
作者:bwner@浙銀網絡安全創新實驗室
本文為作者投稿,Seebug Paper 期待你的分享,凡經采用即有禮品相送! 投稿郵箱:paper@seebug.org
前言
因為最近一直在參加HW,在紅隊中學習到了很多新知識。加殼作為一個常用的免殺手段,我經常是知其然不知其所以然,因此打算自頂向下分析一下upx的源碼,梳理整個程序運行的機制。本文將以最新版本 upx 4.0.2為基礎,對 PE 64位程序進行加殼流程進行分析。
編譯UPX
分析版本:upx-devel 4.0.2 需要壓縮的程序:PE 64位程序 先對編譯upx源碼做一下記錄,挺簡單的,選擇最新版本:
git clone https://github.com/upx/upx.git
cd upx
git submodule update --init
make all
生成的可執行文件upx在upx/build/release中。
目錄結構分析
.
├── CMakeLists.txt
├── COPYING
├── LICENSE
├── Makefile
├── NEWS
├── README
├── README.SRC
├── compile_flags.txt
├── doc
│ ├── BUGS.txt
│ ├── Makefile
│ ├── THANKS.txt
│ ├── elf-to-mem.txt
│ ├── filter.txt
│ ├── linker.txt
│ ├── selinux.txt
│ ├── upx-doc.html
│ ├── upx-doc.txt
│ ├── upx.1
│ └── upx.pod
├── misc
│ ├── podman
│ ├── scripts
│ └── testsuite
├── src
│ ├── Makefile
│ ├── bele.h
│ ├── bele_policy.h
│ ├── check
│ ├── compress
│ ├── conf.h
│ ├── console
│ ├── except.cpp
│ ├── except.h
│ ├── file.cpp
│ ├── file.h
│ ├── filter
│ ├── filter.cpp
│ ├── filter.h
│ ├── headers.h
│ ├── help.cpp
...
...doc 目錄
在/doc中目前包含了elf-to-mem.txt,filter.txt,loader.txt,Makefile,selinux.txt,upx.pod幾項。
elf-to-mem.txt說明了解壓到內存的原理和條件filter.txt解釋了UPX所采用的壓縮算法和filter機制loader.txt告訴開發者如何自定義 loaderselinux.txt介紹了SE Linux中對內存匿名映像的權限控制給UPX造成的影響。這部分文件適用于想更加深入了解UPX的研究者和開發者upx.pod是含關于 UPX 使用方法和功能詳解的文檔,轉換為了upx-doc.html和upx-doc.txt
src 目錄
我UPX源碼都在文件夾/src中,進入該文件夾后我們可以發現其源碼由文件夾/src/check,/src/compress,/src/console,/src/filter,/src/stub,/util和一系列*.h, *.cpp文件構成。
/src/check:此處代碼主要是為了檢查編譯時和運行時環境是否能支持 UPX 的要求,找到潛在的兼容性問題/src/compress:主要包含了壓縮的算法/src/console:這里的代碼主要是實現 UPX 在 Windows 的控制臺驅動,使其能像在 linux terminal 那樣交互。/src/filter:是一系列被filter機制和UPX使用的頭文件。/src/stub:包含了針對不同平臺,架構和格式的文件頭定義和loader源碼,loader源碼在src/stub/src/中,對應不同架構。/util:這里的代碼負責安全性,進行內存管理,幫助發現和避免一些內存錯誤之類的。例如里面的xspan.cpp文件,其中:XSpanStats結構體:它記錄了各種類型的異常情況的計數器,例如空指針、空基址以及和基址不匹配的指針等。xspan_fail_*函數:這些函數被用來處理各種失敗的情況,例如空指針、空基址或者和基址不匹配的指針。當這些情況發生時,相應的計數器會增加,并拋出一個錯誤。xspan_check_range函數:這個函數接受一個指針、一個基礎地址以及一個大小值(以字節為單位)。它首先檢查指針和基地址是否為空,然后檢查指針是否在從基地址開始的給定大小的范圍內。如果任何檢查失敗,它將調用相應的 xspan_fail_* 函數來處理。- 其余的代碼文件主要可以分為負責UPX程序總體的
main.cpp,work.cp和packmast.cpp,負責加脫殼類的定義與實現的p_*.h和p_*.cpp,以及其他起到顯示,運算等輔助作用的源碼文件。
我們的分析將會從main.cpp入手,經過work.cpp,最終跳轉到對應架構和平臺的packer()類中。
main.cpp->filter.cpp->packer.cpp
源碼分析
在經過不斷分析和調整后,可以知道整個源碼運行流程如下,我將流程圖放在源碼分析最前面便于理解框架的整體運行:
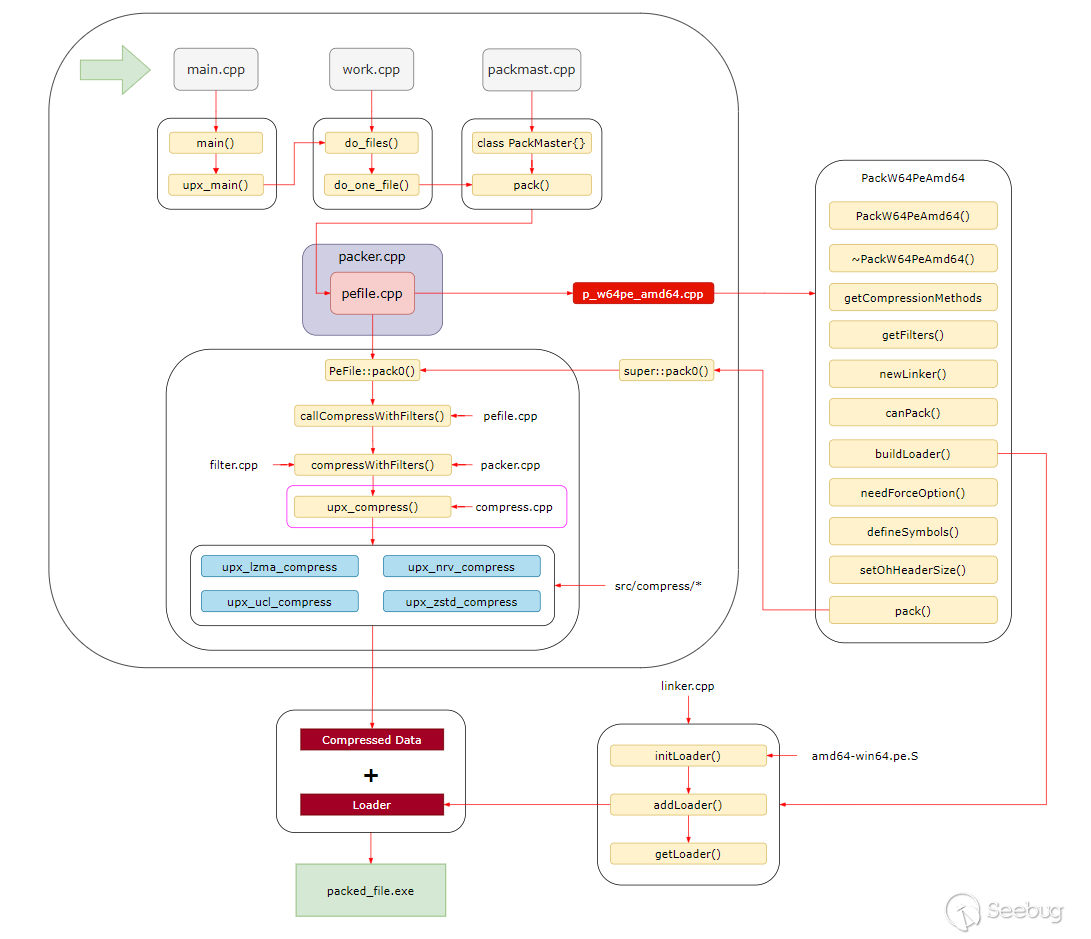
main.cpp
main 函數
main.cpp 包含的函數功能:
main():主函數upx_main():主入口函數main_get_options():獲取參數main_get_envoptions():從環境變量獲取參數check_options():檢查參數catch異常并退出
我們先從主函數入手,可以看到主函數main()的主要作用是調用upx_main():
int __acc_cdecl_main main(int argc, char *argv[]) {
#if 0 && (ACC_OS_DOS32) && defined(__DJGPP__)
// LFN=n may cause problems with 2.03's _rename and mkdir under WinME
putenv("LFN=y");
#endif
#if (ACC_OS_WIN32 || ACC_OS_WIN64) && (ACC_CC_MSC) && defined(_WRITE_ABORT_MSG) && \
defined(_CALL_REPORTFAULT)
_set_abort_behavior(_WRITE_ABORT_MSG, _WRITE_ABORT_MSG | _CALL_REPORTFAULT);
#endif
acc_wildargv(&argc, &argv);
// srand((int) time(nullptr));
srand((int) clock());
// info: main() is implicitly "noexcept", so we need a try block
#if 0
int r = upx_main(argc, argv);
#else
int r;
try {
r = upx_main(argc, argv);
} catch (const Throwable &e) {
printErr("unknown", e);
std::terminate();
} catch (...) {
std::terminate();
}
#endif
#if 0 && defined(__GLIBC__)
// malloc_stats();
#endif
return r;
}__acc_cdecl_main 這個函數修飾符是為了確保 main 函數使用正確的調用約定。具體來說不同的編譯器可能有不同的默認調用約定:
- GCC 和 Clang 的默認是
__attribute__((cdecl)), 等價于 cdecl。 - MSVC 的默認是 __stdcall 。
為了可移植性,UPX 定義了__acc_cdecl_main 函數修飾符,當編譯 UPX 時:
- 對于 GCC/Clang,
__acc_cdecl_main為空,main 正常定義。 - 對于 MSVC,通過 __cdecl 定義 main ,強制用 cdecl 調用約定。
#if (ACC_OS_WIN32 || ACC_OS_WIN64) && (ACC_CC_MSC) && defined(_WRITE_ABORT_MSG) && \
defined(_CALL_REPORTFAULT)
_set_abort_behavior(_WRITE_ABORT_MSG, _WRITE_ABORT_MSG | _CALL_REPORTFAULT);
#endif如果操作系統是 Windows 并使用 MSVC 編譯器,且定義了_WRITE_ABORT_MSG 和 _CALL_REPORTFAULT 宏,就會執行:
_set_abort_behavior(_WRITE_ABORT_MSG, _WRITE_ABORT_MSG | _CALL_REPORTFAULT);
這行代碼用來設置 Crash 時的行為,啟用 Crash 日志和報告功能。
acc_wildargv(&argc, &argv);根據命名我推測這行代是用來碼處理 wildcards 參數的,wildcards(Windows wildcards) 指的是 Windows 中的通配符:
- 檢查是否存在通配符
- 如果存在,則展開通配符,獲得實際的參數列表
- 更新 argc 和 argv ,指向新的參數列表
總的來說這個函數的功能為:根據通配符acc_wildargv()函數會操作和修改命令行參數
acc_wildargv的聲明是在miniacc.h文件中:
ACCLIB_EXTERN(void, acc_wildargv) (int*, char***);宏 ACCLIB_EXTERN 的定義是:
#define ACCLIB_EXTERN(rt,func,args) rt func args就是簡單地展開成一個標準的函數聲明:
void acc_wildargv(int *argc, char ***argv);它的作用是:
- 向使用這個頭文件的代碼提供 acc_wildargv() 的函數聲明
- 隱藏具體的 AccLib 命名空間,只暴露標準的函數聲明
這樣可以在不泄露實現的情況下,向其他代碼提供 AccLib 中函數的接口。 接著往下看main代碼,可以看到:
srand((int) clock());這里是初始化隨機數發生器,srand的工作模式為:
- 第一次調用 srand() 時,使用指定的種子初始化隨機數發生器
- 之后每調用一次 rand(),從隨機數發生器中產生下一個隨機數
如果想看一下這個隨機函數用在了哪些地方,具體可以看一下packer.cpp中用到的rand():
第一個用到的地方是用來生成打包文件的隨機 ID,這個隨機 ID 用來區分不同的打包文件。
// Create a pseudo-unique program id.
