
作者: 程進@默安科技
01. 研究背景
在如今,做安全防御已經不僅僅是被動的等著攻擊者攻擊,作為防御方,有越來越多的方法去反擊攻擊者,甚至給攻擊者一些威脅。
設備指紋技術是一種長久有效的追蹤技術,即使攻擊者掛再多 vpn,也能夠準確識別攻擊者身份。
本文借助理海大學發布的 (Cross-)Browser Fingerprinting via OS and Hardware Level Features 文章,寫一些個人理解,與原文一并服用,效果更佳。
02. 設備指紋技術介紹
1. 第一代
第一代指紋追蹤是 cookie 這類的服務端在客戶端設置標志的追蹤技術,evercookie 是 cookie 的加強版。
2. 第二代
第二代指紋追蹤是設備指紋技術,發現 IP 背后的設備。通過 js 獲取操作系統、分辨率、像素比等等一系列信息,傳到后臺計算,然后歸并設備。
唯一性可以保證,但準確率很難完全保證。主要原因就是在跨瀏覽器指紋識別上面。跨瀏覽器之后,第二代技術中很重要的 canvas 指紋、瀏覽器插件指紋都變了,所以很難把跨瀏覽器指紋歸并到同一設備上。
因為設備指紋相同,很大概率上是同一臺設備;但是,設備指紋不同時,不一定不是同一臺設備。
3. 第三代
第三代指紋追蹤技術,則是發現設備后面的人。通過人的習慣、人的行為等等來對人進行歸并,此項技術比較復雜。
4. 總 結
第一代、第二代的指紋追蹤技術是可以直接通過 js 收集信息的,第三代指紋追蹤技術目前可看到的案例是2017年 RSA 創新沙盒的冠軍 unifyid 技術。但是在 RSA 的答辯現場我們可以看到,unifyid 在移動端安裝軟件、收集信息,不僅僅是通過 js。至于利用于 web 上,還任重而道遠。
因此,2.5代指紋識別技術,即跨瀏覽器指紋識別技術。
03. 跨瀏覽器指紋識別特征
這篇 paper 中的創新點很多,最主要的是深入研究了顯卡的渲染方法,圖片的哪些部分用到硬件渲染,哪些部分只用到軟件渲染,或者跟瀏覽器有關,paper 中都有深入研究。
著重講一些比較有意思的特征,文章中用到的所有特征如下:
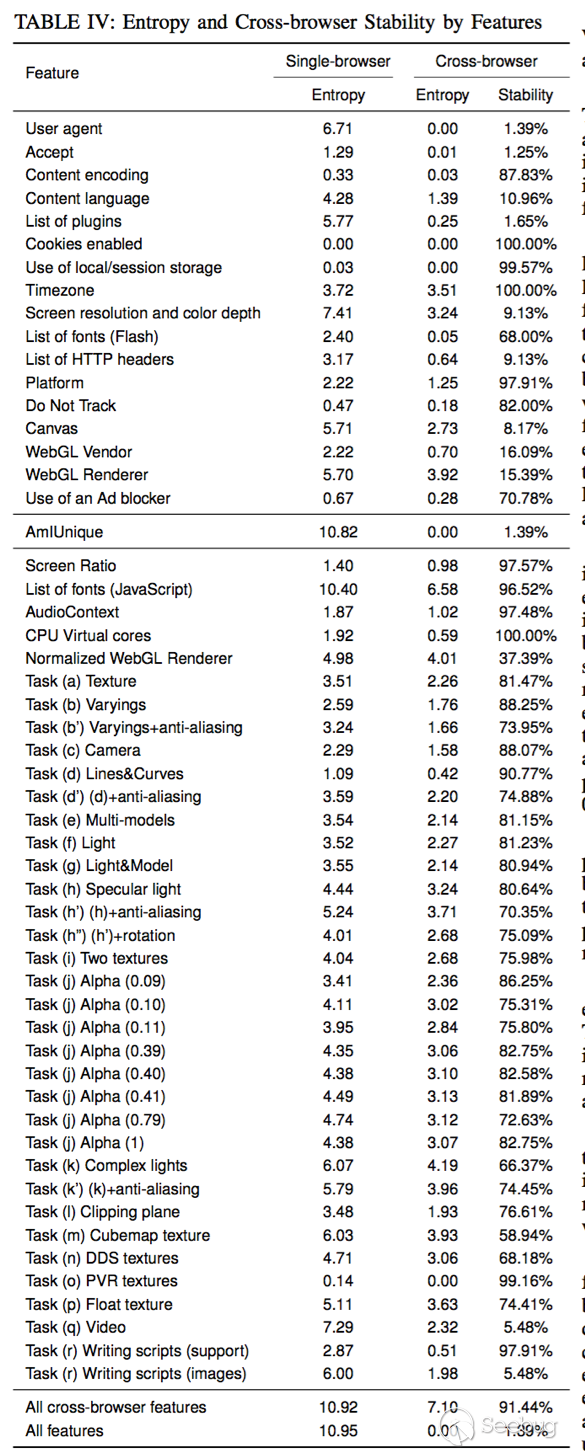
其中很多特征都是在其他設備指紋的 paper 中出現過的,并且目前被廣泛用于設備指紋項目。比如 canvas 指紋在單瀏覽器識別中是比較有區分度的特征。
