
作者:evilpan
原文鏈接:https://mp.weixin.qq.com/s/w6und9w0CAlcISrrJX4vnA
背景
在四月份的時候出了那么一個新聞,說微信有一個點擊圖片就崩潰的 bug,當時各大微信群里都在傳播導致手機各種閃退。
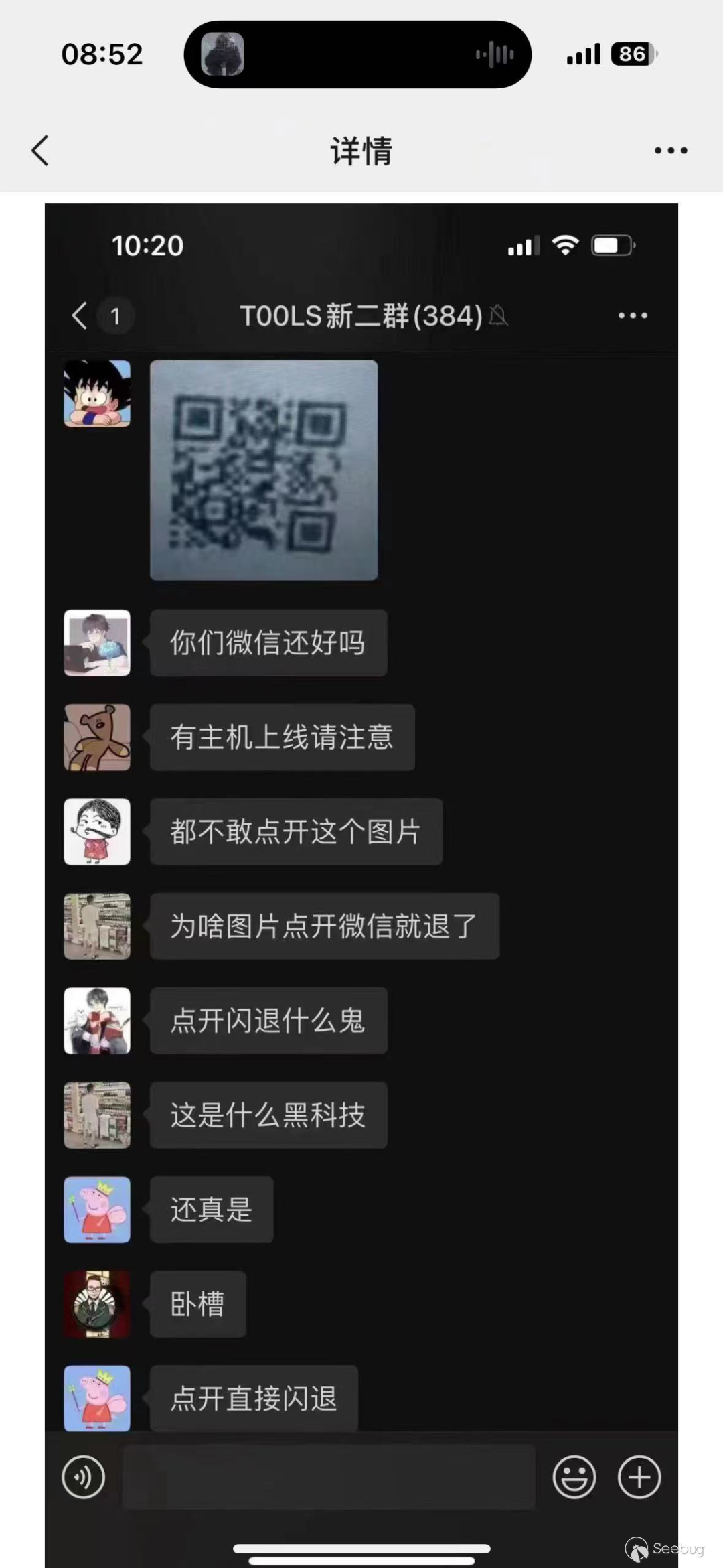
由于當時筆者正在忙著卷 Java Web,沒有第一時間去蹭這個熱點,不過當時也稍微了解了一下 crash 的原理。最近對于 Java 的漏洞挖掘正好告一段落,于是就突然想起了這個事。
這個 bug 的根源在于一個畸形的二維碼解碼時導致的空指針錯誤,詳細分析和修復的記錄可以參考 fix(wechat_qrcode): Init nBytes after the count value is determined #3480。
在國內二維碼可以說是隨處可見的東西,如果說解碼的核心 SDK 有漏洞,那么很可能影響非常廣泛。加上許多應用,基于各種奇怪的業務和目的還實現了靜默解碼的功能,要是能夠發現一個可以利用的漏洞,那也是一個典型的 0-click 場景。
因此筆者打算簡單 Fuzz 一下相關的二維碼解碼代碼,放在服務器后臺慢慢跑著,也不會過多占用搬磚時間,希望哪天清晨 boki 醒來能夠有些意外收獲。
編譯
Fuzz 的第一步自然是先能成功編譯目標代碼,然后再嘗試使用帶插樁的編譯器進行編譯。
之前出現問題的代碼倉庫是 https://github.com/opencv/opencv_contrib,這是 opencv 下的一個子倉庫,提供了許多額外的 OpenCV 模塊,根據 README 的介紹,編譯這些模塊的過程如下:
$ cd <opencv_build_directory>
$ cmake -DOPENCV_EXTRA_MODULES_PATH=<opencv_contrib>/modules <opencv_source_directory>
$ make -j5也就是說編譯這些模塊還需要依賴 OpenCV 的源代碼倉庫,因此我們把這兩個倉庫都下載下來進行編譯。這里圖省事我就直接使用 AFL++ 進行編譯了,使用 cmake 的編譯命令如下:
cmake -DCMAKE_C_COMPILER=afl-clang-fast -DCMAKE_CXX_COMPILER=afl-clang-fast++ \
-DCMAKE_CXX_FLAGS="-fsanitize=address,undefined -fno-sanitize-recover=all -g" \
-DCMAKE_C_FLAGS="-fsanitize=address,undefined -fno-sanitize-recover=all -g" \
-DCMAKE_EXE_LINKER_FLAGS="-fsanitize=address,undefined -fno-sanitize-recover=all" \
-DCMAKE_MODULE_LINKER_FLAGS="-fsanitize=address,undefined -fno-sanitize-recover=all" \
-DCMAKE_BUILD_TYPE=Debug,ASAN,UBSAN -DWITH_SSE2=ON -DMONOLITHIC_BUILD=ON -DBUILD_SHARED_LIBS=OFF \
-DOPENCV_EXTRA_MODULES_PATH=/home/evilpan/fuzzing/opencv_contrib/modules \
