
作者:WenR0@n0tr00t Security Team
簡介
最近刷完了吳恩達(Andrew Ng)的Machine Learning課程,恰巧實驗室有相關的需求,看了幾個前輩的機器學習檢測PHP Webshell 的文章,便打算自己也抄起袖子,在實戰中求真知。
本文會詳細的介紹實現機器學習檢測PHP Webshell的思路和過程,一步一步和大家一起完成這個檢測的工具,文章末尾會放出已經寫好的下載鏈接。
可能需要的背景知識
-
php基礎知識(PHP opcode)
-
php Webshell
-
Python(scikit-learn)
背景知識簡單介紹
PHP:世界上最好的編程語言,這個不多說了。
PHP opcode:PHP opcode 是腳本編譯后的中間語言,就如同Java 的Bytecode、.NET 的MSL。
PHP Webshell:可以簡單的理解為 網頁后門。
Python scikit-learn:

(翻譯:用起來美滋滋的Python 機器學習包)
可行性分析
PHP Webshell本質上也是一段PHP的代碼,在沒有深入研究前,也知道PHP Webshell 必然有一些規律,比如執行了某些操作(執行獲取到的命令、列出目錄文件、上傳文件、查看文件等等)。如果直接用PHP 的源代碼分析,會出現很多的噪音,比如注釋內容、花操作等等。如果我們將PHP Webshell 的源代碼轉化成僅含執行語句操作的內容,就會一定程度上,過濾掉這些噪音。所以,我們使用PHP opcode 進行分析。
針對opcode這種類型的數據內容,我們可以采用詞袋,詞頻等方法來進行提取關鍵特征。最后使用分類的算法來進行訓練。
根據上面的簡單“分析”,知道咱們在大體思路上,是可以行得通的。
實戰
第一步:準備環境
要獲取到PHP opcode,需要添加一個PHP 的插件 VLD,我們拿Windows環境來進行舉例。
插件下載地址:傳送門
選擇對應版本進行下載
下載好后,放入到PHP 安裝目錄下的ext文件夾內,我使用的是PHPstudy環境,
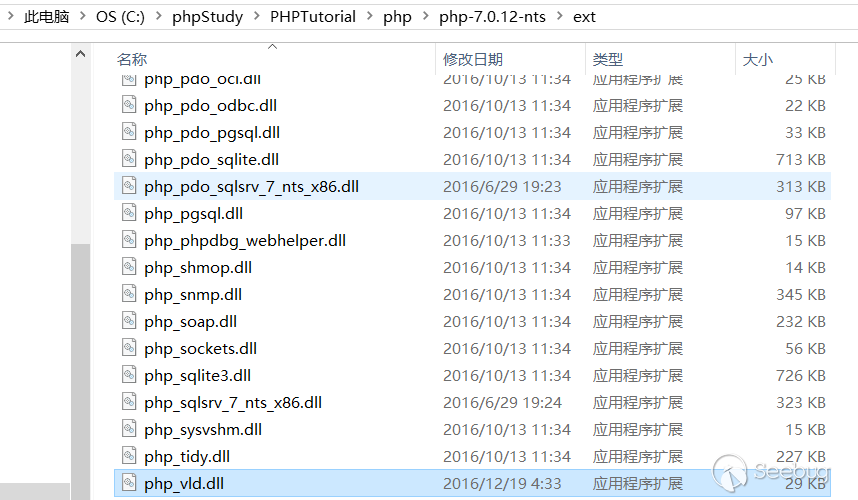
然后編輯php.ini文件,添加一行內容
extension=php_vld.dll測試是否安裝成功:
測試文件1.php
<?php
echo "Hello World";
?>執行命令:
php -dvld.active=1 -dvld.execute=0 1.php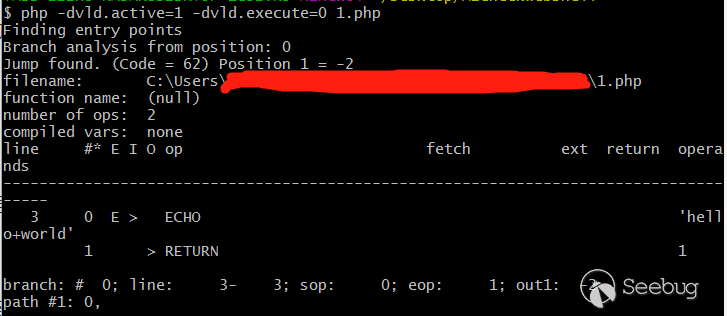
如果顯示內容是差不多一樣的,那我們的環境配置就成功了。
我們需要的就是這段輸出中的

ECHO 、RETURN這樣的opcode。
到這里,我們的PHP環境配置基本完成了。
第二步:準備數據
進行機器學習前,我們很關鍵的一步是要準備數據,樣本的數量和質量直接影響到了我們最后的成果。
下載數據
這里需要準備的數據分為兩類,【白名單數據】、【黑名單數據】。
白名單數據指我們正常的PHP程序,黑名單數據指的是PHP Webshell程序。數據源還是我們的老朋友 github.com
在github上搜索PHP,可以得到很多的PHP的項目,咱們篩選幾個比較知名和常用的。
白名單列表(一小部分):
- https://github.com/WordPress/WordPress
- https://github.com/typecho/typecho
- https://github.com/phpmyadmin/phpmyadmin
- https://github.com/laravel/laravel
