
作者:wh1t3Pig
原文鏈接:《基于代碼屬性圖的自動化漏洞挖掘實踐》
0 前言
應用程序分析技術挖掘應用漏洞一直以來都是學術界和工業界的研究重點之一。從最初的正則匹配到最近的代碼屬性圖挖掘方案,國內外有很多來自不同階段的安全工具或商業產品來發掘程序代碼的安全問題。在 Java 語言方面,業界已經有了不少出色的產品,如 CodeQL 等,但是,多數產品考慮的角度是從甲方視角或開源視角出發的,也就是產品的輸入大部分是以源碼為主。然而,我們安全研究人員更多面對地是編譯后的項目,比如編譯后的 WAR、第三方依賴 JAR 等形式。對于此類形式目標的漏洞挖掘,當前存在的審計產品或多或少都有一些限制,比如最近幾年很火的 CodeQL 就無法直接處理此類形式的目標代碼。當前,安全研究人員大多以人工或一些輔助工具來完成此類形式項目的漏洞挖掘。很明顯,這種方式審計效率是非常低的,而且,審計結果也很容易遺漏。為此,需要一款能解決此類問題的工具。
1 方案介紹
為了更好地輔助安全研究人員進行漏洞挖掘,我設計了基于代碼屬性圖的自動化漏洞挖掘方案,并開發了 tabby 項目用于解決此類問題,旨在更簡單更全面地挖掘更多的安全問題。方案通過整合代碼語義信息和圖數據庫相關技術,使得單一項目(編譯后的目標文件)分析后可多次重復分析,而無需重復進行繁重的程序語義分析。這種方式帶來了分析成本上的優勢。并且圖數據庫自身所擅長的路徑檢索能力也能充分發揮在漏洞調用鏈路的挖掘上。
方案將傳統的程序分析流程拆分成了兩個階段,包括代碼屬性圖生成階段和漏洞發現階段。由代碼屬性圖生成階段生成的帶污點信息的代碼屬性圖將作為漏洞發現階段的基礎,用于動態查詢分析具體漏洞細節。 從開發實現上看,主要為 tabby 核心項目和用于跟蹤數據流的 neo4j 擴展 tabby path finder,如下圖所示: 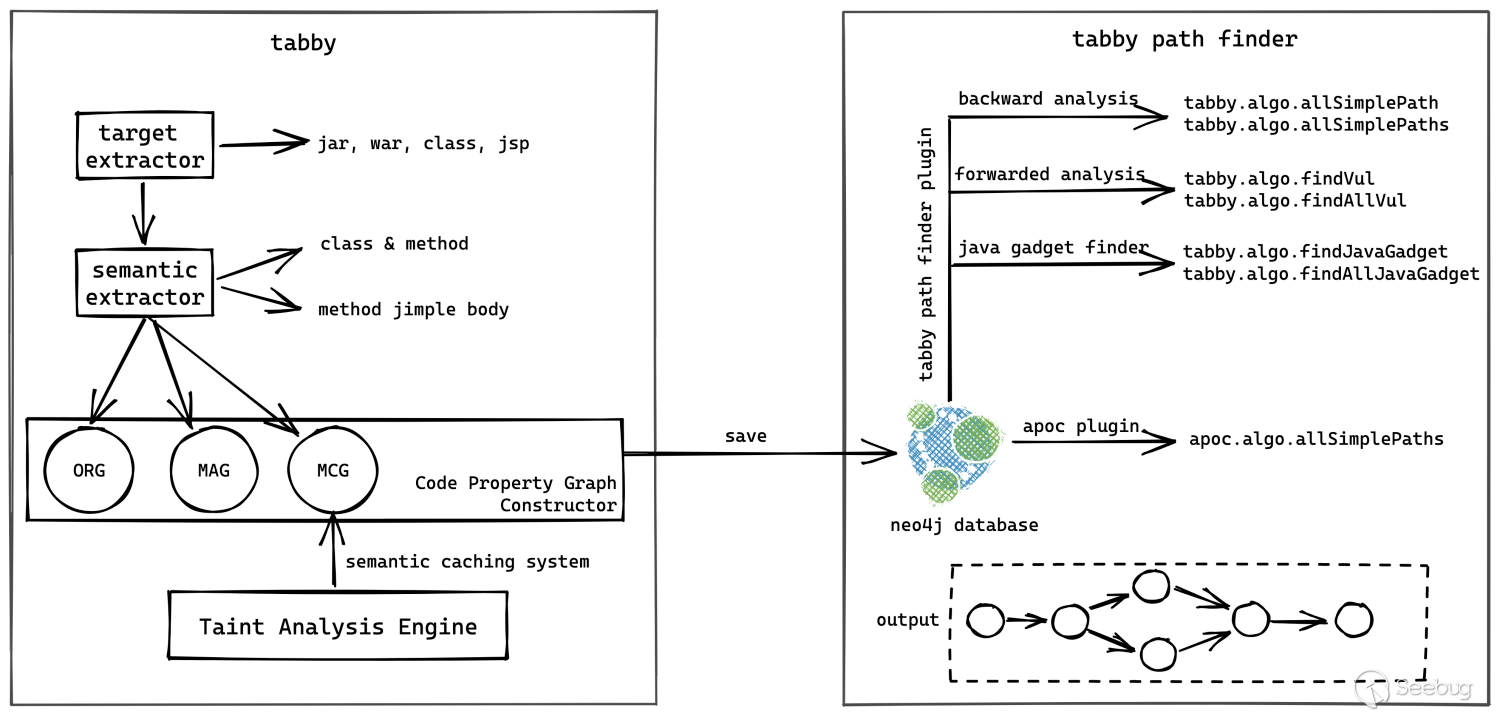
接下來,將詳細介紹我們是怎么設計和實現這個方案的。
1. 針對面向對象語言的代碼屬性圖實現方案
首先,最基礎的是如何設計一個能在圖數據庫中直接進行代碼分析的圖結構。為此,我們調研了一些學術界的代碼屬性圖實現方案,如下幾篇重要的論文