/home/evilpan/fuzzing/opencv
make -j128 -C modules/wechat_qrcode關鍵點在于不編譯動態庫,而是使用靜態庫,因為 AFL 對于最終的測試程序只會測試靜態編譯代碼中的覆蓋率而不會考慮動態編譯的庫。
后來發現 cmake 可以不用指定那么多選項,只需要指定 afl-clang,config 之后在 make 時通過環境變量指定 AFL_USE_ASAN 即可,AFL 會選擇好合適的編譯參數。參考:https://aflplus.plus/docs/fuzzing_in_depth/
$ cmake -DCMAKE_C_COMPILER=afl-clang-fast -DCMAKE_CXX_COMPILER=afl-clang-fast++ -DBUILD_SHARED_LIBS=OFF
$ env AFL_USE_ASAN=1 make -j32小試牛刀
編譯完后就可以編寫測試代碼了。不過根據前面的 pull-request,在修復漏洞時也提供了一個 testcase:
TEST(Objdetect_QRCode_bug, issue_3478) {
auto detector = wechat_qrcode::WeChatQRCode();
std::string image_path = findDataFile("qrcode/issue_3478.png");
Mat src = imread(image_path, IMREAD_GRAYSCALE);
ASSERT_FALSE(src.empty()) << "Can't read image: " << image_path;
std::vector<std::string> outs = detector.detectAndDecode(src);
ASSERT_EQ(1, (int) outs.size());
ASSERT_EQ(16, (int) outs[0].size());
ASSERT_EQ("KFCVW50 ", outs[0]);
}可以參考這個代碼來編寫我們的 test-harness。我這里是直接改掉了 test_main.cpp,不使用單元測試框架而是直接自己編寫,一個初始的 test-harness 代碼如下:
int main(int argc, char **argv) {
if (argc < 2) return 1;
std::string image_path(argv[1]);
Mat src = imread(image_path, IMREAD_GRAYSCALE);
if (!src.empty()) {
auto detector = wechat_qrcode::WeChatQRCode();
std::vector<std::string> outs = detector.detectAndDecode(src);
}
return 0
}修改后只需要重新編譯這個模塊即可:
make -C modules/wechat_qrcode生成的測試二進制文件為 build/bin/opencv_test_wechat_qrcode:
afl-fuzz -i corpus/ -o output -t +2000 -- ./opencv_test_wechat_qrcode @@corpus 中隨便丟了幾張畸形二維碼文件,直接開跑!

雖然能跑,但是慢的一批!
初步優化
上面的的 fuzz 代碼實在太慢,必須要進行優化!組織架構調整!把寒氣也傳遞給每一個 fuzzer!
