
作者:0x7F@知道創宇404實驗室
時間:2021年8月13日
0x00 前言
最近在使用 Golang 的 regexp 對網絡流量做正則匹配時,發現有些情況無法正確進行匹配,找到資料發現 regexp 內部以 UTF-8 編碼的方式來處理正則表達式,而網絡流量是字節序列,由其中的非 UTF-8 字符造成的問題。
我們這里從 Golang 的字符編碼和 regexp 處理機制開始學習和分析問題,并尋找一個有效且比較通用的解決方法,本文對此進行記錄。
本文代碼測試環境 go version go1.14.2 darwin/amd64
0x01 regexp匹配字節序列
我們將匹配網絡流量所遇到的問題,進行抽象和最小化復現,如下:
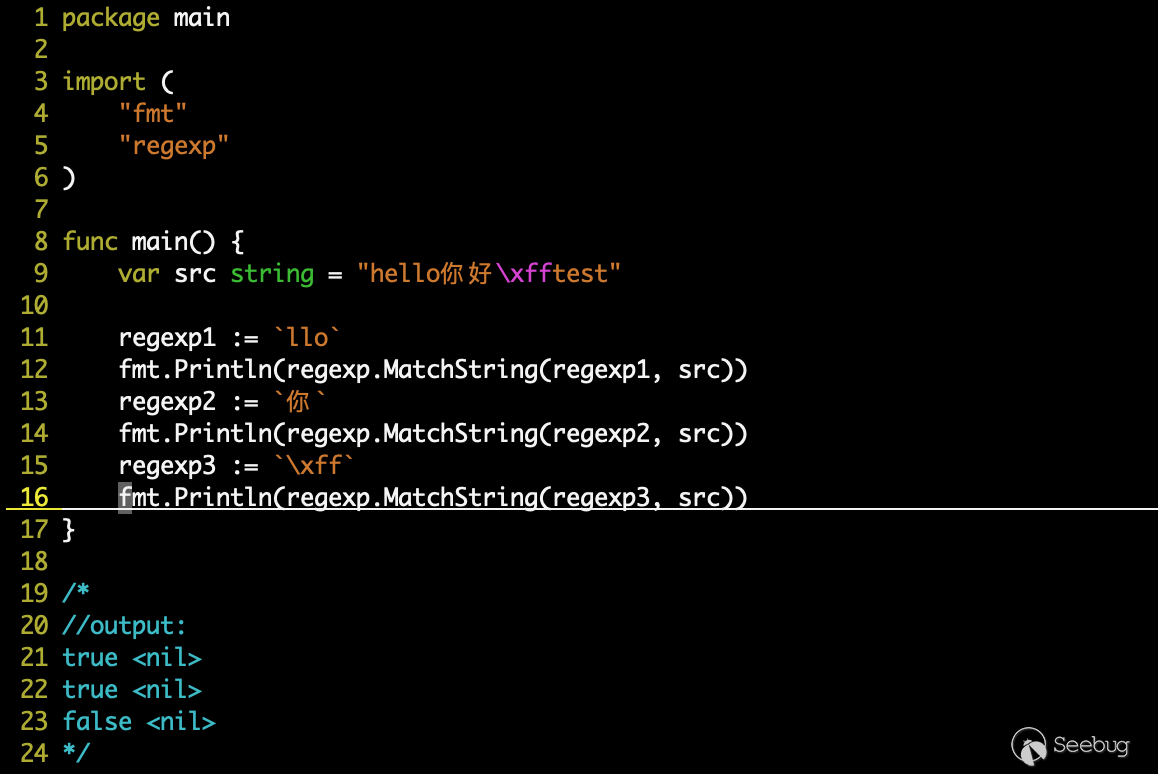
我們可以看到 \xff 沒有按照預期被匹配到,那么問題出在哪里呢?