[1] Martin M, Livshits B, Lam M S. Finding application errors and security flaws using PQL: a program query language[J]. Acm Sigplan Notices, 2005, 40(10): 365-383.
[2] Yamaguchi F, Golde N, Arp D, et al. Modeling and discovering vulnerabilities with code property graphs[C]//2014 IEEE Symposium on Security and Privacy. IEEE, 2014: 590-604.
[3] Backes M, Rieck K, Skoruppa M, et al. Efficient and flexible discovery of php application vulnerabilities[C]//2017 IEEE european symposium on security and privacy (EuroS&P). IEEE, 2017: 334-349.上面三篇論文在代碼屬性圖的設計上做了一些嘗試,但是他們主要針對的對象是面向過程語言,這其中不涉及解決一些面向對象語言的特性,比如多態特性。舉個實際例子
interface IFace {
void test();
}
class A implements IFace {
public void test(){}
}
class B implements IFace {
public void test(){}
}
class Main {
public static void test(IFace iFace){
iFace.test();
}
public static void main(String[] args) {
IFace a = new A();
test(a);
IFace b = new B();
test(b);
}
}如果采用論文中所設計的代碼屬性圖,簡化分析 Main#test 函數,我們可以得到這樣一個指向關系
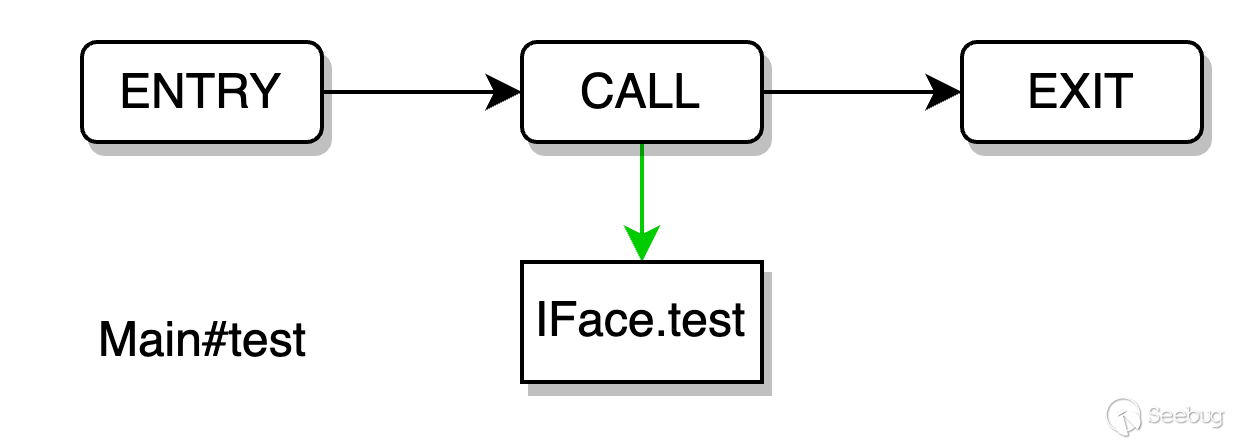
在面向過程語言中,這樣分析是沒有問題的,因為 IFace 對象的指向是固定的,而在面向對象語言中,由于 IFace 是一個接口 interface 類型,它實際的代碼實現是空的,我們需要找到對應的具體實現該接口的對象才能進行相應分析。比如上述的代碼表示,我們需要從分析過程中,推算出當前執行的 iFace.test() 可能是 A.test 或 B.test。很明顯,此類代碼屬性圖是不符合分析面向對象語言的。 此外,上述論文中的代碼屬性圖都保留了 AST、CFG,但是,實際上如果當前函數內容和分析算法均不發生改變,不管是第一次分析也好,還是第 n 次分析也好,其分析結果是固定的,那么保留 AST、CFG 結構除了更好的展示代碼結構外,并沒有起到多大的用處。當然,假設分析算法也同時開放給用戶的情況另算。 為了能契合面向對象語言,我們重新設計了面向對象語言的代碼屬性圖實現方案。我們的方案摒棄了多余的數據結構(AST、CFG),新增了針對面向對象語言的特殊數據結構。
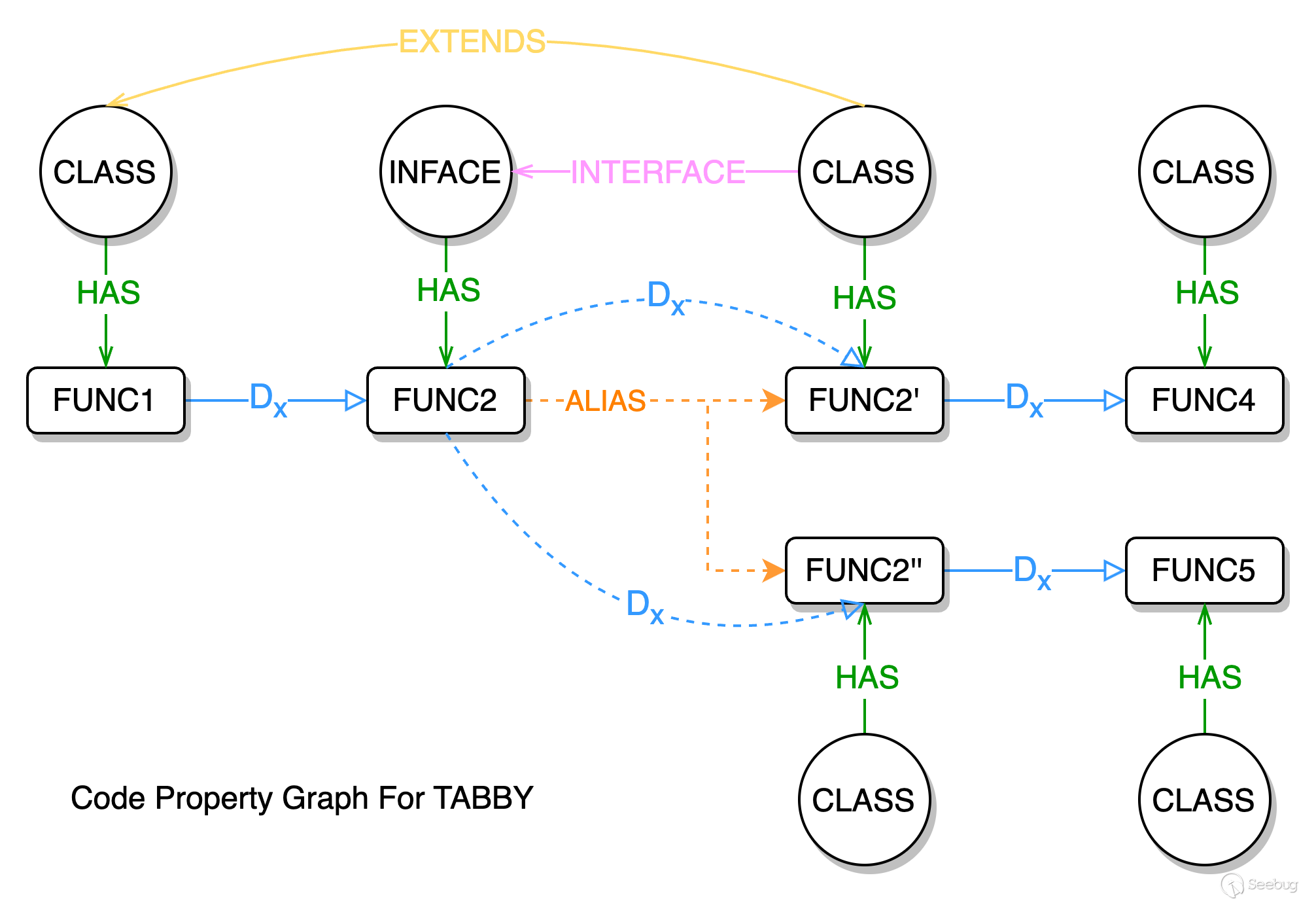
該代碼屬性圖實現方案由類關系圖 ORG、函數別名圖 MAG、函數調用圖 MCG 3 種子圖組合而成。圖中共有 Class 和 Method 兩種實體節點,5 種關系邊,下文將詳細敘述這三種子圖構成及作用。
類關系圖 Object Relation Graph
類關系圖用于描述對象自身的相關語義信息和對象之間的語義關系,共三種關系
- 類與函數之間的歸屬關系 HAS 邊
- 類與接口之間的實現關系 INTERFACE 邊
- 類與類之間的繼承關系 EXTENDS 邊
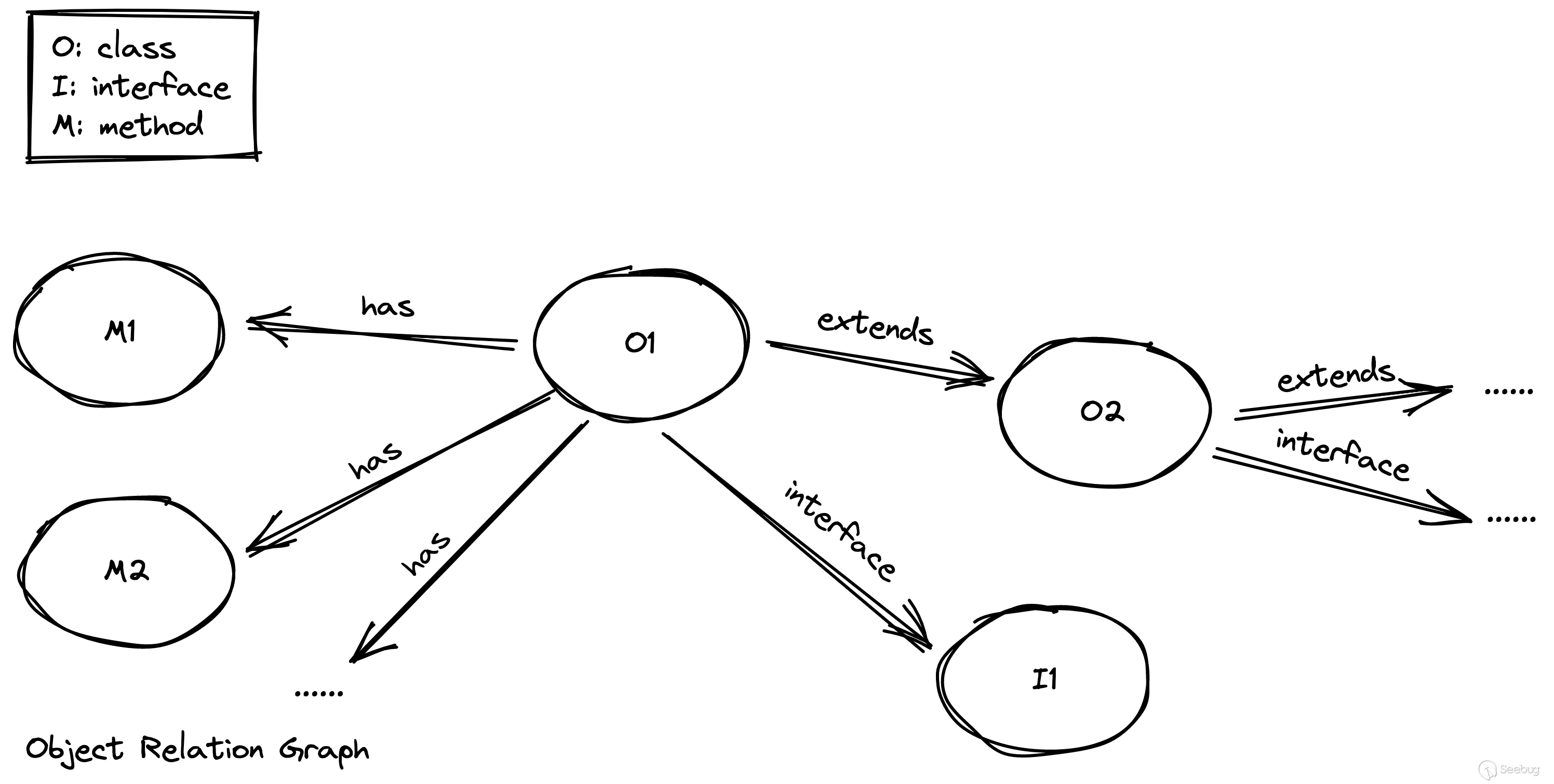
通過串聯類與類、類與函數之間的關系邊,我們可以得到一顆顆獨立對象函數繼承樹。 利用 Neo4j 的查詢語法,我們可以動態查詢符合條件的類和函數。
函數別名圖 Method Alias Graph
