
來源:同程安全應急響應中心
作者:Nearg1e@YSRC
Django官方 News&Event 在4月4日發布了一個安全更新,修復了兩個URL跳轉的漏洞,一個是urlparse的鍋,另一個由長亭科技的安全研究員phithon報告,都非常漂亮。因為有復現Django漏洞的習慣,晚上抽了點時間復現了一下。有趣的點還挺多。把兩個漏洞的分析整合在一起,湊了篇文章。
CVE-2017-7233分析 — Django is_safe_url() URL跳轉過濾函數Bypass
國外安全研究員roks0n提供給Django官方的一個漏洞。
關于is_safe_url函數
Django自帶一個函數:django.utils.http.is_safe_url(url, host=None, allowed_hosts=None, require_https=False),用于過濾需要進行跳轉的url。如果url安全則返回ture,不安全則返回false。文檔如下:
print(is_safe_url.__doc__)
Return ``True`` if the url is a safe redirection (i.e. it doesn't point to
a different host and uses a safe scheme).
Always returns ``False`` on an empty url.
If ``require_https`` is ``True``, only 'https' will be considered a valid
scheme, as opposed to 'http' and 'https' with the default, ``False``.讓我們來看看常規的幾個用法:
from django.utils.http import is_safe_url
In [2]: is_safe_url('http://baidu.com')
Out[2]: False
In [3]: is_safe_url('baidu.com')
Out[3]: True
In [5]: is_safe_url('aaaaa')
Out[5]: True
In [8]: is_safe_url('//blog.neargle.com')
Out[8]: False
In [7]: is_safe_url('http://google.com/adadadadad','blog.neargle.com')
Out[7]: False
In [13]: is_safe_url('http://blog.neargle.com/aaaa/bbb', 'blog.neargle.com')
Out[13]: True可見在沒有指定第二個參數host的情況下,url如果非相對路徑,即HttpResponseRedirect函數會跳往別的站點的情況,is_safe_url就判斷其為不安全的url,如果指定了host為blog.neargle.com,則is_safe_url會判斷url是否屬于’blog.neargle.com’,如果url是’blog.neargle.com’或相對路徑的url,則判斷其url是安全的。
urllib.parse.urlparse的特殊情況
問題就出在該函數對域名和方法的判斷,是基于 urllib.parse.urlparse
的,源碼如下(django/utils/http.py):
def _is_safe_url(url, host):
if url.startswith('///'):
return False
url_info = urlparse(url)
if not url_info.netloc and url_info.scheme:
return False
if unicodedata.category(url[0])[0] == 'C':
return False
return ((not url_info.netloc or url_info.netloc == host) and
(not url_info.scheme or url_info.scheme in ['http', 'https']))我們來看一下urlparse的常規用法及幾種urlparse無法處理的特殊情況。
>>> urlparse('http://blog.neargle.com/2017/01/09/chrome-ext-spider-for-probe/')
ParseResult(scheme='http', netloc='blog.neargle.com', path='/2017/01/09/chrome-ext-spider-for-probe/',
params='', query='', fragment='')
>>> urlparse('ftp:99999999')
ParseResult(scheme='', netloc='', path='ftp:99999999', params='', query='', fragment='')
>>> urlparse('http:99999999')
ParseResult(scheme='http', netloc='', path='99999999', params='', query='', fragment='')
>>> urlparse('https:99999999')
ParseResult(scheme='', netloc='', path='https:99999999', params='', query='', fragment='')
>>> urlparse('javascript:222222')
ParseResult(scheme='', netloc='', path='javascript:222222', params='', query='', fragment='')
>>> urlparse('ftp:aaaaaaa')
ParseResult(scheme='ftp', netloc='', path='aaaaaaa', params='', query='', fragment='')
