
作者:LoRexxar'@知道創宇404實驗室
時間:2020年9月21日
英文版:http://www.bjnorthway.com/1345/
前言
自從人類發明了工具開始,人類就在不斷為探索如何更方便快捷的做任何事情,在科技發展的過程中,人類不斷地試錯,不斷地思考,于是才有了現代偉大的科技時代。在安全領域里,每個安全研究人員在研究的過程中,也同樣的不斷地探索著如何能夠自動化的解決各個領域的安全問題。其中自動化代碼審計就是安全自動化繞不過去的坎。
這一次我們就一起聊聊自動化代碼審計的發展史,也順便聊聊如何完成一個自動化靜態代碼審計的關鍵。
自動化代碼審計
在聊自動化代碼審計工具之前,首先我們必須要清楚兩個概念,漏報率和誤報率。
- 漏報率是指沒有發現的漏洞/Bug
- 誤報率是指發現了錯誤的漏洞/Bug
在評價下面的所有自動化代碼審計工具/思路/概念時,所有的評價標準都離不開這兩個詞,如何消除這兩點或是其中之一也正是自動化代碼審計發展的關鍵點。
我們可以簡單的把自動化代碼審計(這里我們討論的是白盒)分為兩類,一類是動態代碼審計工具,另一類是靜態代碼審計工具。
動態代碼審計的特點與局限
動態代碼審計工具的原理主要是基于在代碼運行的過程中進行處理并挖掘漏洞。我們一般稱之為IAST(interactive Application Security Testing)。
其中最常見的方式就是通過某種方式Hook惡意函數或是底層api并通過前端爬蟲判別是否觸發惡意函數來確認漏洞。
我們可以通過一個簡單的流程圖來理解這個過程。
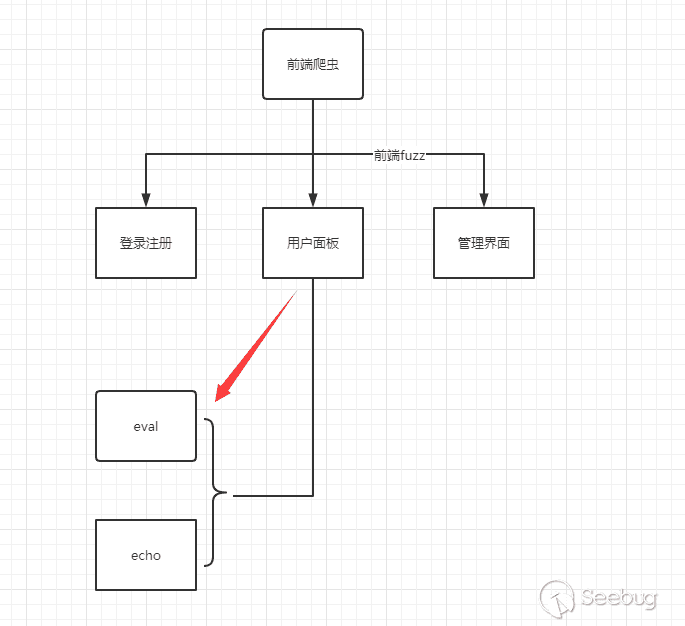
在前端Fuzz的過程中,如果Hook函數被觸發,并滿足某種條件,那么我們認為該漏洞存在。
這類掃描工具的優勢在于,通過這類工具發現的漏洞誤報率比較低,且不依賴代碼,一般來說,只要策略足夠完善,能夠觸發到相應惡意函數的操作都會相應的滿足某種惡意操作。而且可以跟蹤動態調用也是這種方法最主要的優勢之一。
但隨之而來的問題也逐漸暴露出來:
(1) 前端Fuzz爬蟲可以保證對正常功能的覆蓋率,卻很難保證對代碼功能的覆蓋率。
如果曾使用動態代碼審計工具對大量的代碼掃描,不難發現,這類工具針對漏洞的掃描結果并不會比純黑盒的漏洞掃描工具有什么優勢,其中最大的問題主要集中在功能的覆蓋度上。
一般來說,你很難保證開發完成的所有代碼都是為網站的功能服務的,也許是在版本迭代的過程中不斷地冗余代碼被遺留下來,也有可能是開發人員根本沒有意識到他們寫下的代碼并不只是會按照預想的樣子執行下去。有太多的漏洞都無法直接的從前臺的功能處被發現,有些甚至可能需要滿足特定的環境、特定的請求才能觸發。這樣一來,代碼的覆蓋率得不到保證,又怎么保證能發現漏洞呢?