對比一下已經開源的 fp2 的指紋列表

fp2 中的都是一些常規的追蹤項目,并且如果用過就知道,其中很多項目是沒有什么區分度的,比如
- Has session storage or not
- Has local storage or not
- Has indexed DB
- Has IE specific 'AddBehavior'
- Has open DB
- Is AdBlock installed or not
- Has the user tampered with its languages 1
- Has the user tampered with its screen resolution 1
- Has the user tampered with its OS 1
- Has the user tampered with its browser
這些項只能進行一些大致的區分,并沒有什么實際的參考價值
但是這篇 paper 中去掉了這些區分度低的特征,用到了另一類特征,顯卡渲染圖片,就是特征表中的 task(a)-task(r),可以看到這些 task 的跨瀏覽器穩定性都非常高,也就是說受瀏覽器的影響不是很大,抽一些任務介紹一下
首先,paper 中對圖片渲染進行了簡單的介紹
在此之前,首先介紹下面的基本畫布設置。畫布的大小為 256×256。畫布的軸定義如下,[0,0,0]是畫布的中心,其中x軸是向右延伸的水平線,y軸是延伸到底部的垂直線,z軸朝遠離 屏幕方向延伸。存在功率為 [R:0.3,G:0.3,B:0.3](1) 的環境光,相機位于 [0,0,-7] 的位置。這兩個組件是必需的,否則模型完全是黑色的。在本文的其余部分,除非指定,例如具有 2D 特征的任務(d)和其他帶有附加燈的任務,其他所有任務中使用相同的基本設置。
這里列舉幾個典型的 task
1. task(a):紋理
圖2(a)中的任務是測試片段著色器中的常規紋理特征。
具體來說,Suzanne 模型[19]在隨機生成紋理的畫布上呈現。紋理,大小為 256×256 的正方形,通過隨機選擇每個像素的顏色來創建。也就是說,我們在一個像素的三個基色(紅色,綠色和藍色)之間產生 0 和 255 之間的三個隨機值,將三個基色混合在一起,并將其用作像素的顏色。
