
翻譯:k0shl
論文地址:http://www.cs.vu.nl/~herbertb/download/papers/anc_ndss17.pdf
作者博客:http://whereisk0shl.top
前言
這個關于側信道攻擊很有意思,也是顛覆一些傳統觀念的研究,非常值得研究,anc_ndss17.pdf是一個非常好的論文,我對這篇論文進行了翻譯,同時也對AnC的源碼進行了編譯,初步測試,下一步打算仔細研究源碼,目前C源碼支持x86-64,ARM,以及AMD,平臺主要在Linux,VUSec沒有公開Javascript代碼,因為js的實現可能對于瀏覽器,adobe系列等等來說還是存在很大危害的,因為這個廠商無法緩解。
但是對C源碼的學習有利于我們熟悉這個漏洞,同時也有可能能將其用js實現,我將分享論文的整體框架和其中關于AnC實現部分。
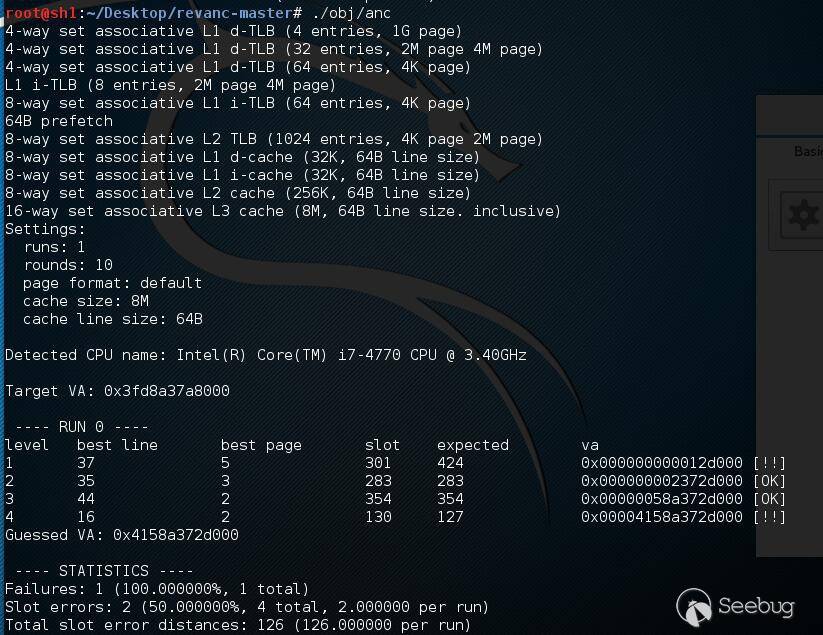
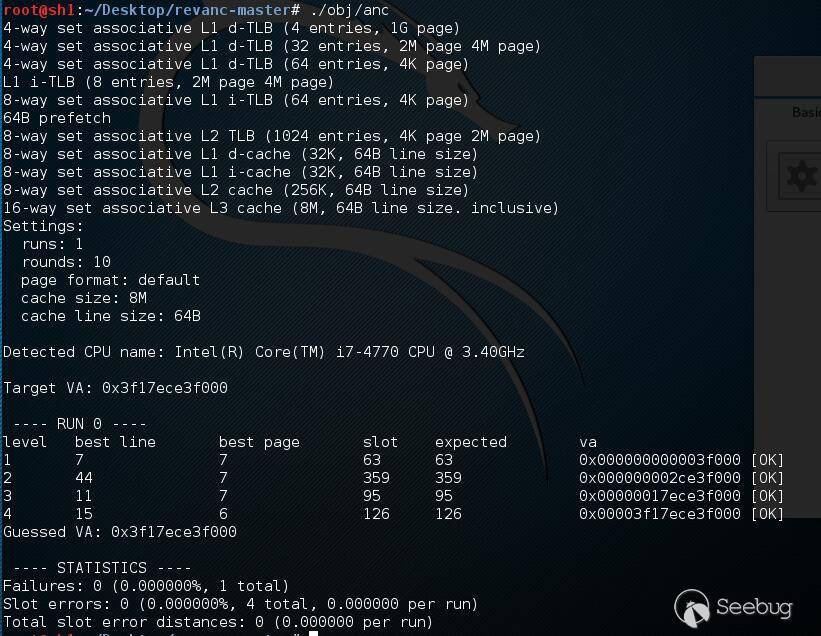
首先我們來看一下整個源碼的運行情況,通過測試,這個源碼并非每次都能夠跑出最后結果,可能受緩存噪聲等因素的影響,導致有時候是失敗的。
失敗的情況:
成功的情況:
AnC論文梗概
第二章我們將提出威脅模型
第三章我們將講解地址轉換的細節
這一章我們將講解在AnC利用過程中碰到的問題,以及如何解決的
第四五章我們將講解解決每一個問題的細節
第六章我們會講解AnC攻擊最新Linux上運行的Chrome瀏覽器和火狐瀏覽器的細節
我們將會展示AnC成功對瀏覽器堆的ASLR和火狐瀏覽器的JIT代碼的ASLR進行去隨機化,同時和現在的繞過ASLR的方法相比速度更快,需求更低。
第七章我們將討論AnC對于基于瀏覽器的漏洞利用和對于依賴于在地址空間中的信息隱藏或泄露對抗ASLR的安全防御的影響
第八章我們將討論緩解攻擊的方法
最后一章作為結束部分。
首先我們需要了解AnC攻擊的基本原理,實際上就是要了解物理地址和虛擬地址的轉換,頁表級之間的轉換規則,相關的內容,在安全客上有一篇關于這個基礎原理的翻譯。
http://bobao.#/learning/detail/3520.html
對于這種攻擊方式的理解,重要的就是下面兩幅圖:
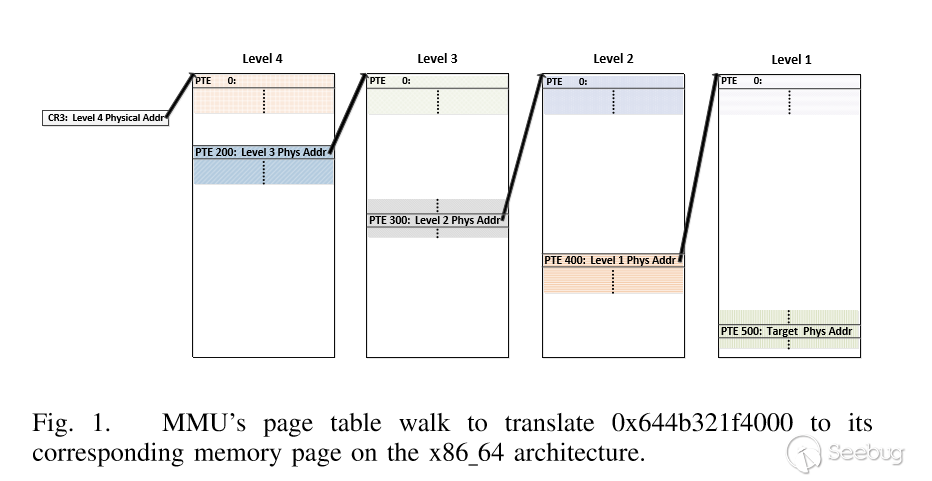
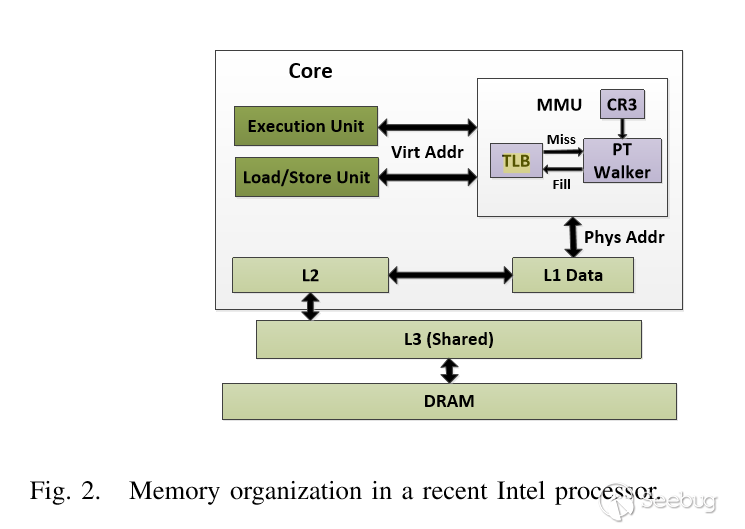
