
作者:leveryd
原文鏈接:https://mp.weixin.qq.com/s/hvb_Kr6DqAPPfnN-lbx1aA
背景
假設機器A和機器B在同一個局域網,機器A使用nc -l 127.0.0.1 8888,在機器B上可以訪問機器A上"僅綁定在127.0.0.1的服務"嗎?
[root@instance-h9w7mlyv ~]# nc -l 127.0.0.1 8888 &
[1] 44283
[root@instance-h9w7mlyv ~]# netstat -antp|grep 8888
tcp 0 0 127.0.0.1:8888 0.0.0.0:* LISTEN 44283/ncnc用法可能不同,有的使用 nc -l 127.0.0.1 -p 8888 監聽8888端口
kubernetes的kube-proxy組件之前披露過CVE-2020-8558漏洞,這個漏洞就可以讓"容器內的惡意用戶、同一局域網其他機器"訪問到node節點上"僅綁定在127.0.0.1的服務"。這樣有可能訪問到監聽在本地的"kubernetes無需認證的apiserver",進而控制集群。
本文會帶你做兩種網絡環境(vpc和docker網橋模式)下的漏洞原理分析,并復現漏洞。
漏洞分析
怎么復現?
terraform可以基于聲明式api編排云上的基礎設施(虛擬機、網絡等)
你也可以按照文章后面的步驟來復現漏洞。
為什么可以訪問其他節點的"僅綁定在127.0.0.1的服務"?
假設實驗環境是,一個局域網內有兩個節點A和B、交換機,ip地址分別是ip_a和ip_b,mac地址分別是mac_a和mac_b。
來看看A機器訪問B機器時的一個攻擊場景。
如果在tcp握手時,A機器構造一個"惡意的syn包",數據包信息是:
| 源ip | 源mac | 目的ip | 目的mac | 目的端口 | 源端口 |
|---|---|---|---|---|---|
| ip_a | mac_a | 127.0.0.1 | mac_b | 8888 | 44444(某個隨機端口) |
此時如果交換機只是根據mac地址做數據轉發,它就將syn包發送給B。
syn包的數據流向是:A -> 交換機 -> B
B機器網卡在接收到syn包后:
鏈路層:發現目的mac是自己,于是扔給網絡層處理
網絡層:發現ip是本機網卡ip,看來要給傳輸層處理,而不是轉發
* 傳輸層:發現當前"網絡命名空間"確實有服務監聽 127.0.0.1:8888, 和 "目的ip:目的端口" 可以匹配上,于是準備回復syn-ack包
從"內核協議棧"角度看,發送包會經過"傳輸層、網絡層、鏈路層、設備驅動",接受包剛好相反,會經過"設備驅動、鏈路層、網絡層、傳輸層"
syn-ack數據包信息是:
| 源ip | 源mac | 目的ip | 目的mac | 目的端口 | 源端口 |
|---|---|---|---|---|---|
| 127.0.0.1 | mac_b | ip_a | mac_a | 44444(某個隨機端口) | 8888 |
syn-ack包的數據流向是:B -> 交換機 -> A
A機器網卡在收到syn-ack包后,也會走一遍"內核協議棧"的流程,然后發送ack包,完成tcp握手。
這樣A就能訪問到B機器上"僅綁定在127.0.0.1的服務"。所以,在局域網內,惡意節點"似乎"很容易就能訪問到其他節點的"僅綁定在127.0.0.1的服務"。
但實際上,A訪問到B機器上"僅綁定在127.0.0.1的服務"會因為兩大類原因失敗: 交換機有做檢查,比如它不允許數據包的目的ip地址是127.0.0.1,這樣第一個syn包就不會轉發給B,tcp握手會失敗。公有云廠商的交換機(比如ovs)應該就有類似檢查,所以我在某個公有云廠商vpc網絡環境下測試,無法成功復現漏洞。 數據包到了主機,但是因為ip是127.0.0.1,很特殊,所以"內核協議棧"為了安全把包丟掉了。
所以不能在云vpc環境下實驗,于是我選擇了復現"容器訪問宿主機上的僅綁定在127.0.0.1的服務"。
先來看一下,"內核協議棧"為了防止惡意訪問"僅綁定在127.0.0.1的服務"都做了哪些限制。
"內核協議棧"做了哪些限制?