之所以選擇這個隨機生成的紋理,是因為這個紋理比常規紋理具有更多的指紋特征。原因如下,當片段著色器將紋理映射到模型時,片段著色器需要在紋理中插入點,以便將紋理映射到模型上的每個點。插入值算法在不同的顯卡中是不同的,當紋理變化很大時,差異就被放大。因此,我們需要生成在每對相鄰像素之間顏色變化很大的這種紋理。

2. task(d):線和曲線
圖(d)中的任務是測試線和曲線。 在畫布上繪制一條曲線和三條不同角度的直線。具體來說,曲線遵循以下功能:y = 256-100cos(2.0πx/ 100.0)+ 30cos(4.0πx/ 100.0)+ 6cos(6.0πx/ 100.0),其中[0,0]為畫布的左上角,x軸向右增加,y軸增加到底部。 三行的起點和終點是 {[38.4,115.2],[89.6,204.8]},{[89.6,89.6],[153.6,204.8]} 和 {[166.4,89.6],[217.6,204.8]}。
選擇這些特定的線條和曲線,以便測試不同的漸變和形狀。

3. task(f):光
圖(f)中的任務是測試漫射點光和 Suzanne 模型的相互作用。 漫射點光在照亮物體時會引起漫反射。 具體地說,該光是在 RGB 上具有相同值的白色,對于每種原色,光的功率為2,光源位于 [3.0,-4.0,-2.0]。 在這個任務中選擇一個白光源,因為紋理是各種顏色的,單色光可能會減少紋理上的一些微妙差異。 光線的強度需要精心設計。非常弱的光線不會照亮 Suzanne 模型,模型就會不可見;非常強的光會使一切變白,減少指紋特征。
在 6 臺機器的小規模實驗中,功率從 0 增加到 255,我們發現當光功率為2時,這些機器之間的像素差異最大。光照位置可隨機選擇,不會影響特征指紋識別結果。
可以看出,這些任務深入研究了圖片渲染引擎的特征,js 沒辦法直接獲取到顯卡的設置和驅動,但是通過這種方法,當不同的顯卡渲染同一張圖片時,因設置不同,渲染出來的圖片 hash 也不同。用這種圖片 hash 作為特征,其實是從側面得到機器顯卡的特征,同一臺機器在不同的瀏覽器上用到同一個顯卡,所以可以看到這些 task 的跨瀏覽器穩定性都很高,總共 10 余種 task。
Paper中除了這些task,還有一些其他新穎的東西
