
作者:果勝
本文為作者投稿,Seebug Paper 期待你的分享,凡經采用即有禮品相送!
投稿郵箱:paper@seebug.org
目前在威脅情報領域基于機器學習的數據分析技術已經的得到了很多應用,諸多安全廠商和團隊都開始建立相關的機器學習模型用于威脅的檢測和相關數據的分析。其中自然語言處理(NLP)相關技術在惡意代碼檢測,樣本分析,威脅情報抽取與建模中有著重要的地位,本文主要梳理和介紹一些NLP技術在威脅情報中的應用場景與相關概念和技術,以供參考。
典型應用場景
NLP技術的安全應用多在于文本類數據的分析以及序列問題的處理,例如對HTTP協議傳輸數據的安全檢測等,這里選取一些典型場景予以介紹。
惡意腳本代碼檢測
腳本代碼(bash/powershell/sql/js等)不必編譯即可執行,故而與二進制惡意代碼分析不同,對腳本代碼本身進行語義分析即可判定其性質。嚴格來說,對程序語言進行語義分析不屬于NLP技術(自然語言處理)的范疇,但是NLP的相關技術可以有效的解決問題。例如,對HTTP協議參數進行語義分析,判斷其文本是否符合sql/js語法,從而確認參數是否為sqli/xss payload。與傳統的基于規則的方法相比,基于機器學習NLP的方法對于未知數據的檢測(機器學習有更好的泛化能力)和混淆后代碼的檢測(混淆本身不破壞語法結構)有更好的效果。不過NLP技術并不萬能,分詞技術的弱點和機器學習模型本身的不精確性會影響其最后的效果,仍需要結合規則使用。
二進制樣本分析
對于二進制樣本分析人員來說,反匯編后的程序某種程度可視為一個由匯編指令,以及指令塊控制流構成的序列。目前一些安全研究者試圖通過NLP技術解析反匯編序列,從而完成提取惡意代碼的特征片段,檢查二進制樣本相似度和家族關系等工作。這方面的應用在AAAI-20大會上有精彩的分析,可以參考。
威脅情報生產與建模
對安全人員來說威脅情報可能存在多個來源,依據其格式不同,可劃分為結構化數據(已經過表結構處理,便于機器識別)和非結構化數據(主要為自然語言等數據)。通過NLP技術對非結構化數據進行處理,可以提取出其中的關鍵知識,邏輯關系等信息并轉化為結構化數據,從而用于生產可以被機器直接使用的機讀情報或作為威脅建模的素材。例如semfuzz工具即通過對linux安全公告,git更新日志等信息進行NLP處理,提取其中的版本,API名稱,變量名等關鍵信息,并以此構建精確的fuzz工程,提高發現漏洞的效率。
特征工程
計算機對文本數據進行處理,需要將文本序列轉化為由數值構成的數據,這一把文本變為特征數據的過程稱為特征工程。此處簡要介紹一些NLP特征工程的關鍵概念。
分詞
分詞是指將文本內容轉化為詞序列的過程,只有通過分詞計算機才能明確將文本數值化的最小處理單位,樣例如下:
import nltk
text = nltk.word_tokenize("This is an exmaple.")
print(text)
['This', 'is', 'an', 'exmaple', '.']可見代碼對目標以空格和標點符號為邊界切割了整句話。分詞是整個NLP技術的基礎,分詞的水平對最終的結果有很大影響。對于不同類型的文本需要設計獨立的分詞方式,例如對html文本的分詞即需要以<>或html標簽為邊界進行切割,才可能得到可以被正確處理的詞序列。
詞袋模型
詞袋模型是一種基于詞匯出現次數將詞序列數值化的方法,詞袋模型通過計算單個詞匯在文本中出現的次數來表示一個詞序列,例如對以下文本:
This is an apple.This is a banana.
