
作者:oxen@EnsecTeam
公眾號:EnsecTeam
我們專注漏洞檢測方向:danenmao、arnoxia、皇天霸、lSHANG、KeyKernel、BugQueen、zyl、隱形人真忙、oxen(不分先后)
提示:文章主要介紹漏洞掃描服務的衡量指標及如何解決的一些實踐經驗思考,大概閱讀完所需時間15分鐘左右
上一篇:《分布式Web漏洞掃描服務建設實踐系列——掃描架構演進及要點問題解決實踐》
一 引 言
一款掃描產品上線后,我們經常會反思到底做得怎么樣呢?那么如何去衡量一款掃描器的優劣呢?我們確定了幾個指標:準確率、掃描及時度及自主發現率,通俗來講就是如何更快、更全、更準、更智能的去掃描,或者說如何能達到一種完美的平衡,下面從這四個維度去闡述一下我們的實踐及思考。
二 衡量指標及解決思路
(一)更快(掃描及時度)
更快:更及時發現漏洞,甚至追求在攻擊者之前發現安全漏洞,但有一些殘酷現實擺在面前:
- 線上業務存在數千萬的url需要掃描(截止目前數據中心已經收集超過7千萬url,并且已經根據url進行了去重去臟處理);
- 存在眾多安全漏洞掃描poc(光通用漏洞poc單個url發包量粗略估計10000+以上,還不包括第三方已知漏洞poc);
- 需要根據業務線承壓能力進行限速(小的產品線能夠承載的qps小于50/s):這意味著即使不考慮poc本身掃描時間,光考慮限速單個url掃描就需要3.3分鐘,再加上poc本身運行時間、集群調度時間,單個url總掃描時間肯定大于3.3分鐘。
我們期望一輪線上所有業務例行掃描能夠在3小時以內解決戰斗,甚至期望能夠做到1小時以內;集群形態時考慮的就是增加機器資源,通過足夠的機器資源來提升掃描性能,即使不考慮資源成本,但因為有限速的限制,累加資源最終也會遇到瓶頸,況且真沒這么多機器(偷笑);這條路看來是走不通的,還是得從源頭進行解決:
1.降低掃描量
數據中心中存在6千萬url(已經經過了前面介紹的基于hash的url處理過程),但是有多少url是應該掃描或值得掃描?如果無區別的進行同等掃描估計一個月都沒法完成一輪掃描,這里需要方法將數據中心中應該掃描的url抽取出來,減少掃描的url量。我們的思路是:
(1)抽取待掃描URL:通過url頁面內容變化來判斷當前url是否值得或需要掃描,這個過程中需要排除動態內容對內容相似性對比的干擾(默認認為內容存在變化才需要二次掃描);同時存在后端邏輯變化未反映到頁面內容的情形,這種該如何進行識別?完全識別應該是做不到的,只能借助其他手段輔助進行判斷;比如可以通過數據分析統計出同一域名下不同url的訪問順序,通過順序的變化來輔助判斷,甚至可以統計不同url的訪問量,通過訪問量的變化來進行判斷等,可以綜合這些因素進行考慮篩選;
(2)分階段進行:第一階段優先掃描當天庫中新增URL(url第一次掃描),第二階段每半周掃描一次庫中有變動的URL,第三階段每月掃描一次庫中全量URL,主要用于彌補后端邏輯有變化但是未引起頁面內容變化,導致第二階段掃描無法覆蓋的case。
(3)分類進行:如果url實在太多,這里只能進行取舍,可以按照業務重要性及業務風險情況等維度進行url分類,優先去掃描既重要又風險大的業務。
