
作者: Flanker
原文鏈接:https://mp.weixin.qq.com/s/G26MJOH4VPene1Sd_zjEQw
本文撥開二進制Fuzzing的迷霧為Fuzzing戰爭系列的第二篇,也是Fuzzing戰爭:從刀劍弓斧到星球大戰的續篇。
每個人都期待有全圖點亮的體驗,然而現實中安全研究的目標卻更多是編譯好的二進制binary而沒有源碼。迷霧之下崇山峻嶺羊腸小道,但應許之地卻往往也隱藏其中。本文將以目前最為主流的Android on ARM/AARCH64為例,綜合筆者在 MOSEC 2020 和 RWCTF Tech Forum 2021 的演講內容,首次系統性地闡述如何實現無源碼情況下的大規模Coverage-Guided Fuzzing理論、工程和實踐,和小試牛刀即發現的主流移動終端中廣泛存在的真實漏洞。出于閱讀體驗,本篇可能會分多次發出,持續更新中。
Let's rock n' roll !
溫故而知新
就像簡陋的紙帶機模型卻能描述出完備的圖靈機一樣,一個五行的bash腳本甚至也可以成為fuzzer,當然作為一個dumb fuzzer,直到宇宙毀滅,它也不一定能發現一個漏洞。
現代Fuzzing技術以樣本為驅動,論Coverage Feedback為核心,取遺傳算法為理論。獲取Coverage的辦法主要有三種:
- Compiler Instrumentation w/ source, e.g GCC / LLVM
- Hardware-tracing, e.g. Intel PT
- binary-based: static rewrite/ dynamic tracing
相比于傳統的Grammar Fuzzer, CGF Fuzzer在每輪變異樣本的輸入運行后,會評估該樣本是否觸及了更多的代碼塊,從而決定是否保留它進而進行更深度的變異,從而自動構建輸入樣本的格式。以AFL為例,在x86形式下,其核心插樁代碼邏輯如下所描述:
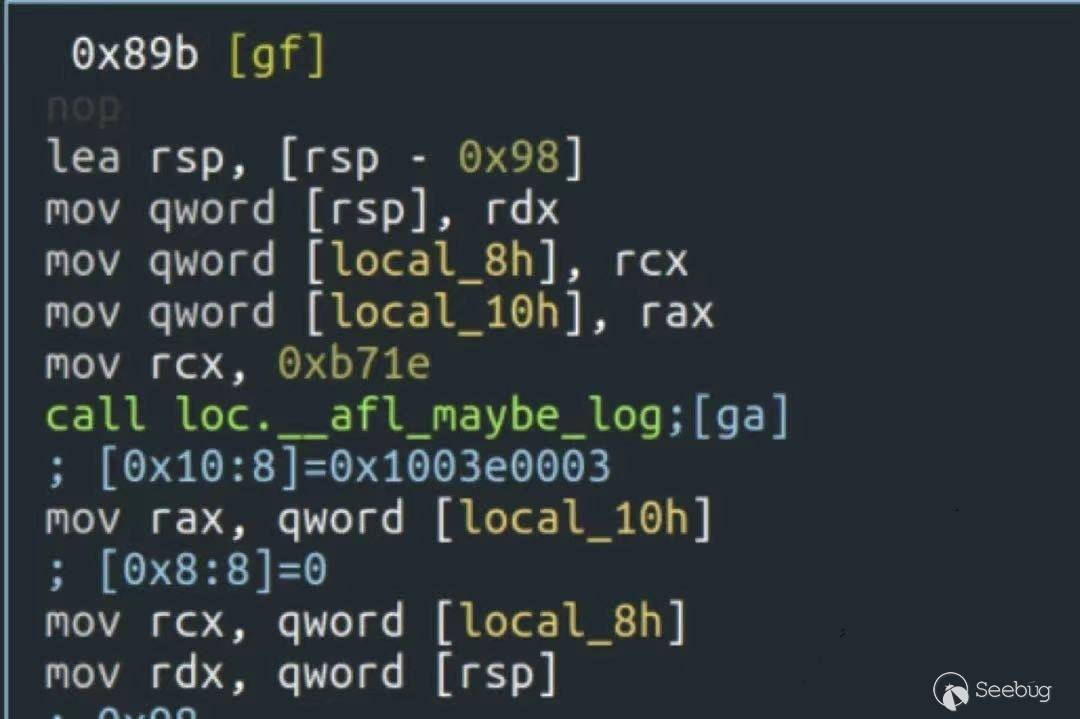
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;在有源碼的情況下,基于編譯器工具鏈的支持,我們可以很容易地在編譯過程中實現以上的變更。
Elephant in the room