1. CPU內核數量
這個在之前的設備指紋方案中都是沒有使用到的,現代瀏覽器可以用 navigator .hardware Concurrency 來獲取。如果不支持這個方法,則可以利用另一種方式獲取,具體來說是,當增加 Web Worker 的數量時,可以監視 payload 的完成時間。當計算量達到一定的程度,Web Woker 完成 payload 的時間顯著增加,達到硬件并發的限制,從而判斷核心的數量。一些瀏覽器(如Safari)會將 Web Workers 的可用內核數量減少一半,所以在獲取跨瀏覽器指紋時,我們需要將獲取到的核心數量加倍。
此處內容,有興趣的同學可以看看這篇文章。
2. writing script(language)
這個其實可以理解為語言,但不是當前瀏覽器所使用的語言,而是系統支持的所有語言,比如中文簡體、中文繁體、英語,js 中并沒有接口直接獲取這種語言,但是這里作者想到了另一種方法,就是在頁面中用所有的語言寫兩個字,如果系統支持該語言,那么就能正常寫出來;如果不支持,顯示出來的就是方框。通過這種方法獲取系統支持的語言。

3. AudioContext
能熟悉設備指紋的同學都知道,AudioContext 在很多設備指紋項目上都用到了。具體來說,現有的指紋識別工作使用 OscillatorNode 產生一個三角波,然后將波傳 Dynamics Compressor Node,一個調節聲音的信號處理模塊,產生壓縮效果。 然后,經處理的音頻信號通過 Analyser Node 轉換為頻率域。
該 paper 指出,頻域在不同的瀏覽器中是不同的,這個特征受瀏覽器的影響,不能完全反應出聲卡的特征。也就是說,現有的方案只能識別單瀏覽器。但是他們發現,頻率和峰值的比,在瀏覽器之間是相對穩定的。
因此,在頻率和值的坐標系上創建一個間距很小的列表,并將峰值頻率和峰值映射到相應的格子。 如果一個格子包含一個頻率或值,我們將格子標記為1,否則為0,這樣的格子列表用作跨瀏覽器特征。
除了波形處理外,還能從音頻設備上獲取以下信息:采樣率、最大通道數、輸入數、輸出數、通道數、通道數模式和通道解釋。
這是現有的設備指紋工作沒有用到的又一個跨瀏覽特征。
在 demo 站中,從我電腦上收集到的信息如下
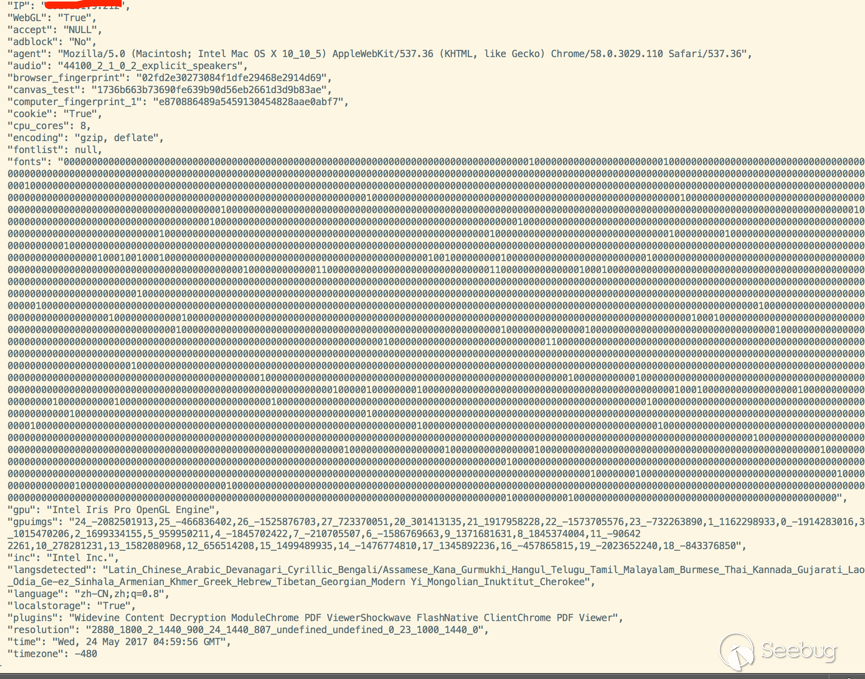