我們重點關注第五章 AnC的實施
第五章 AnC實施
安裝我們的TTT和SMC計時器,我們現在繼續執行第三章D節中描述的AnC。 首先在第五章A節中,我們將展示我們如何在訪問目標堆以及的目標JIT區域上執行代碼時觸發MMU遍歷。 然后我們將在第五章的B、C、D節中討論如何識別存儲目標虛擬地址的頁表項的頁偏移。 在第五章的E、F節中,我們將講解我們用于觀察信號并唯一地識別存儲它們的緩存行內的頁表項的位置的技術。 在第五章G、H節中,我們討論了通過激活頁表緩存和消除噪聲來清理MMU信號的技術。
A.觸發MMU頁表遍歷
為了觀察CPU緩存上的MMU活動,我們需要確保1)當我們訪問目標時,我們知道緩沖區中頁偏移,2)我們能夠驅逐TLB以觸發MMU 在目標內存位置上遍歷。 我們討論如何從堆內存和JIT代碼中實現這些目標。
堆:我們使用ArrayBuffer類型來回退我們試圖去隨機化的堆內存。 ArrayBuffer總是頁對齊的,這使我們能夠預測目標ArrayBuffer中任何索引的相對頁偏移量。 最近Intel處理器有兩個級別的TLB。 第一級包括指令TLB(iTLB)和數據TLB(dTLB),而第二級是更大的統一的TLB緩存。 為了同時使用數據TLB和已定義的TLB,我們訪問TLB驅逐緩沖區(應該是被驅逐行所保存的緩沖區)中的每個頁面,其大小大于已定義的TLB。 我們后面將展示該TLB驅逐緩沖區也可以用于在期望的偏移處驅逐LLC高速緩存集合。
代碼:為了分配足夠大的JIT代碼區域,我們在一個asm.js模塊中噴射2的17次方個JavaScript函數。我們可以通過改變由JIT引擎編譯的語句的數量來調整這些函數的大小。這些函數的機器碼從一個依賴于瀏覽器的但是在頁面中已知的偏移開始,并且在內存中彼此跟隨,并且由于我們可以在目標瀏覽器上預測它們(機器碼)的大小,我們知道每個函數從asm.js對象開始位置的偏移。為了最小化這些函數對緩存的影響但不影響它們的大小,我們在所有函數的入口添加一個if語句,以便我們可以不執行函數的邏輯。為了不遮蔽頁表緩存行信號,我們的目標是一旦執行就擊中單個高速緩存行,但這樣做仍然會讓功能之間存在大塊偏移。為了在執行我們的一個功能時觸發頁表遍歷,我們需要使用iTLB和已定義的TLB。為了使用iTLB,我們使用一個單獨的asm.js對象,并執行一些功能,這些功能跨越了超過iTLB大小的頁面。為了使用統一的TLB,我們使用我們用于堆的相同的TLB驅逐緩沖區。