先說結論,下面三個內核參數都會影響 route_localnet rp_filter * accept_local
以docker網橋模式為例,想要在docker容器中訪問到宿主機的"僅綁定在127.0.0.1的服務",就需要: 宿主機上 route_localnet=1 docker容器中 rp_filter=0、accept_local=1、route_localnet=1
宿主機網絡命名空間中
[root@instance-h9w7mlyv ~]# sysctl -a|grep route_localnet
net.ipv4.conf.all.route_localnet = 1
net.ipv4.conf.default.route_localnet = 1
...容器網絡命名空間中
[root@instance-h9w7mlyv ~]# sysctl -a|grep accept_local
net.ipv4.conf.all.accept_local = 1
net.ipv4.conf.default.accept_local = 1
net.ipv4.conf.eth0.accept_local = 1
[root@instance-h9w7mlyv ~]# sysctl -a|grep '\.rp_filter'
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.eth0.rp_filter = 0
...容器中和宿主機中因為是不同的網絡命名空間,所以關于網絡的內核參數是隔離的,并一定相同。
route_localnet配置
是什么?
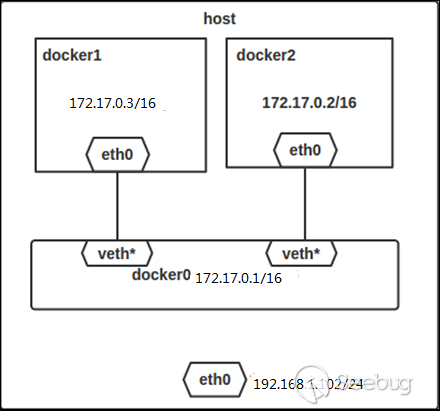
宿主機上curl 127.0.0.1時,源ip和目的都是127.0.0.1,此時網絡能正常通信,說明數據包并沒有被丟棄。說明這種情景下,沒有調用到 ip_route_input_noref 函數查找路由表。 CVE-2020-8558漏洞中,kube-proxy設置route_localnet=1,導致關閉了上面所說的檢查。 https://elixir.bootlin.com/linux/v4.18/source/net/ipv4/route.c#L1912 ip_route_input_slow 函數中用到 route_localnet配置,如下: 在收到數據包時,從ip層來看,數據包會經過 ip_rcv(ip層入口函數) -> ip_rcv_finish -> ip_route_input_slow。 在ip_route_input_slow函數中可以看到,如果源ip或者目的ip是"loopback地址",并且接收數據包的設備沒有配置route_localnet選項時,就會認為是非法數據包。 內核網絡參數詳解 提到,rp_filter=1時,會嚴格驗證源ip。 怎么檢查源ip呢?就是收到數據包后,將源ip和目的ip對調,然后再查找路由表,找到會用哪個設備回包。如果"回包的設備"和"收到數據包的設備"不一致,就有可能校驗失敗。這個也就是后面說的"反向檢查"。 上面提到 收到數據包時,從ip層來看,會執行 ip_route_input_slow 函數查找路由表。 ip_route_input_slow 函數會執行 fib_validate_source 函數執行 "驗證源ip",會使用到rp_filter和accept_local配置 https://elixir.bootlin.com/linux/v4.18/source/net/ipv4/fib_frontend.c#L412 當在容器中 如果容器中 accept_local=1、rp_filter=0 有一個條件不成立,就會發生丟包。這個時候如果你在容器網絡命名空間用 小技巧:nsenter -n -t 容器進程pid 可以進入到容器網絡空間,接著就可以tcpdump抓"容器網絡中的包" 借用網絡上的一張圖來說明docker網橋模式
在容器內 因此會走默認網關(172.17.0.1),在鏈路層就會找網關的mac地址 實際上 因此第一個syn包信息是
內核協議棧中哪里用route_localnet配置來檢查?
/*
* NOTE. We drop all the packets that has local source
* addresses, because every properly looped back packet
* must have correct destination already attached by output routine.
*
* Such approach solves two big problems:
* 1. Not simplex devices are handled properly.
* 2. IP spoofing attempts are filtered with 100% of guarantee.
* called with rcu_read_lock()
*/
static int ip_route_input_slow(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev,
struct fib_result *res)
{
...