在前文中,提到了三篇論文設計的代碼屬性圖沒有考慮面向對象語言,導致在圖中函數調用之間是相互割裂的。還是用上文提到的這個例子,我們沒有辦法在圖數據庫中直接找到一個從 Main#test 函數到 A#test 或 B#test 的一條通路,也就意味著我們不能通過類似 Neo4j 的查詢語法來直接完成函數調用鏈路的輸出。這顯然是不符合我們的實際需求的,為此,我們設計了函數別名圖來解決這個問題。 函數別名圖描述了某一函數所有具體實現的語義圖,主要用于面向對象語言多態特性在圖數據庫中的表達。該圖由描述函數與函數之間的別名關系 ALIAS 邊連接而成,類似 ORG 圖,函數別名圖也會產生一顆顆獨立的函數樹,樹頂為 interface 或頂層類型,樹枝為當前樹頂函數的具體實現。

以上文中的代碼為例,通過 MAG 圖,我們可以找到一條從 Main#main 到 A#test 或 B#test 的函數調用通路。有了通路之后,我們就可以通過 Neo4j 的查詢語法來查詢此類函數調用路徑。而且,MAG 圖可以使得程序分析過程中的函數枚舉實現下方到圖數據庫中進行,在一定程度上,可以緩解程序分析過程中的路徑爆炸問題,詳見 ppt 12。
函數調用圖 Method Call Graph
函數調用圖主要用于描述函數與函數之間的調用關系圖,利用該有向的調用關系可以查詢出一條有效的函數調用路徑。同時,我們也保留了 PDG 圖,在 CALL 邊上保留了污點信息用于后續的過程間數據流分析。更近一步的是,通過污點分析,我們可以保留受污染的調用邊,減少后續圖數據庫中無用邊的枚舉遞歸查找。

通過組合上述三個子圖,我們最終可以達到 2 個效果 1. 直接利用 Neo4j 的查詢語法即可完成有效路徑枚舉工作 2. 可以將“有效”路徑的判別下放到圖數據庫中完成(即過程間數據流分析)
2. 結合圖數據庫的污點分析引擎
接下來,我們來看看如何在圖數據庫中來判定“有效”路徑 為了能更好的結合圖數據庫的技術優勢,我們重新編排了程序分析的整體流程,簡單來看,將其分為化整為零和化零為整兩個部分。 化整為零部分著重于生成 PDG(program data graph),使得每一條函數調用邊上都有入參等變量的污點信息。 化零為整部分著重于利用 PDG 和圖數據庫的路徑檢索能力,重建函數調用鏈路。重建過程以污點信息動態推算,邊剪枝無效調用邊重建鏈路,在一定程度上緩解了路徑爆炸問題。
化整為零