正如我們稍后將討論的,AnC將會在每一輪中觀察到一個頁偏移量。 這允許我們以不會干擾測量中的頁偏移的方式為統一的TLB驅逐緩沖區選擇iTLB驅逐函數和頁偏移。
B.PRIME+PROBE和MMU信號
AnC的主要思想是我們可以觀察MMU的頁偏移對LLC的影響。 我們可以為此目的實現兩種攻擊[49]:PRIME + PROBE或EVICT + TIME。 要實施PRIME + PROBE攻擊,我們需要遵循以下幾個步驟:
1、為所有可用的頁顏色構建最佳LLC驅逐集。 最佳驅逐集是被接收的內存位置的精確數目(取決于LLC設置的相關性),確保目標緩存行從托管目標緩存行的LLC緩存集合中被驅逐。
2、通過訪問所有驅逐集合來引導LLC。
3、訪問我們想要去隨機化的目標虛擬地址,使其頁表項進入LLC。
4、通過訪問所有驅逐集并測試其中哪個執行需要更長時間來探測LLC。
需要較長時間執行的驅逐集可能需要從內存中提取一個(或者多個)項,由于在初始階段,驅逐集中的條目已經被傳入LLC,并且唯一的內存引用(除了TLB驅逐集之外)是目標虛擬地址,因此, 這些“被探測的”驅逐集合中的四個已經托管了用于目標虛擬地址的頁表項。 如前所述,這些緩存組唯一地標識每個頁表級的頁表項偏移的高6位。
然而,這種方法有兩個問題。首先,從JavaScript建立最優的LLC驅逐集,PRIME + PROBE是必需的,而最近已經被證明可能需要花費時間,特別是沒有精確的計時器。第二,執行PRIME + PROBE攻擊可能存在誤差,因為我們試圖測量的目標將在測量中產生噪聲。更確切地說,我們需要在訪問目標虛擬地址之前清除TLB。我們可以在啟動步驟之前或之后這樣做,但是在任一情況下,驅逐TLB將導致MMU執行一些我們不想要的頁表遍歷。假設我們在主要步驟之前執行TLB驅逐。在執行初期步驟期間訪問LLC驅逐集的中間,很有可能會發生許多TLB未命中,導致頁表遍歷可能在我們不知情的情況下填充已經被引導的緩存集,在探測步驟中會產生許多錯誤信息。現在假設我們在完成步驟之后執行TLB驅逐的步驟。類似的情況可能會發生:TLB驅逐集中的一些頁面將導致頁表遍歷,導致填充已經被引導的緩存集,并且再次在探測中產生錯誤信息。
我們使用PRIME + PROBE在最開始實現AnC。 它花費了很長時間來建立最佳驅逐集,并且最終由于噪聲很高而不能識別MMU信號。 為了解決這些問題,我們利用我們的目標的獨特屬性,這樣可以不建立最佳驅逐集(第五章C節),從而不會產生大量噪聲,并且由于能夠控制觸發器(MMU的頁表遍歷),我們可以選擇一個更奇特的EVICT+TIME 攻擊,允許我們避免PRIME + PROBE(第五章D節)的缺點。