/* Following code try to avoid calling IN_DEV_NET_ROUTE_LOCALNET(),
* and call it once if daddr or/and saddr are loopback addresses
*/
if (ipv4_is_loopback(daddr)) { // 目的地址是否"loopback地址"
if (!IN_DEV_NET_ROUTE_LOCALNET(in_dev, net)) // localnet配置是否開啟。net是網絡命名空間,in_dev是接收數據包設備配置信息
goto martian_destination; // 認為是非法數據包
} else if (ipv4_is_loopback(saddr)) { // 源地址是否"loopback地址"
if (!IN_DEV_NET_ROUTE_LOCALNET(in_dev, net))
goto martian_source; // 認為是非法數據包
}
...
err = fib_lookup(net, &fl4, res, 0); // 查找"路由表",res存放查找結果
...
if (res->type == RTN_BROADCAST)
...
if (res->type == RTN_LOCAL) { // 數據包應該本機處理
err = fib_validate_source(skb, saddr, daddr, tos,
0, dev, in_dev, &itag); // "反向查找", 驗證源地址是否有問題
if (err < 0)
goto martian_source;
goto local_input; // 本機處理
}
if (!IN_DEV_FORWARD(in_dev)) { // 沒有開啟ip_forward配置時,認為不支持 轉發數據包
err = -EHOSTUNREACH;
goto no_route;
}
...
err = ip_mkroute_input(skb, res, in_dev, daddr, saddr, tos, flkeys); // 認為此包需要"轉發"
}static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
...
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (!skb_valid_dst(skb)) { // 是否有路由緩存. 宿主機curl 127.0.0.1時,就有緩存,不用查找路由表。
err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, dev); // 查找路由表
if (unlikely(err))
goto drop_error;
}
...
return dst_input(skb); // 將數據包交給tcp層(ip_local_deliver) 或 轉發數據包(ip_forward)rp_filter和accept_local
是什么?
內核協議棧中哪里用rp_filter和accept_local配置來檢查?
/* Ignore rp_filter for packets protected by IPsec. */
int fib_validate_source(struct sk_buff *skb, __be32 src, __be32 dst,
u8 tos, int oif, struct net_device *dev,
struct in_device *idev, u32 *itag)
{