0x02 UTF-8編碼
翻閱 Golang 的資料,我們知道 Golang 的源碼采用 UTF-8 編碼, regexp 庫的正則表達式也是采用 UTF-8 進行解析編譯(而且 Golang 的作者也是 UTF-8 的作者),那我們先來看看 UTF-8 編碼規范。
1.ASCII
在計算機的世界,字符最終都由二進制來存儲,標準 ASCII 編碼使用一個字節(低7位),所以只能表示 127 個字符,而不同國家有不同的字符,所以建立了自己的編碼規范,當不同國家相互通信的時候,由于編碼規范不同,就會造成亂碼問題。
“中文”
GB2312: \xd6\xd0\xce\xc4
ASCII: ????2.Unicode
為了解決亂碼問題,提出了 Unicode 字符集,為所有字符分配一個獨一無二的編碼,隨著 Unicode 的發展,不斷添加新的字符,目前最新的 Unicode 采用 UCS-4(Unicode-32) 標準,也就是使用 4 字節(32位) 來進行編碼,理論上可以涵蓋所有字符。
但是 Unicode 只是字符集,沒有考慮計算機中的使用和存儲問題,比如:
- 與已存在的 ASCII 編碼不兼容,
ASCII(A)=65 / UCS-2(A)=0065 - 由于 Unicode 編碼高字節可能為 0,C 語言字符串串函數將出現 00 截斷問題
- 從全世界來看原來 ASCII 的字符串使用得最多,而換成 Unicode 過后,這些 ASCII 字符的存儲都將額外占用字節(存儲0x00)
3.UTF-8
后來提出了 UTF-8 編碼方案,UTF-8 是在互聯網上使用最廣的一種 Unicode 的實現方式;UTF-8 是一種變長的編碼方式,編碼規則如下:
- 對于單字節的符號,字節的第一位設為 0,后面 7 位為這個符號的 Unicode 的碼點,兼容 ASCII