但更多的時候,房間里會有這么一些閉源的大象:
- 來自于供應鏈的黑盒SDK
- 平臺私有庫 (例如移動設備中Qualcomm, Samsung, Apple等不開源的系統組件內容)
- 一些即使有源碼但需要特殊運行時支持的產品,或者因為部門墻而拿不到源碼的自家產品 (true story)
引入注目卻大部分時間讓人束手無策,也少見對這方面的研究和成功實踐。公開的文獻中對此類目標仍然是dumb fuzz居多,

這前朝Fuzzer的劍,就斬不了本朝的binary target了么?
Static or Dynamic? "996還是11116?"
為了解決這個問題,我們首先需要確定在無源碼情況下應當如何收集Coverage。ELF/MachO的Static Rewrite和Dynamic Tracing是我們可能的選項,那他們分別是什么,對于實際環境下的目標又應當如何選擇?是996,還是11116?

Static Rewrite
Static Rewrite基于Disassembling 和 Static Patching。目標ELF/MachO/PE首先被匯編后,根據其Control Flow提取出Basic Block。類似于孫悟空復制出六小齡童一樣,我們可以在Basic Block的edge處插入希望被執行的指令,進而獲得一個新的binary,也就是所謂的rewrite。AFL-DynInst和e9patch 是其中的典型案例,例如AFL-DynInst的做法即是
.. inserting callbacks for each basic block and an initialization callback either at _init or at specified entry point ..它的優點非常明顯:對于實現較好的rewrite,目標binary在性能上具有巨大的優勢。但同樣地缺點也非常明顯,魔鬼在于細節。
- rewrite事實上修改了目標的basic block,這意味著我們通常必須要將一些basic block進行ELF內的遷移以騰出足夠的空間。那么對于主流的relocatable binary而言,這涉及到重定位會帶來的一系列問題。同理上反匯編引擎需要能夠盡可能地識別出控制流,否則就會出現遺漏覆蓋率或者運行時崩潰。而不幸的是,目前的rewrite工具對ARM平臺的binary支持并不是很好。