由于前面的的運行是直接讀取文件,因此一個直觀的優化是使用 AFL++ 的 persistent mode,稍微修改一下代碼,直接把 buffer 當做源圖片進行讀取,如下所示:
int fuzz_buf(unsigned char *buf, size_t size) {
Mat src = imdecode(Mat(1, size, CV_8UC1, buf), IMREAD_GRAYSCALE);
if (!src.empty()) {
auto detector = wechat_qrcode::WeChatQRCode();
std::vector<std::string> outs = detector.detectAndDecode(src);
return outs.size();
}
return -1;
}
__AFL_FUZZ_INIT();
int main(int argc, char **argv) {
// if (argc < 2) return 1;
// return fuzz(argv[1]);
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF;
while (__AFL_LOOP(10000)) {
int len = __AFL_FUZZ_TESTCASE_LEN;
fuzz_buf(buf, len);
}
return 0;
}這次執行就不需要 @@ 了,可以直接運行:
afl-fuzz -i corpus/ -o output -t +2000 -- ./opencv_test_wechat_qrcode_persist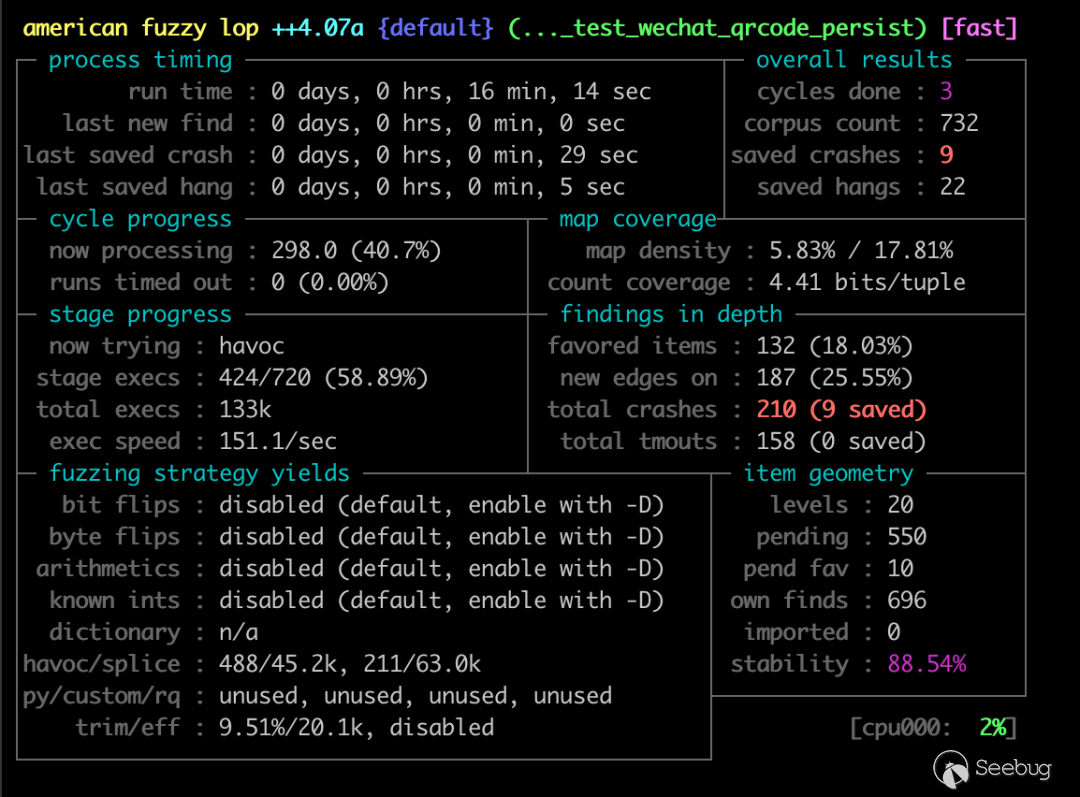
可以看到速度已經有了顯著的提升!并且跑了十幾分鐘后就已經出現了 Crash!