化整為零部分涉及了單函數過程內分析算法和跨函數過程間分析算法。 單函數過程內分析算法的實現以靜態分析框架 SOOT 作為基礎,在 SOOT 轉化的 Jimple 語法中進行相應的指針分析。此處,依據 Java 的語法規則,我們可以總結出 12 種污點流轉規則

關于過程內分析細節,在 ppt 15 中,給了一個動態的分析案例,在此就不在累述了。
我們重點來看一下過程間分析算法。在程序分析技術的發展過程中,有很多用于加快分析速度的方法。我們采用了基于摘要的過程間分析算法,也就是每分析完一個函數內容后生成相應的語義緩存,該緩存可用于描述經過調用該函數后函數調用者、函數入參、函數返回值的相關語義信息。利用緩存信息可一定程度上避免程序分析過程中的重復計算問題。
我們站在前人的肩膀上設計了 tabby 的語義緩存系統。從 Java 語法的角度,我們可以知道函數運行完可能會對函數調用者和函數入參變量產生影響。為此,我們需要在函數運行完最后的語句后,整理出當前函數調用者和函數入參所發生的變化。同時,如果當前函數有返回值,還需要記錄該返回值同函數調用者以及函數入參之間的關系,使得污點能通過返回值進一步傳遞。有了這些信息后,我們主要關注點可以放在函數調用者、函數入參列表以及函數返回值上,將所發生的語義變化抽象成一語義摘要供后續函數調用分析使用。
以下圖代碼為例,我們來看一下 tabby 的語義緩存系統實現

人工分析 swap 函數后,我們可以知道 arg0 和 arg1 進行了交換,返回值同 arg0 相關。 那么,我們需要用一定的規則來形成語義緩存結構。 1. 定義污點實體表示 由于污點關系逃不出函數調用者、函數入參和函數返回值,所以我們在關鍵字上只需要定義 3 種:this、param-n、return,其中 param-n n 為 0~n 范圍內的自然數,數字指代入參位置信息。 2. 定義污點實體特殊表示 除了對變量本身的表示,我們還需要考慮變量屬性、變量數組等特殊表示,用 <f> 指代類屬性;用 <a> 指代變量數組;<s> 指代僅清除并繼承右值污點信息但不改變變量指向關系;<m> 指代不清除原有污點信息,同時繼承右值污點信息,但不改變變量指向關系。 舉幾個實際例子,this<f>name : param-0 表示應處理當前函數調用者的類屬性 name 為第一個函數入參的內容;this<a> : param-0 表示當前函數調用者為數組類型,需將第一個函數入參放入函數調用者的數組種。 利用上面兩個定義,我們可以將當前 swap 函數的語義緩存信息總結為
