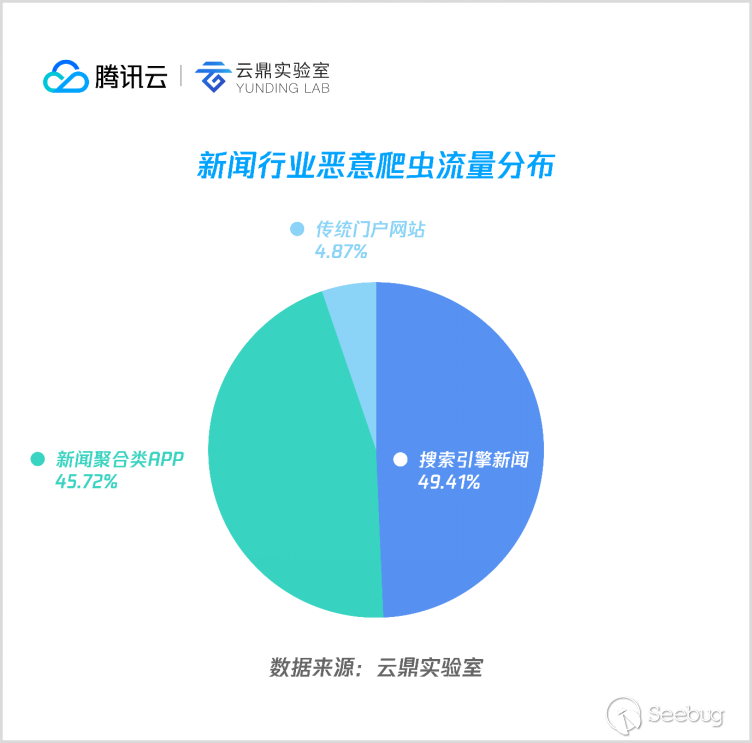
新聞類惡意爬蟲主要用于爬取聚合類新聞 APP 及各大門戶的新聞信息。以搜索引擎的新聞平臺和聚合類APP的數據為主,傳統門戶類爬蟲較少光顧。
11. 其他
其他主要被爬蟲光顧的領域還有新聞、招聘、問答、百科、物流、分類信息、小說等,不進行一一列舉。
三、爬蟲來源 IP 分布
1. 國家分布
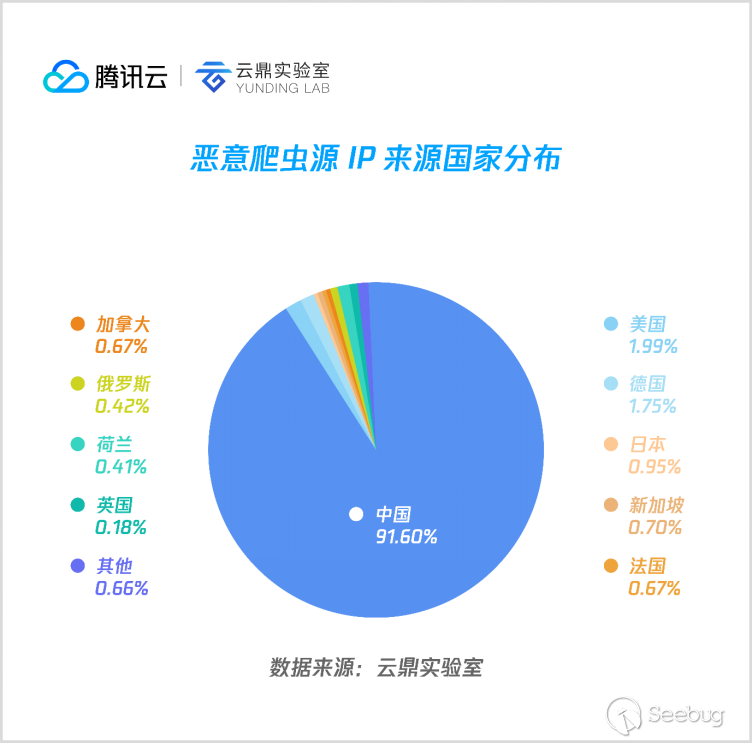
從本次半年度統計捕獲到的爬蟲流量源 IP來看,大部分都來自國內,超過90%,其次主要來自美國、德國、日本等國家。
2. 國內分布
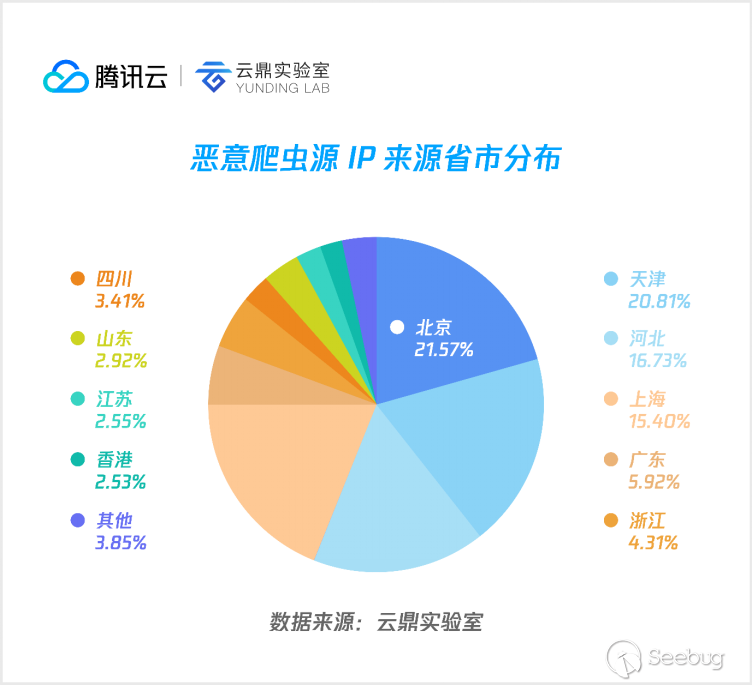
將源自國內的數據抽出來進行細分,可以看到,主要來自北京、天津、河北、上海等省市,以上4個地區所占國內惡意爬蟲流量超70%。這并不是因為爬蟲作者都來自這些地區,而是因為大量的爬蟲部署在租用的 IDC 機房,這些機房大多在發達省市。
3. 網絡分布
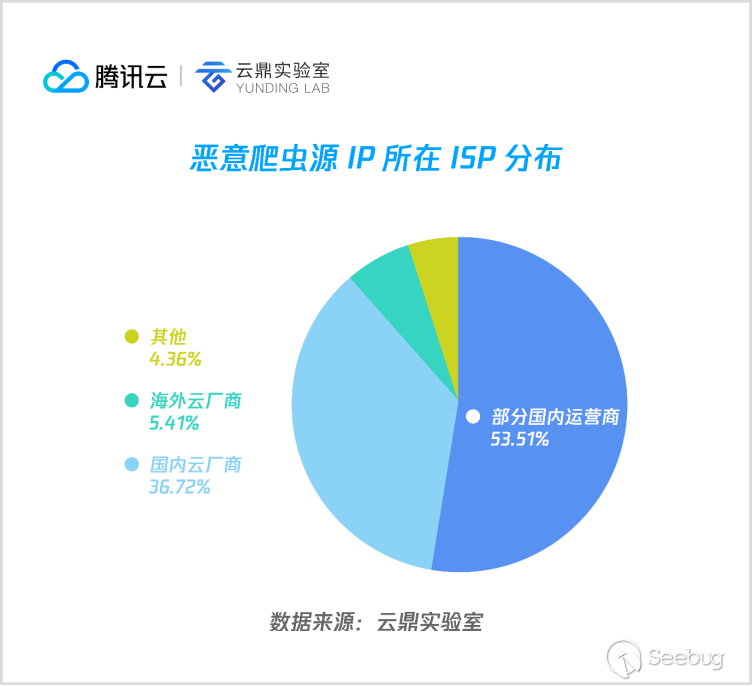
該圖是惡意爬蟲源 IP 的網絡分布,可以看到,超過一半來自國內運營商網絡,而這其中大比例是源自運營商的 IDC 機房。云計算廠商方面,國內主要云廠商都有上榜。
整體數據來看,惡意爬蟲絕大部分都是來自 IDC 機房,隨著惡意程序云端化,云計算廠商應當對云資源被濫用的情況進行及時了解和處理。
四、爬蟲與反爬蟲的對抗
作為互聯網對抗最激烈的戰場之一,說到爬蟲,就不能不提反爬蟲。當反爬蟲工程師對爬蟲進行了反殺,爬蟲工程師也不會任人宰割,很快又研究出了各種反對抗技術。
1.對手是誰
爬蟲和反爬蟲的斗爭由來已久,要想做好反爬蟲,先要知道對手有哪些,才好制定相應的策略。反爬蟲工程師的對手通常來自以下幾類:
- 應屆畢業生
每年三月份左右通常會有一波爬蟲高峰,和應屆畢業生(本科、碩士、博士)有關,為了讓論文有數據支撐,他們的爬蟲簡單粗暴,忽略了服務器壓力,且人數不可預測。
- 創業小公司
初創公司缺少數據支撐,為了公司生存問題,爬取別家數據,不過通常持續不久,較易被反爬蟲手段逼退。
- 成型的商業對手
反爬蟲工作最大的對手,有錢有人有技術,如果需要,會通過分布式、跨省機房、ADSL 等種種手段進行長期爬取。如果雙方持續對抗,最終的結果可能會是彼此找到平衡點。
- 失控爬蟲
許多爬蟲放于服務器運行后,就被程序員忘了,它們或許早已爬不到數據了,但依然會孜孜不倦地消耗服務器資源,直到爬蟲所在服務器到期。
2.技術對抗
猶如安全專家和黑客之爭,爬蟲工程師和反爬蟲工程師也是相愛相殺、你來我往、螺旋上升。經過幾番的技術升級,常用的反爬蟲及對應的反反爬蟲方案如下:
- 驗證碼
驗證碼是最常用的反爬蟲措施,但簡單驗證碼通過機器學習自動識別,通常正確率能達到50%以上甚至更高。
復雜驗證碼通過提交到專門的打碼平臺進行人工打碼,依據驗證碼的復雜度,打碼工人平均每碼收1-2分錢。也同樣容易被繞過,使得數據容易被爬取。
- 封 IP
這是最有效也最容易誤殺的方案。該策略建立在 IP 稀有的前提下,目前通過代理池購買或者撥號 VPS 等方式,可以低成本獲取數十萬的 IP 池,導致單純的封IP策略效果越來越差。
- 滑塊驗證
滑塊驗證結合了機器學習技術,只需要滑動滑塊,而不用看那些復雜到有時人眼也無法分辨的字母。但由于部分廠商實現時校驗算法較為簡單,導致經常只需要相對簡單的模擬滑動操作就能繞過,從而使得數據被惡意爬取。
- 關聯請求上下文
反爬蟲可以通過 Token 或網絡請求上下文是否進行了完整流程的方式來判斷是否真人訪問。但對具有協議分析能力的技術人員來說進行全量模擬并沒有太大困難。