再次優化
先暫停前面的 fuzzer 來分析一下現有的 crash,執行出現的崩潰都大致如下所示:
$ ./opencv_test_wechat_qrcode output/default/crashes/id\:000001\,sig\:06\,src\:000478\,time\:871148\,execs\:98951\,op\:havoc\,rep\:4
terminate called after throwing an instance of 'cv::Exception'
what(): OpenCV(4.7.0-dev) /home/jielv/fuzzing/opencv/modules/imgcodecs/src/loadsave.cpp:74: error: (-215:Assertion failed) size.width > 0 in function 'validateInputImageSize'
Aborted其實,我對你是有一些失望的。當初把你寫出來,是希望你能對標古河的。我是希望你跑起來后,你能夠拼一把,快速給我幾個 segment fault。對于你這個層級,不是丟出幾個 Abort 就可以的。
雖然也有我 -g 的原因,但這里的 Abort 實際上都出現在上面的 imdecode 中,這跟我的預期有點跑偏,明明想跑的是二維碼解碼,結果卻在無關的地方運行了半天。雖然 image codec 也是一個攻擊面,但并不是現在想要搞的,而且這個攻擊面肯定也被很多其他人搞過了,出現問題的幾率并不是很大。
因此,我們需要進一步優化代碼。現在 AFL 變異的是 jpg/png 的圖片,但我們想要變異的其實是二維碼的圖片內容!因此這次優化有兩個思路:
- 提供自定義的變異策略,每次返回一個變異的二維碼;
- 還是讓 AFL 自己變異,但是變異后的內容直接轉成
cv::Mat然后進行二維碼解碼;
不管使用哪個思路,都需要能夠將圖片和 cv::Mat 進行互相轉換,否則即便有 crash 也可能不能生成合法的圖片導致無法利用。
Mat2Vector
一開始想著偷個懶,直接讓 ChatGPT 來幫我生成代碼將 Mat 轉成字符數組,如下所示:
std::vector<char> mat_to_vector(const cv::Mat& mat) {
// Copy data from cv::Mat to vector<char>
std::vector<char> data(mat.data, mat.data + mat.total() * mat.elemSize());
return data;
}然后,將原來的預料圖片用 imread 讀取成 cv::Mat,并用上面的函數轉成 vector 并保存到磁盤中,形成新的預料,這樣在變異的時候可以直接變異并生成 cv::Mat:
int fuzz_buf(unsigned char *buf, size_t size) {
// Mat src = imdecode(Mat(1, size, CV_8UC1, buf), IMREAD_GRAYSCALE);
Mat src = Mat(std::vector<unsigned char>(buf, buf + size));
return fuzz_mat(src);
}理想很美好,但是這樣跑并沒有結果!猜測是 Mat 中除了 data 數據,應該還有一些元數據(metadata),用以表示矩陣的特性,比如行/列,直接填入數據無法表示原始的矩陣,從而在二維碼解碼時很早就出錯退出了。
cv::Mat
既然偷懶走不通,就只能認真看一下 Mat 了。
cv::Mat 是 OpenCV 中用于表示 n 維數組的數據結構,用于表示 n 維的單通道或者多通道數組,通常是結構比較緊湊的矩陣。對于稀疏數據的高維矩陣則一般用 SparseMat 來進行表示。
對于矩陣/數組 M 而言,其數據布局根據 data 和 step 決定,例如對于二維數組:
M.at(i,j) = M.data + M.step[0] * i + M.step[1] * j注意 M.step[i] >= M.step[i+1],事實上 M.step[i] >= M.step[i+1]*M.size[i+1]。這意味著對于二維矩陣而言,數據是按照行進行存儲的(row-by-row),而對于三維矩陣數據則是按面進行存儲(plane-by-plane)。
我們的目標是創建一個代表二維碼圖片的 Mat,最好是能夠保存到磁盤中并從磁盤讀取,方便我們使用 afl-fuzz 指定語料并進行 fuzz。于是想著有沒有什么序列化/反序列化是針對 cv::Mat 的,查了一下還真有,序列化的代碼如下:
cv::Mat img = cv::imread("example.jpg"); // Load an image
cv::FileStorage fs("example.yml", cv::FileStorage::WRITE); // Create a file storage object for writing
fs << "image" << img; // Write the image to the file
fs.release(); // Close the file反序列化過程和序列化過程類似:
cv::Mat img;
cv::FileStorage fs("example.yml", cv::FileStorage::READ); // Create a file storage object for reading
fs["image"] >> img; // Read the image from the file
fs.release(); // Close the file這里是將 cv::Mat 序列化成了 YAML 數據,輸出的格式如下:
%YAML:1.0
---
img: !!opencv-matrix
rows: 480
cols: 640
dt: u
data: [ 103, 103, 104, 107, 110, 112, 112, 111, 114, 113, 113, 115,
...
134, 135, 134, 132 ]如果將 YAML 文件作為語料的話,又涉及了 YAML 的解析以及 FileStorage 中的無關代碼,和需求有所差距。不過從序列化的數據中我們能夠看出一點,即 cv::Mat 中除了 data 數據外包含的額外元數據只有 rows、cols 和 dt。其中 dt 應該表示 data type,u 是 CV_8U 的縮寫。
由于這是一個黑白的,480x640 的二維碼圖片,如果我們想要變異 cv::Mat,只需要保存行/列/類型不變,針對 data 區域進行 bitflip 變異即可!
不過,只進行 bitflip 變異的空間將會高達 2^(640*480),無疑是個幾何數據,即便是只針對小尺寸圖片如 20x20 那也是不能接受的。因此我們還是寄希望于 AFL 的覆蓋率反饋能產生合適的變異!