(2) 動態代碼審計對底層以及hook策略依賴較強
由于動態代碼審計的漏洞判別主要依賴Hook惡意函數,那么對于不同的語言、不同的平臺來說,動態代碼審計往往要針對設計不同的hook方案。如果Hook的深度不夠,一個深度框架可能就無法掃描了。
拿PHP舉例子來說,比較成熟的Hook方案就是通過PHP插件實現,具體的實現方案可以參考。
由于這個原因影響,一般的動態代碼審計很少可以同時掃描多種語言,一般來說都是針對某一種語言。
其次,Hook的策略也需要許多不同的限制以及處理。就拿PHP的XSS來舉例子,并不是說一個請求觸發了echo函數就應該判別為XSS。同樣的,為了不影響正常功能,并不是echo函數參數中包含<script>就可以算XSS漏洞。在動態代碼審計的策略中,需要有更合理的前端->Hook策略判別方案,否則會出現大量的誤報。
除了前面的問題以外,對環境的強依賴、對執行效率的需求、難以和業務代碼結合的各種問題也確切的存在著。當動態代碼審計的弊端不斷被暴露出來后,從筆者的角度來看,動態代碼審計存在著原理本身與問題的沖突,所以在自動化工具的發展過程中,越來越多的目光都放回了靜態代碼審計上(SAST).
靜態代碼審計工具的發展
靜態代碼審計主要是通過分析目標代碼,通過純靜態的手段進行分析處理,并挖掘相應的漏洞/Bug.
與動態不同,靜態代碼審計工具經歷了長期的發展與演變過程,下面我們就一起回顧一下(下面的每個時期主要代表的相對的發展期,并不是比較絕對的誕生前后):
上古時期 - 關鍵字匹配
如果我問你“如果讓你設計一個自動化代碼審計工具,你會怎么設計?”,我相信,你一定會回答我,可以嘗試通過匹配關鍵字。緊接著你也會迅速意識到通過關鍵字匹配的問題。
這里我們拿PHP做個簡單的例子。

雖然我們匹配到了這個簡單的漏洞,但是很快發現,事情并沒有那么簡單。