int r = secpath_exists(skb) ? 0 : IN_DEV_RPFILTER(idev); // r=rp_filter配置
struct net *net = dev_net(dev);
if (!r && !fib_num_tclassid_users(net) &&
(dev->ifindex != oif || !IN_DEV_TX_REDIRECTS(idev))) { // dev->ifindex != oif 表示 不是lo虛擬網卡接收到包
if (IN_DEV_ACCEPT_LOCAL(idev)) // accept_local配置是否打開。idev是接受數據包的網卡配置
goto ok;
/* with custom local routes in place, checking local addresses
* only will be too optimistic, with custom rules, checking
* local addresses only can be too strict, e.g. due to vrf
*/
if (net->ipv4.fib_has_custom_local_routes ||
fib4_has_custom_rules(net)) // 檢查"網絡命名空間"中是否有自定義的"策略路由"
goto full_check;
if (inet_lookup_ifaddr_rcu(net, src)) // 檢查"網絡命名空間"中是否有設備的ip和源ip(src值)相同
return -EINVAL;
ok:
*itag = 0;
return 0;
}
full_check:
return __fib_validate_source(skb, src, dst, tos, oif, dev, r, idev, itag); // __fib_validate_source中會執行"反向檢查源ip"
}curl 127.0.0.1 --interface eth0時,有一些結論:
宿主機收到請求包時,無論 accept_local和rp_filter是啥值,都通過fib_validate_source檢查
容器中收到請求包時,必須要設置 accept_local=1、rp_filter=0,才能不被"反向檢查源ip"tcpdump -i eth0 'port 8888' -n -e觀察,就會發現詭異的現象:容器接收到了syn-ack包,但是沒有回第三個ack握手包。如下圖
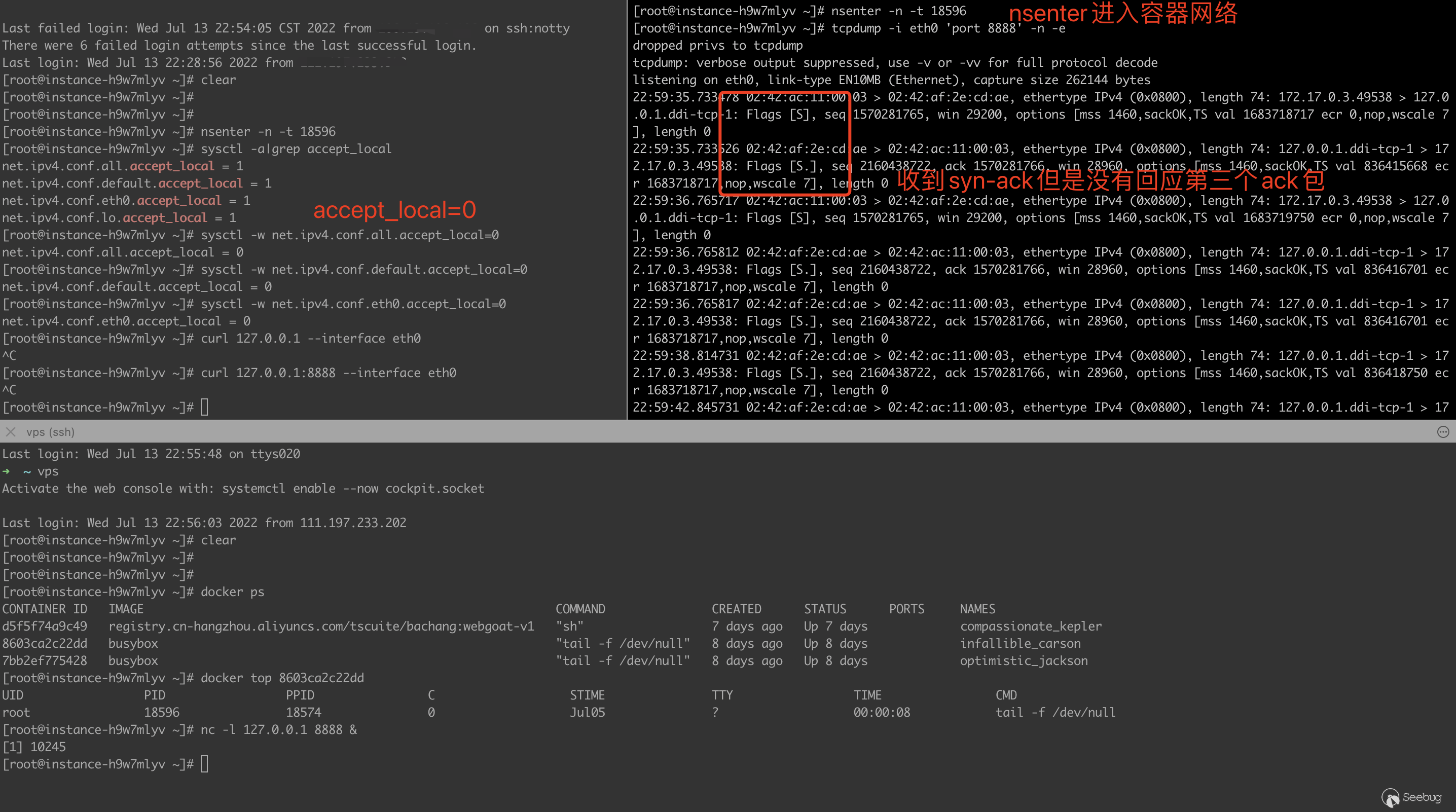
docker網橋模式下復現漏洞
docker網橋模式下漏洞原理是什么?
curl 127.0.0.1:8888 --interface eth0時,發送第一個syn包時,在網絡層查找路由表[root@instance-h9w7mlyv ~]# ip route show
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3[root@instance-h9w7mlyv ~]# arp -a|grep 172.17.0.1
_gateway (172.17.0.1) at 02:42:af:2e:cd:ae [ether] on eth002:42:af:2e:cd:ae就是docker0網橋的mac地址,所以網關就是docker0網橋[root@instance-h9w7mlyv ~]# ifconfig docker0
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
...
ether 02:42:af:2e:cd:ae txqueuelen 0 (Ethernet)
...