First Blood
使用上述策略優化之后裁剪語料的長度,僅使用一個 29x29 的二維碼圖片生成的矩陣作為初始語料進行變異:
int fuzz_buf(void *buf, size_t size) {
// Mat src = imdecode(Mat(1, size, CV_8UC1, buf), IMREAD_GRAYSCALE);
if (size < 841) return -1;
Mat src = Mat(29, 29, CV_8U, buf);
return fuzz_mat(src);
}跑起來之后發現速度又變得很慢,估計語料還是太大,先放在后臺跑一會,然后去看了兩集異世界廁紙番。回來之后發現居然有 crash:
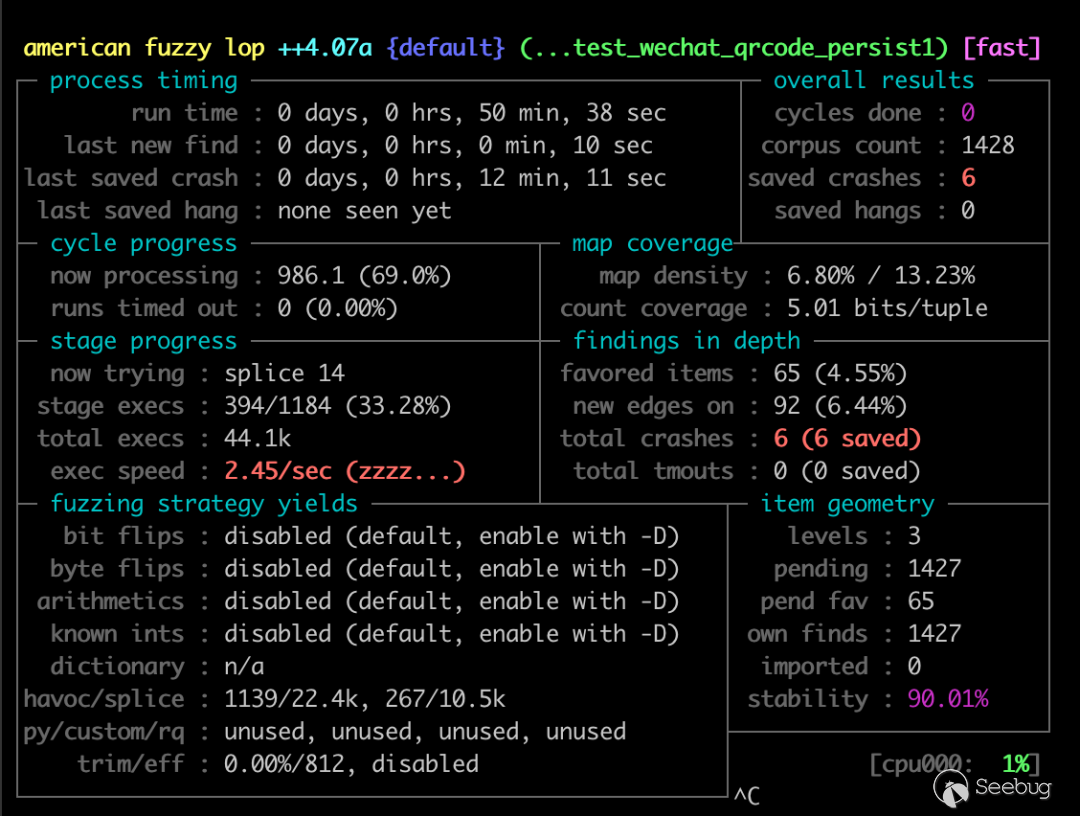
簡單分析一下發現都是同一處代碼的 crash,精簡的 poc 執行輸出如下:
$ opencv_test_wechat_qrcode poc.bin
/home/evilpan/fuzzing/opencv_contrib/modules/wechat_qrcode/src/zxing/qrcode/detector/detector.cpp:1022:50: runtime error: signed integer overflow: -2147483648 + -2147483648 cannot be represented in type 'int'這是一個整數溢出,出現在 qrcdoe 檢測過程中計算維度時:
int Detector::computeDimension(Ref<ResultPoint> topLeft, Ref<ResultPoint> topRight,
Ref<ResultPoint> bottomLeft, float moduleSizeX, float moduleSizeY) {
int tltrCentersDimension = ResultPoint::distance(topLeft, topRight) / moduleSizeX;
int tlblCentersDimension = ResultPoint::distance(topLeft, bottomLeft) / moduleSizeY;
float tmp_dimension = ((tltrCentersDimension + tlblCentersDimension) / 2.0) + 7.0; // 問題在這行
int dimension = cvRound(tmp_dimension);
int mod = dimension & 0x03; // mod 4
switch (mod) { // mod 4
case 0:
dimension++;
break;
// 1? do nothing
case 2:
dimension--;
break;
}
return dimension;
}計算錨點時 tltrCentersDimension + tlblCentersDimension 產生了整數溢出,PoC 如下:
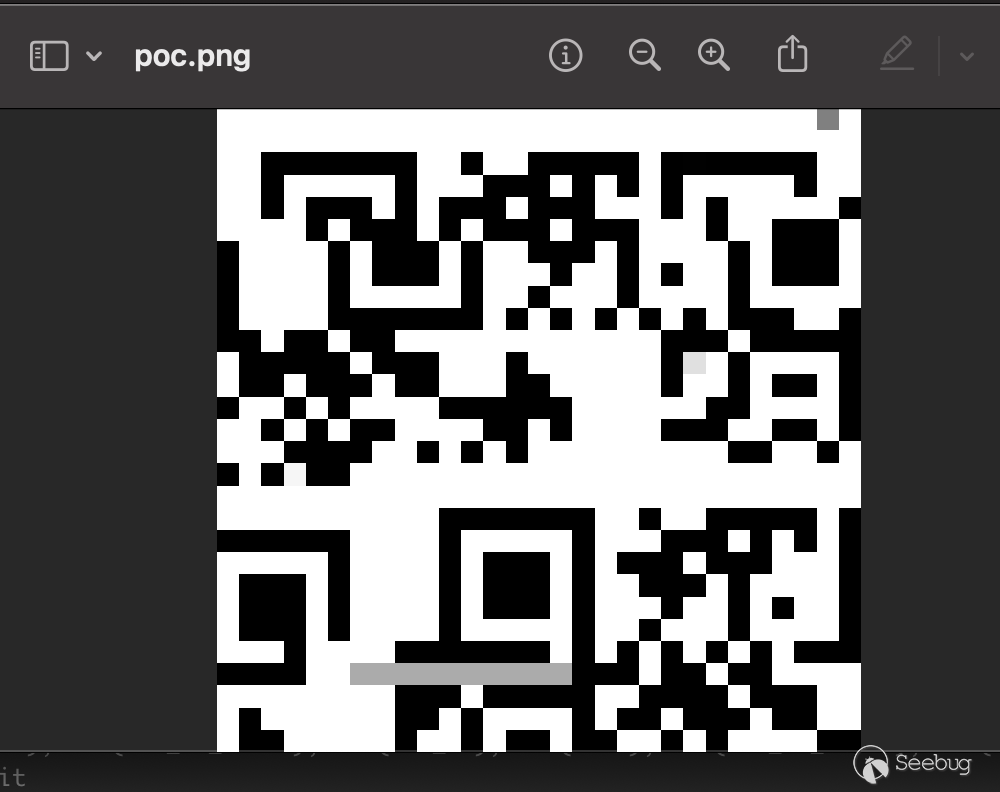
當然,這個 PoC 直接掃碼是掃不出來的,因為我們傳入的是原始數據,而且是死在了 detector 之中。
畫蛇添足
雖然現在已經可以產生一些崩潰,但注意到圖像并不是二值圖像而是灰度圖,因為我們原始的語料是 Mat.data() 保存而成的二進制數據,這個數據中每個像素還是 8 bit 的,只不過只有兩種值,分別是 0 和 255,而我們變異過程中就成了灰度圖。
為了解決這個問題,我們只能重新構建序列化的數據結構,確保每個字節的變異都能產生有效的二值圖像。圖像中每個像素只占 1 bit,由于內存是字節尋址的,每個字節可以保存 8 個像素。
寫了個 MatWrapper 來封裝 cols、rows、type 和 data 數據,并添加 serialize/deserialize 方法去實現序列化:
class MatWrapper {
public:
int mRows;
int mCols;
int mType;
int mSize;
std::vector<uchar> mBuf;
MatWrapper() {}
void save(const std::string& filename, bool compact=false) {
std::ofstream fs(filename);
fs << serialize(compact);
fs.close();
}
void load(const std::string& filename, bool compact=false) {
std::stringstream ss;
std::ifstream file(filename, std::ios::binary);
ss << file.rdbuf();
deserialize(ss.str(), compact);
}
void fromImage(const std::string& filename) {
auto mat = imread(filename, IMREAD_GRAYSCALE);
mRows = mat.rows;
mCols = mat.cols;
mType = mat.type();
// assert(mat.elemSize() == 1);
mSize = mat.total() * mat.elemSize();
mBuf = std::vector<uchar>(mat.data, mat.data + mSize);
}
void toImage(const std::string& filename) {
imwrite(filename, get());
}
Mat get() { return Mat(mRows, mCols, mType, mBuf.data()); }
std::string serialize(bool compact = false) const { }
bool deserialize(const std::string& buf, bool compact = false) { }
// ...