- https://github.com/top-think/framework
- https://github.com/symfony/symfony
- https://github.com/bcit-ci/CodeIgniter
- https://github.com/yiisoft/yii2
再繼續搜索一下 Webshell 關鍵字,也有很多收集 Webshell 的項目。
黑名單列表(一小部分):
- https://github.com/tennc/webshell
- https://github.com/ysrc/webshell-sample
- https://github.com/xl7dev/WebShell
創建工程文件夾
創建工程文件夾【MLCheckWebshell】,并在目錄下創建【black-list】【white-list】文件夾。用于存放黑名單文件和白名單文件。
提取opcode
我們創建一個utils.py 文件,用來編寫提取opcode的工具函數。
工具函數1:
def load_php_opcode(phpfilename):
"""
獲取php opcode 信息
:param phpfilename:
:return:
"""
try:
output = subprocess.check_output(['php.exe', '-dvld.active=1', '-dvld.execute=0', phpfilename], stderr=subprocess.STDOUT)
tokens = re.findall(r'\s(\b[A-Z_]+\b)\s', output)
t = " ".join(tokens)
return t
except:
return " "方法load_php_opcode 解讀:
用Python 的subprocess 模塊來進行執行系統操作,獲取其所有輸出,并用正則提取opcode,再用空格來連接起來
工具函數2;
def recursion_load_php_file_opcode(dir):
"""
遞歸獲取 php opcde
:param dir: 目錄文件
:return:
"""
files_list = []
for root, dirs, files in os.walk(dir):
for filename in files:
if filename.endswith('.php'):
try:
full_path = os.path.join(root, filename)
file_content = load_php_opcode(full_path)
print "[Gen success] {}".format(full_path)
print '--' * 20
files_list.append(file_content)
except:
continue
return files_list工具方法2 recursion_load_php_file_opcode 的作用是遍歷目標文件夾內的所有的PHP文件并生成opcode,最后生成一個列表,并返回。
然后我們在工程目錄下,創建train.py文件。
編寫 prepare_data() 函數
def prepare_data():
"""
生成需要使用的數據,寫入文件后,以供后面應用
:return:
"""
# 生成數據并寫入文件
if os.path.exists('white_opcodes.txt') is False:
print '[Info] White opcodes doesnt exists ... generating opcode ..'