- 對于需要 n 字節來表示的符號(n > 1),第一個字節的前 n 位都設為 1,第 n+1 位設置為 0;后面字節的前兩位一律設為 10,剩下的的二進制位則用于存儲這個符號的 Unicode 碼點(從低位開始)。
編碼規則如下:
Unicode符號范圍(十六進制) | UTF-8編碼方式(二進制)
00000000 - 0000007F | 0xxxxxxx
00000080 - 000007FF | 110xxxxx 10xxxxxx
00000800 - 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx
00010000 - 0010FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx編碼中文 你 如下:
Unicode: \u4f60 (0b 01001111 01100000)
UTF-8: \xe4\xbd\xa0 (0b 1110/0100 10/111101 10/100000)
(這里用斜線分割了下 UTF-8 編碼的前綴)1.根據 UTF-8 編碼規則,當需要編碼的符號超過 1 個字節時,其第一個字節前面的 1 的個數表示該字符占用了幾個字節。
2.UTF-8 是自同步碼(Self-synchronizing_code),在 UTF-8 編碼規則中,任意字符的第一個字節必然以 0 / 110 / 1110 / 11110 開頭,UTF-8 選擇 10 作為后續字節的前綴碼,以此進行區分。自同步碼可以便于程序尋找字符邊界,快速跳過字符,當遇到錯誤字符時,可以跳過該字符完成后續字符的解析,這樣不會造成亂碼擴散的問題(GB2312存在該問題)
0x03 byte/rune/string
在 Golang 中源碼使用 UTF-8 編碼,我們編寫的代碼/字符會按照 UTF-8 進行編碼,而和字符相關的有三種類型 byte/rune/string。
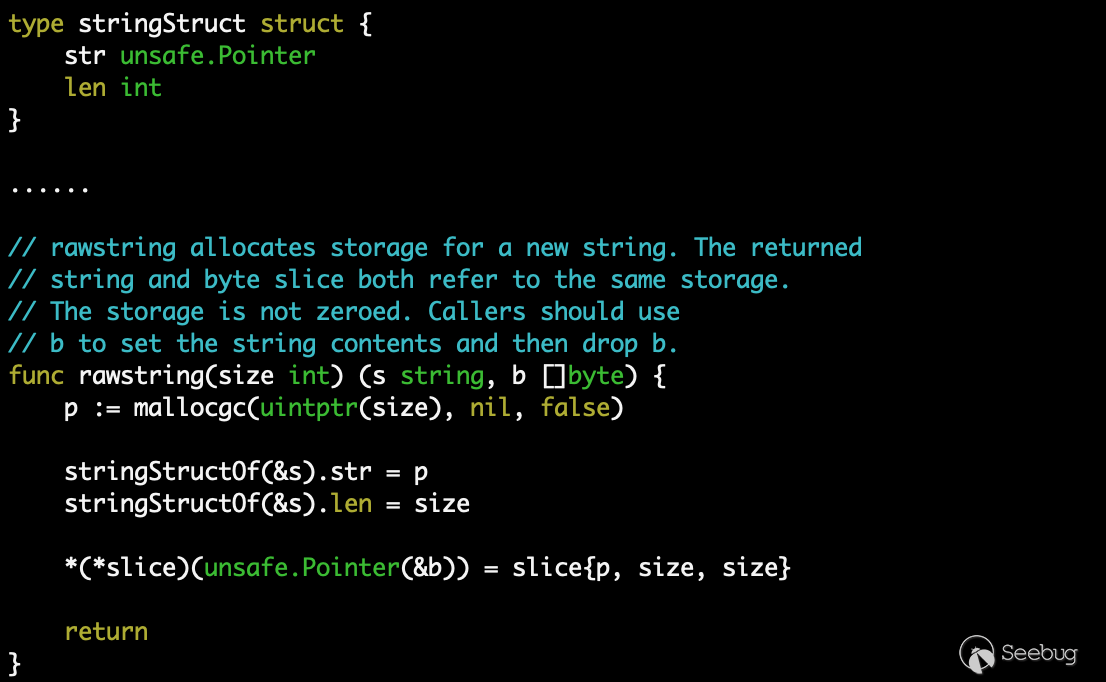