unsigned Packer::getRandomId() const {
if (opt->debug.disable_random_id)
return 0x01020304;
unsigned id = 0;
#if 0 && defined(__unix__)
// Don't consume precious bytes from /dev/urandom.
int fd = open("/dev/urandom", O_RDONLY | O_BINARY);
if (fd < 0)
fd = open("/dev/random", O_RDONLY | O_BINARY);
if (fd >= 0) {
if (read(fd, &id, 4) != 4)
id = 0;
close(fd);
}
#endif
while (id == 0) {
#if !(HAVE_GETTIMEOFDAY) || ((ACC_OS_DOS32) && defined(__DJGPP__))
id ^= (unsigned) time(nullptr);
id ^= ((unsigned) clock()) << 12;
#else
struct timeval tv;
gettimeofday(&tv, nullptr);
id ^= (unsigned) tv.tv_sec;
id ^= ((unsigned) tv.tv_usec) << 12; // shift into high-bits
#endif
#if HAVE_GETPID
id ^= (unsigned) getpid();
#endif
id ^= (unsigned) fi->st.st_ino;
id ^= (unsigned) fi->st.st_atime;
id ^= (unsigned) rand();
}
return id;
}第二個地方是在調試模式下隨機選擇一個壓縮方法或過濾器(Filter):
if (opt->debug.use_random_method && nmethods >= 2) {
int method = methods[rand() % nmethods];
...
}
if (opt->debug.use_random_filter && nfilters >= 3 && filters[nfilters - 1] == 0) {
int filter_id = filters[rand() % (nfilters - 1)];
...
} 這里提前講一下 filter,過濾器(Filter)是 UPX 中用于預處理輸入文件的數據流的組件,它可以實現一些轉換,從而改善輸入數據的壓縮效果。 過濾器能夠預處理輸入流從而給予壓縮算法更好的輸入,Packer 會嘗試使用不同的過濾器并選擇壓縮效果最好的那個。 main函數主要還是去執行upx_main()的,接著看upx_main()。
upx_main 函數
upx_main() 函數具體流程為:
- 進行命令行參數解析初始化、壓縮算法初始化、隨機數初始化、版本信息初始化等
- 調用upx_doctest_check()做一些doctest測試
- 解析命令行參數opt,讀取配置
- 根據命令執行不同處理:壓縮、解壓、顯示信息等
- 如果是壓縮或解壓命令,會調用do_files()
- do_files()會循環處理每個文件,調用do_one_file()
- do_one_file()會創建PackMaster實例,并調用其pack/unpack方法
- PackMaster會根據格式創建Packer子類實例,如PeFile
- PeFile中的pack/unpack方法會進行實際的壓縮/解壓處理
- 在壓縮處理中,會調用PeFile的compressWithFilters()方法
- compressWithFilters()會創建Filter實例,并調用其過濾處理數據
首先在完成初始化后,調用main_get_options() 解析命令行參數,根據參數設置 opt 全局配置,根據 opt->cmd決定執行哪個操作,默認為壓縮。接著開始壓縮工作,調用 do_files() 壓縮/解壓縮傳入的文件列表(do_files()具體函數聲明在work.cpp中),返回操作結果。
opt->cmd 是 UPX 源碼中一個全局變量,表示需要執行的操作。代碼定義在 src/options.h 中:
/*************************************************************************
// command line options
**************************************************************************/
// main command
enum {
CMD_NONE,
CMD_COMPRESS,
CMD_DECOMPRESS,
CMD_TEST,
CMD_LIST,
CMD_FILEINFO,
CMD_HELP,
CMD_LICENSE,
CMD_VERSION,
};
struct Options;
extern Options *opt; // global options, see class PackMaster for per-file local options
struct Options final {
int cmd;
// compression options
int method;
bool method_lzma_seen;
bool method_nrv2b_seen;
bool method_nrv2d_seen;
bool method_nrv2e_seen;
int level; // compression level 1..10
int filter; // preferred filter from Packer::getFilters()
bool ultra_brute;
bool all_methods; // try all available compression methods ?
int all_methods_use_lzma;
bool all_filters; // try all available filters ?
bool no_filter; // force no filter
bool prefer_ucl; // prefer UCL
bool exact; // user requires byte-identical decompression
....
}opt -> cmd中opt 是 Options 結構體的一個指針,含義為訪問結構體 Options 的成員(成員變量) cmd,cmd成員包含的值如下:
enum {
CMD_NONE,
CMD_COMPRESS, // 壓縮
CMD_DECOMPRESS, // 解壓縮
CMD_TEST, // 測試
CMD_LIST, // 列出文件內容
CMD_FILEINFO, // 查看文件信息
CMD_HELP, // 顯示幫助信息
CMD_LICENSE, // 顯示軟件許可
CMD_VERSION, // 顯示版本信息
};在upx_main()函數中,根據解析到的命令行參數會設置opt->cmd為對應的操作值:
switch (opt->cmd) {
case CMD_COMPRESS:
//...
break;
case CMD_DECOMPRESS:
//...
break;
// ...
}接著看開始工作部分,/* start work */代碼如下:
/* start work */
set_term(stdout);
if (do_files(i, argc, argv) != 0)
return exit_code;
if (gitrev[0]) {
// also see UPX_CONFIG_DISABLE_GITREV in CMakeLists.txt
bool warn_gitrev = true;
const char *ee = getenv("UPX_DEBUG_DISABLE_GITREV_WARNING");
if (ee && ee[0] && strcmp(ee, "1") == 0)
warn_gitrev = false;
if (warn_gitrev) {
FILE *f = stdout;
int fg = con_fg(f, FG_RED);
con_fprintf(
f, "\nWARNING: this is an unstable beta version - use for testing only! Really.\n");
fg = con_fg(f, fg);
UNUSED(fg);
}
}do_files() 函數的功能是處理命令行傳入的多個文件,函數聲明在work.cpp中,相對應work.cpp中有處理單一文件的函數do_one_file(),多文件時使用do_files()先初步處理,然后再讓do_one_file()挨個根據opt->cmd 執行不同的操作:
- 如果 opt->cmd 是 CMD_COMPRESS ,則對每個文件調用 do_one_file() 壓縮
- 如果 opt->cmd 是 CMD_DECOMPRESS ,則對每個文件調用 do_one_file() 解壓縮
- 在處理每個文件時,能夠處理異常,返回相應的錯誤碼。
- 在處理完成所有文件后,調用 UiPacker 的相應函數,提供總結信息(UiPacker負責UPX中和用戶交互相關的所有功能,包括進度顯示、交互事件、統計信息收集等)
- 返回 0 表示成功處理所有文件,返回 -1 表示有一個文件處理時出現致命錯誤。
do_one_file() 函數的具體操作流程:
void do_one_file(const char *iname, char *oname) {
int r;
struct stat st;
mem_clear(&st);
#if HAVE_LSTAT
r = lstat(iname, &st);
#else
r = stat(iname, &st);
...
}- 打開輸入文件(iname)并獲取文件信息,如大小、權限等
- 檢查文件是否為普通文件,并且大小大于零
- 打開輸出文件(oname),可以是一個文件或者標準輸出
- 根據 opt->cmd 的值,調用PackMaster執行不同的操作:
- 如果 opt->cmd 是 CMD_COMPRESS ,則調用 pm.pack() 對文件進行壓縮
- 如果opt->cmd 是 CMD_DECOMPRESS ,則調用 pm.unpack() 對文件進行解壓縮
- 如果需要,則復制輸入文件的時間戳等屬性到輸出文件,然后關閉輸入輸出文件
- 如果生成了臨時輸出文件,則保留輸出文件并刪除輸入文件(即完成重命名),或者生成備份并刪除輸入文件
- 處理異常,拋出相應的異常或錯誤
此處pm是PackMaster的對象:
// handle command - actual work is here
PackMaster pm(&fi, opt);
if (opt->cmd == CMD_COMPRESS)
pm.pack(&fo);
else if (opt->cmd == CMD_DECOMPRESS)
pm.unpack(&fo);
else if (opt->cmd == CMD_TEST)
pm.test();
else if (opt->cmd == CMD_LIST)
pm.list();
else if (opt->cmd == CMD_FILEINFO)
pm.fileInfo();
else
throwInternalError("invalid command");PackMaster 類的定義在 src/packmast.h 中,注釋寫得十分清楚:"dispatch to a concrete subclass of class Packer; see work.cpp",這個部分后面會講。
#pragma once
class Packer;
class InputFile;
class OutputFile;
/*************************************************************************
// dispatch to a concrete subclass of class Packer; see work.cpp
**************************************************************************/
class PackMaster final {
public:
explicit PackMaster(InputFile *f, Options *o = nullptr) noexcept;
~PackMaster() noexcept;
void pack(OutputFile *fo);
void unpack(OutputFile *fo);
void test();
void list();
void fileInfo();
typedef Packer *(*visit_func_t)(Packer *p, void *user);
static Packer *visitAllPackers(visit_func_t, InputFile *f, const Options *, void *user);
private:
OwningPointer(Packer) packer = nullptr; // owner
InputFile *fi = nullptr; // reference
static Packer *getPacker(InputFile *f);
static Packer *getUnpacker(InputFile *f);
// setup local options for each file
Options local_options;
Options *saved_opt = nullptr;
};
/* vim:set ts=4 sw=4 et: */PackMaster 類的主要功能是:
- PackMaster 的構造函數會調用 getPacker() 函數,根據輸入文件的類型分配對應的 Packer 子類。