>>> urlparse('ftp:127.0.0.1')
ParseResult(scheme='ftp', netloc='', path='127.0.0.1', params='', query='', fragment='')
>>> urlparse('ftp:127.0.0.1')
ParseResult(scheme='ftp', netloc='', path='127.0.0.1', params='', query='', fragment='')可以發現當scheme不等于http,且path為純數字的時候,urlparse處理例如aaaa:2222222223的情況是不能正常分割開的,會全部歸為path。這時url_info.netloc == url_info.scheme == "",則((not url_info.netloc or url_info.netloc == host) and (not url_info.scheme or url_info.scheme in ['http', 'https']))為true。(這里順便提一下,django官方News&Event中提到的poc:”http:99999999″是無法bypass的,在前面的判斷if not url_info.netloc and url_info.scheme:都過不了。)例如下面幾種情況:
>>> is_safe_url('http:555555555')
False
>>> is_safe_url('ftp:23333333333')
True
>>> is_safe_url('https:2333333333')
True使用IP Decimal Bypass is_safe_url
但是既然是url跳轉漏洞,我們就需要讓其跳轉到指定的url里,https:2333333333這樣的url明顯是無法訪問的,而冒號之后必須純數字,http:127.0.0.1是無法pypass的。有什么方法呢?其實ip不僅只有常見的點分十進制表示法,純十進制數字也可以表示一個ip地址,瀏覽器也同樣支持。例如: 127.0.0.1 == 2130706433, 8.8.8.8 == 134744072(轉換器:http://www.ipaddressguide.com/ip ),而'http:2130706433'是在瀏覽器上是可以訪問到對應的ip及服務的,即'http:2130706433 = http://127.0.0.1/'。
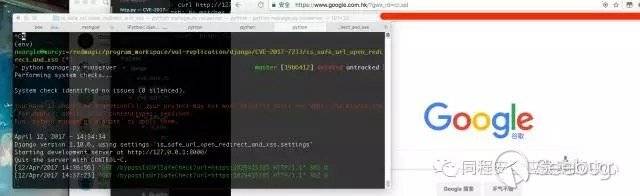
這里我們選用 https:1029415385 作為poc,這是一個google的ip,這個url可以 bypassis_safe_url 并跳轉到google.com。
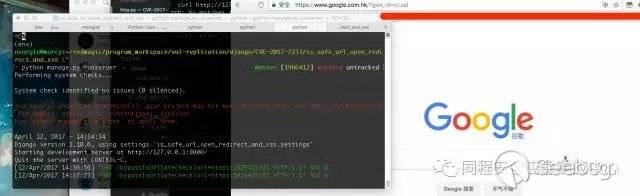
漏洞驗證與影響
我們來寫一個簡單的環境:
from django.http import HttpResponseRedirect
from django.utils.http import is_safe_url
def BypassIsUrlSafeCheck(request):
url = request.GET.get("url", '')
if is_safe_url(url, host="blog.neargle.com"):
return HttpResponseRedirect(url)
else:
return HttpResponseRedirect('/')然后訪問: http://127.0.0.1:8000/bypassIsUrlSafeCheck?url=https:1029415385 , 如圖,url被重定向到了google.com。
并非只有開發者自己使用is_safe_url會受到影響,Django默認自帶的admin也使用了這個函數來處理next GET | POST參數,當用戶訪問/admin/login/?next=https:1029415385進行登錄時,登錄后同樣會跳轉到google.com,退出登錄時同樣使用到了該函數。
def _get_login_redirect_url(request, redirect_to):
# Ensure the user-originating redirection URL is safe.
if not is_safe_url(url=redirect_to, host=request.get_host()):
return resolve_url(settings.LOGIN_REDIRECT_URL)
return redirect_to
@never_cache
def login(request, template_name='registration/login.html',
redirect_field_name=REDIRECT_FIELD_NAME,
authentication_form=AuthenticationForm,
extra_context=None, redirect_authenticated_user=False):
......
return HttpResponseRedirect(_get_login_redirect_url(request, redirect_to))
......
修復
django修復了代碼,自己重構了一下urlparse函數,修復了urlparse函數的這個漏洞。
# Copied from urllib.parse.urlparse() but uses fixed urlsplit() function.
def _urlparse(url, scheme='', allow_fragments=True):
"""Parse a URL into 6 components:
<scheme>://<netloc>/<path>;<params>?<query>#<fragment>
Return a 6-tuple: (scheme, netloc, path, params, query, fragment).