actions {
"param-0" : ["param-1"],
"param-1" : ["param-0"],
"return" : ["param-0"]
}有了這樣一個語義緩存結構之后,我們需要將這一緩存信息應用到調用函數的分析中,也就是例子中 b 函數的分析。 語義緩存的利用可以分為 3 個步驟 1. 初始化并復制所有涉及的變量信息,包括函數調用者、函數入參變量列表 2. 根據語義緩存做污點賦值操作 3. 清楚臨時變量 以上述 b 函數的分析為例,可以將其應用過程轉換為下表的流程
 此外,除了形成函數本身的語義摘要信息外,我們還需要同時生成邊上的污點數據緩存,也就是 PDG 的生成。這部分主要標識當前函數調用的各個變量同當前函數的函數調用者、函數入參之間的聯系,以一整型數組表示。 數組位置信息指代當前調用變量的位置信息,數組數值信息指代當前位置上的變量的污點信息。 數值信息規則如下表所示
此外,除了形成函數本身的語義摘要信息外,我們還需要同時生成邊上的污點數據緩存,也就是 PDG 的生成。這部分主要標識當前函數調用的各個變量同當前函數的函數調用者、函數入參之間的聯系,以一整型數組表示。 數組位置信息指代當前調用變量的位置信息,數組數值信息指代當前位置上的變量的污點信息。 數值信息規則如下表所示

以 b 函數調用 swap 為例,假設變量 a0 來源于參數 0,那么 A a2 = swap(a0, a1); 轉化的污點數組為 [-1,0, -3],這里 swap 的調用者為隱含變量,即 this 為函數調用者。
做個小結,化整為零部分主要內容為污點分析,并生成語義緩存。函數本身的語義緩存主要用于分析過程中緩解重復計算的問題;調用邊上的語義緩存用于后續化零為整的動態數據流分析,即 PDG
化零為整
有了相關的語義緩存信息之后,我們就可以通過編寫 neo4j 的擴展來實現動態自定義的污點數據流分析,來看一個實際的例子 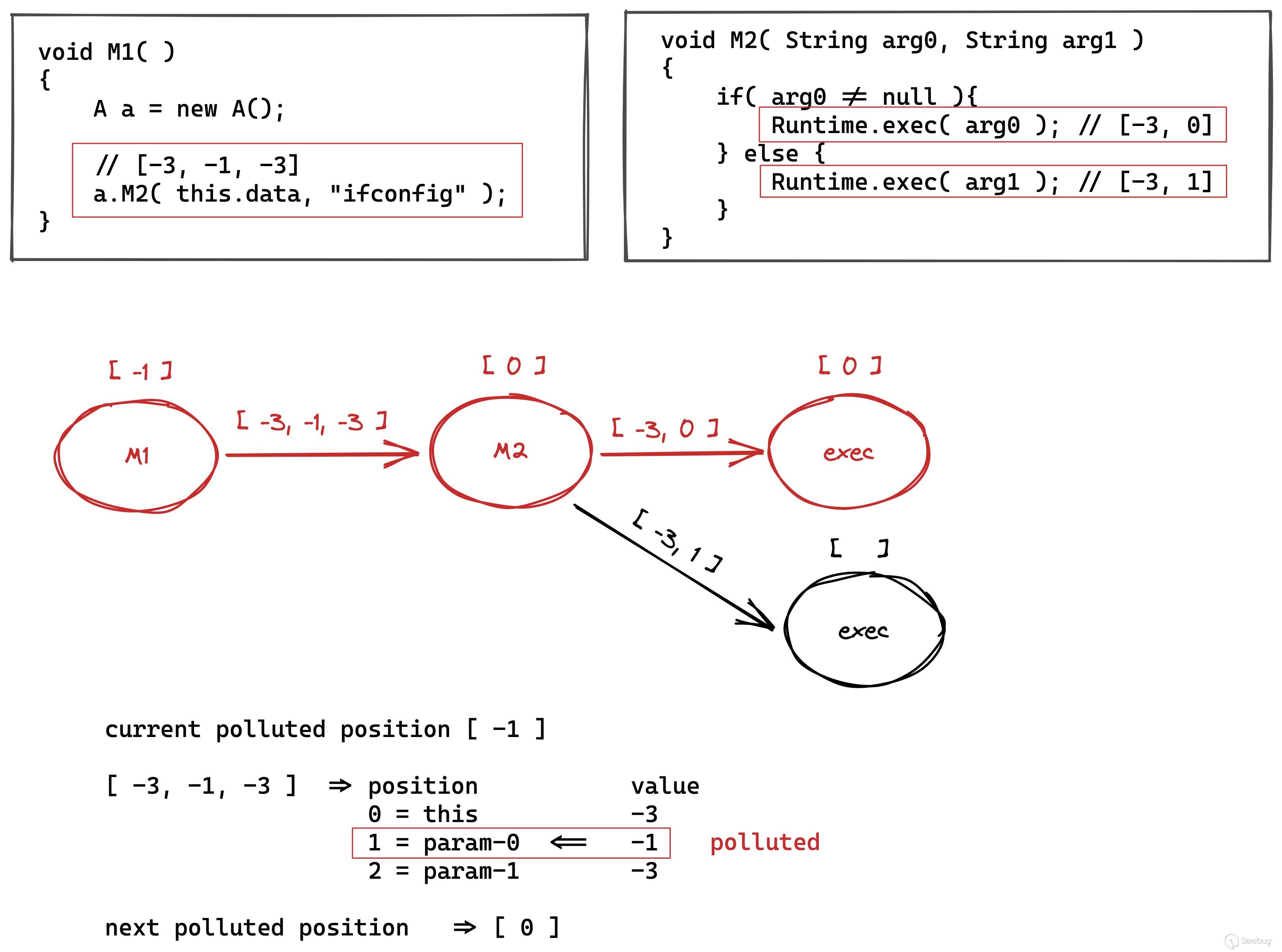 首先,人工分析一下 M1 函數和 M2 函數,可以知道的是 M2 函數存在危險函數