- 對于ARM/AARCH64的目標而言,該方法更存在一個終極悖論:在ARM server和工作站普及之前,rewrite后的binary應當在哪里運行?如果仍然需要在移動設備、開發板上運行的話,我們還是需要面臨著平臺本身的限制,移動設備在高負荷的Fuzzing時經常會出現過熱變慢甚至變磚的情況,且從成本和物理連接上并不適合動態scale。
當然,隨著ARM工作站的逐漸普及(特別是蘋果M1芯片的攪局),這個狀況后面可能會有所改觀。但目前M1芯片的Mac產品仍不支持直接運行Android Binary (Kernel和linker不同導致),這也是筆者后續所關注和研究的方向。
Dynamic Tracing
相對于靜態編輯技術,Dynamic Tracing著力于運行時獲取coverage信息。這也通常會有兩種實現方式:
- 基于ptrace等實施動態hook,典型案例如frida-qdbi-fuzzer,但這仍需要在同架構下運行
- 基于QEMU實現運行時異構模擬,在模擬執行的過程中獲取coverage, 這也是后面我們會提到的重點
QEMU stands for Quick EMUlator
 QEMU通過
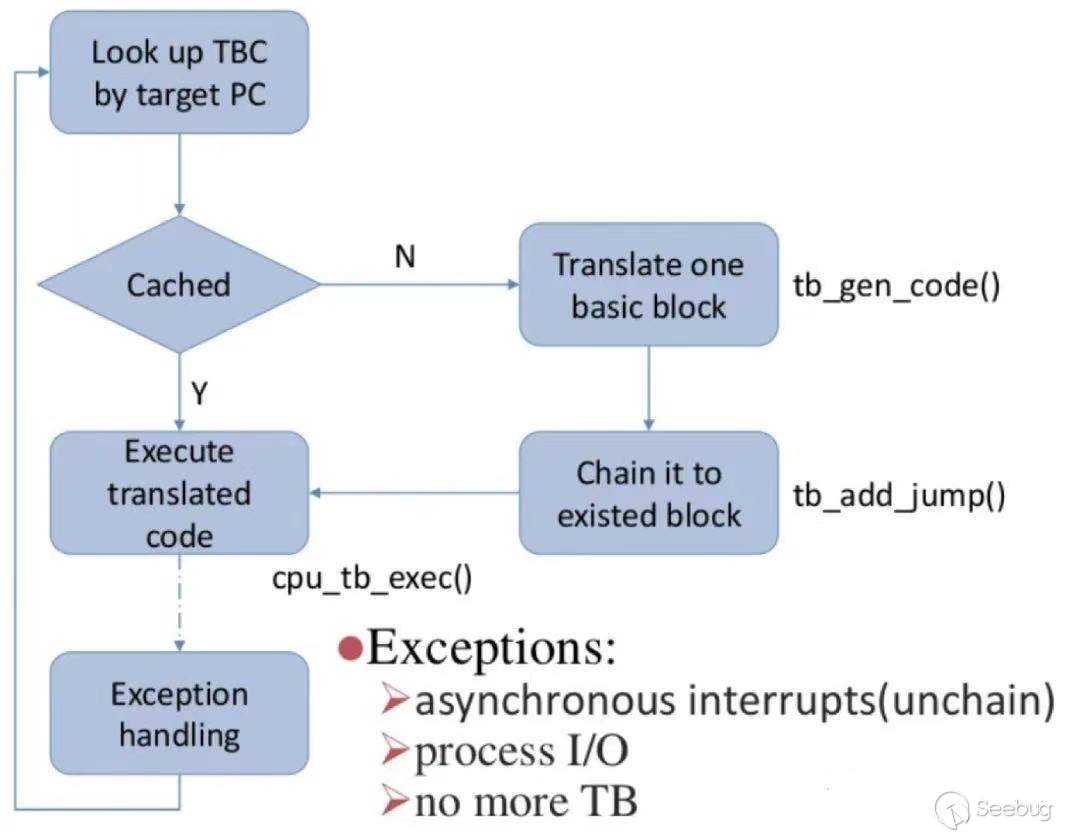
QEMU通過Translated Block的方式提供動態二進制翻譯。我們知道,任何計算機科學技術中的問題都能通過添加中間層解決,QEMU定義了TCG (Tiny Code Generator)的概念作為IR中間語言,任何前端目標語言指令都會被統一翻譯為標準Ops后,再通過后端的解釋器翻譯為Host Machine的Target Code。
在QEMU執行目標程序時,根據指令位置查詢到對應已翻譯的TB會被直接執行,而未翻譯的TB則會被進行實時翻譯,并鏈入緩存序列中,如下圖所示:
這種JIT的方式給了我們操作的空間,一種簡單的思路是與tb掛鉤,在tb_find_slow中直接掛鉤記錄當前的pc值并傳遞給AFL,如下圖所示:
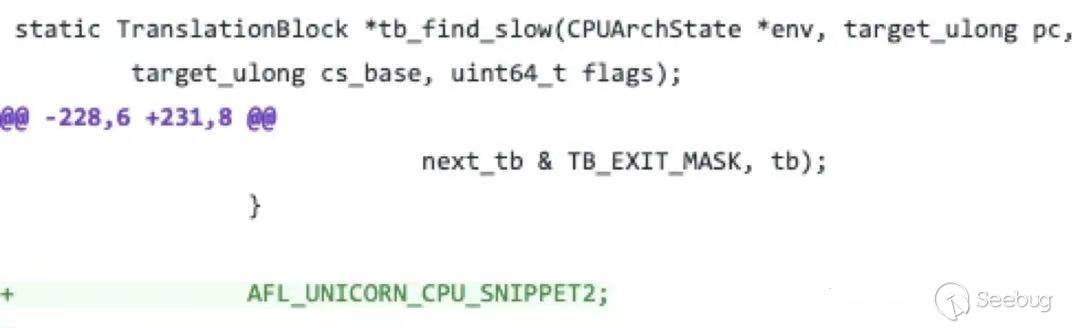

但顯然這個初步的方法有很大的優化空間:
- 在