C.緩存顏色對AnC來說不重要
基于緩存的邊信道攻擊受益于在后端操作之后的緩存狀態中可用的整合信息 - 受害者訪問的緩存集。 緩存集由顏色(即頁顏色)和頁(緩存行)偏移量唯一標識。 例如,具有8192個緩存集的LLC中的緩存集可以由(顏色,偏移)元組標識,其中0≤color<128并且0≤offset <64。
ASLR對頁偏移中的指針(即,隨機化指針)進行編碼。 我們可以為頁面內的64個緩存行偏移量中的每一個構建一個驅逐集合,驅逐每個集合的該緩存行偏移量的所有顏色。 唯一的問題是不同頁表級的頁表項可能使用不同的頁面顏色,因此,我們就會看到重疊的偏移信號。 但是考慮到我們可以控制觀察到的虛擬地址相對于我們的目標虛擬地址的偏移,我們可以控制不同頁表級內的頁表項的偏移,如第三章D節所述,來解決這個問題。
在下面的描述中,我們的EVICT + TIME攻擊不依賴驅逐集的執行時間。 這意味著我們不需要構建最佳驅逐集。 加上ASLR對顏色不可知的事實,我們可以使用任何頁面作為驅逐集合的一部分。 不能使用特定的顏色布局方案來分配頁表來避免顯示這個信號,因為它們都會出現在我們的驅逐集中。 這意味著,在足夠大量的內存頁的情況下,我們可以在給定頁偏移量下從LLC(和L1D和L2)逐出任何頁表項,而不依賴于需要很長時間構建的最佳驅逐集。
D.MMU上的EVICT+TIME攻擊
對加密密鑰或竊聽的傳統側信道攻擊有利于觀察整個LLC的狀態。 這就是為什么諸如PRIME + PROBE 和FLUSH + RELOAD是允許攻擊者觀察LLC的整個狀態的側信道攻擊的原因。
與這些攻擊相比,EVICT + TIME只能在每個測量周期獲得關于一個緩存集的信息,與PRIME + PROBE等攻擊相比,減少了帶寬。 EVICT + TIME進一步做出強有力的假設,即攻擊者可以在執行后臺運算時觀察目標主機的性能。 雖然這些屬性經常使EVICT + TIME比其他的緩存攻擊差,但是它容易地適用于AnC:AnC不需要高帶寬(例如,破解加密密鑰),并且它可以監視受害者(即,MMU),因為其執行后臺(即,頁表遍歷)。EVICT + TIME在以下步驟中實現AnC:
1.使用一個足夠大的內存頁集作為驅逐集。