也許你說你可以通過簡單的關鍵字重新匹配到這個問題。
\beval\(\$但是可惜的是,作為安全研究員,你永遠沒辦法知道開發人員是怎么寫代碼的。于是選擇用關鍵字匹配的你面臨著兩種選擇:
- 高覆蓋性 – 寧錯殺不放過
這類工具最經典的就是Seay,通過簡單的關鍵字來匹配經可能多的目標,之后使用者可以通過人工審計的方式進一步確認。
\beval\b\(- 高可用性 – 寧放過不錯殺
這類工具最經典的是Rips免費版
\beval\b\(\$_(GET|POST)用更多的正則來約束,用更多的規則來覆蓋多種情況。這也是早期靜態自動化代碼審計工具普遍的實現方法。
但問題顯而易見,高覆蓋性和高可用性是這種實現方法永遠無法解決的硬傷,不但維護成本巨大,而且誤報率和漏報率也是居高不下。所以被時代所淘汰也是歷史的必然。
近代時期 - 基于AST的代碼分析
有人忽略問題,也有人解決問題。關鍵字匹配最大的問題是在于你永遠沒辦法保證開發人員的習慣,你也就沒辦法通過任何制式的匹配來確認漏洞,那么基于AST的代碼審計方式就誕生了,開發人員是不同的,但編譯器是相同的。
在分享這種原理之前,我們首先可以復現一下編譯原理。拿PHP代碼舉例子:
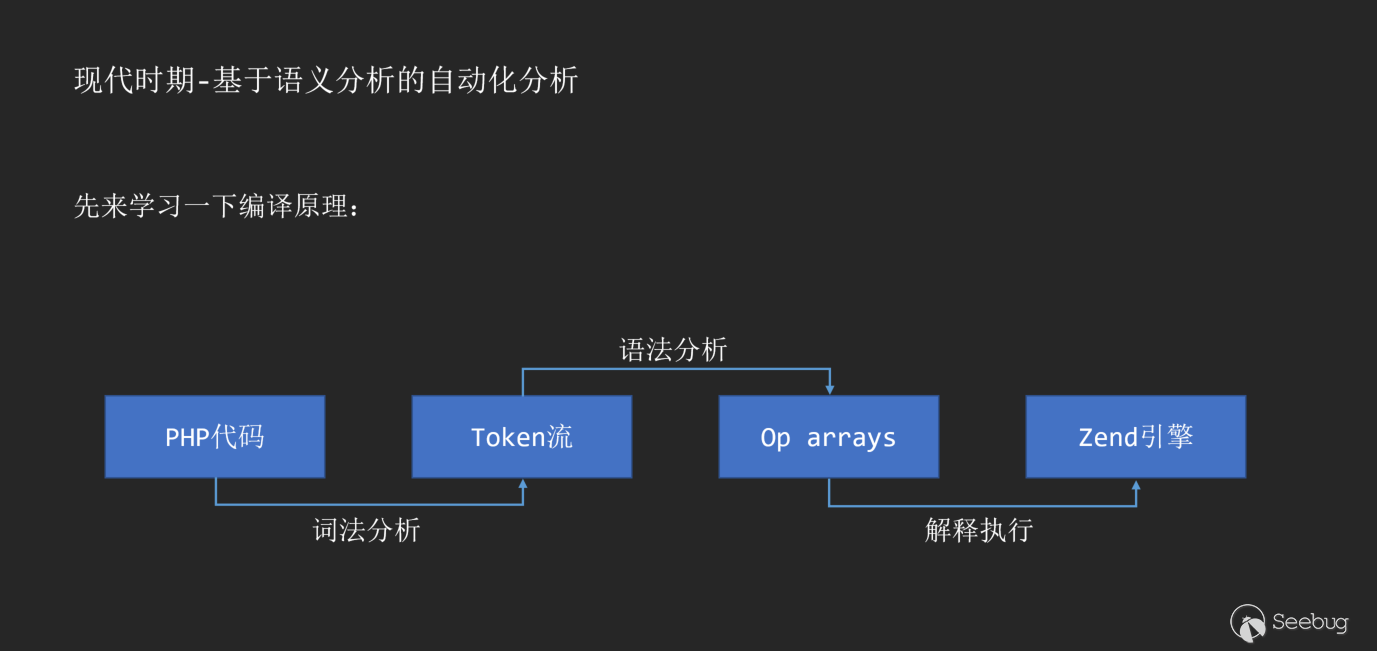
隨著PHP7的誕生,AST也作為PHP解釋執行的中間層出現在了編譯過程的一環。
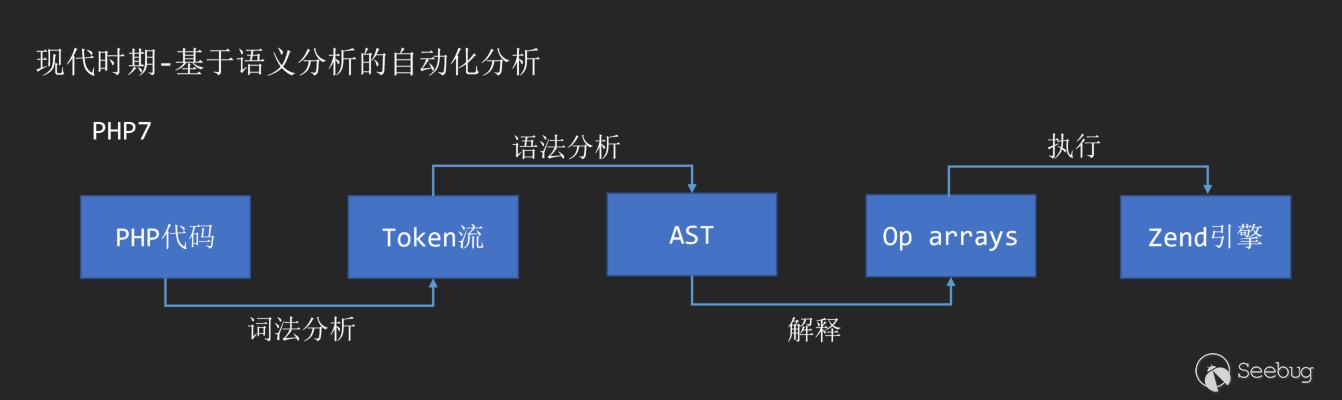
通過詞法分析和語法分析,我們可以將任意一份代碼轉化為AST語法樹。常見的語義分析庫可以參考:
當我們得到了一份AST語法樹之后,我們就解決了前面提到的關鍵字匹配最大的問題,至少我們現在對于不同的代碼,都有了統一的AST語法樹。如何對AST語法樹做分析也就成了這類工具最大的問題。