2.降低poc發包量
針對常見通用安全漏洞,全部重新調研目前的主流掃描方案,然后結合自身經驗進行充分思路碰撞形成新掃描方式,同時將poc發包量作為重要考量因素始終貫穿其中,達到換一種掃描思路來降低poc發包量;這里以反射型xss為例,傳統掃描方案:收集盡可能全的payloads(至少70+),通過遍歷每一個payload發包去驗證是否存在漏洞,這里首先不考慮因payloads收集不全而造成漏報的問題,實際上這種情況發生的概率其實不低,就單單從發包量來考慮,單個參數就需要發包70+,一個url按照10處來估算(一個url需要掃描的位置有:headers、path、參數等),單個url至少發包700+,這從速度來考慮簡直是災難。
而新的掃描方案單個參數只需要發包7次不到(包括6次探測包+1次驗證包),通過發送探測包(包括“<>’”/*=”、“’”、“””等)來確定xss輸出的漏洞點及漏洞發生的具體場景,然后針對其發生場景針對性的構造一個payload進行驗證是否存在漏洞即可,相對于傳統掃描方案,性能提升了將近10倍。
3.限速
業務的承壓能力越強,限速QPS可以放得更寬,相應掃描速度就會越快,尷尬是我們擁有數萬域名量,主要里面還有一些小產品線,過高的QPS甚至可以將小產品線掃掛,在沒有方法知曉產品線承壓能力情況下,只能按照最低限速50QPS進行統一限速掃描; 但實際情況是不同業務線抗壓能力相差甚遠,統一按照50QPS進行限速將嚴重影響掃描速度,這里急需根據不同業務線進行逐個的限速設置,不過這里缺乏參照標準,只能借助于業務線的訪問量進行大概估計。其實最理想的狀態是,能否根據當前業務的響應狀態來動態調整發包量?通過發包來確定業務線當前響應的快慢,只要業務線沒有響應延遲的情況發生,便可動態調整發包量,從而做到根據業務線實際情況進行限速適配;不幸的是,由于網絡延時的變化造成動態調整效果不甚理想,還有一段路需要走,或者是否存在其他更好的方式?
(二)更全(自主發現率)
更全:主要關注漏報率,反過來說就是主動發現率;造成漏報概括起來就兩點:第一掃描能力不覆蓋,第二能力覆蓋,但是由于缺乏輸入源或者平臺產生異常;為了做到更全,我們就需要考慮:
- 覆蓋能覆蓋的一切Web漏洞類型;
- 收集最全的url作為掃描輸入源;
- 建立完善的監控追蹤體系,實時監控,第一時間恢復。
理想很美好,可問題是:
(1)漏洞類型,特別是弱點規則成百上千需要收集和整理,這是一個浩大的工程,并且為了掃描的準確性,需要一一搭建本地環境進行驗證確認;
(2)存在一些漏洞類型依靠之前傳統的掃描思路很難解決,或者說不適合以掃描來解決,并且還是一些非常高危的漏洞類型,比如越權、無回顯漏洞等;
(3)掃描之前一直以IDC全流量作為掃描的輸入源,可問題是全流量并沒有全機房覆蓋,同時由于帶寬及跨機房傳輸問題,全流量一直存在30%-40%丟失的問題,更重要的是全流量缺乏post請求類型及https流量,可post流量是檢測某些漏洞類型的基礎,比如存儲型xss,而https是未來發展的趨勢。
為了解決這些難題,我們的思路是:
1.規則收集
Web漏洞類型其實范圍挺廣泛,從掃描的角度來看,主要可以分為通用未知漏洞、第三方已知漏洞、主機弱口令、弱點規則等;比較麻煩的是第三方已知漏洞和弱點規則的收集整理,說實話沒有捷徑可走,只能通過人工去進行篩選收集;針對弱點規則,唯一比較欣慰的是可以通過SRC報告的歷史漏洞進行查漏補缺,但對于第三方已知漏洞就只能通過公開漏洞庫、官方安全消息進行補充,這需要專門的人力進行,特別針對歷史的漏洞,更需要大量人力去搜集整理,這時候安全社區的優勢就體現出來了,要么去和安全社區合作,要么就只能通過SRC以安全社區的思路進行收集,依靠小部分人力總會有所遺漏。
比較慶幸的是,我們有IDC全流量(其實全流量是個寶貝),將全流量導入到waf規則集,關注攔截的記錄中是否存在掃描所遺漏的規則;同時針對waf未識別的流量進行流量分析,通過機器學習的方法來識別出潛在感興趣記錄,然后人工分析來識別規則是否覆蓋;當然前提是需要擁有眾多業務,攻擊者也希望以此作為目標進行掃描探測或攻擊嘗試。
2.非傳統掃描方式
Web存在一部分漏洞,按照傳統思路其實不適合掃描,或者說很難掃描,這時候需要換種思路進行考慮,比如通過xss平臺解決一部分存儲型xss的難題,通過回顯平臺去解決無回顯漏洞的難題,同時我們還會去嘗試以掃描的方式去解決部分csrf,甚至去嘗試解決越權訪問的難題。
其實就是換種思路讓不可能變成可能,接著說存儲型xss,其掃描的難點就在于輸出點定位,大部分掃描方式只能遍歷同一域名的所有url來尋找輸出點,這種檢測思路對于大型互聯網企業來說簡直就是災難(根據上面更快的分析邏輯),我們需要另尋思路,除了依賴上面的xss平臺解決一部分case,還有其他方式嗎?其實是有的,我們可以思考存儲型xss最可能出現在哪?其實最有可能出現在一個請求的直接響應中,或者出現在一個請求后的緊接著的一個請求響應中(存儲型xss必須要交互增加一些內容的,基于人的習慣,自己增加的內容自己往往會去查看是否成功等,這意味著下一個請求就很有可能是新增內容的輸出點),基于這樣的考慮,完全可以依靠全流量統計分析出訪問鏈接直接的順序關系,通過這種方式來解決部分存儲型xss,而不至于遍歷域名的所有url這種耗費資源和性能的事情。
3.數據中心
收集最全的url作為掃描輸入源,這一直就是數據中心的終極目標,當然url唯一且干凈也是數據中心的重要目標;為了收集更全的url絞盡了腦汁,除了IDC全流量,還考慮依托OA全流量,通過主機agent去收集線上業務訪問日志、甚至收集線下流量導入到線上,當然還有爬蟲,甚至還有用戶主動上傳;但不幸的是,庫中收集的流量還是十分有限,絕大部分漏報都是流量缺失導致,這也是下一步需要考慮的重點。
4.異常監控
掃描平臺后端是一個基于云的分布式掃描集群,邏輯相對比較復雜;為了監控異常,需要關注掃描任務的完整生命周期:一個url的漏掃,需要關注url是否存在于數據中心、是否推送到掃描集群掃描、是在集群的那個節點上掃描的、掃描過程中是否出現異常、當時是否掃出漏洞、漏洞是否推送成功、人工是否已經check發單等所有關鍵節點;同時為了監控掃描平臺的異常,還需要關注每周漏洞產出的趨勢、數據中心中url趨勢、掃描的耗費時間趨勢等等。
