
作者:Alfy@墨云科技VLab Team
原文鏈接:https://mp.weixin.qq.com/s/MtFZc1Zv6uNo25ORNijpaQ
什么是web登錄入口
目前,大多數Web站點都具備身份驗證的功能,防止非授權訪問。web站點中每個賬戶都有特定的操作權限,如果非授權用戶能夠通過非常規的方式(如弱口令爆破、竊取他人的用戶名口令等)登錄他人賬戶,則可能造成站點用戶信息泄露、站點系統被控制等嚴重后果。
當用戶訪問相關頁面時,系統會要求其輸入用戶名、口令等相關信息進行驗證,驗證通過才允許后續網頁訪問。網頁中進行身份驗證的輸入點統稱為登錄入口;登錄入口中不同的輸入類型如username、password、captcha和login按鈕等,分別稱為登錄實體。因而,登錄入口是一種重要的攻擊面。此外,web站點的管理后臺的登錄入口具有更高的價值,一旦被攻擊者非法登錄成功,會暴露出更多的攻擊面(例如系統配置等)。
為了提升Web網站的安全防護能力,消除web登錄入口中存在的風險是重要的一環。其中,通過自動化的識別網站登錄入口,并進行弱口令檢測,是最為有效的web登錄入口風險檢測手段。墨云科技的Vackbot智能滲透機器人在此方面取得了突破。

登錄入口識別方法
1.識別方法概述
傳統識別方法基于規則的方法,誤報和漏報的問題比較突出,規則一旦形成,除非人為更改,否則長期處于停滯狀態,靈活性較差。傳統建模方法只考慮了部分上下文信息,缺乏對登錄入口整體信息的認識。
不同于基于規則和基于傳統建模登錄入口識別的方法,圖神經網絡建模在對每個節點表征時不僅參考自身節點信息同時考慮了鄰居節點信息,更加充分利用網頁結構信息來決策不同網頁標簽所屬的登錄實體類別。圖神經網絡是一種特征提取器,它對相關數據信息構造一個圖結構,生成節點的特征時它不僅參考自身節點信息同時考慮了鄰居節點信息,它能夠充分利用網頁標簽之間結構信息,從而提升相關登錄實體識別效果。
2.我們的方法
為了有效的自動識別登錄入口,我們提出了基于GCN模型為主,傳統規則為輔的登錄入口識別方法。首先,對網頁DOM TREE的前序遍歷過濾掉不屬于登錄實體的網頁標簽,同時,根據網頁標簽類型和屬性值包含的關鍵詞分別識別不同的候選網頁標簽,不同網頁標簽構造一個全連接圖,基于網頁標簽圖進行網頁標簽建模學習。

如何基于圖卷積神經網絡建模
基于圖神經網絡建模首先需要把網頁數據轉為一個具體的圖數據,具體處理流程包括網頁數據去噪、節點特征構建、分類建模。
1.網頁數據去噪
網頁DOM TREE中包含了大量的網頁標簽,這些網頁標簽中與登錄入口相關的網頁標簽非常有限,并且登錄入口相關的網頁標簽一般都相對集中在一顆網頁子樹中,基于規則的方法通過網頁標簽類型、網頁屬性關鍵詞、網頁標簽相鄰信息可以有效過濾掉大量的非登錄的網頁標簽。在登錄入口識別的具體實現中,為了方便使用鄰居網頁標簽信息,使用了dom tree的后序遍歷對不相關的網頁標簽過濾,獲取候選的登錄入口相關的網頁標簽集合。
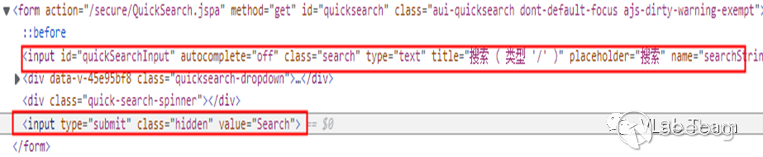
2.特征設計
2.1 節點特征設計
網頁標簽屬性值對判斷一個網頁標簽所屬的實體類別很重要,這里使用TFIDF算法計算登錄實體與關鍵詞的相關性。它由TF(詞頻)和DF(文檔頻率)組成。TF表示關鍵詞在網頁中出現的頻次,TF值越大則關鍵詞對網頁標簽的代表性越強,DF代表關鍵詞在所有網頁標簽中出現的頻次,DF越大關鍵詞對網頁標簽的區分性越小。為了方便結合兩部分引入了逆向文件頻率 (IDF) ,它可以由所有關鍵詞個數除以包含該關鍵詞的數目,再取對數得到。具體實現如下所示:
● 對所有的網頁標簽屬性值分詞計算詞語的IDF值;
● 針對每一個網頁標簽計算詞語的TF值,由TF和IDF計算得到所有詞語的TFIDF值;
● 計算TFIDF值選擇值最大的若干個關鍵詞作為登錄入口識別任務特征詞。
以下是根據TFIDF方法對大規模語料對所有的詞語統計排序,選擇與不同實體類型強相關的詞語的相關關系如下表所示:
| 實體類型 | 部分關鍵詞列表 |
|---|---|
| username | ['user', '用戶名', 'account', '帳號', '郵箱', '身份證','email'] |
| password | ['pwd', '密碼', 'password','pin','密鑰'] |