可以形成一個如下的詞空間
['This','is','an','a','apple','banana']
在這個詞空間中,可以將兩句話的詞序列分別用詞袋模型表示為如下數值:
[1,1,1,0,1,0] #['This','is','an','apple']
[1,1,0,1,0,1] #['This','is','a','banana']
詞袋模型將每個詞序列按照詞匯出現次數表示,完成了文本向數據的轉化。
TF-IDF模型
簡單的利用詞匯出現次數表示詞序列存在無法完全反映詞匯重要程度的缺陷,例如’to‘,’and‘一類的詞匯會具有很高的詞頻,為了修正這一缺陷,可以使用tf-idf模型,該模型對某一詞匯計算數值的公式如下:
TF(詞頻) = 詞匯在文本中出現次數/文本總詞數
IDF(逆文件頻率) = log(語料庫文本總數/包含某個詞的文本數+1)
TF-IDF = TF * IDF
TF-IDF模型的核心思想在于以詞匯在某個文本中的重要性來對詞匯進行數值化,即由某個詞在文本中出現的頻率(TF)和該詞匯在所有文本中出現的概率(IDF)共同決定,TF越高且同時IDF越低,說明某一詞匯在某一文本中越重要。TF-IDF模型常常用于文本關鍵詞提取和搜索引擎技術中。
詞向量模型
詞袋模型和TF-IDF模型本質上均為基于詞頻的模型,此類模型忽略了詞序列中的先后關系,無法反映某個詞匯的上下文對詞匯意義的影響。為了修正這一缺陷,可以通過詞向量的方式來表征一個詞匯,詞向量模型建立在一個基本假設上:具有相似上下文詞匯的具有相似語義。以經典的詞向量word2vec為例,通過訓練一個以詞匯的one-hot形式向量為輸入(ont-hot編碼是一種將詞匯以字母為單位轉化成定長數據的方法)的神經網絡,可以得到文本的詞向量,主要模型有如下兩種:
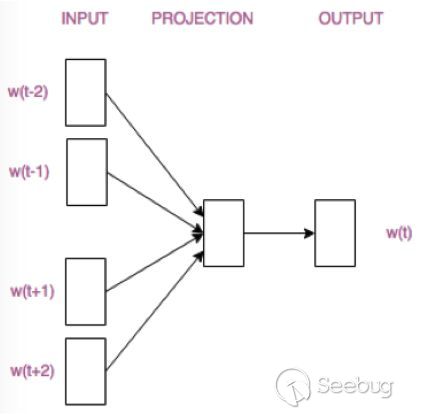
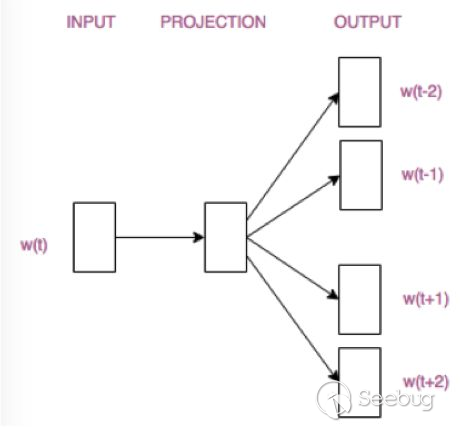
其中CBOW模型以某一詞匯的上下文作為輸入,預測上下問對應的詞匯,而Skip-Gram模型以某一詞匯作為輸入,預測該詞匯對應的上下文。在最終完成訓練之后,神經網絡隱藏層的矩陣權重(隱藏層可以參見深度學習的內容),即為所得的詞向量。
由于在訓練詞向量的過程中使用了詞匯的上下文信息,因而詞向量本身即包含了詞匯的語義信息,一個詞向量在低維空間中的演示圖如下:
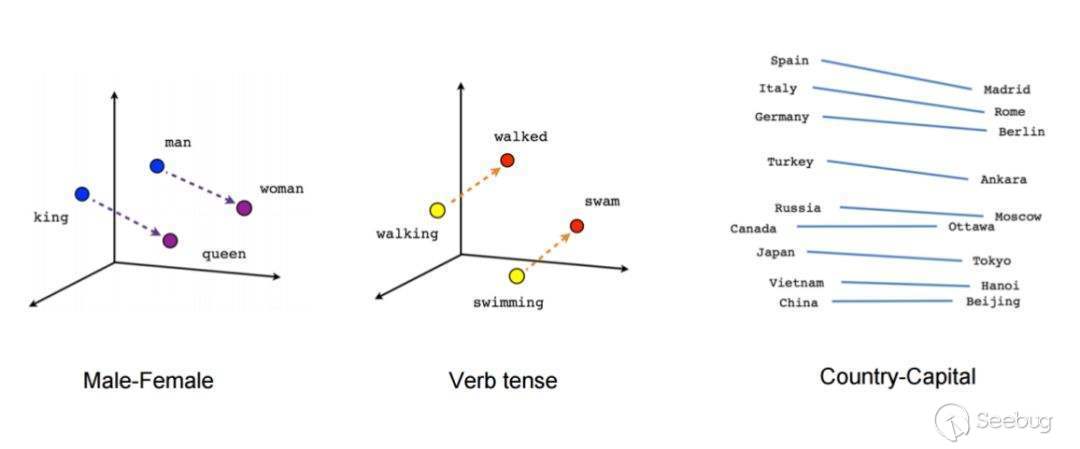
可以發現具有相似映射關系的詞匯構成的向量幾乎是平行的,這也是語義在詞向量空間中具體的表現形式。因而通過詞向量進行特征工程處理的文本,在需要上下文信息和相似度的場景下有更好的表現。在word2vec之后,還提出了fasttext,bert等模型,這些模型的基本思想都比較類似,在此不一一介紹。目前主流的NLP工具包中均提供了詞向量API,可以方便的對文本進行處理。
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
corpus = 'corpus.txt' #語料文本
#對出現超過兩次的詞匯,以前后3個詞匯為上下文訓練次向量
w2v_model = Word2Vec(LineSentence(corpus),window=3,min_count=2)
wordvector = []
for key in w2v_model.wv.vocab.keys():
#逐一獲取每個詞匯的對應詞向量
wordvector.append(w2v_model[key])關鍵詞提取
文本挖掘是一個與NLP技術有交叉的領域,其目的是通過對文本數據進行挖掘,獲取其中關鍵的知識和信息,在文本特征分析和安全情報提取中,關鍵詞提取的一些算法有較好的表現。例如對反序列化或二進制數據應用關鍵詞提取的方法進行分析,可以在缺少安全樣本的情況下發現其中存在異常的payload和shellcode。在此簡要介紹一些關鍵詞提取技術。