| 源ip | 目的ip | 源mac | 目的mac | 源端口 | 目的端口 |
|---|---|---|---|---|---|
| 容器eth0 ip | 127.0.0.1 | 容器eth0 mac | docker0 mac | 4444(隨機端口) | 8888 |
syn包數據包數據流向是 容器內eth0 -> veth -> docker0。
veth設備作為docker0網橋的"從設備",接收到syn包后直接轉發,不會調用到"內核協議棧"的網絡層。
docker0網橋設備收到syn包后,在"內核協議棧"的鏈路層,看到目的mac是自己,就把包扔給網絡層處理。在網絡層查路由表,看到目的ip是本機ip,就將包扔給傳輸層處理。在傳輸層看到訪問"127.0.0.1:8888",就會查看是不是有服務監聽在"127.0.0.1:8888"。
怎么復現?
從上面分析可以看出來,需要將宿主機docker0網橋設備route_localnet設置成1。
宿主機docker0網橋設備需要設置rp_filter和accept_local選項嗎?答案是不需要,因為docker0網橋設備在收到數據包在網絡層做"反向檢查源地址"時,會知道"響應數據包"也從docker0網橋發送。"發送和接收數據包的設備"是匹配的,所以能通過"反向檢查源地址"的校驗。
容器中eth0網卡需要設置rp_filter=0、accept_local=1、localnet=1。為什么容器中eth0網卡需要設置rp_filter和accept_local選項呢?因為eth0網橋設備如果做"反向檢查源地址",就會知道響應包應該從lo網卡發送。"接收到數據包的設備是eth0網卡",而"發送數據包的設備應該是lo網卡",兩個設備不匹配,"反向檢查"就會失敗。rp_filter=0、accept_local=1可以避免做"反向檢查源地址"。
即使ifconfig lo down,
ip route show table local仍能看到local表中有回環地址的路由。
下面你可以跟著我來用docker復現漏洞。
首先在宿主機上打開route_localnet配置
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.all.route_localnet=1然后創建容器,并進入到容器網絡命名空間,設置rp_filter=0、accept_local=1
[root@instance-h9w7mlyv ~]# docker run -d busybox tail -f /dev/null // 創建容器
62ba93fbbe7a939b7fff9a9598b546399ab26ea97858e73759addadabc3ad1f3
[root@instance-h9w7mlyv ~]# docker top 62ba93fbbe7a939b7fff9a9598b546399ab26ea97858e73759addadabc3ad1f3
UID PID PPID C STIME TTY TIME CMD
root 43244 43224 0 12:33 ? 00:00:00 tail -f /dev/null
[root@instance-h9w7mlyv ~]# nsenter -n -t 43244 // 進入到容器網絡命名空間