2.對于在可能的64個偏移中的偏移t處的目標緩存行,通過讀取驅逐集中的所有內存頁中的相同偏移量來驅逐緩存行。 訪問此集合還會刷新dTLB和已指定的TLB。 如果我們是目標代碼,通過在偏移量t執行函數來調用iTLB。
3.通過在堆目標的情況下解引用,或者在代碼目標的情況下在該位置執行函數時,訪問我們想要在與t不同的緩存行去隨機化的目標虛擬地址。
EVICT + TIME的第三步觸發頁表遍歷,取決于偏移t的緩存行是否是托管頁表項緩存行,操作將需要更長或更短的時間。 EVICT + TIME解決了我們面對PRIME + PROBE的問題:首先,我們不需要創建最佳的LLC驅逐集,因為我們不依賴驅逐集提供信息,其次,LLC驅逐集是用TLB驅逐集,減少由于較少的頁表遍歷產生的噪聲。 更重要的是,這些頁表遍歷(由于TLB未命中)導致顯著減少錯誤信息,還是因為我們不依賴于探測驅逐集來獲得時間信息。
由于這些改進,當在解引用堆地址和執行JIT函數時,在JavaScript中的所有64個可能的緩存行偏移上嘗試EVICT + TIME時,可以觀察到與目標虛擬地址的頁表項對應的緩存行偏移。 我們在第七節提供進一步的評估,但在此之前,我們描述如何可以唯一地標識由EVICT + TIME標識的緩存行內的頁表項的偏移量。
E.頁表項切片
在這個階段,我們已經識別了在不同頁表級的頁表項的(可能重疊的)緩存行偏移。 對于ASLR仍然保留兩個熵源:由于不可能區分哪個緩存行偏移屬于哪個頁表級,并且緩存行內的頁表項的偏移量尚未知道。 我們通過分配一個足夠大的緩沖區(在我們的這種情況下是分配一個2G的空間)和訪問這個緩沖區中的不同位置來解決這兩個熵源,以便對已經分配了緩沖區的虛擬地址去隨機化。 我們對PTL1和PTL2去隨機化的方法不同于我們對PTL3和PTL4去隨機化的額方法。 我們在下面描述這兩種技術。
將PTL1和PTL2去隨機化:讓我們從PTL1的頁表項托管目標虛擬地址v的緩存行開始。我們觀察到當(可能的)4個高速緩存行之一改變時,因為我們訪問v + i×4KB, 1,2,...,8}。 如果其中一個緩存行在i處改變,它立即向我們提供兩條信息:改變的緩存行正在托管PTL1的頁表項,并且PTL1的v的頁表項偏移是8-i。 我們可以執行相同的技術在PTL2對頁表項去隨機化,但是現在我們需要增加2MB觀察PTL2,這樣能達到和每次增加4KB的地址相同效果。 作為示例,圖5示出了當我們改變PTL1處的頁表項的緩存行時AnC觀察到的示例MMU活動。