white_opcodes_list = recursion_load_php_file_opcode('.\\white-list\\')
with open('white_opcodes.txt', 'w') as f:
for line in white_opcodes_list:
f.write(line + '\n')
else:
print '[Info] White opcodes exists'
if os.path.exists('black_opcodes.txt') is False:
black_opcodes_list = recursion_load_php_file_opcode('.\\black-list\\')
with open('black_opcodes.txt', 'w') as f:
for line in black_opcodes_list:
f.write(line + '\n')
else:
print '[Info] black opcodes exists'
# 使用數據
white_file_list = []
black_file_list = []
with open('black_opcodes.txt', 'r') as f:
for line in f:
black_file_list.append(line.strip('\n'))
with open('white_opcodes.txt', 'r') as f:
for line in f:
white_file_list.append(line.strip('\n'))
len_white_file_list = len(white_file_list)
len_black_file_list = len(black_file_list)
y_white = [0] * len_white_file_list
y_black = [1] * len_black_file_list
X = white_file_list + black_file_list
y = y_white + y_black
print '[Data status] ... ↓'
print '[Data status] X length : {}'.format(len_white_file_list + len_black_file_list)
print '[Data status] White list length : {}'.format(len_white_file_list)
print '[Data status] black list length : {}'.format(len_black_file_list)
# X raw data
# y label
return X, yprepare_data 做了以下幾個事:
- 把黑名單和白名單中的PHP opcode 統一生成并分別寫入到兩個不同的文件中。
- 如果這兩個文件已經存在,那就不再次生成了
- 把白名單中的PHP opcode 貼上 【0】的標簽
- 把黑名單中的PHP opcode 貼上 【1】的標簽
- 最后返回所有PHP opcode 的集合數據 X(有序)
- 返回所有PHP opcode 的標簽 y(有序)
第三步:編寫訓練函數
終于到了我們的重點節目了,編寫訓練函數。
在這里先簡單的介紹一下scikit-learn中我們需要的一些使用起來很簡單的對象和方法。
- CountVectorizer
- TfidfTransformer
- train_test_split
- GaussianNB
CountVectorizer 的作用是把一系列文檔的集合轉化成數值矩陣。
TfidfTransformer 的作用是把數值矩陣規范化為 tf 或 tf-idf 。
train_test_split的作用是“隨機”分配訓練集和測試集。這里的隨機不是每次都隨機,在參數確定的時候,每次隨機的結果都是相同的。有時,為了增加訓練結果的有效性,我們會用到交叉驗證(cross validations)。
GaussianNB :Scikit-learn 對樸素貝葉斯算法的實現。樸素貝葉斯算法是常用的監督型算法。
先上寫好的代碼:
def method1():
"""
countVectorizer + TF-IDF 整理數據
樸素貝葉斯算法生成
:return: None
"""
X, y = prepare_data()
cv = CountVectorizer(ngram_range=(3, 3), decode_error="ignore", token_pattern=r'\b\w+\b')
X = cv.fit_transform(X).toarray()
transformer = TfidfTransformer(smooth_idf=False)
X = transformer.fit_transform(X).toarray()
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
gnb = GaussianNB()
gnb.fit(x_train, y_train)