- javascript 參與運算
簡單的爬蟲無法進行 js 運算,如果部分中間結果需要 js 引擎對 js 進行解析和運算,那么就可以讓攻擊者無法簡單進行爬取。但爬蟲開發者依然可以通過自帶 js 引擎模塊或直接使用 phantomjs 等無端瀏覽器進行自動化解析。
- 提高數據獲取成本
當面對的是職業選手時,只能通過提升對方人力成本來實現,比如代碼混淆、動態加密方案、假數據等方式,利用開發速度大于分析速度的優勢,來拖垮對方的意志。如果對方咬定不放松,那只能持續對抗,直到一方由于機器成本或人力成本放棄。
當對抗到了這個階段,與安全對抗一樣,技術之爭就進入了鏖戰的「平衡期」,此時反爬蟲工程師對抗掉了大部分的低級玩家,剩下的高級爬蟲工程師也默契的保持一個不給服務器太大壓力的爬取速度,雙方猶如太極推手,那下一步如何打破這個平衡?
五、對抗新思路:云端 AI 反爬蟲
爬蟲和反爬蟲的對抗,在云計算成為趨勢后,逐漸加入了第三方勢力,云計算廠商可直接為企業提供云端反爬能力,將戰局從反爬蟲與爬蟲的1v1 變成了企業+云廠商與爬蟲 的2v1,助力企業的反爬能力。
尤其是近年來 AI 技術不斷突破,為解決許多問題提供了全新思路。基于這個角度,云鼎實驗室通過深度學習技術對海量真實惡意爬蟲流量進行分析,認為將 AI 技術引入反爬蟲領域能起到極好的補充效果,將是未來此類對抗領域的趨勢所在。
為此,騰訊云網站管家(WAF)聯合云鼎實驗室基于海量真實爬蟲流量建立更為通用的爬蟲識別模型,已卓有成效,后續將致力于把最強的識別能力開放給各企業。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/645/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/645/