- pack()、unpack() 等函數,實際上是通過 packer 屬性調用對應的 Packer 子類的方法。
- local_options 是個 Options 結構體,它存儲了獨立于全局配置的選項。
PackMaster 可以在不修改 Packer 子類的情況下,支持不同的文件類型,這也是packmast.cpp的主要功能。雖然 PackMaster 使用了 final 關鍵字,讓這個類不會再有子類,但是 PackMaster 類內部引用了 Packer 類,Packer 類的聲明位于 packer.h 中,通過這個 Packer 子類對象再執行不同的操作。
packmast.cpp
packmast.cpp在整個upx加殼流程中起到了分類的作用,其中getPacker()會根據文件格式選擇合適的打包器類,比如說檢測到PE文件則選擇pefile.cpp。下面詳細說明packmast.cpp實現的功能: 在packmast.h中聲明了PackMaster類,后續work.cpp會用到這個類:
/*************************************************************************
// dispatch to a concrete subclass of class Packer; see work.cpp
**************************************************************************/
class PackMaster final {
public:
explicit PackMaster(InputFile *f, Options *o = nullptr) noexcept;
~PackMaster() noexcept;
void pack(OutputFile *fo);
void unpack(OutputFile *fo);
void test();
void list();
void fileInfo();
typedef Packer *(*visit_func_t)(Packer *p, void *user);
static Packer *visitAllPackers(visit_func_t, InputFile *f, const Options *, void *user);
private:
OwningPointer(Packer) packer = nullptr; // owner
InputFile *fi = nullptr; // reference
static Packer *getPacker(InputFile *f);
static Packer *getUnpacker(InputFile *f);
// setup local options for each file
Options local_options;
Options *saved_opt = nullptr;
};
/* vim:set ts=4 sw=4 et: */在packmast.cpp中代碼一開始使用構造函數PackMaster::PackMaster(InputFile *f, Options *o) noexcept : fi(f)來初始化PackMaster對象的狀態。PackMaster類的實現提供了以下功能:
PackMaster::PackMaster:PackMaster類的構造器接受一個InputFile的指針和一個可選的Options指針。如果提供了Options,它會創建一個該選項的本地副本,并將全局的opt指針設置為指向這個本地副本。這樣,PackMaster對象就可以使用自己的選項,而不影響全局的選項。析構器則在PackMaster對象被銷毀時恢復全局的opt選項并刪除packer對象。pack():用于執行壓縮操作。它首先獲取一個適合輸入文件的Packer對象,然后調用該對象的doPack()方法來進行壓縮。unpack():用于執行解壓縮操作。它首先獲取一個適合輸入文件的Packer對象,然后調用該對象的doUnpack()方法來進行解壓縮。test():用于測試已壓縮的文件。它首先獲取一個適合輸入文件的Packer對象,然后調用該對象的doTest()方法來進行測試。list():用于列出已壓縮文件的信息。它首先獲取一個適合輸入文件的Packer對象,然后調用該對象的doList()方法來進行列出。fileInfo():用于獲取文件信息。它首先嘗試獲取一個適合解壓縮輸入文件的Packer對象,如果失敗,再嘗試獲取一個適合壓縮輸入文件的Packer對象,然后調用該對象的doFileInfo()方法來獲取文件信息。visitAllPackers():這個方法遍歷所有可能的Packer類型,并對每個類型執行給定的函數。這個函數(try_can_pack或try_can_unpack)會檢查該類型的Packer是否可以處理給定的輸入文件。如果可以,那么該Packer對象就會被返回。getPacker()和getUnpacker():這兩個方法都使用visitAllPackers()方法來找到一個適合處理輸入文件的Packer對象。getPacker()找到的是可以壓縮輸入文件的Packer,而getUnpacker()找到的是可以解壓縮輸入文件的Packer。
work.cpp
該源碼從上到下包含的主要函數有三個:
- do_files:這個函數處理從命令行傳入的所有文件。它首先進行編譯器的一致性檢查,然后遍歷所有輸入的文件,對每個文件調用do_one_file進行處理,捕獲并處理可能拋出的異常。在處理所有文件后,根據命令調用UiPacker的相應函數進行輸出。
- do_one_file:這個函數負責處理一個文件。主要步驟包括檢查文件屬性(是否是普通文件,文件大小是否合理,權限是否合理等),打開輸入文件,打開或者創建輸出文件,根據命令(壓縮,解壓縮,測試,列出,獲取文件信息)調用PackMaster進行處理,復制時間戳,關閉文件,根據需要更改文件名或者刪除文件,復制文件屬性。
- unlink_ofile:這個函數負責在發生異常時刪除輸出文件。unlink_ofile 在 do_one_file 和 do_files 內部使用,不導出。
這個地方的代碼主要是根據packmast.cpp提供的PackMaster類構造PackMaster對象,例如下面的代碼:
InputFile fi;
fi.st = st;
fi.sopen(iname, O_RDONLY | O_BINARY, SH_DENYWR);
...
// handle command - actual work is here
PackMaster pm(&fi, opt);
if (opt->cmd == CMD_COMPRESS)
pm.pack(&fo);
else if (opt->cmd == CMD_DECOMPRESS)
pm.unpack(&fo);
else if (opt->cmd == CMD_TEST)
pm.test();
else if (opt->cmd == CMD_LIST)
pm.list();
else if (opt->cmd == CMD_FILEINFO)
pm.fileInfo();
else
throwInternalError("invalid command");這段代碼首先創建了一個 InputFile 對象 fi,并打開了輸入文件 iname,接著創建一個名為 fo 的 OutputFile 對象,然后使用這個輸入文件 fi 和選項 opt,創建了一個 PackMaster 對象 pm。如果選項 opt 指定的命令是壓縮 (CMD_COMPRESS),那么就調用 pm 的 pack 方法,并傳入輸出文件對象 fo進行壓縮操作。 work.cpp與pefile.cpp的關系是什么?
- work.cpp中的do_one_file()會調用PackMaster進行單個文件的壓縮處理。
- PackMaster會根據文件類型創建合適的Packer子類實例,比如PeFile。
- PeFile定義了pack()和unpack()方法實現具體的壓縮和解壓。
- work.cpp最終通過PackMaster調用到PeFile的pack()方法實現對PE文件的壓縮。
- PeFile::pack()會調用各過程完成導入表、重定位等處理,并調用compressWithFilters()進行實際壓縮。
- 壓縮結果會寫入輸出文件,完成整個壓縮過程。
- 對解壓也是類似的過程,work.cpp通過PackMaster調用PeFile::unpack()。
所以 work.cpp 控制總體流程,使用 packmast.cpp 來根據文件類型從 packer.cpp 中選擇 PeFile 來實現特定格式PE文件的處理。
packer.cpp
packer.cpp 實現了 Packer 抽象類的具體函數,用來提供不同文件格式的打包和解包的基類。Packer 是 PackMaster 的子類,再作為 pefile.cpp 的基類,后續 pefile.cpp 會繼承 packer.cpp 的一部分特性進行打包。
Packer 抽象類提供了共享的函數,子類可以實現各自的壓縮和解壓算法。在源碼里我們可以看到還有packer_f.cpp、packer_c.cpp、packer_c.cpp,這些文件提供了基于packer.cpp函數的共享函數,例如 packer_c.cpp 提供了的共享函數:
isValidCompressionMethod()
getDefaultCompressionMethods()
getDecompressorSections()這些函數并不是 packer.cpp 類的內部函數,而是可以被 Packer 子類調用的共享函數。例如下面我們要講到的 PeFile 可以這樣使用:
class PeFile: public Packer {
void compress() {
methods = getDefaultCompressionMethods(); // 調用共享函數
// ...
}
}在packer.cpp中packer_c.cpp提供的isValidCompressionMethod()也是直接使用的:
int Packer::prepareMethods(int *methods, int ph_method, const int *all_methods) const {
int nmethods = 0;
if (!opt->all_methods || all_methods == nullptr || (-0x80 == (ph_method >> 24))) {
methods[nmethods++] = forced_method(ph_method);
return nmethods;
}
for (int mm = 0; all_methods[mm] != M_END; ++mm) {
int method = all_methods[mm];
if (method == M_ULTRA_BRUTE && !opt->ultra_brute)
break;
if (method == M_SKIP || method == M_ULTRA_BRUTE)
continue;
if (opt->all_methods && opt->all_methods_use_lzma != 1 && M_IS_LZMA(method))
continue;
// check duplicate
assert(Packer::isValidCompressionMethod(method));
// 此處使用assert檢查是否true, 如果false就會拋出assertion failed錯誤
// assert 語句僅在調試環境下有效,在發布版本(Release mode)中 assert 語句會被自動忽略
for (int i = 0; i < nmethods; i++)
assert(method != methods[i]);
// use this method
methods[nmethods++] = method;
}
// debug
if (opt->debug.use_random_method && nmethods >= 2) {
int method = methods[rand() % nmethods];
methods[0] = method;
nmethods = 1;
NO_printf("\nuse_random_method = %d\n", method);
}
return nmethods;
}在壓縮過程中最主要的是void Packer::compressWithFilters(),packer.cpp使用重載對這個函數進行了封裝:
compressWithFilters 函數是用來找到最佳的壓縮方法和過濾器,并執行實際的壓縮操作的一個核心函數。下面是這個函數的主要步驟:
- 初始化:函數首先備份原始的 PackHeader 和 Filter 對象,然后設置一些初始的最佳壓縮結果。
- 準備壓縮方法和過濾器:函數調用 prepareMethods 和 prepareFilters 函數來獲取需要嘗試的所有壓縮方法和過濾器。
- 嘗試各種壓縮方法和過濾器:函數遍歷所有壓縮方法和過濾器的組合。對于每一種組合,它會首先備份原始的 PackHeader 和 Filter 對象,然后嘗試應用過濾器和壓縮方法。如果過濾器和壓縮方法都成功,并且得到的壓縮結果比當前的最佳結果更好,那么就更新最佳結果。
- 恢復數據:對每一種壓縮方法和過濾器的組合,嘗試完成后,函數會恢復原始的數據,以便于下一次嘗試。
- 檢查壓縮結果:在所有的壓縮方法和過濾器都嘗試完畢后,函數會檢查得到的最佳壓縮結果。如果壓縮后的數據大小沒有比原始數據小,那么就拋出一個異常,表示數據不能被壓縮。
- 保存結果:最后,函數會將得到的最佳壓縮結果保存到 Packer 對象的 ph 成員(一個 PackHeader 對象)和 parm_ft 參數指向的 Filter 對象中,最后執行
buildLoader(&best_ft);來構造一個合適的加載器,這個加載器會被嵌入到壓縮的可執行文件中,用來在運行時解壓和恢復原始的程序。
// copy back results
this->ph = best_ph;
*parm_ft = best_ft;
// Finally, check compression ratio.