byte 是最簡單的字節類型(uint8),string 是固定長度的字節序列,其定義和初始化在 https://github.com/golang/go/blob/master/src/runtime/string.go,可以看到 string 底層就是使用 []byte 實現的:
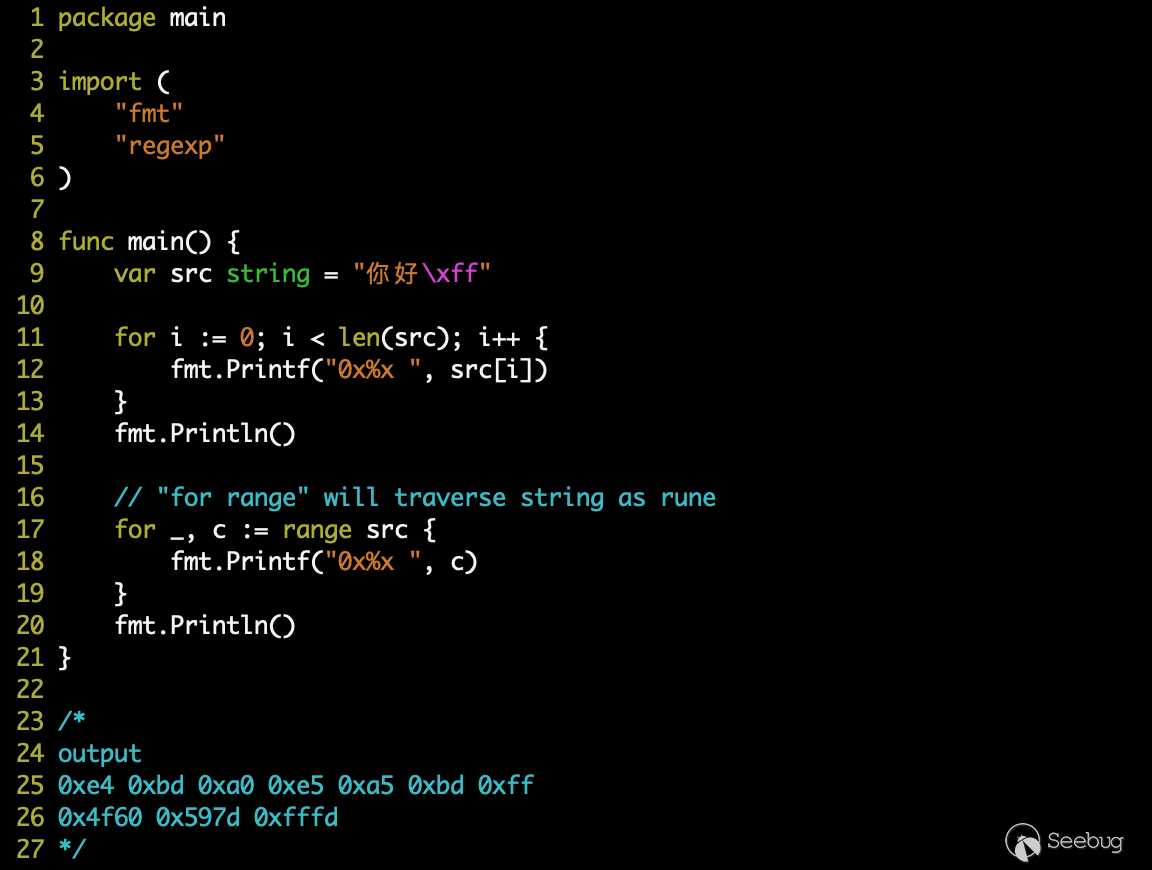
rune 類型則是 Golang 中用來處理 UTF-8 編碼的類型,實際類型為 int32,存儲的值是字符的 Unicode 碼點,所以 rune 類型可以便于我們更直觀的遍歷字符(對比遍歷字節)如下:
類型轉換
byte(uint8) 和 rune(int32) 可以直接通過位擴展或者舍棄高位來進行轉換。
string 轉換比較復雜,我們一步一步來看:
string 和 byte 類型相互轉換時,底層都是 byte 可以直接相互轉換,但是當單字節 byte 轉 string 類型時,會調用底層函數 intstring() (https://github.com/golang/go/blob/master/src/runtime/string.go#L244),然后調用 encoderune() 函數,對該字節進行 UTF-8 編碼,測試如下:

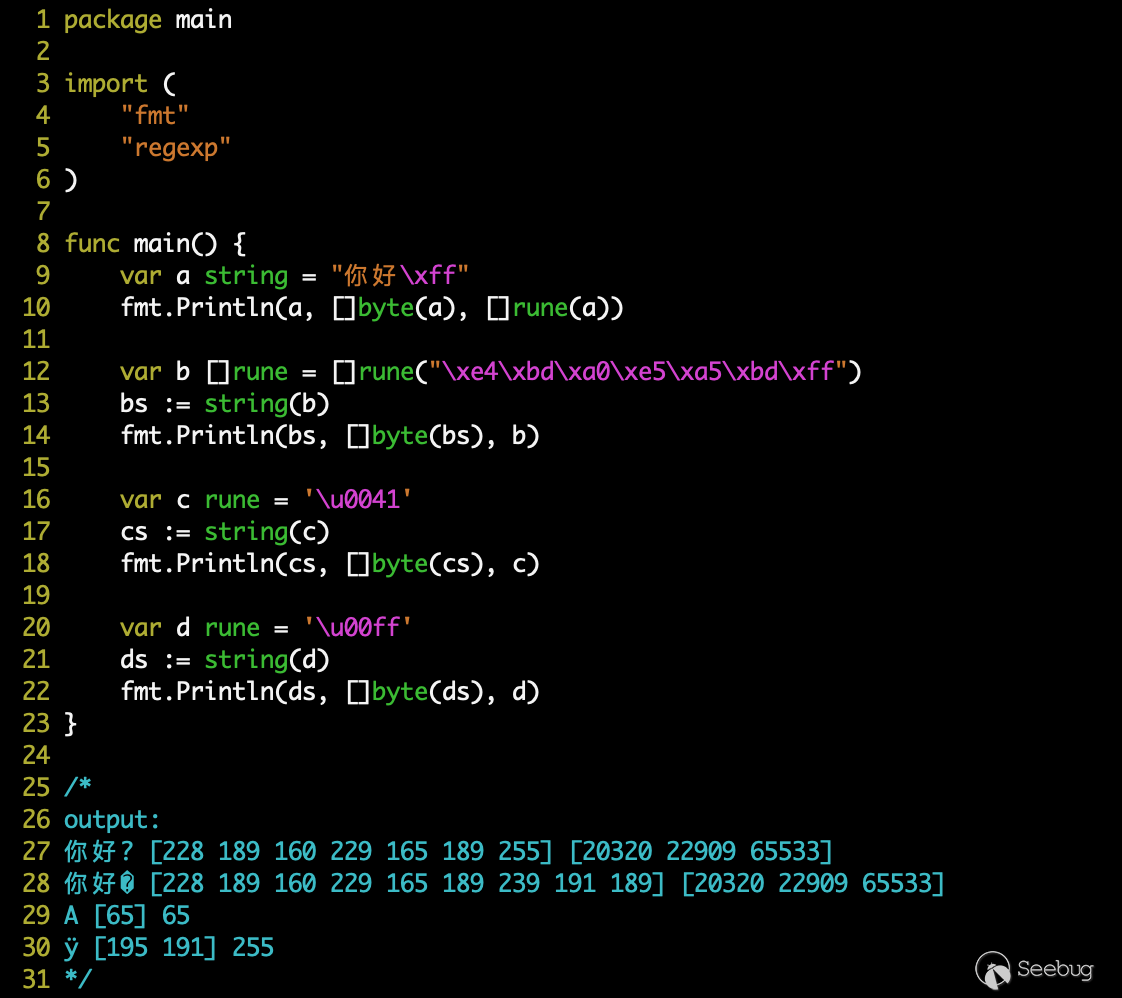
string 和 rune 類型相互轉換時,對于 UTF-8 字符的相互轉換,底層數據發生變化 UTF-8編碼 <=> Unicode編碼;而對于非 UTF-8 字符,將以底層單字節進行處理:
string => rune時,會調用stringtoslicerune()(https://github.com/golang/go/blob/master/src/runtime/string.go#L178),最終跟進到 Golang 