在理解如何分析AST語法樹之前,我們首先要明白information flow、source、sink三個概念,
- source: 我們可以簡單的稱之為輸入,也就是information flow的起點
- sink: 我們可以稱之為輸出,也就是information flow的終點
而information flow,則是指數據在source到sink之間流動的過程。
把這個概念放在PHP代碼審計過程中,Source就是指用戶可控的輸入,比如$_GET、$_POST等,而Sink就是指我們要找到的敏感函數,比如echo、eval,如果某一個Source到Sink存在一個完整的流,那么我們就可以認為存在一個可控的漏洞,這也就是基于information flow的代碼審計原理。
在明白了基礎原理的基礎上,我舉幾個簡單的例子:

在上面的分析過程中,Sink就是eval函數,source就是$_GET,通過逆向分析Sink的來源,我們成功找到了一條流向Sink的information flow,也就成功發現了這個漏洞。
ps: 當然也許會有人好奇為什么選擇逆向分析流而不是正向分析流,這個問題會在后續的分析過程中不斷滲透,慢慢就可以明白其關鍵點。
在分析information flow的過程中,明確作用域是基礎中的基礎.這也是分析information flow的關鍵,我們可以一起看看一段簡單的代碼
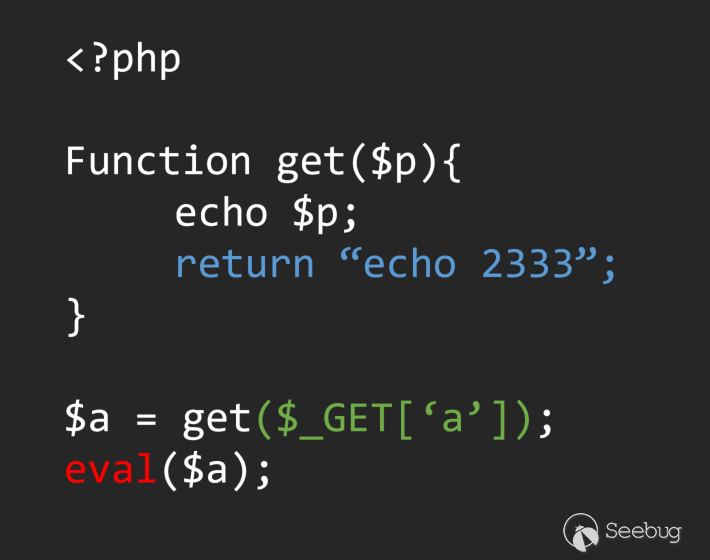
如果我們很簡單的通過左右值去回溯,而沒有考慮到函數定義的話,我們很容易將流定義為:
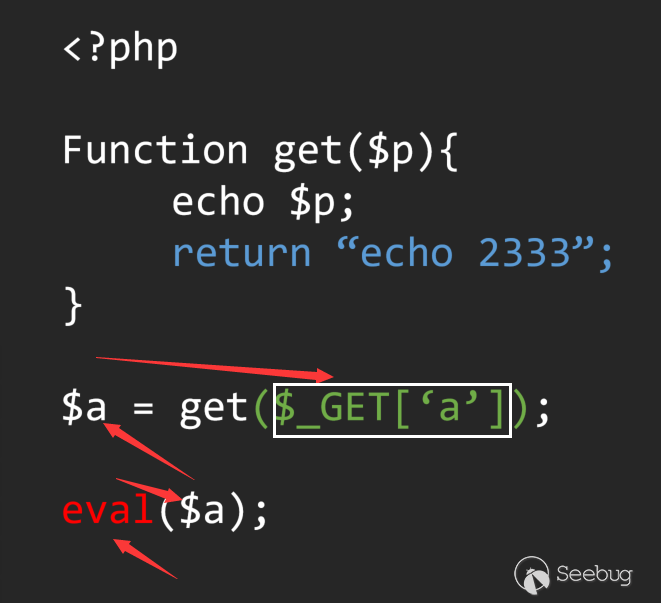
這樣我們就錯誤的把這段代碼定義成了存在漏洞,但很顯然并不是,而正確的分析流程應該是這樣的:
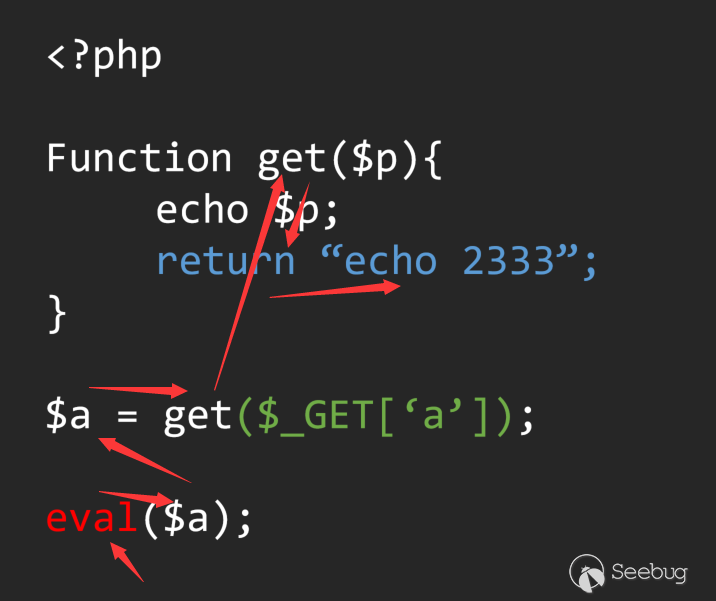