首先,人工分析一下 M1 函數和 M2 函數,可以知道的是 M2 函數存在危險函數 Runtime.exec,并且一個來自于參數 0,一個來源于參數 1。回溯到 M1 的代碼中,我們可以知道傳入 M2 的參數 0 為受污染的變量,參數 1 為固定字符串,不受污染。那么,經過人工分析,實際可以得到上面標紅的函數調用路徑是存在漏洞的。那么,從污點數組中進行推算該如何進行呢? 以 M1-[-3,-1,-3]->M2 這個節點為例 1. M1 函數有基礎的污點信息 [-1],指代當前跟函數調用者本身有關的都是受污染的 2. a.M2(this.data, "ifconfig") 的邊上污點信息為 [-3,-1,-3] 3. 利用 1 和 2 的兩個數組,推得 M2 的基礎污點信息為 [0],表示傳入到 M2 函數的跟入參 0 相關的變量都是受污染的 依次類推,可以得出第一個 exec 函數的基礎污點信息為 [0],表示當前調用 exec 函數的第一個參數是可控的。我們都知道如果 exec 函數的第一個參數是可控的話,當前函數調用鏈路就是有問題的,可以導致任意命令注入。 而第二個 exec 函數的調用,在邊信息 [-3,1] 中找不到 M2 的 [0],則得不出當前 exec 的基礎污點信息,所以當前的調用路徑是不存在命令注入安全問題的。
通過上述例子的推算過程,我們可以編寫 neo4j 的污點推算擴展,通過該擴展,我們可以直接通過自定義函數在圖數據庫上進行動態的污點數據流分析,挖掘存在安全問題的函數調用鏈路。
最終,通過這兩個階段的組合,我們可以直接通過 neo4j 的查詢語法來進行漏洞挖掘。
2 漏洞挖掘案例
截止目前,我們已經使用 tabby 挖掘到了 60+ 0day 漏洞和 8 個 CVE。本節將分享一個實際的 web 漏洞挖掘案例,其余案例可以直接看文末的 ppt。
首先,tabby 對常見的 web 端點進行了識別,可以直接用 IS_ENDPOINT 屬性來表示 source 函數。此處的例子比較特殊,我們需要對框架的特殊 source 進行 neo4j 語句上的描述