(三)更準(準確率)
更準:主要指準確率,要求更低的誤報,誤報產生的原因很多,這里僅列幾點說明:
1.掃描方式引起
還是以反射型xss為例,以發送探測包的方式來替代遍歷payloads的方式,雖然規避了漏報和提高了性能,但是誤報也伴隨而來;通過定位輸出位置及場景來確定是否存在xss,但是xss的最終形成是需要依賴瀏覽器進行解析,所以必然存在誤報:比如以json串輸出,輸出點在單引號或者雙引號中,并且引號被轉義不能被閉合,但是輸出格式是html(本來json輸出content-type應該正確設置為text/json等,但有些非要設置為text/html,通過場景來分析是不會存在xss的,但因為輸出格式問題,瀏覽器會當做html進行解析從而形成漏洞)。
當然上面列舉的這種情形,通過增加一步驗證即可解決(根據場景構造特定payload進行驗證確認)
2.掃描規則引起
掃描漏洞的確認一般都是通過匹配規則來進行的,規則考慮的欠妥都會引起誤報。
最常見的就是掃描特征出現在正常響應中,比如命令執行,通過cat /etc/passwd文件來檢測是否存在漏洞,但是特征出現在搜索結果中明顯就是誤報;當然這里可以通過計算一些動態值予以規避,但悲劇的是動態值一樣可能出現在響應中,這時候就需要考慮發兩次包計算兩次動態值(其實發包量對掃描而言彌足珍貴,多一次包就意味著掃描及時度沒法達成,其實及時度、漏報率、準確率是相互制約的)
3.漏洞類型引起
一些不適合掃描的漏洞類型,比如越權訪問,通過掃描方式進行必然伴隨大量誤報,這個除非革新的掃描思路出現,不然目前很難消除誤報,而且這樣的漏洞類型數目還不在少數。
4.掃描性能引起
為了掃描性能考慮,減少發包量,針對弱點規則,數量眾多規則一起檢測,除了規則本身不嚴謹造成的誤報以外,更多需要關注規則的交叉影響:比如遇到這種場景,不僅僅請求正常路徑響應泄露信息,而是請求任何路徑都是響應泄露信息,這種就會造成規則的交叉影響。
(四)更智能
更智能:掃描平臺寄希望盡量完全自動化的方式去解決一切問題,盡量減少人工的參與量及運維量,我們設計之初就是將更智能作為重要指標進行考量,這里列舉幾例說明:
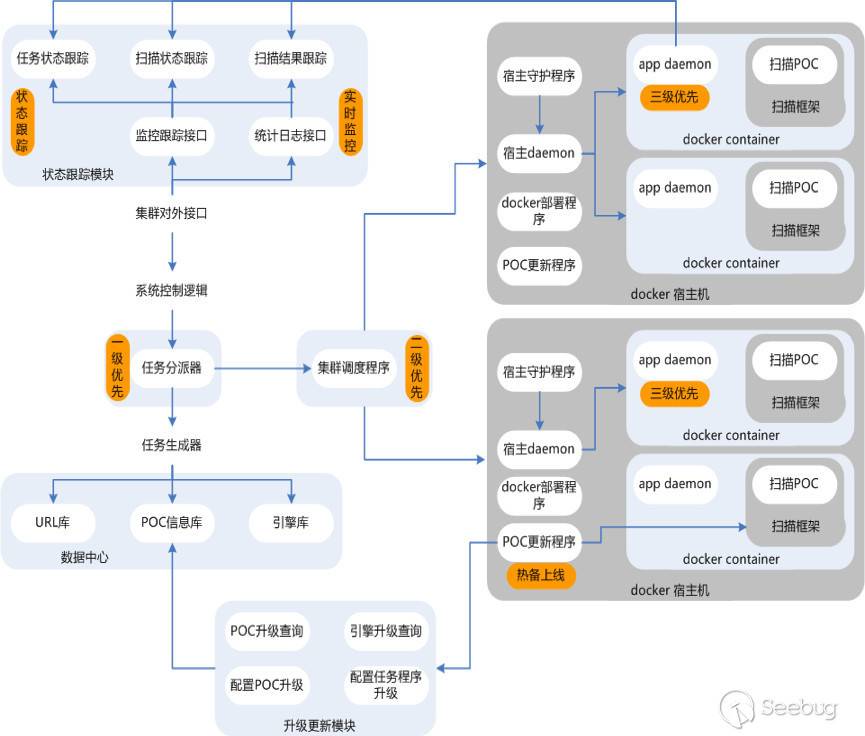
1.熱備上線
寫第一篇文章時其實簡單介紹過熱備上線相關情況,安全掃描poc在方案調研及實現過程中,由于調研的不全面或者考慮的不嚴謹,肯定會出現誤報或者漏報問題,這時候就需要通過更新poc予以解決,現在的難點是:掃描集群時刻都有任務在運行,為了更新任務只能熱備上線,不然只能將未跑完的任務全部kill掉,這樣既浪費掃描資源,又嚴重影響掃描及時度。