在這段代碼中,從主語法樹的作用域跟到Get函數的作用域,如何控制這個作用域的變動,就是基于AST語法樹分析的一大難點,當我們在代碼中不可避免的使用遞歸來控制作用域時,在多層遞歸中的統一標準也就成了分析的基礎核心問題。
事實上,即便你做好了這個最簡單的基礎核心問題,你也會遇到層出不窮的問題。這里我舉兩個簡單的例子
(1) 新函數封裝

這是一段很經典的代碼,敏感函數被封裝成了新的敏感函數,參數是被二次傳遞的。為了解決,這樣information flow的方向從逆向->正向的問題。

通過新建大作用域來控制作用域。
(2) 多重調用鏈

這是一段有漏洞的JS代碼,人工的話很容易看出來問題。但是如果通過自動化的方式回溯參數的話就會發現整個流程中涉及到了多種流向。
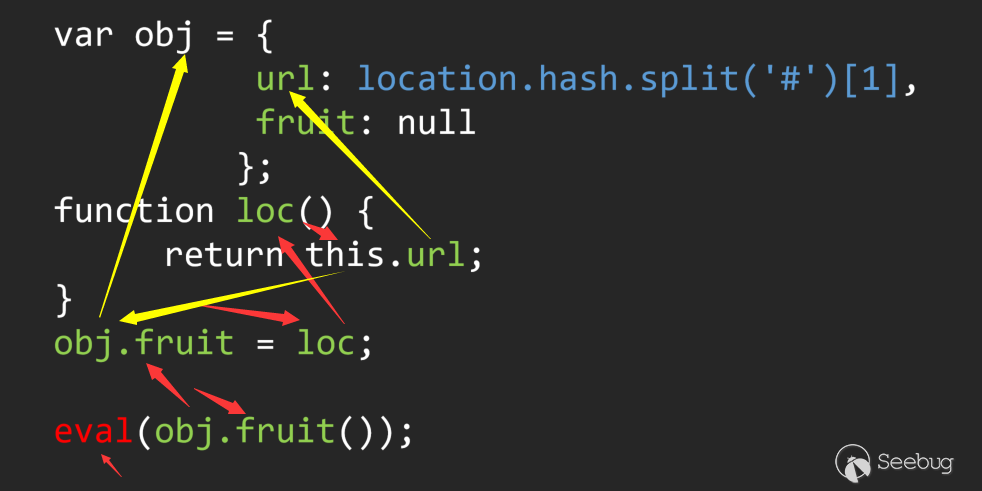
這里我用紅色和黃色代表了流的兩種流向。要解決這個問題只能通過針對類/字典變量的特殊回溯才能解決。
如果說,前面的兩個問題是可以被解決的話,還有很多問題是沒辦法被解決的,這里舉一個簡單的例子。

這是一個典型的全局過濾,人工審計可以很容易看出這里被過濾了。但是如果在自動化分析過程中,當回溯到Source為$_GET['a']時,已經滿足了從Source到sink的information flow。已經被識別為漏洞。一個典型的誤報就出現了。
而基于AST的自動化代碼審計工具也正是在與這樣的問題做博弈,從PHP自動化代碼審計中比較知名的Rips、Cobra再到我自己二次開發的Cobra-W.
- https://www.ripstech.com/
- https://github.com/WhaleShark-Team/cobra
- https://github.com/LoRexxar/Kunlun-M