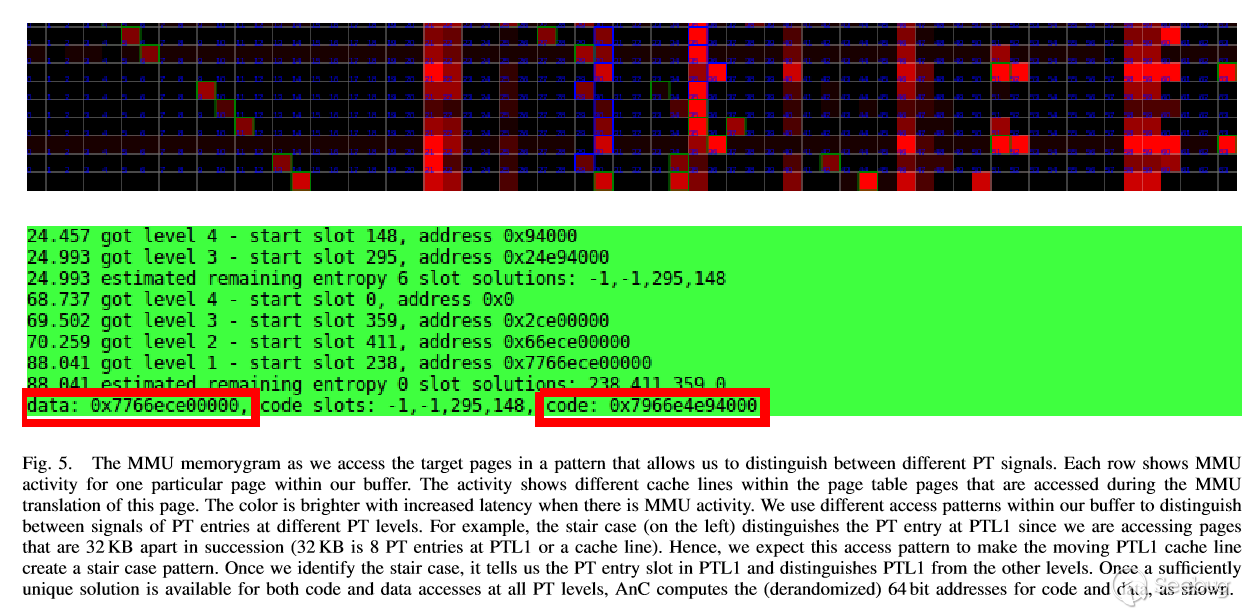
將PTL3和PTL4去隨機化:如我們在第三章E節中討論的,為了使PTL3去隨機化,我們在我們的2GB分配內的虛擬地址空間中進行一個的8GB交叉,用來對PTL4去隨機化,我們需要在我們分配的空間內進行一個4TB虛擬地址空間交叉。我們依賴于第六節討論的內存分配器在瀏覽器中的行為,以確保我們的(許多)分配之一滿足這個屬性。但是假設我們在PTL3或PTL4改變了緩存行,則我們希望檢測和去隨機化相對的級別。 注意,在PTL4處交叉的緩存行將不可避免地導致高速緩存行在PTL3處交叉。
記住PTL3上的每個頁表項都覆蓋1GB的虛擬內存。 因此,如果在PTL3處的緩存行交叉在我們的2GB分配空間內發生,則當交叉正好在緩沖區的中間時,我們的分配可以覆蓋兩個或三個PTL3頁表項。 因為完全在中間的交叉是不可能的,我們考慮具有三個頁表項的情況。 三個頁表項中的兩個或一個在新的緩存行中。 通過在訪問分配中的第一頁,中間頁和最后一頁時觀察PTL3緩存行,我們可以很容易地區分這兩種情況,并完全去隨機化PTL3。
只有在PTL3處的緩存行在其相應頁表頁中的最后時隙中時才發生在PTL4處緩存行交叉。 通過執行類似的技術(即,訪問分配中的第一和最后一頁),如果觀察到頁表項緩存行PTE2從最后一個時隙改變到第一時隙,并且另一個頁表項緩存行PTE1向前移動一個時隙, 可以結束PTL4交叉并且獨特地將PTE2鑒定為PTL3處的頁表項并且將PTE1鑒定為PTL4處的頁表項。
F.解決ASLR
我們創建了一個簡單的求解器,以便對可能的解決方案進行排名,因為我們在2GB分配空間中搜索不同的頁面。 我們的求解器為我們的分配緩沖區的第一頁的每個頁表級假定512個可能的頁表項,并且在每個頁表級獨立于其他級別對解決方案進行排名。
當我們使用我們在第五章E1節和第五章E2節中描述的方法在緩沖區中探索更多頁面時,我們的求解程序在其中一個解決方案中獲得顯著的置信度,或者放棄并開始一個新的2GB分配。 如果在這些頁表級存在緩存行交叉,則解決方案會始終對PTL1和PTL2以及PTL3和PTL4進行去隨機化。
G.驅逐頁表緩存
如第三章B節所述,一些處理器可以將針對不同頁表級的翻譯結果緩存在其TLB中。 AnC需要驅逐這些緩存以便觀察來自所有頁表級的MMU信號。 這很簡單:我們可以訪問一個大于這些緩存大小的緩沖區作為TLB和LLC驅逐的一部分。