};compact 表示是否將 8 像素壓縮為 1 字節,完整代碼比較長這里就不貼了。寫完之后先把之前的二維碼圖片語料批量轉換為了自定義序列化的數據,然后使用 AFL 指定新的語料進行變異和 fuzz。一開始跑出來的都是我自己代碼的 bug (囧),挨個修完之后終于可以很快跑出上面的整數溢出了,而這次的 PoC 也是真正的黑白二維碼圖片。
但是!新的測試用例跑起來也是非常之慢,可能是反序列化的時候做了太多變換,導致速度其實和使用標準的壓縮圖片格式去跑差不多,總而言之感覺有點白給,但還是讓它先跑一會。
二維碼
在把上面的 Fuzzer 放在后臺運行的時,我也想清楚了這個測試用例的問題所在。當前變異的策略雖然能夠生成二值的 Bitmap 圖像,但并不總是合法的二維碼,所以代碼覆蓋率始終在 detect 階段過不去而沒有執行到 decode。
一個理想的策略是每次都能生成隨機的、合法的二維碼,并且在點陣的基礎上進行變異。為此,我們需要先了解二維碼的實現方式。
基本結構
一個二維碼通常由于多個部分組成,如下所示:
此外還有 M3 Micro QR Code,只包含一個定位點,不過比較少用,微信也掃不出來,這里先不介紹。
各個部分的簡單介紹如下:
- Quiet Zone: 二維碼周圍的白邊,底色需要與二維碼的顏色不同防止影響解析;
- Postion Detection Patterns: 位置檢測模式,也稱為定位點,用于定位二維碼;使用點格(module)表示外圍黑邊大小是
7x7,中間的黑塊大小是3x3; - Separators for Postion Detection Patterns: 定位點周圍的分隔線,線寬為一個點格;
- Timing Patterns: 時序模式,用于定位 x/y 軸,二維碼彎曲時可以通過這兩條線的彎曲去進行一定程度的修復;
- Alignment Patterns: 對齊模式,在 Version 2 及以后才有,用于進一步輔助對齊。每個對齊模式的大小是黑格
5x5,白格3x3,中間黑點占一格。對齊模式的個數和 Version 有關; - Format Infomation: 格式信息,占 30 個點格,兩邊各占 15 個,內容相同,互為備份;
- Version Information: 版本信息,也是有兩個互為備份的區塊,各占
3x6大小; - Data and Error Correction Codewords: 數據區,包含編碼的數據正文以及糾錯信息;
二維碼的最小單位是點格(module),一個二維碼邊長所占點格的大小稱為二維碼的維度(Dimension),維度和版本有關:
Dimension = Version * 4 + 17例如當 Version 等于 2 時,邊長就是 25 個點格:

Format Information 區包含了糾錯級別等信息,前面說過一共 15 點格,包括:
- 糾錯等級: 2 點格,即 4 個糾錯等級;
- 數據掩碼: 3 點格,即 8 種掩碼類型;
- 糾錯碼: 10 點格;
糾錯碼計算使用 BCH Code,用到的 Code Words 就保存在前面說過的數據區。
變異策略
了解二維碼的基礎知識之后,我們至少知道了在一個二維碼中哪些能變哪些不能變。二維碼的編碼是相當復雜的,雖然我們可以使用現有的編碼策略去生成二維碼,但是這會導致我們錯過可能由于編碼問題導致的漏洞。
秉承著先跑起來再說的原則,三下五除二用 Python 寫了一個非常丑陋的原型,首先是生成一個隨機的二維碼:
def random_qrcode() -> qrcode.QRCode:
version = randint(1, 40)
box_size = randint(1, 8)
border = 1
error_correction = randint(0, 3)
mask_pattern = randint(0, 7)
data = randstr(randint(1, 25))
qr = qrcode.QRCode(
version=version,
error_correction=error_correction,
box_size=box_size,
border=border,
image_factory=None,
mask_pattern=mask_pattern)
qr.add_data(data)
qr.make()
return qrmake 之后 qrcode 的 modules 已經生成了,所以我們在其基礎上進行變異:
def mutate(qr: qrcode.QRCode, add_buf):
if not add_buf or len(add_buf) == 1:
# do not mutate
return
# flip modules in qrcode randomly
width = len(qr.modules)
rng = random.Random()
flipped = set()
for i in range(0, len(add_buf) - 1, 2):
val = add_buf[i] + (add_buf[i+1] << 8)
if val in flipped:
continue
flipped.add(val)
rng.seed(val)
x = rng.randint(0, width - 1) # col
y = rng.randint(0, width - 1) # row
# print("flip", (x, y))
# avoid position patterns, 7x7 and 1 space
if x < 8 and y < 8:
continue
if x < 8 and y >= (width - 8):
continue
if x >= (width - 8) and y < 8:
continue
qr.modules[y][x] = not qr.modules[y][x]qr.modules 是表示點格的二維數組,我們的變異策略非常簡單粗暴,就是直接基于輸入的數據對點格進行隨機的翻轉,黑的變白的,白的變黑的。幾個小優化:
- 使用 Random 來將 0xffff 大小的隨機數 scale 到寬度 width 的范圍;
- 對于已經翻轉過的點格就不用再次翻轉了;
- 隨機翻轉的范圍排除掉三個角落的定位標志區;
Custom Mutators
現在我們已經可以生成隨機的二維碼圖片了!接下來就需要將其與 Fuzzer 進行結合。在官方文檔 Custom Mutators in AFL++ 中提到,我們可以編譯一個 .so 并通過 AFL_CUSTOM_MUTATOR_LIBRARY 環境變量給 AFL++ 提供自定義的變異器,而且也可以使用 Python API 來提供變異器。
因此我們的 mutator 如下即可:
def fuzz(buf, add_buf, max_size):
"""
Called per fuzzing iteration.