都是在不同的方式方法上,優化information flow分析的結果,而最大的區別則是離不開的高可用性、高覆蓋性兩點核心。
- Cobra是由蘑菇街安全團隊開發的側重甲方的靜態自動化代碼掃描器,低漏報率是這類工具的核心,因為甲方不能承受沒有發現的漏洞的后果,這也是這類工具側重優化的關鍵。
在我發現沒有可能完美的回溯出每一條流的過程之后,我將工具的定位放在白帽子自用上,從開始的Cobra-W到后期的KunLun-M,我都側重在低誤報率上,只有準確可靠的流我才會認可,否則我會將他標記為疑似漏洞,并在多環定制了自定義功能以及詳細的log日志,以便安全研究人員在使用的過程中可以針對目標多次優化掃描。
對于基于AST的代碼分析來說,最大的挑戰在于沒人能保證自己完美的處理所有的AST結構,再加上基于單向流的分析方式,無法應對100%的場景,這也正是這類工具面臨的問題(或者說,這也就是為什么選擇逆向的原因)。
基于IR/CFG的代碼分析
如果深度了解過基于AST的代碼分析原理的話,不然發現AST的許多弊端。首先AST是編譯原理中IR/CFG的更上層,其ast中保存的節點更接近源代碼結構。
也就是說,分析AST更接近分析代碼,換句話就是說基于AST的分析得到的流,更接近腦子里對代碼執行里的流程,忽略了大多數的分支、跳轉、循環這類影響執行過程順序的條件,這也是基于AST的代碼分析的普遍解決方案,當然,從結果論上很難辨別忽略帶來的后果。所以基于IR/CFG這類帶有控制流的解決方案,是現在更主流的代碼分析方案,但不是唯一。
首先我們得知道什么是IR/CFG。 - IR:是一種類似于匯編語言的線性代碼,其中各個指令按照順序執行。其中現在主流的IR是三地址碼(四元組) - CFG: (Control flow graph)控制流圖,在程序中最簡單的控制流單位是一個基本塊,在CFG中,每一個節點代表一個基本塊,每一個邊代表一個可控的控制轉移,整個CFG代表了整個代碼的的控制流程圖。