Note that we don't break the components up in smaller bits
(e.g. netloc is a single string) and we don't expand % escapes."""
url, scheme, _coerce_result = _coerce_args(url, scheme)
splitresult = _urlsplit(url, scheme, allow_fragments)
scheme, netloc, url, query, fragment = splitresult
if scheme in uses_params and ';' in url:
url, params = _splitparams(url)
else:
params = ''
result = ParseResult(scheme, netloc, url, params, query, fragment)
return _coerce_result(result)關于官方提到的 possible XSS attack
django官方News&Event中提到的這個漏洞可能會產生XSS,我認為除非程序員把接受跳轉的url插入的到<script type="text/javascript" src="{{ url }}"></script>等特殊情況之外,直接使用產生XSS的場景還是比較少的。如果你想到了其他的場景還請賜教,祝好。
CVE-2017-7234 django.views.static.serve url跳轉漏洞
漏洞詳情
來自 @Phithon 的一個漏洞。
問題出現在:django.views.static.serve()函數上。該函數可以用來指定web站點的靜態文件目錄。如:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^staticp/(?P<path>.*)$', serve, {'document_root': os.path.join(settings.BASE_DIR, 'staticpath')})
]這樣django項目根目錄下staticpath中的所有文件,就可以在staticp/目錄中訪問。e.g. http://127.0.0.1:8000/staticp/test.css
這種方法是不被django官方推薦在生成環境使用的,對安全性和性能都有一定影響。
問題代碼如下 (django/views/static.py):
path = posixpath.normpath(unquote(path))
path = path.lstrip('/')
newpath = ''
for part in path.split('/'):
if not part:
### Strip empty path components.
continue
drive, part = os.path.splitdrive(part)
head, part = os.path.split(part)
if part in (os.curdir, os.pardir):
### Strip '.' and '..' in path.
continue
newpath = os.path.join(newpath, part).replace('\\', '/')
if newpath and path != newpath:
return HttpResponseRedirect(newpath)path既我們傳入的路徑,如果傳入的路徑為 staticp/path.css ,則path=path.css 。跟蹤代碼可知,path經過了unquote進行url解碼,后來又 replace('\\', '/'),進入HttpResponseRedirect,很詭異的邏輯看起來很有問題。一般遇到這類型的函數我們會先試著找看看,任意文件讀漏洞,但是這個對’.’和’..’進行了過濾,所以這邊這個HttpResponseRedirect函數就成了帥的人的目標。
我們的最終目的是 HttpResponseRedirect('//evil.neargle.com')
或者 HttpResponseRedirect('http://evil.neargle.com'),那么就要使 path != newpath,那么path里面就必須帶有’\‘,好的現在的我們傳入 ’/staticp/%5C%5Cblog.neargle.com’ ,則path=’\\blog.neargle.com’,newpath=’//blog.neargle.com’,HttpResponseRedirect 就會跳轉到 ’blog.neargle.com’ 造成跳轉漏洞。
修復
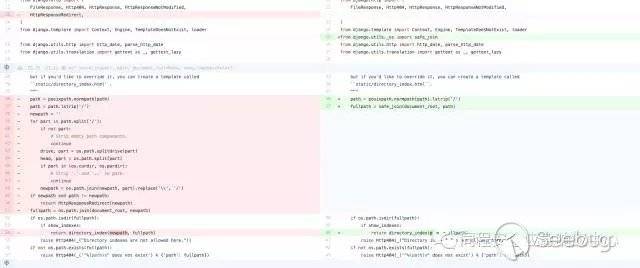
嗯,官方表示自己也不知道為什么要寫這串代碼,刪了這一串代碼然后用safe_url函數代替。
urls
- https://github.com/django/django/commit/5ea48a70afac5e5684b504f09286e7defdd1a81a
- https://www.djangoproject.com/weblog/2017/apr/04/security-releases/
- https://docs.python.org/3/library/urllib.parse.html
PS
瀏覽器不僅僅支持十進制來代替點分十進制的IP,也可以使用十六進制和8進制來代替。http://點分十進制 == http://十進制 == http://0x十六進制 == http://0八進制 (例如: http://127.0.0.1 == http://2130706433 == http://0x7F000001 == http://017700000001 ),十六進制非純數字所以不可用來bypass urlparse,但是八進制還是可以的。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/274/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/274/