tb_find_slow中進行記錄意味著必須要禁用block chain caching,也就是說每一個block都需要跳回dispatcher查詢是否被翻譯過。這帶來了巨大的性能回退。 - 缺乏信息回傳機制,新的block/ 新的chain信息無法在多個子進程之間實現共享,避免重復勞動。
針對這兩個問題,abiondo等提出了如下的解決方案:
- 將記錄代碼下沉,遷移到TCG生成中,也就是TCG生成的ops。這樣無論上層如何修改緩存方式,都仍可以精確地實現記錄。
- 通過pipe管道共享translate request。當子進程遇到新的block時,將信息發送給parent,指令parent同樣進行一次翻譯。

加速

就像計算產業的速度曾經被摩爾定律所主導,但當摩爾定律主頻這個檸檬的汁被榨干之后,人們轉向分布式計算和專用芯片(FPGA)。在窮盡當前系統性的措施之后,我們仍可以借用專用計算的概念來優化Fuzzer,也就是說
如果我們關心的只是特定的代碼片段,我們是否仍需要模擬整個完整的Runtime環境?
筆者在MOSEC 2020上介紹的基于Unicorn框架實現的DroidCorn即是基于這個理念編寫的改進版執行框架。它的結構如下圖所示:
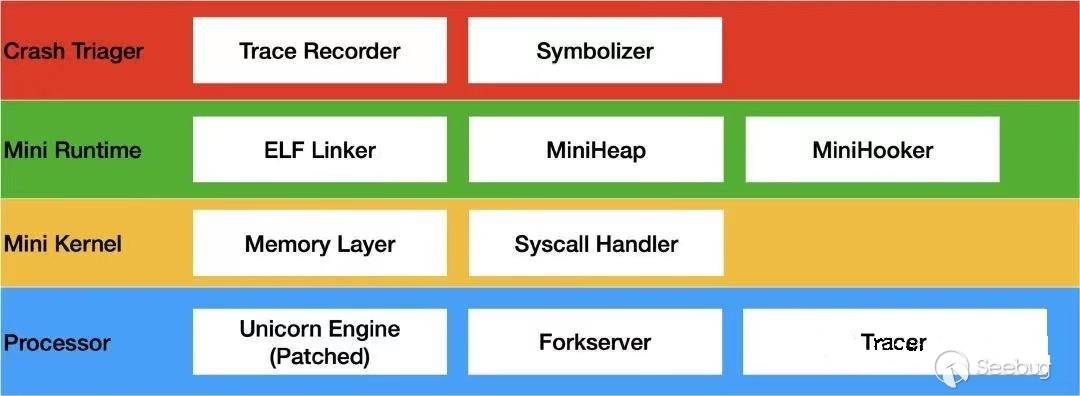
相比于QEMU-usermode,DroidCorn在如下方面進行了重寫,并最終初步獲得了約30%的性能提升。
- 通過Trap的形式實現Hooker,將hot functions例如heap allocators轉移到host端實現,提升熱點區域執行速度。
- 實現最小裁剪版的runtime和syscall handlers,支持跨內核部署和運行,減小運行開銷
- 對syscall等提供沙箱保護和返回值攔截,可用于模擬特定驅動或環境。
這套框架完成了筆者在x86工作站和服務器Linux環境下運行和fuzz ARM binary的目標,在擺脫了物理移動設備的限制之后,我們可以輕松地對其進行大規模并發Fuzz,開拓前人所未到達之領地,發現前人所未發現之漏洞。
加速,加速

當QEMU以上的優化做到極致,我們可能就要考慮優化QEMU本身了。在預先控制流解析的支持下,JIT編譯是否可以被替換為AOT編譯,就像從Dalvik到ART runtime?這是一個開放性的話題,請讀者自行思考。
今日把示君,誰有不平事?