一般來說,我們需要遍歷IR來生成CFG,其中需要按照一定的規則,不過不屬于這里的主要內容就暫且不提。當然,你也可以用AST來生成CFG,畢竟AST是比較高的層級。
而基于CFG的代碼分析思路優勢在于,對于一份代碼來說,你首先有了一份控制流圖(或者說是執行順序),然后才到漏洞挖掘這一步。比起基于AST的代碼分析來說,你只需要專注于從Source到Sink的過程即可。
建立在控制流圖的基礎上,后續的分析流程與AST其實別無太大的差別,挑戰的核心仍然維持在如何控制流,維持作用域,處理程序邏輯的分支過程,確認Source與Sink。
理所當然的是,既然存在基于AST的代碼分析,又存在基于CFG的代碼分析,自然也存在其他的種類。比如現在市場上主流的fortify,Checkmarx,Coverity包括最新的Rips都使用了自己構造的語言的某一個中間部分,比如fortify和Coverity就需要對源碼編譯的某一個中間語言進行分析。前段時間被阿里收購的源傘甚至實現了多種語言生成統一的IR,這樣一來對于新語言的掃描支持難度就變得大大減少了。
事實上,無論是基于AST、CFG或是某個自制的中間語言,現代代碼分析思路也變得清晰起來,針對統一的數據結構已經成了現代代碼分析的基礎。
未來 - QL概念的出現
QL指的是一種面向對象的查詢語言,用于從關系數據庫中查詢數據的語言。我們常見的SQL就屬于一種QL,一般用于查詢存儲在數據庫中的數據。
而在代碼分析領域,Semmle QL是最早誕生的QL語言,他最早被應用于LGTM,并被用于Github內置的安全掃描為大眾免費提供。緊接著,CodeQL也被開發出來,作為穩定的QL框架在github社區化。
那么什么是QL呢?QL又和代碼分析有什么關系呢?