joblib.dump(gnb, 'save/gnb.pkl')
y_pred = gnb.predict(x_test)
print 'Accuracy :{}'.format(metrics.accuracy_score(y_test, y_pred))
print metrics.confusion_matrix(y_test, y_pred)代碼介紹:
首先,我們用了剛才寫的prepare_data()函數來獲取我們的數據集。然后,創建了一個CountVectorizer 對象,初始化的過程中,我們告訴CountVectorizer對象,ngram的上下限為(3,3) 【ngram_range=(3,3)】,當出現解碼錯誤的時候,直接忽略【decode_error="ignore"】,匹配token的方式是【r"\b\w+\b"】,這樣匹配我們之前用空格來隔離每個opcode 的值。
然后我們用 cv.fit_transform(X).toarray() 來“格式化”我們的結果,最終是一個矩陣。
接著創建一個TfidfTransformer對象,用同樣的方式處理一次我們剛才得到的總數據值。
然后使用train_test_split函數來獲取打亂的隨機的測試集和訓練集。這時候,黑名單中的文件和白名單中的文件排列順序就被隨機打亂了,但是X[i] 和 y[i] 的對應關系沒有改變,訓練集和測試集在總數聚集中分別占比60%和40%。
接下來,創建一個GaussianNB 對象,在Scikit-learn中,已經內置好的算法對象可以直接進行訓練,輸入內容為訓練集的數據(X_train) 和 訓練集的標簽(y_train)。
gnb.fit(X_train, y_train)執行完上面這個語句以后,我們就會得到一個已經訓練完成的gnb訓練對象,我們用測試集(X_test) 去預測得到我們的y_pred 值(預測出來的類型)。
然后我們對比原本的 y_test 和 用訓練算法得到的結果 y_pred。
metrics.accuracy_score(y_test, y_pred)結果即為在此訓練集和測試集下的準確率。
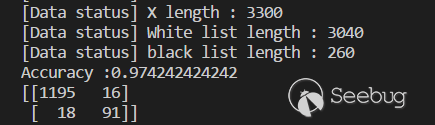
約為97.42%
還需要計算混淆矩陣來評估分類的準確性。
metrics.confusion_matrix(y_test, y_pred)輸出結果見上圖。
編寫訓練函數到這里已經初具雛形。并可以拿來簡單的使用了。
第四步:持久化&應用
編寫完訓練函數,現在我們可以拿新的Webshell來挑戰一下我們剛才已經訓練好的gnb。
但是,如果每次檢測之前,都要重新訓練一次,那速度就非常的慢了,我們需要持久化我們的訓練結果。
在Scikit-learn 中,我們用joblib.dump() 方法來持久化我們的訓練結果,細心的讀者應該發現,在method1() 中有個被注釋掉的語句
joblib.dump(gnb, 'save/gnb.pkl')這個操作就是把我們訓練好的gnb保存到save文件夾內的gnb.pkl文件中。
方面下次使用。
創建check.py
理一下思路:先實例化我們之前保存的內容,然后將新的檢測內容放到gnb中進行檢測,判斷類型并輸出。
核心代碼:
gnb = joblib.load('save/gnb.pkl')
y_p = gnb.predict(X[-1:])最后根據標簽來判斷結果,0 為 正常程序, 1 為 Webshell。
我們來進行一個簡單的測試。
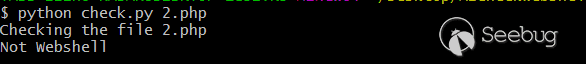

那么,一個簡單的通過樸素貝葉斯訓練算法判斷Webshell的小程序就完成了。
下一步?
這個小程序只是一個簡單的應用,還有很多的地方可以根據需求去改進
如:
在準備數據時:
- 生成 opcode過程中,數據量太大無法全部放入內存中時,更換寫入文件中的方式。
在編寫訓練方法時:
- 更換CountVectorizer的ngram參數,提高準確性。
- 增加cross validation 來增加可靠性
- 更換樸素貝葉斯算法為其他的算法,比如MLP、CNN(深度學習算法)等。
- 在訓練后,得到數據與預期不符合時:
重復增量型訓練,優化訓練結果。
- 增大訓練數據量
- 如果對PHP opcode 有深入研究的同學可以采用其他的提取特征的方法來進行訓練。
- 選擇多種訓練方法,看看哪一種的效果最好,而且不會過度擬合(over fitting)。 ?
結語
最后咱們總結一下機器學習在Webshell 檢測過程中的思路和操作。
- 提取特征,準備數據
- 找到合適的算法,進行訓練
- 檢查是否符合心中預期,會不會出現過度擬合等常見的問題。
- 提供更多更精準的數據,或更換算法。
- 重復1~4
本人也是小菜雞,在此分享一下簡單的思路和方法。希望能拋磚引玉。
項目下載地址:
https://github.com/hi-WenR0/MLCheckWebshell
參考鏈接:
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/526/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/526/