"""
qr = random_qrcode()
mutate(qr, add_buf)
img = qr.make_image()
stream = BytesIO()
img.save(stream, "png")
ret = stream.getvalue()
if len(ret) > max_size:
return bytearray(buf)
return bytearray(ret)注:
fuzz接口的參數 buf 一般包含原始 corpus 的內容,add_buf 則是變異后返回的內容,這里是 PNG 數據。所以前面想把 add_buf 作為變異源來修改 modules 的想法其實是有問題的,當時誤以為 add_buf 是隨機數據但熵根本不夠,因此后面直接把輸入數據忽略了,全部隨機生成。
將其保存為 random_qrcode.py 并使用下面的命令去啟動:
env AFL_CUSTOM_MUTATOR_ONLY=1 PYTHONPATH=$PWD/mutators AFL_PYTHON_MODULE=random_qrcode afl-fuzz -i corpus/ -o output -t +9000 -- ./opencv_test_wechat_qrcode_persist2這里我指定了 AFL_CUSTOM_MUTATOR_ONLY=1,不需要 AFL 自身的變異,因為 AFL 的變異是基于原始語料的,而我并不希望在原始的圖片二進制層級進行變異,否則就又回到了最初的場景。現在我們每次生成一張隨機的二維碼圖片,且肯定是合法的 PNG 格式,避免遭遇圖片解碼時的異常。初始語料我也設置為表示坐標的點而不是圖片。
當然,這個 fuzzer 跑起來巨慢!這是因為我們每次生成時都需要先生成一張二維碼,變異,然后編碼成 PNG 圖片,再再將圖片輸入給目標進行解析。
解決方案可以通過 C++ 直接去生成二維碼,然后將二維碼直接轉成 cv::Mat 去作為輸入。這樣一方面可以節省掉 PNG 編解碼的過程,另一方面也可以擺脫 Python 的依賴。QR-Code-generator 也許是一個不錯的方案。不過考慮到之前畫蛇添足的失敗嘗試,能帶來多少速度的提升也不甚確定。
另外當前覆蓋率反饋的變異其實是有限的(如果有的話),從文檔中來看,LibFuzzer 對于自定義變異的支持可能會更完善一些。而且 LibFuzzer 可以天然支持多核,不用像 AFL 要自己手打一堆 slave。
Anyway,最終運行結果:
$ afl-whatsup -s output/
/usr/local/bin/afl-whatsup status check tool for afl-fuzz by Michal Zalewski
Summary stats
=============
Fuzzers alive : 17
Total run time : 32 days, 13 hours
Total execs : 8 millions, 198 thousands
Cumulative speed : 36 execs/sec
Average speed : 2 execs/sec
Pending items : 567 faves, 22476 total
Pending per fuzzer : 33 faves, 1322 total (on average)
Crashes saved : 0
Hangs saved : 0
Cycles without finds : 0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0/0
Time without finds : 35 seconds
好吧,雖然 OpenCV "非常安全",但是二維碼解析庫又不止這一個!于是又找了另外一個常用的解析庫 ZXing 去進行測試,事實證明還是可以找出問題的!
總結
本文可以看做是一個典型的 Fuzzing 漏洞挖掘心路歷程。即先用 Generic Fuzzer 跑起來,然后通過不斷深入理解代碼,改良變異策略,最終變成 Structure Aware Fuzzing 的結果!雖然 AFL 一把梭能讓機器為自己打工很爽,但是想得到更好的結果還是免不了動手優化。而不看代碼的話可能即便找到問題也無法理解成因,輕則無法編寫利用導致 award-0,重則提交錯誤的 patch 導致后續被其他開發者 revert 并批判一番釘在歷史的恥辱柱上。因此,自動化測試和代碼審計相結合往往才能達到更加有效的漏洞挖掘效果。
參考鏈接
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/2079/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/2079/