編譯器的for-range實現(https://github.com/golang/go/blob/master/src/cmd/compile/internal/walk/range.go#L220),轉換時調用decoderune()對字符進行 UTF-8 解碼,解碼失敗時(非 UTF-8 字符)將返回RuneError = \uFFFD;rune => string時,和byte單字節轉換一樣,會調用intstring()函數,對值進行 UTF-8 編碼。
測試如下:
0x04 regexp處理表達式
在 regexp 中所有的字符都必須為 UTF-8 編碼,在正則表達式編譯前會對字符進行檢查,非 UTF-8 字符將直接提示錯誤;當然他也支持轉義字符,比如:\t \a 或者 16進制,在代碼中我們一般需要使用反引號包裹正則表達式(原始字符串),轉義字符由 regexp 在內部進行解析處理,如下:
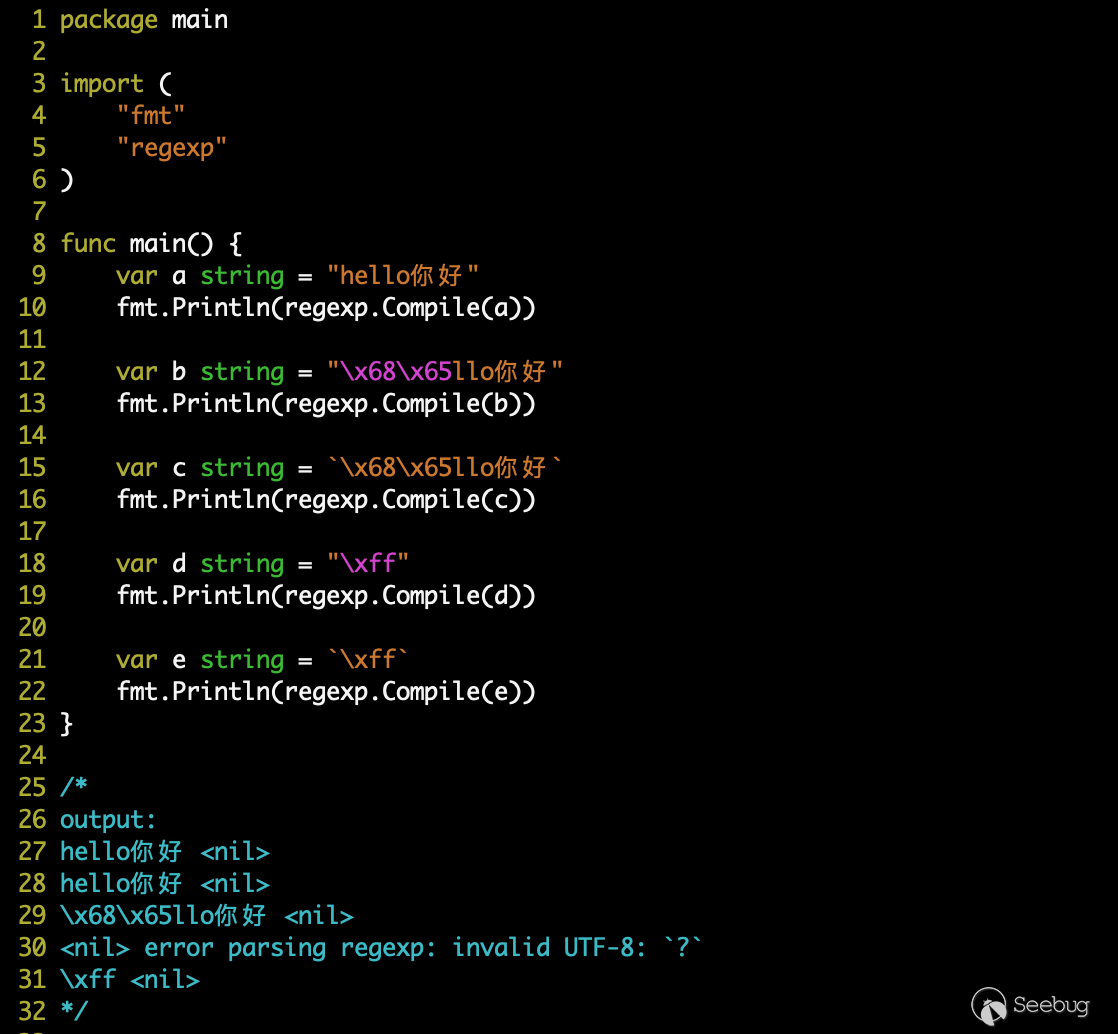
當然為了讓
regexp編譯包含非 UTF-8 編碼字符的表達式,必須用反引號包裹才行
我們在使用 regexp 時,其內部首先會對正則表達式進行編譯,然后再進行匹配。
1.編譯
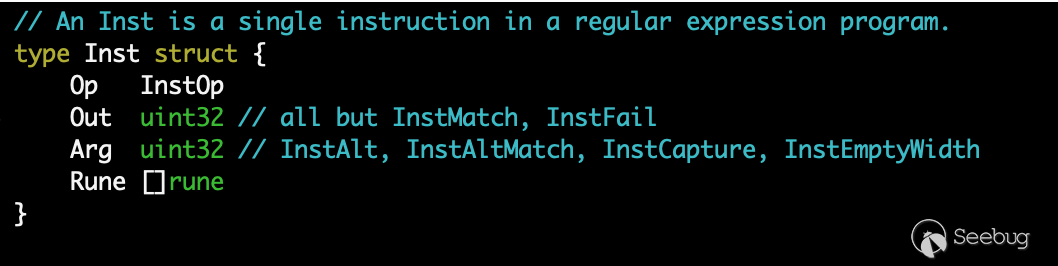
編譯主要是構建自動機表達式,其底層最終使用 rune 類型存儲字符(https://github.com/golang/go/blob/master/src/regexp/syntax/prog.go#L112),所以 \xff 通過轉義后最終存儲為 0x00ff (rune)
除此之外,在編譯階段 regexp 還會提前生成正則表達式中的前綴字符串,在執行自動機匹配前,先用匹配前綴字符串,以提高匹配效率。需要注意的是,生成前綴字符串時其底層將調用 strings.Builder 的 WriteRune() 函數(https://github.com/golang/go/blob/master/src/regexp/syntax/prog.go#L147),內部將調用 utf8.EncodeRune() 強制轉換表達式的字符為 UTF-8 編碼(如:\xff => \xc3\xbf)。