通過內置升級更新模塊,當需要更新某個POC時,可以把POC及對應版本推送到POC更新模塊,POC更新模塊比對新舊兩個版本并進行處理(只有當推送的POC版本大于當前版本時才更新,然后刪除舊版本,給當前POC打上待升級標識);當積累到一定數量的待升級POC,或者固定的周期時(這些都可以在調度程序中進行設置),調度程序啟動升級準備工作,標識所有存活容器為待升級狀態,當某個docker容器執行完當前基本單元("單poc+單url")返回結果后,調度程序發現該容器狀態為待升級狀態,則不再分配掃描任務,并且啟動POC更新程序,POC更新程序去升級更新模塊查詢那些POC帶有待升級標識,將所有待升級標識的POC自動拉取到docker容器中,并與容器中的當前版本進行比對,同樣POC版本大于當前容器中的版本時才進行更新處理,更新完成以后,通知調度程序升級完成;調度程序獲取到相關狀態后,重置容器的狀態為正常狀態,并且可以繼續進行掃描任務的派發及執行,基本可以做到不干擾當前運行任務情況下,更新升級,做到熱備上線。
2.掃描能力自我完善
前面通過一系列動作使掃描平臺日臻完善,但一時的優秀不是目的,持久的優秀才是最終目的,那么后期通過什么方式來持續保障或者完善掃描平臺呢?除了前面介紹的通過全流量進行payloads自動收集、查漏補缺以外,我們還可以搭建眾多主流掃描引擎來進行外界報告漏洞的自動能力對比,持續提升掃描能力;當然SRC poc收集、第三方平臺合作、通用漏洞實時分析&新增掃描poc也在同步進行中。
3.異常自動診斷恢復
監控到掃描體系中的任一階段存在異常時,啟動自動診斷程序進行判斷,并根據具體場景來進行后續處理,續掃、重掃或者啟動報警人工干預等,第一篇文章中討論了部分case,這里就不再詳細闡述了。
三 總 結
整套體系化建設實踐后,大家應該比較好奇我們最終的效果對吧?其實“分布式Web漏洞掃描服務建設實踐”系列第一篇文章的時候,我們有簡單說過衡量指標的一些統計數據:掃描出來的漏洞準確率達到了98%以上,基本可以做到無需人工check;輸入源URL存在的情況下漏報率更是控制在0.5%以下,即使算上輸入源URL缺失導致的漏掃,線上的自主發現率也已經達到了90%以上(掃描發現的漏洞占所有線上漏洞的比例,線上漏洞的發現途徑有很多,比如掃描發現、外界SRC報告、友商報告、人工滲透測試等);每天新增URL例行任務2小時內結束,全量URL例行任務2天內結束;隨著漏洞檢測能力的持續提升,安全事件中因常規型漏洞(掃描器很難自動掃描發現的漏洞,比如越權、邏輯、CSRF漏洞類型)引起的占比也由15年之前的52%降低到目前的18%左右;SRC外界白帽子報告的線上漏洞中常規型漏洞占比也由15年之前的72%降低到目前的34%左右,隨著今年自研的白盒及灰盒檢測能力的持續上線,這個占比肯定會下降得更加明顯,當然隨之我們的漏洞檢測重心也會往越權、邏輯等漏洞探索,我們的目標很明確:期望盡最大可能通過自動化的方式低成本的去解決線上絕大部分漏洞問題(我們人力真的很少,哭樣)。
今天就說到這里,感興趣同學可以繼續關注后續"分布式Web漏洞掃描服務建設實踐"系列技術文章。最后這句感悟依然分享給大家“掃描技術雖已成熟,但只有精心耕耘方能知曉其精髓,而剛觸及其精髓才知挑戰依舊”,下篇文章“掃描框架實踐”再見。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/635/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/635/
暫無評論