| captcha | ['captcha', '驗證碼', 'valid','更換', 'yzm','verify', 'secret', 'code'] |
| login | ['login', '登錄', '登入', '登陸', 'submit', '確認','進入系統'] |
2.2 邊權重設計
網頁內登錄實體相關的網頁標簽一般相對集中,距離較近的網頁標簽的相關性也較強,因此,我們基于網頁Dom TREE計算候選網頁標簽之間的距離distance,構建網頁標簽節點之間的邊權重similarity,其計算公式如下所示,其中path length為網頁標簽在Dom tree中深度。
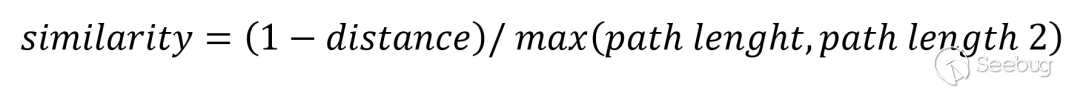
3. GCN建模
在登錄入口識別任務中使用了GCN模型提取特征,它是一種采用圖卷積的神經網絡,可以同時基于自身節點信息與鄰居節點信息學習每個節點的表征,極大程度提升了登錄實體識別的準確性。
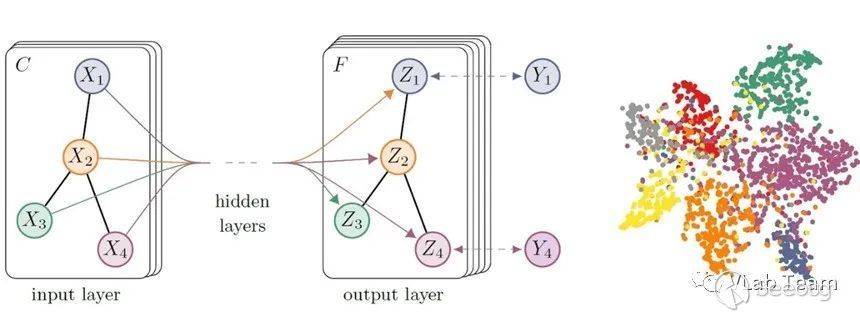
像其他深度學習結構一樣,GCN也是一種特征提取器,生成節點的特征時它不僅參考自身節點信息同時考慮了鄰居節點信息。對于第L+1層的節點特征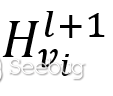 ,其模型公式如下所示:
,其模型公式如下所示:
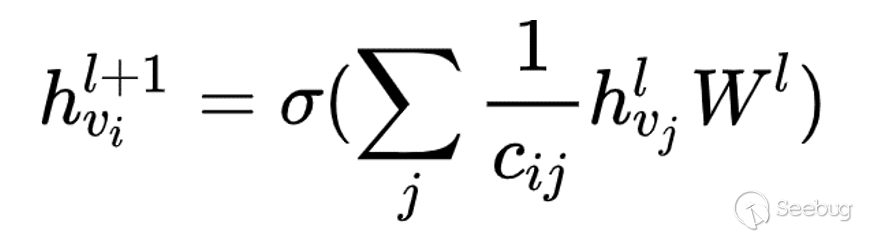
其中是節點的鄰居節點,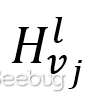 是節點在第l層的節點特征,
是節點在第l層的節點特征,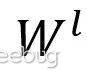 是模型要學習的參數,
是模型要學習的參數,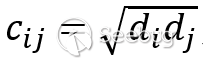 為歸一化的系數,
為歸一化的系數,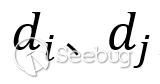 為節點和節點的度。歸一化就是除以節點的度,這樣每個節點信息傳遞時就被規范化了,不會因為節點的度大,它對相鄰的所有節點都分配很大的影響力。同時為了在更新節點特征時考慮到節點自己的信息,一般把節點自己加入鄰居節點集合。通過gcn模型提取節點的特征后使用soft max分類器對網頁標簽分類,從而基于網頁標簽類別識別登錄入口相關信息。
為節點和節點的度。歸一化就是除以節點的度,這樣每個節點信息傳遞時就被規范化了,不會因為節點的度大,它對相鄰的所有節點都分配很大的影響力。同時為了在更新節點特征時考慮到節點自己的信息,一般把節點自己加入鄰居節點集合。通過gcn模型提取節點的特征后使用soft max分類器對網頁標簽分類,從而基于網頁標簽類別識別登錄入口相關信息。
實驗結果
測試數據集從網上隨機找了1777個包含登錄入口的網頁數據,當網頁內所有登入實體全部識別正確則視為識別正確,評估指標acc為0.98。同時基于相同測試集,我們增加了對比實驗,其中基于規則的方法是根據網頁標簽類型和屬性值包含的關鍵詞分別識別不同的登錄實體;基于條件隨機場(CRF)的方法,首先,過濾掉不是登錄實體的網頁標簽,然后對候選網頁標簽序列使用CRF建模。每種方案的測試結果如下表所示:
| 不同方法登錄入口識別效果 | 基于規則的方法 | 基于條件隨機場(CRF)的方法 | 基于圖卷積神經網絡(GCN)的方法 |
|---|---|---|---|
| Acc | 0.65 | 0.88 | 0.98 |
總結
隨著網絡安全行業日新月異的發展,人工智能技術作為一種交叉學科技術,需要被網絡安全行業從業者良好的使用,以提升現有網絡安全技術的能力。同時,人工智能技術面臨著數據標簽及質量,模型可解釋性,模型遷移能力等各方面的挑戰,網絡安全從業者應正確的認識人工智能技術所帶來的效益及其本身的局限性,挖掘人工智能與網絡安全的落地應用結合點,切忌對人工智能盲目認知,實現兩者的有效融合發展。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1969/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1969/
暫無評論