// Might be inhibited when blocksize < file_size, for instance.
if (!inhibit_compression_check) {
if (best_ph.c_len + best_ph_lsize >= best_ph.u_len)
throwNotCompressible();
if (!checkCompressionRatio(best_ph.u_len, best_ph.c_len))
throwNotCompressible();
// postconditions 2)
assert(best_ph.overlap_overhead > 0);
}
// convenience
buildLoader(&best_ft);pefile.cpp
pefile.cpp 是 packer.cpp 的子類,主要是針對PE文件進行操作。在壓縮過程中我們需要注意PeFile::pack0函數。
template <typename ht, typename LEXX, typename ord_mask_t>
void PeFile::unpack0(OutputFile *fo, const ht &ih, ht &oh, ord_mask_t ord_mask, bool set_oft) {
// infoHeader("[Processing %s, format %s, %d sections]", fn_basename(fi->getName()), getName(),
// objs);
handleStub(fi, fo, pe_offset);
if (ih.filealign == 0)
throwCantUnpack("unexpected value in the PE header");
const unsigned iobjs = ih.objects;
const unsigned overlay =
file_size_u -
ALIGN_UP(isection[iobjs - 1].rawdataptr + isection[iobjs - 1].size, ih.filealign);
checkOverlay(overlay);
ibuf.alloc(ph.c_len);
obuf.allocForDecompression(ph.u_len);
fi->seek(isection[1].rawdataptr - 64 + ph.buf_offset + ph.getPackHeaderSize(), SEEK_SET);
fi->readx(ibuf, ibufgood = ph.c_len);
// decompress
decompress(ibuf, obuf);
unsigned skip = get_le32(obuf + (ph.u_len - 4));
unsigned take = sizeof(oh);
SPAN_S_VAR(byte, extra_info, obuf);
extra_info = obuf.subref("bad extra_info offset %#x", skip, take);
// byte * const eistart = raw_bytes(extra_info, 0);
memcpy(&oh, extra_info, take);
extra_info += take;
skip += take;
unsigned objs = oh.objects;
if ((int) objs <= 0 || (iobjs > 2 && isection[2].size == 0))
throwCantUnpack("unexpected value in the PE header");
Array(pe_section_t, osection, objs);
take = sizeof(pe_section_t) * objs;
extra_info = obuf.subref("bad extra section size at %#x", skip, take);
memcpy(osection, extra_info, take);
extra_info += take;
skip += take;
rvamin = osection[0].vaddr;
if (iobjs > 2) {
// read the noncompressed section
ibuf.dealloc();
ibuf.alloc(isection[2].size);
fi->seek(isection[2].rawdataptr, SEEK_SET);
fi->readx(ibuf, ibufgood = isection[2].size);
}
// unfilter
if (ph.filter) {
Filter ft(ph.level);
ft.init(ph.filter, oh.codebase - rvamin);
ft.cto = (byte) ph.filter_cto;
OCHECK(obuf + (oh.codebase - rvamin), oh.codesize);
ft.unfilter(obuf + (oh.codebase - rvamin), oh.codesize);
}
// FIXME: ih.flags is checked here because of a bug in UPX 0.92
if (ih.flags & IMAGE_FILE_RELOCS_STRIPPED) {
oh.flags |= IMAGE_FILE_RELOCS_STRIPPED;
ODADDR(PEDIR_RELOC) = 0;
ODSIZE(PEDIR_RELOC) = 0;
}
rebuildImports<LEXX>(extra_info, ord_mask, set_oft);
rebuildRelocs(extra_info, sizeof(ih.imagebase) * 8, oh.flags, oh.imagebase);
rebuildTls();
rebuildExports();
if (iobjs > 3) {
// read the resource section if present
ibuf.dealloc();
ibuf.alloc(isection[3].size);
fi->seek(isection[3].rawdataptr, SEEK_SET);
fi->readx(ibuf, ibufgood = isection[3].size);
}
rebuildResources(extra_info, isection[ih.objects - 1].vaddr);
// FIXME: this does bad things if the relocation section got removed
// during compression ...
// memset(eistart, 0, ptr_udiff_bytes(extra_info, eistart) + 4);
// fill the data directory
ODADDR(PEDIR_DEBUG) = 0;
ODSIZE(PEDIR_DEBUG) = 0;
ODADDR(PEDIR_IAT) = 0;
ODSIZE(PEDIR_IAT) = 0;
ODADDR(PEDIR_BOUND_IMPORT) = 0;
ODSIZE(PEDIR_BOUND_IMPORT) = 0;
setOhHeaderSize(osection);
oh.chksum = 0;
// write decompressed file
if (fo) {
unsigned ic = 0;
while (ic < objs && osection[ic].rawdataptr == 0)
ic++;
ibuf.dealloc();
ibuf.alloc(osection[ic].rawdataptr);
ibuf.clear();
infoHeader("[Writing uncompressed file]");
// write header + decompressed file
fo->write(&oh, sizeof(oh));
fo->write(osection, objs * sizeof(pe_section_t));
fo->write(ibuf, osection[ic].rawdataptr - fo->getBytesWritten());
for (ic = 0; ic < objs; ic++)
if (osection[ic].rawdataptr)
fo->write(obuf + (osection[ic].vaddr - rvamin),
ALIGN_UP(osection[ic].size, oh.filealign));
copyOverlay(fo, overlay, obuf);
}
ibuf.dealloc();
}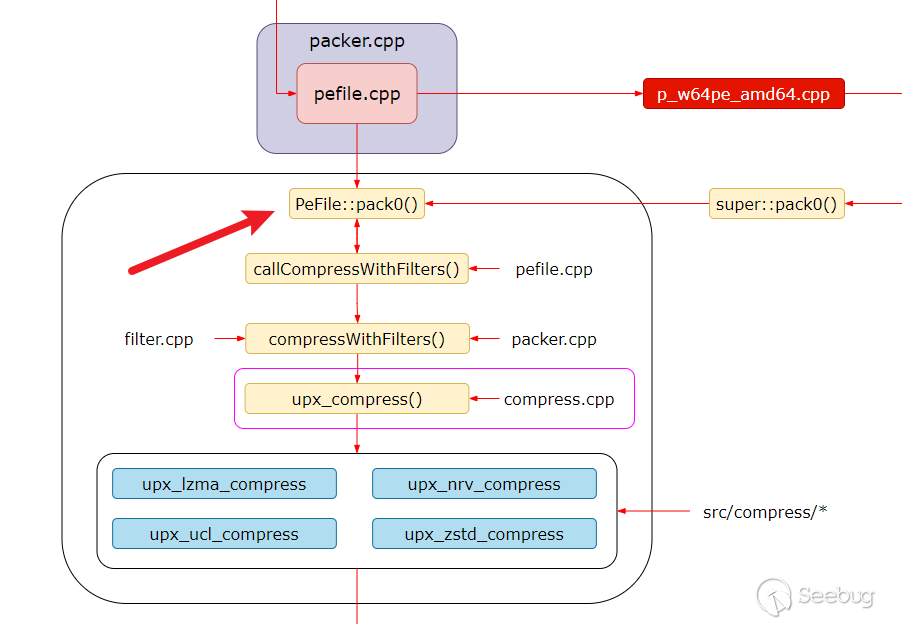
PeFile::pack0 執行步驟總結如下:
- 讀取并解析 PE 文件的相關信息,如頭部數據,區段信息等。
- 將 PE 文件的代碼和數據進行壓縮,通常會使用某種壓縮算法。
- 生成一段解壓縮的代碼并添加到壓縮后的 PE 文件中,以便在運行時解壓縮并執行原始的代碼。
- 預檢查:在函數的開頭部分,進行了一些預檢查。包括檢查 PE 文件的一些屬性,例如是否需要完整性檢查等。對應的代碼在函數的開頭部分,例如:
if (opt->exact)
throwCantPackExact();這一段代碼檢查了是否需要精確打包。如果需要,則拋出異常。
- 處理PE文件的各個部分:在函數的中間部分,處理了PE文件的各個部分,包括導入表,資源,TLS(線程局部存儲),重定位等等。對應的代碼在函數的中間部分,例如:
const unsigned dllstrings = processImports();
processTls(&tlsiv); // call before processRelocs!!
processLoadConf(&loadconfiv);
processResources(&res);
processExports(&xport);
processRelocs();這一段代碼處理了 PE 文件的導入表,TLS,加載配置,資源,導出表和重定位。
- 對文件進行打包和壓縮:在處理完所有的部分后,開始對文件進行打包和壓縮。在這個過程中,可能會對文件進行一些修改,例如修改PE頭部,添加或刪除某些段等。對應的代碼在函數的后半部分,例如:
callCompressWithFilters(ft, filter_strategy, ih.codebase);這一段代碼調用了一個函數來進行壓縮,并使用了過濾器。
- 將處理后的數據寫入到輸出文件,并復制覆蓋層:最后,將處理后的數據寫入到輸出文件,并復制文件的覆蓋層(如果存在的話)。對應的代碼在函數的最后部分,例如:
fo->write(&oh, sizeof(oh));
fo->write(osection, sizeof(osection[0]) * oobjs);
...
copyOverlay(fo, overlay, obuf);這一段代碼將處理后的 PE 頭部和各個部分寫入到輸出文件,然后復制文件的覆蓋層。 復制覆蓋層是指在原始的可執行文件壓縮過程中,一些數據并沒有被壓縮,這部分數據通常被稱為覆蓋層(overlay)。這可能包括一些附加的未壓縮數據,例如數字簽名,不會被壓縮。在解壓縮過程中,這部分覆蓋層數據需要被直接復制到解壓縮的文件中,而不需要進行解壓縮處理。
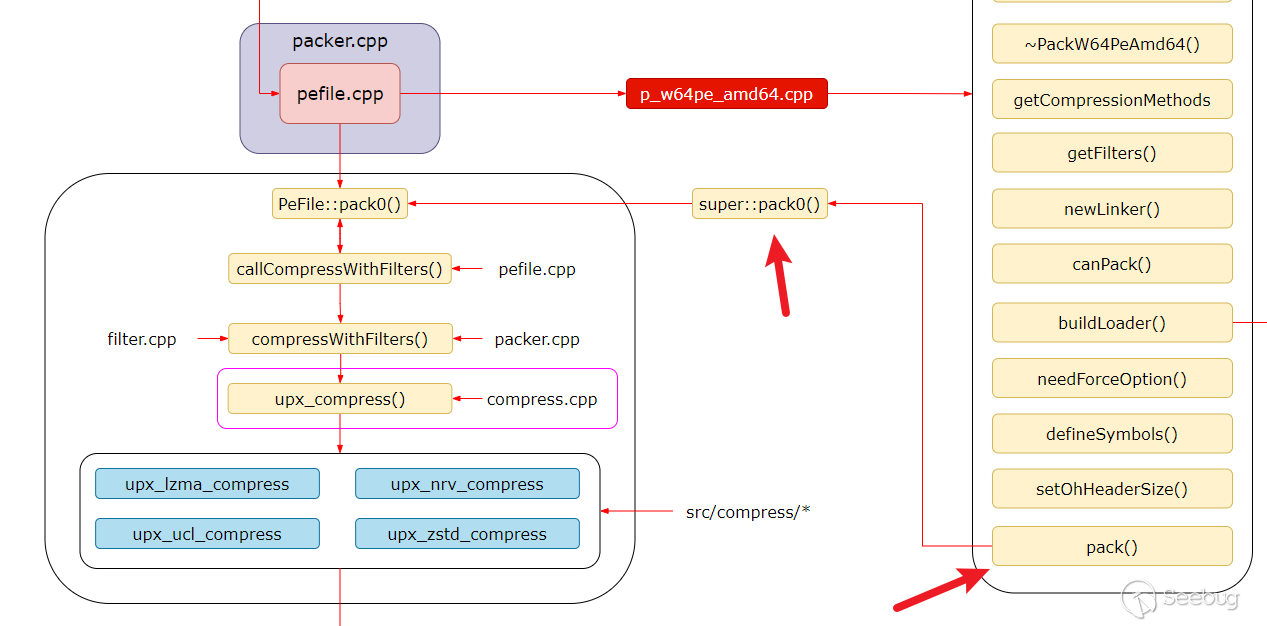
p_w64pe_amd64.cpp
接下來是 p_w64pe_amd64.cpp,p_w64pe_amd64.cpp 實現了針對64位PE文件的壓縮打包邏輯,而 pefile.cpp 包含了PE文件格式的通用處理邏輯。p_w64pe_amd64.cpp是對pefile.cpp模板的復用:
- p_w64pe_amd64.cpp 繼承自 Packer 和 PeFile 類,具體實現了64位PE文件的壓縮打包操作,p_w64pe_amd64.cpp中的pack0()方法是PackW64PeAmd64類中的成員方法,它調用了父類PeFile的pack0()模板方法進行壓縮。
- PeFile 類在 pefile.cpp 中實現,它包含了針對PE文件格式的通用處理邏輯,如讀取PE頭信息、導入表處理、重定位表處理等。
- p_w64pe_amd64.cpp 重用了PeFile類的功能,并實現了64位PE特有的壓縮打包邏輯。
- 在 p_w64pe_amd64.cpp 中,關鍵的pack()方法會調用PeFile::pack0()進行實際的壓縮工作。
- PeFile::pack0() 實現了壓縮的通用流程,讀取原始文件信息、壓縮主代碼段、生成新頭信息等。
- 所以 p_w64pe_amd64.cpp 依賴并復用了 pefile.cpp 中PeFile類的通用功能,并在此基礎上實現64位PE文件的特定處理。
對于64位PE,
p_w64pe_amd64.cpp中的pack0()會實例化PeFile::pack0<LE64>(),而PeFile32和PeFile64則分別實例化PeFile::pack0<LE32>()``和PeFile::pack0<LE64>()
接著分析p_w64pe_amd64.cpp的源碼:
/* p_w64pe_amd64.cpp --
This file is part of the UPX executable compressor.