2.匹配
當匹配時,首先使用前綴字符串匹配,這里使用常規的字符串匹配。UTF-8 可以正常進行匹配,但當我們的字符串中包含非 UTF-8 字符就會出現問題,原因正則表達式中的前綴字符串已經被強制 UTF-8 編碼了,示例如下:
regexp: `\xff`
real regexp prefix: []byte(\xc3\xbf)
string: "\xff"
real string: []byte(\xff)
[NOT MATCHED]當執行自動機匹配時,將最終調用 tryBacktrace() 函數進行逐字節回溯匹配(https://github.com/golang/go/blob/master/src/regexp/backtrack.go#L140),使用 step() 函數遍歷字符串(https://github.com/golang/go/blob/master/src/regexp/regexp.go#L383),該函數有 string/byte/rune 三種實現,其中 string/byte 將調用 utf8.DecodeRune*() 強制為 rune 類型,所以三種實現最終都返回 rune 類型,然后和自動機表達式存儲的 rune 值進行比較,完成匹配。而這里當非 UTF-8 字符通過 utf8.DecodeRune*() 函數時,將返回 RuneError=0xfffd,示例如下:
(PS: 不應該用簡單字符表達式,簡單字符表達式將會直接使用前綴字符串完成匹配)
regexp: `\xcf-\xff`
real regexp inst: {Op:InstRune Out:4 Arg:0 Rune:[207 255]}
string: "\xff"