我跨瀏覽器測試的結果,的確能夠跨瀏覽器識別,看到這里,由衷的佩服該項目。
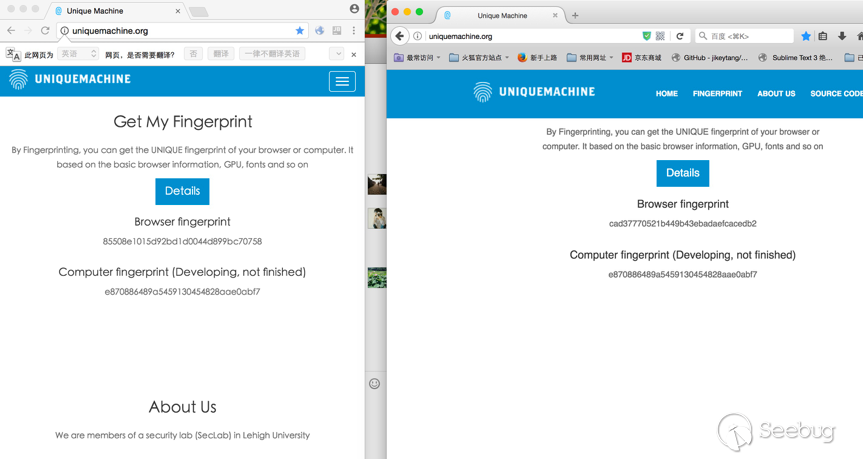
04. 查看代碼
在我看來,十多個 task,AudioContext,CPU core number,writing script,跨瀏覽器穩定性都如此之高,做一些機器學習的分析工作,算一算相似性,真的非常容易達到跨瀏覽器識別的目的。
但我們來看看后端分析代碼,如下:
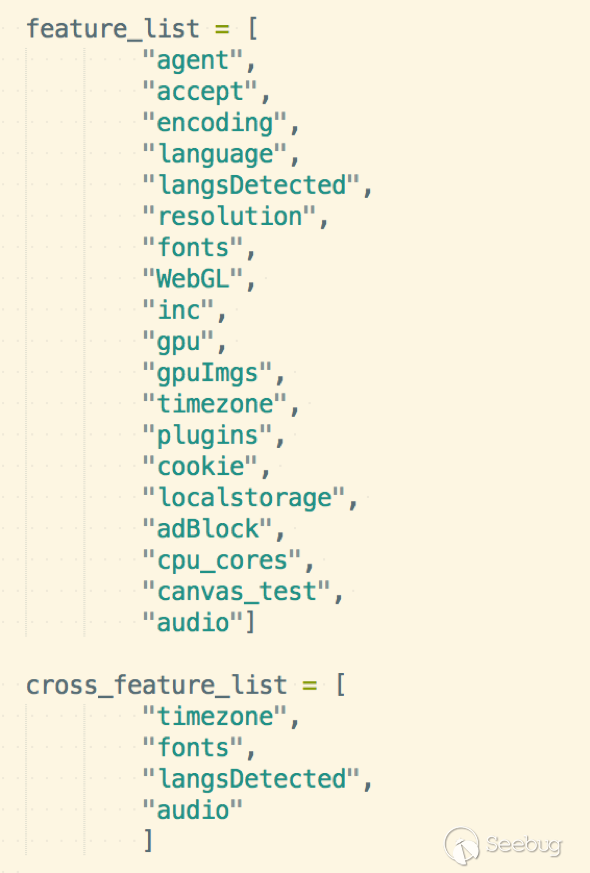
這是代碼中獲取到的從前端傳來的特征,然后就該通過這些特征計算跨瀏覽器指紋了。
但是,他只是簡單的把這些項目加到一起 hash 了一下,就作為跨瀏覽器指紋。
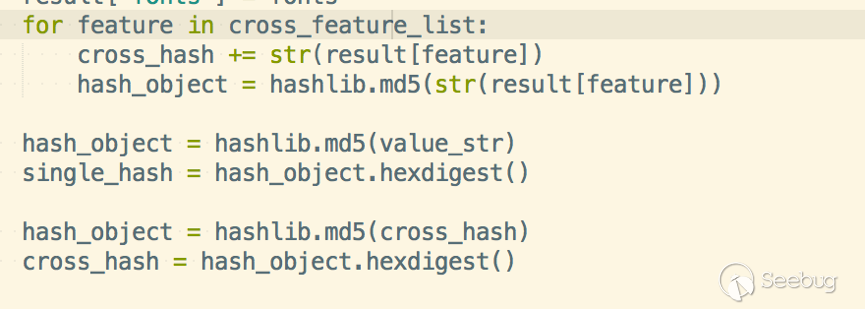
雖然 demo 站說明了跨瀏覽器指紋還在開發中,并沒有什么復雜的計算,跟 paper 中提到的分析方式完全不同,跟我預期的什么機器學習的方式也不同。
但是,跨瀏覽器的特征倒是選用了一些穩定性極高的特征,所以直接 hash 也能進行跨瀏覽器識別。
Paper 中的思路真的很好,所以沿著這個思路,我們還有很多工作要做。
05. 最后說一句
該 paper 中一直提到的 IP 不可信的問題,既然是黑客溯源,對面是黑客,提出這個觀點也無可厚非,畢竟大家都會掛 VPN 或者用肉雞。但是 IP 作為一個重要信息,在設備指紋項目中,還是有用武之地的。
我個人的觀點:IP 雖然不可信,但是短時間的 IP 是可信的。
各位可以自己去試試 IP+設備指紋的區分度還是很好的,而且很大程度上能解決一部分跨瀏覽器識別的問題。
本文僅是自己的一些心得分享,歡迎大家在評論區留言,也可關注我的個人微博@chengable。淺知拙見,拋磚引玉,期待與大家的交流。
作者簡介: 程進,默安科技影武者實驗室安全工程師。主要參與一些安全產品的安全能力推進,包括幻盾的蜜網、黑客溯源技術,SDL靂鑒的漏洞掃描、代碼審計等。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/350/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/350/