*/
#include "conf.h"
#include "file.h"
#include "filter.h"
#include "packer.h"
#include "pefile.h"
#include "p_w64pe_amd64.h"
#include "linker.h"
static const CLANG_FORMAT_DUMMY_STATEMENT
#include "stub/amd64-win64.pe.h"
/*************************************************************************
//
**************************************************************************/
PackW64PeAmd64::PackW64PeAmd64(InputFile *f) : super(f) { use_stub_relocs = false; }
PackW64PeAmd64::~PackW64PeAmd64() noexcept {}
const int *PackW64PeAmd64::getCompressionMethods(int method, int level) const {
bool small = ih.codesize + ih.datasize <= 256 * 1024;
return Packer::getDefaultCompressionMethods_le32(method, level, small);
}
const int *PackW64PeAmd64::getFilters() const {
static const int filters[] = {0x49, FT_END};
return filters;
}
Linker *PackW64PeAmd64::newLinker() const { return new ElfLinkerAMD64; }
/*************************************************************************
// pack
**************************************************************************/
bool PackW64PeAmd64::canPack() {
if (!readFileHeader())
return false;
checkMachine(ih.cpu);
if (ih.cpu != IMAGE_FILE_MACHINE_AMD64)
return false;
return true;
}
void PackW64PeAmd64::buildLoader(const Filter *ft) {
// recompute tlsindex (see pack() below)
unsigned tmp_tlsindex = tlsindex;
const unsigned oam1 = ih.objectalign - 1;
const unsigned newvsize = (ph.u_len + rvamin + ph.overlap_overhead + oam1) & ~oam1;
if (tlsindex && ((newvsize - ph.c_len - 1024 + oam1) & ~oam1) > tlsindex + 4)
tmp_tlsindex = 0;
// prepare loader
initLoader(stub_amd64_win64_pe, sizeof(stub_amd64_win64_pe), 2);
addLoader("START");
if (ih.entry && isdll)
addLoader("PEISDLL0");
if (isefi)
addLoader("PEISEFI0");
addLoader(isdll ? "PEISDLL1" : "", "PEMAIN01",
icondir_count > 1 ? (icondir_count == 2 ? "PEICONS1" : "PEICONS2") : "",
tmp_tlsindex ? "PETLSHAK" : "", "PEMAIN02",
// ph.first_offset_found == 1 ? "PEMAIN03" : "",
M_IS_LZMA(ph.method) ? "LZMA_HEAD,LZMA_ELF00,LZMA_DEC20,LZMA_TAIL"
: M_IS_NRV2B(ph.method) ? "NRV_HEAD,NRV2B"
: M_IS_NRV2D(ph.method) ? "NRV_HEAD,NRV2D"
: M_IS_NRV2E(ph.method) ? "NRV_HEAD,NRV2E"
: "UNKNOWN_COMPRESSION_METHOD",
// getDecompressorSections(),
/*multipass ? "PEMULTIP" : */ "", "PEMAIN10");
addLoader(tmp_tlsindex ? "PETLSHAK2" : "");
if (ft->id) {
const unsigned texv = ih.codebase - rvamin;
assert(ft->calls > 0);
addLoader(texv ? "PECTTPOS" : "PECTTNUL");
addLoader("PEFILTER49");
}
if (soimport)
addLoader("PEIMPORT", importbyordinal ? "PEIBYORD" : "", kernel32ordinal ? "PEK32ORD" : "",
importbyordinal ? "PEIMORD1" : "", "PEIMPOR2", isdll ? "PEIERDLL" : "PEIEREXE",
"PEIMDONE");
if (sorelocs) {
addLoader(soimport == 0 || soimport + cimports != crelocs ? "PERELOC1" : "PERELOC2",
"PERELOC3", big_relocs ? "REL64BIG" : "", "RELOC64J");
if (0) {
addLoader(big_relocs & 6 ? "PERLOHI0" : "", big_relocs & 4 ? "PERELLO0" : "",
big_relocs & 2 ? "PERELHI0" : "");
}
}
if (use_dep_hack)
addLoader("PEDEPHAK");
// NEW: TLS callback support PART 1, the callback handler installation - Stefan Widmann
if (use_tls_callbacks)
addLoader("PETLSC");
addLoader("PEMAIN20");
if (use_clear_dirty_stack)
addLoader("CLEARSTACK");
addLoader("PEMAIN21");
if (ih.entry && isdll)
addLoader("PEISDLL9");
if (isefi)
addLoader("PEISEFI9");
addLoader(ih.entry || !ilinker ? "PEDOJUMP" : "PERETURN");
// NEW: TLS callback support PART 2, the callback handler - Stefan Widmann
if (use_tls_callbacks)
addLoader("PETLSC2");
addLoader("IDENTSTR,UPX1HEAD");
}
bool PackW64PeAmd64::needForceOption() const {
// return true if we need `--force` to pack this file
bool r = false;
r |= (ih.opthdrsize != 0xf0); // optional header size is 0xF0 in PE32+ files
r |= ((ih.flags & IMAGE_FILE_EXECUTABLE_IMAGE) == 0);
r |= ((ih.flags & IMAGE_FILE_32BIT_MACHINE) != 0); // 32 bit machine flag may not be set
r |= (ih.coffmagic != 0x20b); // COFF magic is 0x20B in PE32+ files
r |= (ih.entry == 0 && !isdll);
r |= (ih.ddirsentries != 16);
return r;
}
void PackW64PeAmd64::defineSymbols(unsigned ncsection, unsigned upxsection, unsigned sizeof_oh,
unsigned ic, unsigned s1addr) {
const unsigned myimport = ncsection + soresources - rvamin;
// patch loader
linker->defineSymbol("original_entry", ih.entry);
if (use_dep_hack) {
// This works around a "protection" introduced in MSVCRT80, which
// works like this:
// When the compiler detects that it would link in some code from its
// C runtime library which references some data in a read only
// section then it compiles in a runtime check whether that data is
// still in a read only section by looking at the pe header of the
// file. If this check fails the runtime does "interesting" things
// like not running the floating point initialization code - the result
// is a R6002 runtime error.
// These supposed to be read only addresses are covered by the sections
// UPX0 & UPX1 in the compressed files, so we have to patch the PE header
// in the memory. And the page on which the PE header is stored is read
// only so we must make it rw, fix the flags (i.e. clear
// IMAGE_SCN_MEM_WRITE of osection[x].flags), and make it ro again.
// rva of the most significant byte of member "flags" in section "UPX0"
const unsigned swri = pe_offset + sizeof_oh + sizeof(pe_section_t) - 1;
// make sure we only touch the minimum number of pages
const unsigned addr = 0u - rvamin + swri;
linker->defineSymbol("swri", addr & 0xfff); // page offset
// check whether osection[0].flags and osection[1].flags
// are on the same page
linker->defineSymbol(
"vp_size", ((addr & 0xfff) + 0x28 >= 0x1000) ? 0x2000 : 0x1000); // 2 pages or 1 page
linker->defineSymbol("vp_base", addr & ~0xfff); // page mask
linker->defineSymbol("VirtualProtect", ilinkerGetAddress("kernel32.dll", "VirtualProtect"));
}
linker->defineSymbol("start_of_relocs", crelocs);
if (ilinker) {
if (!isdll)
linker->defineSymbol("ExitProcess", ilinkerGetAddress("kernel32.dll", "ExitProcess"));
linker->defineSymbol("GetProcAddress", ilinkerGetAddress("kernel32.dll", "GetProcAddress"));
linker->defineSymbol("kernel32_ordinals", myimport);
linker->defineSymbol("LoadLibraryA", ilinkerGetAddress("kernel32.dll", "LoadLibraryA"));
linker->defineSymbol("start_of_imports", myimport);
linker->defineSymbol("compressed_imports", cimports);
}
if (M_IS_LZMA(ph.method)) {
linker->defineSymbol("lzma_c_len", ph.c_len - 2);
linker->defineSymbol("lzma_u_len", ph.u_len);
}
linker->defineSymbol("filter_buffer_start", ih.codebase - rvamin);
// in case of overlapping decompression, this hack is needed,
// because windoze zeroes the word pointed by tlsindex before
// it starts programs
linker->defineSymbol("tls_value",
(tlsindex + 4 > s1addr) ? get_le32(obuf + tlsindex - s1addr - ic) : 0);
linker->defineSymbol("tls_address", tlsindex - rvamin);
linker->defineSymbol("icon_delta", icondir_count - 1);
linker->defineSymbol("icon_offset", ncsection + icondir_offset - rvamin);
const unsigned esi0 = s1addr + ic;
linker->defineSymbol("start_of_uncompressed", 0u - esi0 + rvamin);
linker->defineSymbol("start_of_compressed", esi0);
if (use_tls_callbacks) {
linker->defineSymbol("tls_callbacks_ptr", tlscb_ptr - ih.imagebase);
linker->defineSymbol("tls_module_base", 0u - rvamin);
}
linker->defineSymbol("START", upxsection);
}
void PackW64PeAmd64::setOhHeaderSize(const pe_section_t *osection) {
// SizeOfHeaders
oh.headersize = ALIGN_UP(pe_offset + sizeof(oh) + sizeof(*osection) * oh.objects, oh.filealign);
}
void PackW64PeAmd64::pack(OutputFile *fo) {
unsigned mask = (1u << IMAGE_SUBSYSTEM_WINDOWS_GUI) | (1u << IMAGE_SUBSYSTEM_WINDOWS_CUI) |
(1u << IMAGE_SUBSYSTEM_EFI_APPLICATION) |
(1u << IMAGE_SUBSYSTEM_EFI_BOOT_SERVICE_DRIVER) |
(1u << IMAGE_SUBSYSTEM_EFI_RUNTIME_DRIVER) | (1u << IMAGE_SUBSYSTEM_EFI_ROM);
super::pack0(fo, mask, 0x0000000140000000ULL);
}
/* vim:set ts=4 sw=4 et: */在給定的源代碼中,定義了類的構造函數、析構函數、成員函數,這些函數的功能為:
PackW64PeAmd64(InputFile *f): 這是類的構造函數,它接受一個指向InputFile類型對象的指針f,這個對象可能是用來表示待壓縮的輸入文件。~PackW64PeAmd64() noexcept: 這是類的析構函數,它在類的對象不再需要時被調用,用于做一些清理工作。getCompressionMethods(int method, int level) const: 這個函數返回一個指向整型數組的指針,這個數組表示可用于壓縮的方法,參數method和level可能用于指定或調整壓縮方法和級別。getFilters() const: 這個函數返回一個指向整型數組的指針,這個數組表示用于壓縮前后處理的過濾器。newLinker() const: 這個函數返回一個指向Linker類型對象的指針,這個對象可能用于處理文件的鏈接問題。canPack(): 這個函數檢查當前的輸入文件是否可以被壓縮,返回一個布爾值。buildLoader(const Filter *ft): 這個函數用于構建加載器,它接受一個指向Filter類型對象的指針ft,這個對象可能用于指定過濾器。needForceOption() const: 這個函數檢查是否需要強制壓縮選項,返回一個布爾值。defineSymbols(unsigned ncsection, unsigned upxsection, unsigned sizeof_oh, unsigned ic, unsigned zzzzzzzzzzs1addr): 這個函數用于定義鏈接器的符號。setOhHeaderSize(const pe_section_t *osection): 這個函數用于設置可選頭部的大小。pack(OutputFile *fo): 這個函數用于壓縮文件,它接受一個指向OutputFile類型對象的指針fo,這個對象可能是用來表示壓縮后的輸出文件。
主要打包函數在PackW64PeAmd64::pack(OutputFile *fo):
void PackW64PeAmd64::pack(OutputFile *fo) {
unsigned mask = (1u << IMAGE_SUBSYSTEM_WINDOWS_GUI) | (1u << IMAGE_SUBSYSTEM_WINDOWS_CUI) |
(1u << IMAGE_SUBSYSTEM_EFI_APPLICATION) |
(1u << IMAGE_SUBSYSTEM_EFI_BOOT_SERVICE_DRIVER) |
(1u << IMAGE_SUBSYSTEM_EFI_RUNTIME_DRIVER) | (1u << IMAGE_SUBSYSTEM_EFI_ROM);
super::pack0(fo, mask, 0x0000000140000000ULL);
}super是訪問父類成員的關鍵字,super::pack0調用了父類PeFile的pack0()模板方法進行實際的壓縮工作,所以從這里開始正式執行pefile.cpp模板提供的打包函數PeFile::pack0()。
filter.cpp
filter是 UPX 中用于預處理輸入文件的數據流的組件,壓縮的程序需要經過過濾器filter處理數據流來便于壓縮,它可以實現一些轉換,從而改善輸入數據的壓縮效果。filter的核心思想是轉換相對跳轉和調用轉為絕對地址,以便更好地壓縮。 filter.h中公有類:
/*************************************************************************
// A filter is a reversible operation that modifies a given
// block of memory.