例如,Skylake i7-6700K內核可以緩存32個項用于PTL2查找。 假設我們探測在頁表頁的第i個高速緩存行中是否存在頁表活動,訪問0 + i×64,2MB + 1×64,4MB + i×64的64MB(即,32×2MB) 64,...,62MB + i×64將驅逐PTL2頁表緩存。
雖然我們需要實現這種機制并本地觀察所有頁表級的信號,我們注意到由于JavaScript運行活動,這些頁表緩存在我們的探測期間會被自然驅逐。
H.處理噪聲
實現旁信道攻擊的主要問題是噪聲。 我們部署了許多對策,以減少噪聲。 我們在這里來介紹一下:
隨機探測:為了避免硬件預取器引起的錯誤,我們(仍然)需要探索的可能剩余偏移量中隨機選擇t(我們驅逐的頁偏移量)。這種隨機選擇也有助于均勻由系統事件引起的局部噪聲。
每個偏移量多次采樣:為了增加探測的可靠性,我們對每個偏移量進行多次采樣(“回合”),并考慮用于決定緩存與存儲器訪問的中值。 這個簡單的策略大大降低了假陽性和假陰性。 對于大規模實驗和可視化測量對其他求解參數的影響,請參見第七章C節
對于AnC攻擊,假定是無影響的,因為攻擊者總是可以使用新的分配重試,我們將在下一節中討論。 我們使用Chrome和Firefox在第七節中評估AnC攻擊的成功率,誤報和假否定。
I.討論
我們實現了兩個版本的AnC。 在C中的本機實現,以便研究不具有JavaScript干擾和JavaScriptonly實現的MMU頁表遍歷活動的行為。
我們將本機版本移植到不同的體系結構和Microsoft Windows 10,以顯示第七章D節中介紹的AnC的通用性。 我們的移植努力圍繞著實現本地版本的SMC(第四章B節)來準確區分ARM上的緩存和非緩存內存訪問,ARM只提供粗粒度(0.5μs)定時機制和處理不同的頁表結構。 我們的本地實現代碼共1283行。
我們的JavaScript專門在Chrome和Firefox瀏覽器上工作,目的是展示在第七章中的各種實驗中提出的AnC攻擊對操作系統的影響。我們需要使用asm.js 調整JavaScript實現,來使測量更快,更可預測。這限制了我們的分配大小最大是2GB。 我們的JavaScript實現用了2370行代碼。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/226/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/226/
暫無評論