以上介紹了binary fuzzing技術的現狀和筆者的思考、探索和實踐。在接下來的文章中我們將進入實戰環節,針對數億移動手機中所廣泛內置默認使用的閉源圖片解析庫進行fuzz,并分析發現的數十個遠程內存破壞漏洞,i.e. CVE-2020-12751, CVE-2020-25278, CVE-2020-12751, CVE-2021-22493。敬請期待。
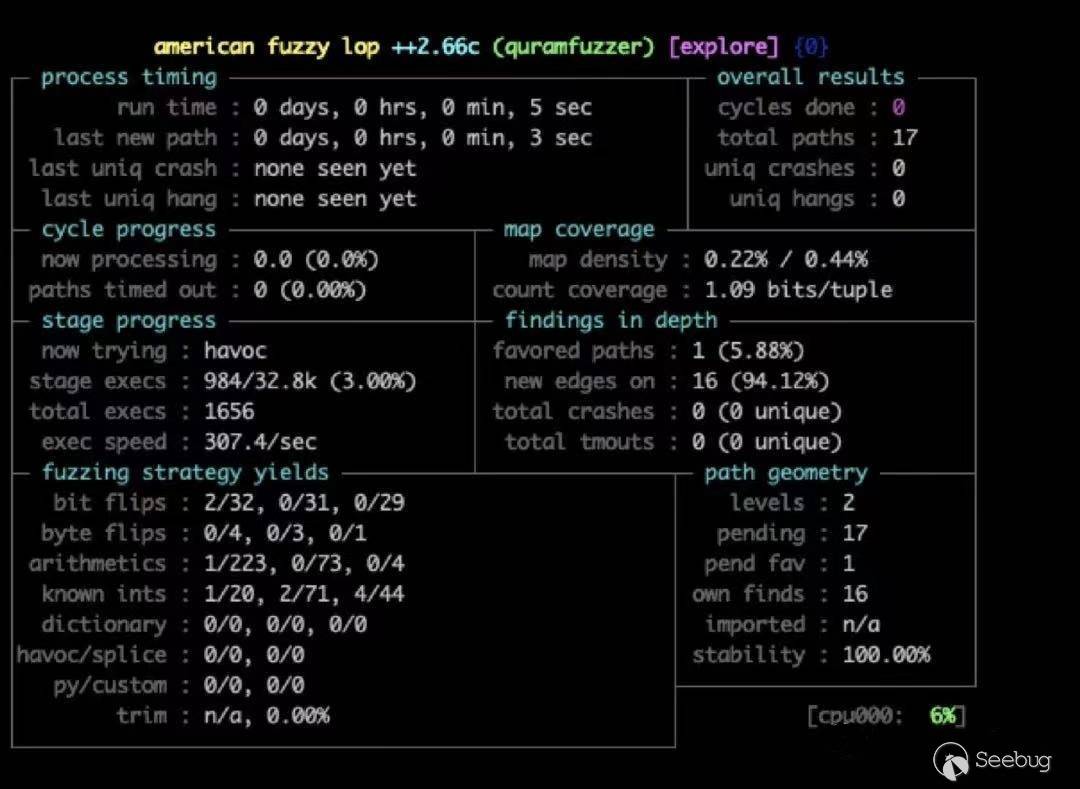
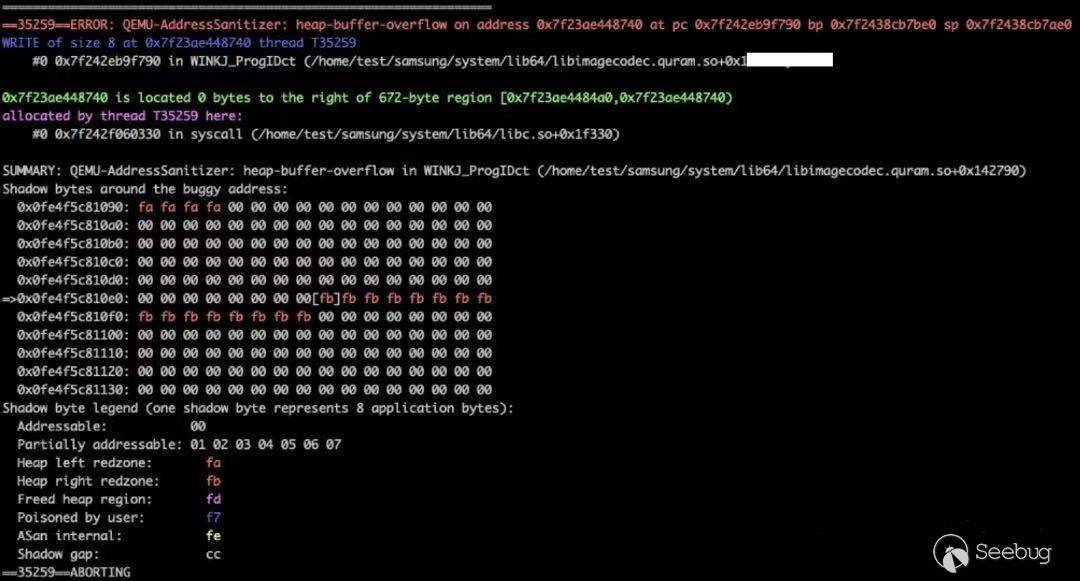
本文所對應的RWCTF 2021 Tech Forum上分享的PPT可以在 https://speakerdeck.com/flankerhqd/blowing-the-cover-of-android-binary-fuzzing查閱。
References
https://github.com/lunixbochs/usercorn
https://github.com/AeonLucid/AndroidNativeEmu
https://github.com/AFLplusplus/AFLplusplus
https://github.com/Battelle/afl-unicorn
https://abiondo.me/2018/09/21/improving-afl-qemu-mode
https://github.com/andreafioraldi/qasan
https://gts3.org/~wen/assets/papers/xu:os-fuzz.pdf
篇后隨筆
數十年前因特網的蠻荒時代,ARPA的先賢們曾滿懷信念,希望能建立一個田園牧歌的大同世界,Richard Stallman至今仍在為了看似瘋癲的信念而奔走呼號。曾經我們以為這個夢想已經越來越近,但撕裂的地緣政治和殘酷的資本迅速消滅了所有的幻想。
曾經的程序員(我更愿意稱為計算機工程師和科學家)是極客,是創作者,是藝術家。開源社區的蓬勃發展是他們靈感的碰撞,才華的閃光,成千上萬人智慧的結晶。但很不幸的是,創作的果實被貪婪地資本所攫取,they are taker not giver,開源驅動的基礎架構技術發展和完善讓手藝人異化成了流水工。精妙的計算科學變成了CRUD的堆需求,嚴謹的數學計算被7*24人肉盯盤取代,每一個電腦配一個人,看是電腦還是人先crash。先賢圖靈和馮諾依曼們若泉下有知,是否會預料到今天的局面?
愿每個人都能有時間看看天空,再次引述下天才黑客GeoHot的一句話:I want power, not power over people, but power over nature and the destiny of technology. I just want to know how the things work.
愿我們仍能記住這段話:
Computer science is the study of algorithmic processes, computational machines and computation itself. As a discipline, computer science spans a range of topics from theoretical studies of algorithms, computation and information to the practical issues of implementing computational systems in hardware and software.
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1465/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1465/
暫無評論