//
// A filter can fail and return false. In this case the buffer
// must be unmodified (or otherwise restored).
//
// If a filter fails and somehow cannot restore the block it must
// call throwFilterException() - this will cause the compression
// to fail.
//
// Unfilters throw exceptions in case of errors.
//
// The main idea behind filters is to convert relative jumps and calls
// to absolute addresses so that the buffer compresses better.
**************************************************************************/
class Filter final {
public:
explicit Filter(int level) noexcept;
void init(int id = 0, unsigned addvalue = 0) noexcept;
bool filter(SPAN_0(byte) buf, unsigned buf_len);
void unfilter(SPAN_0(byte) buf, unsigned buf_len, bool verify_checksum = false);
void verifyUnfilter();
bool scan(SPAN_0(const byte) buf, unsigned buf_len);
static bool isValidFilter(int filter_id);
static bool isValidFilter(int filter_id, const int *allowed_filters);
public:
// Will be set by each call to filter()/unfilter().
// Read-only afterwards.
byte *buf = nullptr;
unsigned buf_len = 0;
// Checksum of the buffer before applying the filter
// or after un-applying the filter.
unsigned adler;
// Input parameters used by various filters.
unsigned addvalue;
const int *preferred_ctos = nullptr;
// Input/output parameters used by various filters
byte cto; // call trick offset
// Output used by various filters. Read only.
unsigned calls;
unsigned noncalls;
unsigned wrongcalls;
unsigned firstcall;
unsigned lastcall;
unsigned n_mru; // ctojr only
// Read only.
int id;
private:
int clevel; // compression level
};根據源碼可以總結出過濾器運行流程大致為:
initFilter->isValidFilter -> getFilter -> do_filter
初始化filter -> 判斷filter是否有效 -> 獲取filter的過濾器ID對應的FilterEntry對象 -> 根據方法進行填充
在filter.h中可以看到FilterEntry結構體的定義:
struct FilterEntry {
int id; // 0 .. 255
unsigned min_buf_len;
unsigned max_buf_len;
int (*do_filter)(Filter *); // filter a buffer
int (*do_unfilter)(Filter *); // unfilter a buffer
int (*do_scan)(Filter *); // scan a buffer
};do_filter 和 do_unfilter 是函數指針,它們指向實現過濾和解過濾操作的函數。舉個例子來理解filter: 如果過濾器ID是0x01(Fill holes),那么在壓縮階段,filter() 函數將會調用 do_filter() 函數,該函數會用某個字節(如0x00或0xFF)填充輸入數據流中的空洞。在解壓縮階段,unfilter()函數將會調用do_unfilter()函數,該函數會從數據流中移除這些填充字節,恢復原始的數據流。 過濾器的種類和功能包括:(0x00代表過濾器ID)
Page align(0x00):將輸入流對齊到頁面邊界,通常為 4096 字節。Fill holes(0x01):用某個字節(如 0x00 或 0xff)填充輸入流中的空洞。Fix references(0x02):修復輸入流中的內部引用。Remove duplicates(0x03):刪除輸入流中的重復字節序列。Data swap(0x04):交換輸入數據的字節序。UPX1 fix(0x10):修復 UPX v1 打包格式中的引用。Delta encoding(0x11):差分編碼,將輸入數據表示為原始數據與初始數據之間的差異。MRU encoding(0x12):最近最先使用編碼,使用可能重復的數字來表示輸入流中的值。
過濾器通過上面的方式能夠預處理輸入流從而給予壓縮算法更好的輸入,它位于 UPX 的 Packer 組件之前執行,Packer 默認會嘗試使用不同的過濾器并選擇壓縮效果最好的那個。如果想使用 Remove duplicates,通過命令行參數 --filter 可以指定, 我測試的時候貌似沒什么效果。
upx --filter=0x03 myprogram.execompress.cpp
在src/compress/compress.cpp文件中,定義了三個函數:upx_compress、upx_decompress、upx_test_overlap,分別用來壓縮、解壓縮、測試解壓縮過程中是否有數據覆蓋。
upx_compress函數是一個通用的接口,用于根據指定的壓縮方法對數據進行壓縮。具體的壓縮方法包括:LZMA,NRV,UCL,ZSTD等。可以在以下代碼中看到這個函數:
int upx_decompress(const upx_bytep src, unsigned src_len, upx_bytep dst, unsigned *dst_len,
int method, const upx_compress_result_t *cresult) {
int r = UPX_E_ERROR;
assert(*dst_len > 0);
assert(src_len < *dst_len); // must be compressed
if (cresult && cresult->debug.method == 0)
cresult = nullptr;
if (__acc_cte(false)) {
}
#if (WITH_LZMA)
else if (M_IS_LZMA(method))
r = upx_lzma_decompress(src, src_len, dst, dst_len, method, cresult);
#endif
#if (WITH_NRV)
else if ((M_IS_NRV2B(method) || M_IS_NRV2D(method) || M_IS_NRV2E(method)) && !opt->prefer_ucl)
r = upx_nrv_decompress(src, src_len, dst, dst_len, method, cresult);
#endif
#if (WITH_UCL)
else if (M_IS_NRV2B(method) || M_IS_NRV2D(method) || M_IS_NRV2E(method))
r = upx_ucl_decompress(src, src_len, dst, dst_len, method, cresult);
#endif
#if (WITH_ZLIB)
else if (M_IS_DEFLATE(method))
r = upx_zlib_decompress(src, src_len, dst, dst_len, method, cresult);
#endif
#if (WITH_ZSTD)
else if (M_IS_ZSTD(method))
r = upx_zstd_decompress(src, src_len, dst, dst_len, method, cresult);
#endif
else {
throwInternalError("unknown decompression method");
}
return r;
}根據指定的壓縮方法,upx_compress函數將調用對應的壓縮函數:
- LZMA壓縮:如果壓縮方法是LZMA,那么會調用
upx_lzma_compress函數。LZMA(Lempel-Ziv-Markov chain Algorithm)是一種非常有效的壓縮算法,它可以提供非常高的壓縮比。
else if (M_IS_LZMA(method))
r = upx_lzma_compress(src, src_len, dst, dst_len, cb, method, level, cconf, cresult);- NRV壓縮:如果壓縮方法是NRV,那么會調用
upx_nrv_compress函數。NRV是UCL壓縮庫中的一種壓縮算法。
else if ((M_IS_NRV2B(method) || M_IS_NRV2D(method) || M_IS_NRV2E(method)) && !opt->prefer_ucl)
r = upx_nrv_compress(src, src_len, dst, dst_len, cb, method, level, cconf, cresult);- UCL壓縮:如果壓縮方法是UCL,那么會調用
upx_ucl_compress函數。
else if (M_IS_NRV2B(method) || M_IS_NRV2D(method) || M_IS_NRV2E(method))
r = upx_ucl_compress(src, src_len, dst, dst_len, cb, method, level, cconf, cresult);- ZSTD壓縮:如果壓縮方法是ZSTD,那么會調用
upx_zstd_compress函數。ZSTD是由Facebook開發的一種快速實時壓縮算法。
else if (M_IS_ZSTD(method))
r = upx_zstd_compress(src, src_len, dst, dst_len, cb, method, level, cconf, cresult);以上代碼中的upx_lzma_compress,upx_nrv_compress,upx_ucl_compress,upx_zstd_compress等函數是具體的壓縮函數的調用,它們的具體實現在src/compress/*文件夾中。