match (source:Method {NAME:"doAction"})<-[:HAS]-(c:Class)-[:INTERFACE|EXTENDS*]->(c1:Class {NAME:"nc.bs.framework.adaptor.IHttpServletAdaptor"})描述當前 source 的函數名為 doAction,且當前 source 的歸屬類實現了 IHttpServletAdaptor 接口
其次,tabby 內置了一些常見的 sink 函數,使用 VUL 屬性來區分
match (sink:Method {IS_SINK: true, VUL: "FILE_WRITE"})描述查找文件上傳相關的危險函數
最后,我們利用 tabby path finder 提供的具備污點分析的擴展函數進行漏洞利用鏈挖掘
call tabby.algo.findAllVul(sources, sinks, 8, false) yield path
return path limit 1通過組合上述查詢語句,最終可以查詢出一條有效的存在漏洞的函數調用鏈路。
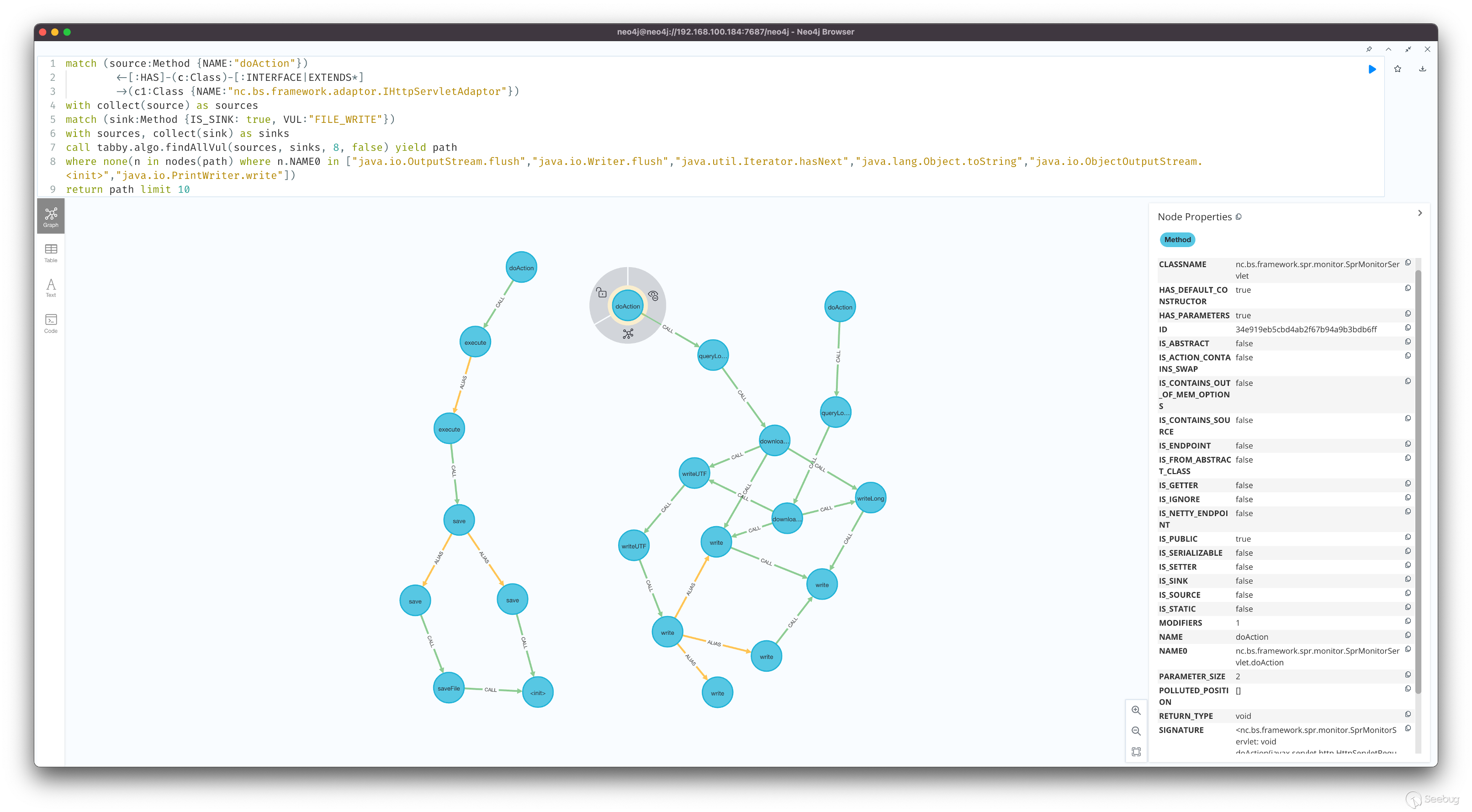
上述例子是利用 tabby 最簡單的一種應用方式,還有更多的使用方法等著你來探索 XD
3 總結
隨著技術的發展,程序分析技術和圖數據庫的結合在自動化漏洞挖掘的應用上變成了一種趨勢。最近幾年很火的 CodeQL 也是基于這種思路開發的。本文所提及的實踐僅為一種粗淺的嘗試,主要介紹了 tabby 的兩個重要部分的設計和實現思路。歡迎有興趣的同學來一起交流和實踐 XD
另外,此文的另一個目的是作為 KCON 2022 議題 《 tabby: java code review like a pro 》 的一個補充,從文章的方式解釋了 ppt 中不太清晰的點。如果你還有其他的疑問,非常歡迎私我交流 XD
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/2041/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/2041/