首先我們回顧一下基于AST、CFG這類代碼分析最大的特點是什么?無論是基于哪種中間件建立的代碼分析流程,都離不開3個概念,流、Source、Sink,這類代碼分析的原理無論是正向還是逆向,都是通過在Source和Sink中尋找一條流。而這條流的建立圍繞的是代碼執行的流程,就好像編譯器編譯運行一樣,程序總是流式運行的。這種分析的方式就是數據流分析(Data Flow)。
而QL就是把這個流的每一個環節具象化,把每個節點的操作具像成狀態的變化,并且儲存到數據庫中。這樣一來,通過構造QL語言,我們就能找到滿足條件的節點,并構造成流。下面我舉一個簡單的例子來說:
<?php
$a = $_GET['a'];
$b = htmlspecialchars($a);
echo $b;我們簡單的把前面的流寫成一個表達式
echo => $_GET.is_filterxss這里is_filterxss被認為是輸入$_GET的一個標記,在分析這類漏洞的時候,我們就可以直接用QL表達
select * where {
Source : $_GET,
Sink : echo,
is_filterxss : False,
}我們就可以找到這個漏洞(上面的代碼僅為偽代碼),從這樣的一個例子我們不難發現,QL其實更接近一個概念,他鼓勵將信息流具象化,這樣我們就可以用更通用的方式去寫規則篩選。
也正是建立在這個基礎上,CodeQL誕生了,它更像是一個基礎平臺,讓你不需要在操心底層邏輯,使用AST還是CFG又或是某種平臺,你可以將自動化代碼分析簡化約束為我們需要用怎么樣的規則來找到滿足某個漏洞的特征。這個概念也正是現代代碼分析主流的實現思路,也就是將需求轉嫁到更上層。
聊聊KunLun-M
與大多數的安全研究人員一樣,我從事的工作涉及到大量的代碼審計工作,每次審計一個新的代碼或者框架,我都需要花費大量的時間成本熟悉調試,在最初接觸到自動化代碼審計時,也正是希望能幫助我節省一些時間。
我接觸到的第一個項目就是蘑菇街團隊的Cobra
這應該是最早開源的甲方自動化代碼審計工具,除了一些基礎的特征掃描,也引入了AST分析作為輔助手段確認漏洞。
在使用的過程中,我發現Cobra初版在AST上的限制實在太少了,甚至include都沒支持(當時是2017年),于是我魔改出了Cobra-W,并刪除了其中大量的開源漏洞掃描方案(例如掃描java的低版本包),以及我用不上的甲方需求等...并且深度重構了AST回溯部分(超過上千行代碼),重構了底層的邏輯使之兼容windows。
在長期的使用過程中,我遇到了超多的問題與場景(我為了復現Bug寫的漏洞樣例就有十幾個文件夾),比較簡單的就比如前面漏洞樣例里提到的新函數封裝,最后新加了大遞歸邏輯去新建掃描任務才解決。還有遇到了Hook的全局輸入、自實現的過濾函數、分支循環跳轉流程等各類問題,其中我自己新建的Issue就接近40個...
為了解決這些問題,我照著phply的底層邏輯,重構了相應的語法分析邏輯。添加了Tamper的概念用于解決自實現的過濾函數。引入了python3的異步邏輯優化了掃描流程等...
也正是在維護的過程中,我逐漸學習到現在主流的基于CFG的代碼分析流程,也發現我應該基于AST自實現了一個CFG分析邏輯...直到后來Semmle QL的出現,我重新認識到了數據流分析的概念,這些代碼分析的概念在維護的過程中也在不斷地影響著我。
在2020年9月,我正式將Cobra-W更名為KunLun-M,在這一版本中,我大量的剔除了正則+AST分析的邏輯,因為這個邏輯違背了流式分析的基礎,然后新加了Sqlite作為數據庫,添加了Console模式便于使用,同時也公開了我之前開發的有關javascript代碼的部分規則。
KunLun-M可能并不是什么有技術優勢的自動化代碼審計工具,但卻是唯一的仍在維護的開源代碼審計工具,在多年研究的過程中,我深切的體會到有關白盒審計的信息壁壘,成熟的白盒審計廠商包括fortify,Checkmarx,Coverity,rips,源傘掃描器都是商業閉源的,國內的很多廠商白盒團隊都還在起步,很多東西都是摸著石頭過河,想學白盒審計的課程這些年我也只見過南京大學的《軟件分析》,很多東西都只能看paper...也希望KunLun-M的開源和這篇文章也能給相應的從業者帶來一些幫助。
同時,KunLun-M也作為星鏈計劃的一員,秉承開放開源、長期維護的原則公開,希望KunLun-M能作為一顆星星鏈接每一個安全研究員。
星鏈計劃地址: - https://github.com/knownsec/404StarLink-Project
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1339/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1339/