upx_decompress與upx_compress相對應,執行的是與之相反的功能。
upx_test_overlap函數被用來測試在解壓縮過程中是否有數據覆蓋的發生。數據覆蓋是指解壓縮的輸出會覆蓋未解壓縮的輸入數據,這通常在解壓縮的輸出和輸入共享相同的內存區域并且輸出比輸入大時發生,這種情況在解壓縮過程中是需要避免的。
在UPX中這種情況可能發生,因為UPX的設計目標是使得解壓縮可以在原地進行,即解壓縮的輸出可以覆蓋壓縮的輸入,以節省內存。但是,如果解壓縮的輸出數據比輸入數據大,并且輸出和輸入的內存區域有重疊,那么就會發生數據覆蓋。為了避免這種情況,UPX在解壓縮之前會使用upx_test_overlap函數來測試是否會發生數據覆蓋。
upx_test_overlap函數接受壓縮數據和解壓縮數據的內存區域,以及預期的解壓縮數據的大小等參數。然后,它會調用相應的*_test_overlap函數(例如upx_lzma_test_overlap、upx_ucl_test_overlap等),來測試給定的解壓縮方法是否會導致數據覆蓋。如果測試發現會發生數據覆蓋,那么upx_test_overlap函數會返回一個錯誤代碼。否則,它會返回一個表示成功的代碼。
compress algorithm
關于upx壓縮算法部分,在src/compress目錄下,upx 主要使用了下面幾種壓縮算法:
- LZMA 是 Lempel–Ziv–Markov chain 算法,它屬于字典編碼類壓縮算法,壓縮率較高。
- UCL 是Universal Codec Library,也是一個字典編碼類算法。
- Zlib 是 DEFLATE算法的實現,也屬于字典編碼類壓縮算法。
- Zstandard(Zstd) 是 Facebook開發的壓縮算法,它采用哈希函數的技術加快搜索過程。
這四種算法各有優劣:
- LZMA 和 UCL 壓縮率較高,但速度相對慢一些。適合打包桌面軟件使用。
- Zlib 和 Zstd 壓縮率在中等水平,但速度快,適合網絡傳輸。
在代碼中,upx 對算法進行打包,根據 method 參數的不同,選擇調用相應壓縮算法的實現,例如在src/compress/compress.cpp:
if (M_IS_LZMA(method)) {
r = upx_lzma_compress(...); // 使用LZMA算法
}
else if (M_IS_ZSTD(method)) {
r = upx_zstd_compress(...); // 使用Zstd算法
}什么是字典編碼類壓縮算法?字典編碼類壓縮算法是一類基于重復字符串匹配的壓縮算法,它的主要思想是:
- 構建一個字符串到編碼的映射(字典)
- 在要壓縮的數據流中查找重復的字符串
- 將重復的字符串替換為字典中的編碼
典型的字典編碼類壓縮算法有:LZ77、LZ78、LZW、DEFLATE 等。具體的做法是:
- 先將光標停在要壓縮的數據流的起點
- 查找一個沒有在字典中出現過的字符串
- 將這個字符串添加到字典中并分配一個編碼
- 將這個編碼寫到壓縮的數據流中
- 光標后移到該字符串結束點
- 重復上述過程直到壓縮完所有數據
這樣可以實現壓縮的效果:
- 原始字符串 ==> 較短的編碼字符串
在這篇文章算法部分不詳細展開,后續可能會進行進一步分析。
Loader
p_w64pe_amd64.cpp: buildLoader
這里我們要回到p_w64pe_amd64.cpp的源碼中進行分析,下面是p_w64pe_amd64中PackW64PeAmd64成員函數buildLoader:
void PackW64PeAmd64::buildLoader(const Filter *ft) {
// recompute tlsindex (see pack() below)
unsigned tmp_tlsindex = tlsindex;
const unsigned oam1 = ih.objectalign - 1;
const unsigned newvsize = (ph.u_len + rvamin + ph.overlap_overhead + oam1) & ~oam1;
if (tlsindex && ((newvsize - ph.c_len - 1024 + oam1) & ~oam1) > tlsindex + 4)
tmp_tlsindex = 0;
// prepare loader
initLoader(stub_amd64_win64_pe, sizeof(stub_amd64_win64_pe), 2);
addLoader("START");
if (ih.entry && isdll)
addLoader("PEISDLL0");
if (isefi)
addLoader("PEISEFI0");
addLoader(isdll ? "PEISDLL1" : "", "PEMAIN01",
icondir_count > 1 ? (icondir_count == 2 ? "PEICONS1" : "PEICONS2") : "",
tmp_tlsindex ? "PETLSHAK" : "", "PEMAIN02",
// ph.first_offset_found == 1 ? "PEMAIN03" : "",
M_IS_LZMA(ph.method) ? "LZMA_HEAD,LZMA_ELF00,LZMA_DEC20,LZMA_TAIL"
: M_IS_NRV2B(ph.method) ? "NRV_HEAD,NRV2B"
: M_IS_NRV2D(ph.method) ? "NRV_HEAD,NRV2D"
: M_IS_NRV2E(ph.method) ? "NRV_HEAD,NRV2E"
: "UNKNOWN_COMPRESSION_METHOD",
// getDecompressorSections(),
/*multipass ? "PEMULTIP" : */ "", "PEMAIN10");
addLoader(tmp_tlsindex ? "PETLSHAK2" : "");
if (ft->id) {
const unsigned texv = ih.codebase - rvamin;
assert(ft->calls > 0);
addLoader(texv ? "PECTTPOS" : "PECTTNUL");
addLoader("PEFILTER49");
}
if (soimport)
addLoader("PEIMPORT", importbyordinal ? "PEIBYORD" : "", kernel32ordinal ? "PEK32ORD" : "",
importbyordinal ? "PEIMORD1" : "", "PEIMPOR2", isdll ? "PEIERDLL" : "PEIEREXE",
"PEIMDONE");
if (sorelocs) {
addLoader(soimport == 0 || soimport + cimports != crelocs ? "PERELOC1" : "PERELOC2",
"PERELOC3", big_relocs ? "REL64BIG" : "", "RELOC64J");
if (0) {
addLoader(big_relocs & 6 ? "PERLOHI0" : "", big_relocs & 4 ? "PERELLO0" : "",
big_relocs & 2 ? "PERELHI0" : "");
}
}
if (use_dep_hack)
addLoader("PEDEPHAK");
// NEW: TLS callback support PART 1, the callback handler installation - Stefan Widmann
if (use_tls_callbacks)
addLoader("PETLSC");
addLoader("PEMAIN20");
if (use_clear_dirty_stack)
addLoader("CLEARSTACK");
addLoader("PEMAIN21");
if (ih.entry && isdll)
addLoader("PEISDLL9");
if (isefi)
addLoader("PEISEFI9");
addLoader(ih.entry || !ilinker ? "PEDOJUMP" : "PERETURN");
// NEW: TLS callback support PART 2, the callback handler - Stefan Widmann
if (use_tls_callbacks)
addLoader("PETLSC2");
addLoader("IDENTSTR,UPX1HEAD");
}它的主要作用是創建和配置在解壓縮UPX壓縮文件時使用的加載器,buildLoader函數接受一個Filter類型的指針ft作為參數,這是表示在壓縮和解壓縮過程中使用的過濾器。
buildLoader函數內主要使用了兩個函數,都在packer.cpp中:
initLoader:
void Packer::initLoader(const void *pdata, int plen, int small, int pextra) {
owner_delete(linker);
linker = newLinker();
assert(bele == linker->bele);
linker->init(pdata, plen, pextra);
unsigned size;
char const *const ident = getIdentstr(&size, small);
linker->addSection("IDENTSTR", ident, size, 0);
}addLoader:
#define C const char *
#define N ACC_STATIC_CAST(void *, nullptr)
void Packer::addLoader(C a) { addLoaderVA(a, N); }
void Packer::addLoader(C a, C b) { addLoaderVA(a, b, N); }
void Packer::addLoader(C a, C b, C c) { addLoaderVA(a, b, c, N); }
void Packer::addLoader(C a, C b, C c, C d) { addLoaderVA(a, b, c, d, N); }
void Packer::addLoader(C a, C b, C c, C d, C e) { addLoaderVA(a, b, c, d, e, N); }
void Packer::addLoader(C a, C b, C c, C d, C e, C f) { addLoaderVA(a, b, c, d, e, f, N); }
void Packer::addLoader(C a, C b, C c, C d, C e, C f, C g) { addLoaderVA(a, b, c, d, e, f, g, N); }
void Packer::addLoader(C a, C b, C c, C d, C e, C f, C g, C h) {
addLoaderVA(a, b, c, d, e, f, g, h, N);