[root@instance-h9w7mlyv ~]#
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.all.accept_local=1 // 設置容器中的accept_local配置
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.all.rp_filter=0 // 設置容器中的rp_filter配置
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.default.rp_filter=0
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.eth0.rp_filter=0如果你是
docker exec -ti busybox sh進入到容器中,然后執行sysctl -w配置內核參數,就會發現報錯,因為/proc/sys目錄默認是作為只讀掛載到容器中的,而內核網絡參數就在/proc/sys/net目錄下。
然后就可以在容器中使用curl 127.0.0.1:端口號 --interface eth0來訪問宿主機上的服務。
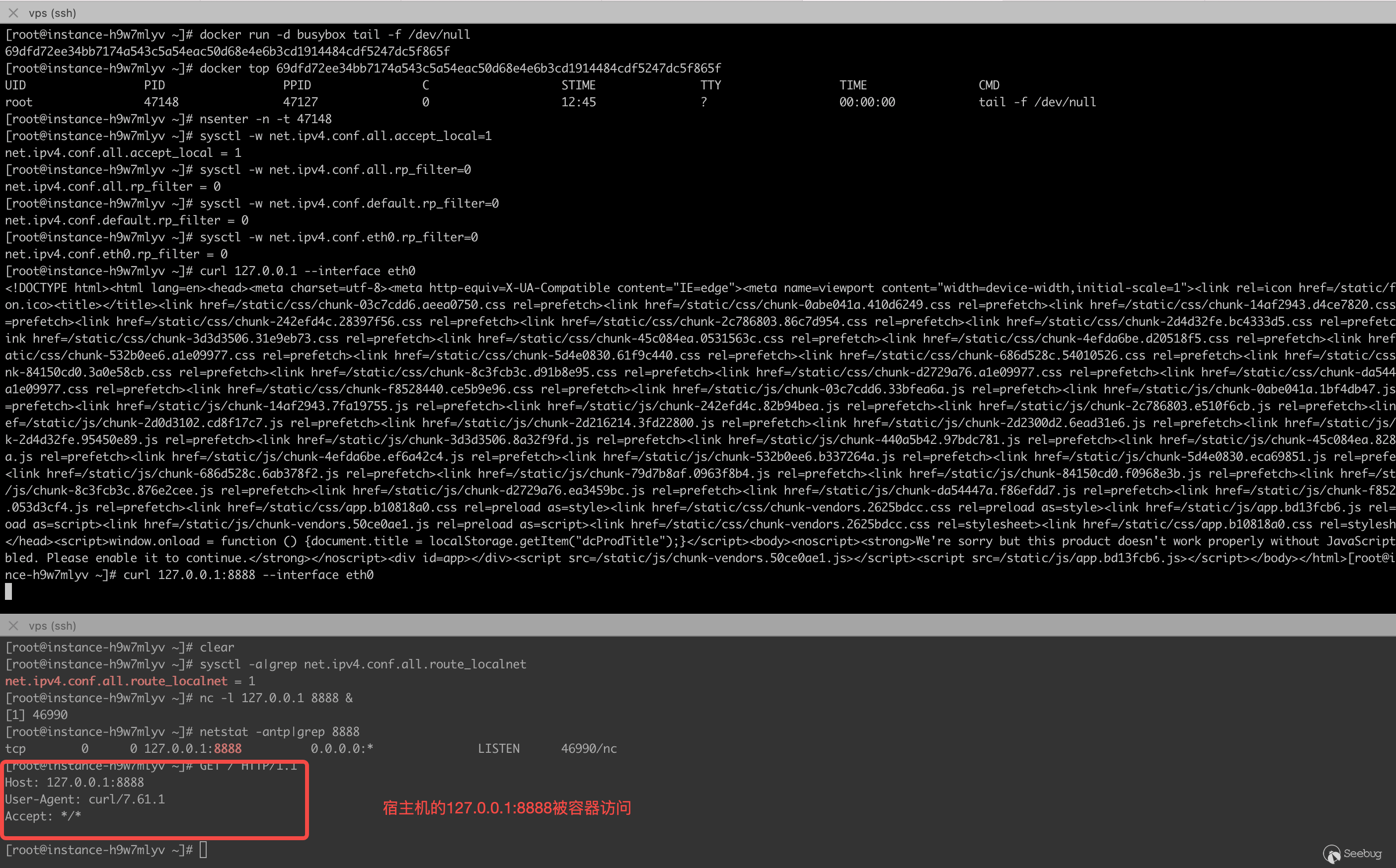
kubernetes對漏洞的修復
在 這個pr 中kubelet添加了一條iptables規則
root@ip-172-31-14-33:~# iptables-save |grep localnet
-A KUBE-FIREWALL ! -s 127.0.0.0/8 -d 127.0.0.0/8 -m comment --comment "block incoming localnet connections" -m conntrack ! --ctstate RELATED,ESTABLISHED,DNAT -j DROP這條規則使得,在tcp握手時,第一個syn包如果目的ip是"環回地址",同時源ip不是"環回地址"時,包會被丟棄。
所以如果你復現時是在kubernetes環境下,就需要刪掉這條iptables規則。
或許你會有疑問,源ip不也是可以偽造的嘛。確實是這樣,所以在 https://github.com/kubernetes/kubernetes/pull/91569 中有人評論到,上面的規則,不能防止訪問本地udp服務。
總結
公有云vpc網絡環境下,可能因為交換機有做限制而導致無法訪問其他虛擬機的"僅綁定在127.0.0.1的服務"。
docker容器網橋網絡環境下,存在漏洞的kube-proxy已經設置了宿主機網絡的route_localnet選項,但是因為在容器中/proc/sys默認只讀,所以無法修改容器網絡命名空間下的內核網絡參數,也很難做漏洞利用。
kubernetes的修復方案并不能防止訪問本地udp服務。
如果kubernetes使用了cni插件(比如calico ipip網絡模型),你覺得在node節點能訪問到master節點的"僅綁定在127.0.0.1的服務"嗎?
參考
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1938/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1938/