string by step(): 0xfffd
[NOT MATCHED]比較復雜,不過簡而言之就是 regexp 內部會對表達式進行 UTF-8 編碼,會對字符串進行 UTF-8 解碼。
了解 regexp 底層匹配運行原理過后,我們甚至可以構造出更奇怪的匹配:
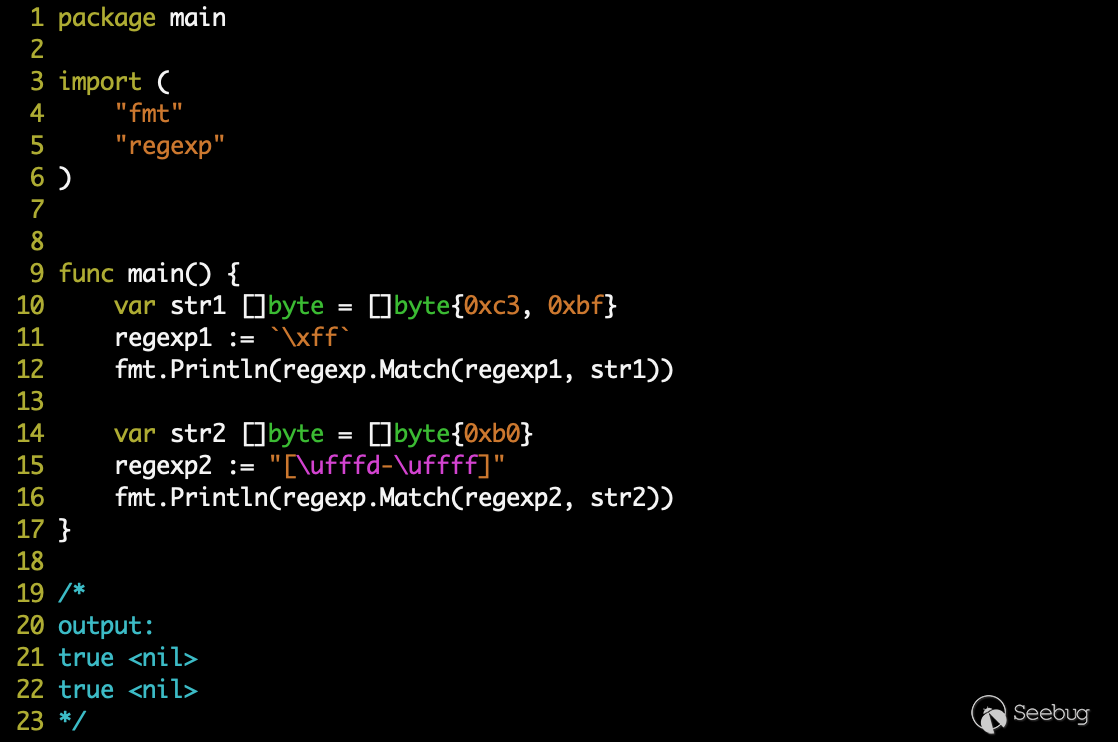
0x05 解決方法
在了解以上知識點過后,就很容易解決問題了:表達式可以使用任意字符,待匹配字符串在匹配前手動轉換為合法的 UTF-8 字符串。
因為當 regexp 使用前綴字符串匹配時,會自動轉換表達式字符為 UTF-8 編碼,和我們的字符串一致;當 regexp 使用自動機匹配時,底層使用 rune 進行比較,我們傳入的 UTF-8 字符串將被正確通過 UTF-8 解碼,可以正確進行匹配。
實現測試如下:

0x06 總結
關于開頭提出的 regexp 匹配的問題到這里就解決了,在不斷深入語言實現細節的過程中發現:Golang 本身在盡可能的保持 UTF-8 編碼的一致性,但在編程中字節序列是不可避免的,Golang 中使用 string/byte 類型來進行處理,在 regexp 底層實現同樣使用了 UTF-8 編碼,所以問題就出現了,字節序列數據和編碼后的數據不一致。
個人感覺 regexp 用于匹配字節流并不是一個預期的使用場景,像是 Golang 官方在 UTF-8 方面的一個取舍。
當然這個過程中,我們翻閱了很多 Golang 底層的知識,如字符集、源碼等,讓我們了解了一些 Golang 的實現細節;在實際常見下我們不是一定要使用標準庫 regexp,還可以使用其他的正則表達式庫來繞過這個問題。
References:
https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://blog.golang.org/strings
https://zh.wikipedia.org/wiki/UTF-8
https://stackoverflow.com/questions/53009692/utf-8-encoding-why-prefix-10
https://en.wikipedia.org/wiki/Self-synchronizing_code
https://www.zhihu.com/question/19817672
https://pkg.go.dev/regexp/syntax
https://github.com/golang/go/issues/38006
https://github.com/golang/go/tree/master/src/regexp
https://golang.org/src/runtime/string.go
https://github.com/golang/go/blob/master/src/builtin/builtin.go
https://github.com/golang/gofrontend/blob/master/go/statements.cc#L6841
https://github.com/golang/go/blob/master/src/cmd/compile/internal/walk/range.go#L220
https://github.com/golang/go/blob/master/src/runtime/string.go#L244
https://github.com/golang/go/blob/master/src/runtime/string.go#L178
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1679/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1679/
暫無評論