}
void Packer::addLoader(C a, C b, C c, C d, C e, C f, C g, C h, C i) {
addLoaderVA(a, b, c, d, e, f, g, h, i, N);
}
void Packer::addLoader(C a, C b, C c, C d, C e, C f, C g, C h, C i, C j) {
addLoaderVA(a, b, c, d, e, f, g, h, i, j, N);
}
#undef C
#undef N這段代碼是對addLoader進行重載,addLoader為重載的函數,參數個數不同,用于接收不同個數的const char參數。
#define C 和 #define N 是用定義宏來分別表示 const char 和 nullptr,每個addLoader內部都調用addLoaderVA,將可變參數打包傳遞給addLoaderVA,addLoaderVA才是實際的實現函數。
addLoaderVA:
void Packer::addLoaderVA(const char *s, ...) {
va_list ap;
va_start(ap, s);
linker->addLoader(s, ap);
va_end(ap);
}addLoaderVA中使用了linker->addLoader(s, ap)將第一個固定參數 s 和可變參數 ap 傳遞給 linker 的 addLoader 方法,linker 是一個 ElfLinker類的對象,addLoader是ElfLinker類中定義的成員函數,inker->addLoader() 根據傳入的第一個字符串參數和可變參數,將這些字符串添加到加載器中。
總結一下,buildLoader函數具體做了以下操作:
- 初始化加載器:
initLoader(stub_amd64_win64_pe, sizeof(stub_amd64_win64_pe), 2);用預定義的stub_amd64_win64_pe模板初始化加載器。 - 添加各種代碼片段到加載器:
addLoader()函數用于向加載器添加不同的代碼片段。這些代碼片段由字符串參數標識,例如 "START","PEISDLL0","PEMAIN01"等,作為各個段的名稱。 - 根據不同的條件添加對應的代碼片段:例如,如果文件是DLL或EFI,或者使用了特定的壓縮方法(如LZMA或NRV),那么將添加相應的代碼片段。
- 支持TLS回調:如果啟用了TLS回調(通過
use_tls_callbacks變量控制),則會添加支持TLS回調的代碼片段。 - 最后,添加加載器的結束標記:"IDENTSTR,UPX1HEAD"。
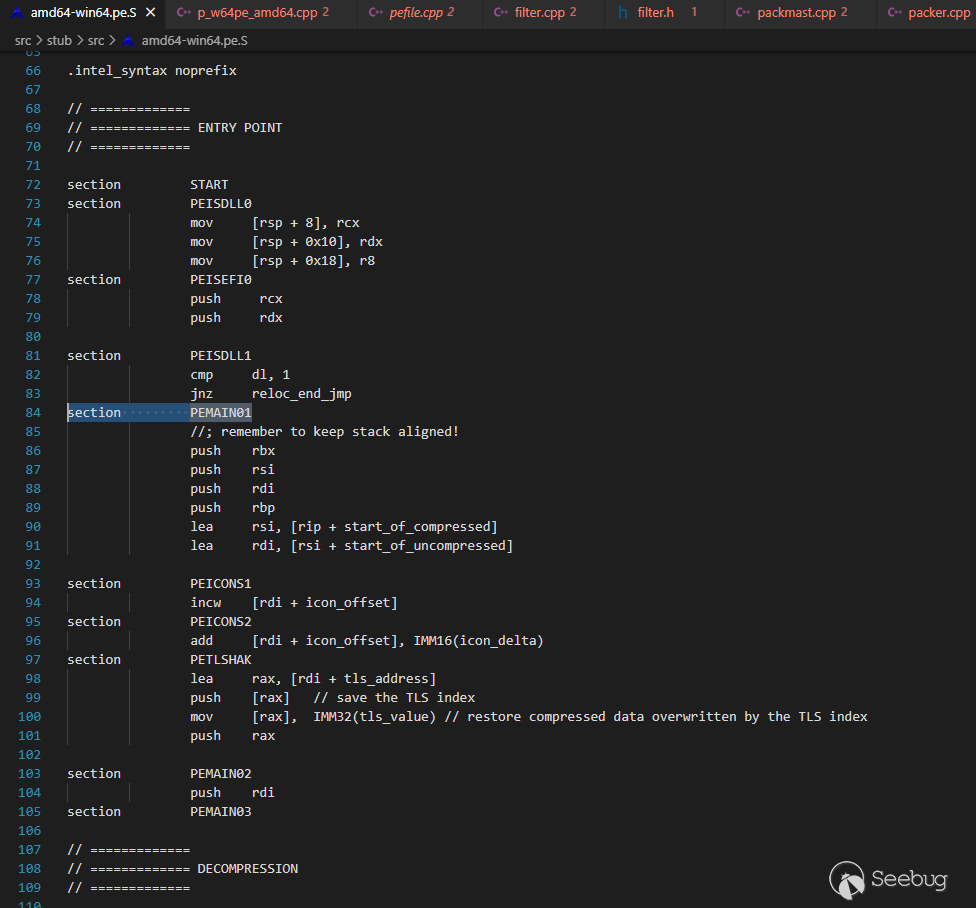
標識符在amd64-win64.pe.S中:
linker.cpp
根據源碼我們可以發現 linker 是一個非常關鍵的類,主要用來構建和管理可執行文件的加載器。它的主要作用有:
- 管理加載器的各個Section。可以添加、查找Section。
- 提供加載器生成的框架。處理各個代碼段的添加、重定位、鏈接,優化加載器的生成過程。
- 實現不同的重定位(Relocation)類型,針對不同架構做重定位處理。
- 維護符號(Symbol)信息。Symbol與Section相關聯。
- 獲取最終連接好的加載器。
- 封裝可執行文件加載器的構建過程,如匹配算法、節對齊等。
- 鏈接可執行文件中的數據,使加載器可以訪問。
- 提供便利的接口,如addLoader系列函數。
- 鏈接外部符號,能夠獲取導入表等信息。
對應函數進行分類來分析代碼可知:
 1. 管理加載器的各個Section:
- addSection - 添加Section
- findSection - 查找Section
- getSection/getSectionSize - 獲取Section信息
2. 提供加載器生成的框架:
- init - 初始化加載器amd64-win64.pe.S
- addLoader - 添加加載器代碼
- getLoader - 獲取最終生成的加載器
3. 實現不同的重定位(Relocation):
- relocate1 - 不同架構的重定位實現
- relocate - 進行重定位
4. 維護符號信息:
- addSymbol - 添加符號
- defineSymbol - 定義符號
- getSymbolOffset - 獲取符號偏移
5. 獲取最終連接好的加載器:
- getLoader - 獲取最終的加載器代碼
6. 封裝可執行文件加載器的構建過程:
- alignCode/alignData - 代碼/數據對齊
- preprocess* - 預處理符號表和重定位信息
7. 鏈接可執行文件中的數據:
- defineSymbol - 鏈接可執行文件符號
8. 提供便利的接口:
- addLoader - 添加加載器代碼段的接口
9. 鏈接外部符號:
- defineSymbol - 可以鏈接外部庫的符號
1. 管理加載器的各個Section:
- addSection - 添加Section
- findSection - 查找Section
- getSection/getSectionSize - 獲取Section信息
2. 提供加載器生成的框架:
- init - 初始化加載器amd64-win64.pe.S
- addLoader - 添加加載器代碼
- getLoader - 獲取最終生成的加載器
3. 實現不同的重定位(Relocation):
- relocate1 - 不同架構的重定位實現
- relocate - 進行重定位
4. 維護符號信息:
- addSymbol - 添加符號
- defineSymbol - 定義符號
- getSymbolOffset - 獲取符號偏移
5. 獲取最終連接好的加載器:
- getLoader - 獲取最終的加載器代碼
6. 封裝可執行文件加載器的構建過程:
- alignCode/alignData - 代碼/數據對齊
- preprocess* - 預處理符號表和重定位信息
7. 鏈接可執行文件中的數據:
- defineSymbol - 鏈接可執行文件符號
8. 提供便利的接口:
- addLoader - 添加加載器代碼段的接口
9. 鏈接外部符號:
- defineSymbol - 可以鏈接外部庫的符號
我們可以看到 p_w64pe_amd64.cpp 沒有使用 getLoader() 函數,getLoader()是通用的加載器模板代碼,而p_w64pe_amd64.cpp 針對具體的amd64 PE平臺重寫了buildLoader方法直接生成了amd64平臺的加載器代碼,因此只使用initLoader、addLoader就可以了。
amd64-win64.pe.S
在src/stub/src目錄下可以看到這種名字為架構-系統.類型.S的匯編代碼文件, 例如:amd64-win64.pe.S,這是針對windows 64位PE程序的匯編代碼。
- amd64:指示該文件用于 AMD64(也稱為 x86-64)架構
- win64:指示該文件用于 64 位 Windows 系統
- pe:指示該文件用于處理 PE(Portable Executable)
- .S:文件的擴展名,表明這是一個匯編語言源代碼文件
這個匯編代碼也整理的十分整齊,比如把入口點統一放在一起:
// =============
// ============= ENTRY POINT
// =============
section START
section PEISDLL0
mov [rsp + 8], rcx
mov [rsp + 0x10], rdx
mov [rsp + 0x18], r8
section PEISEFI0
push rcx
push rdx
section PEISDLL1
cmp dl, 1
jnz reloc_end_jmp
section PEMAIN01
//; remember to keep stack aligned!
push rbx
push rsi
push rdi
push rbp
lea rsi, [rip + start_of_compressed]
lea rdi, [rsi + start_of_uncompressed]
section PEICONS1
incw [rdi + icon_offset]
section PEICONS2
add [rdi + icon_offset], IMM16(icon_delta)
section PETLSHAK
lea rax, [rdi + tls_address]
push [rax] // save the TLS index
mov [rax], IMM32(tls_value) // restore compressed data overwritten by the TLS index
push rax
section PEMAIN02
push rdi
section PEMAIN03涉及到重定位的放在了一起:
// =============
// ============= RELOCATION
// =============
section PERELOC1
lea rdi, [rsi + start_of_relocs]
section PERELOC2
add rdi, 4
section PERELOC3
lea rbx, [rsi - 4]
reloc_main:
xor eax, eax
mov al, [rdi]
inc rdi
or eax, eax
jz SHORT(reloc_endx)
cmp al, 0xEF
ja reloc_fx
reloc_add:
add rbx, rax
mov rax, [rbx]
bswap rax
add rax, rsi
mov [rbx], rax
jmp reloc_main
reloc_fx:
and al, 0x0F
shl eax, 16
mov ax, [rdi]
add rdi, 2
section REL64BIG
or eax, eax
jnz SHORT(reloc_add)
mov eax, [rdi]
add rdi, 4
section RELOC64J
jmp SHORT(reloc_add)
reloc_endx:修改PEMAIN01字段的代碼就會修改加殼后的入口函數匯編代碼,注意棧對齊:
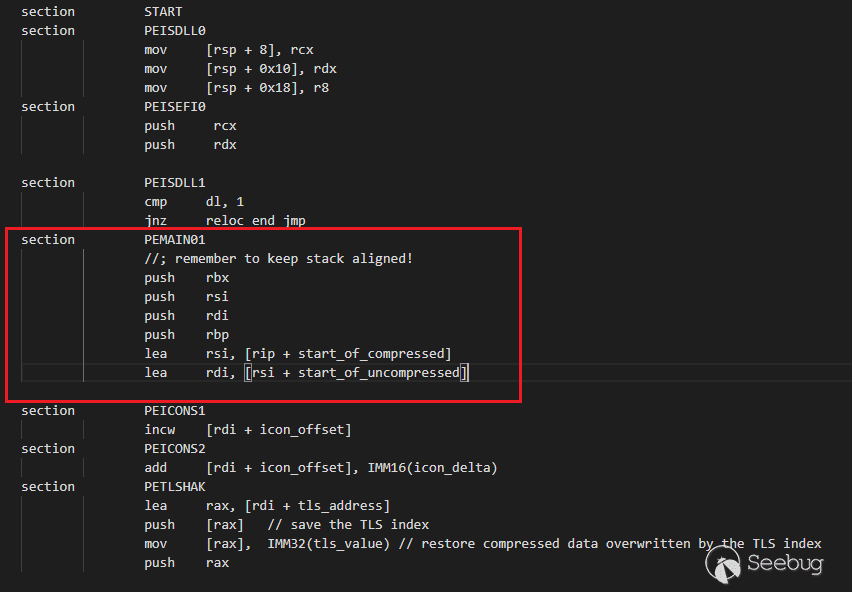
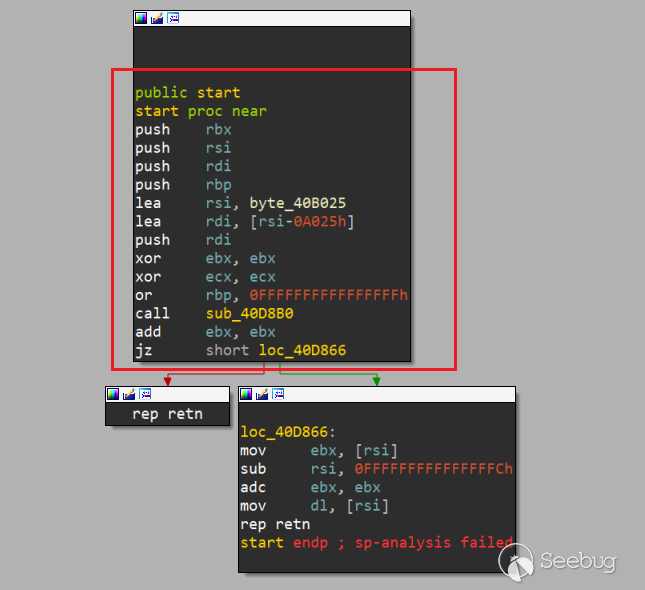
總結
本文主要是自頂向下分析整個upx打包流程中涉及的源碼,我在行文過程中學習到了很多知識,希望大家閱讀后也能有所收獲。文章限于本人知識面有限,也可能存在疏漏,如有問題希望可以多多指出。
參考鏈接
- UPX源碼分析——加殼篇 - i春秋 - 博客園
- 手動編譯UPX并修改Loader
- [原創] UPX源碼學習和簡單修改-加殼脫殼-看雪-安全社區|安全招聘|kanxue.com
- upx壓縮殼源碼分析的一些關鍵點
- 運行時壓縮(UPX)_upx壓縮算法_Mi1k7ea的博客-CSDN博客
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/3001/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/3001/
暫無評論