textrank
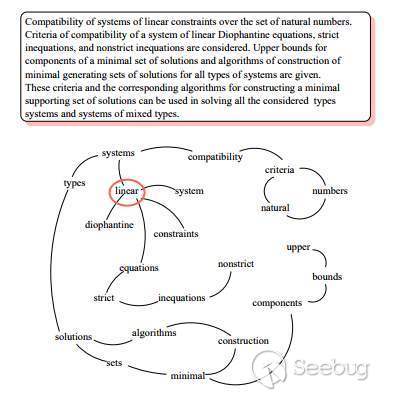
textrank算法來自與用于計算網頁排名的pagerank算法,其思路是首先以N(N>0)為窗口,將文本轉換為一個由詞匯與前后N個詞匯構成的網絡(結構與由鏈接相互關聯的網頁相似),如圖:
然后對每個節點計算計算權重,其思路為某個詞匯的權重等于其相鄰詞匯的加權排名之和 ,公式為:
其中WS表示了某詞匯的權重,In(Vi)表示該詞匯之前相鄰詞匯,Out(Vj)表示該詞匯之后相鄰詞匯,d用于平滑函數,W(ji)表示某一關系的權重。從公式可見,任何一個詞匯的權重都由其上下文的權重決定,故而該算法需要從零開始,在網絡中反復傳播迭代以獲取最終的結果。在各詞匯權重均求出后,即可對詞匯按權重排序,并將結果中相鄰的詞匯合并以獲取關鍵詞。 作為一種無監督算法,textrank的優勢在于無需樣本訓練即可在目標上使用。且該算法適用于任意長度的文本。故而在分析一些中短長度的數據時,有不錯的表現。
LDA
LDA算法是一種依據概率求解文本中關鍵詞的算法。其出發點是認為文本中的任意一個詞匯都是根據一定概率從某個主題中選擇的,而任意一個主題都是根據一定概率被文本選擇的,即:
$P(詞匯|文檔) = \sum_{主題}{p(詞匯|主題)*p(主題|文檔)}$
LDA算法則從這一思路反向計算歸于某一主題的關鍵詞,LDA算法本身比較復雜,在此不做詳述。目前主流的機器學習工具包也都提供了這一重要的算法。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from nltk.corpus import stopwords
corpus = 'What are some of the real world uses topic modelling has? Historians can use LDA to identify important events in history by analysing text based on year. Web based libraries can use LDA to recommend books based on your past readings. News providers can use topic modelling to understand articles quickly or cluster similar articles. Another interesting application is unsupervised clustering of images, where each image is treated similar to a document.'
#使用詞袋模型對文本特征工程
cntVector = CountVectorizer(stop_words=stopwords.words('english'))
cntTf = cntVector.fit_transform([corpus])
#假設目標文本有5個主題
lda = LatentDirichletAllocation(n_components=1)
docres = lda.fit_transform(cntTf) #使用lda算法計算關鍵詞
def print_top_words(model, feature_names, n_top_words):
#打印每個主題下權重較高的term
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
n_top_words=6
tf_feature_names = cntVector.get_feature_names()
print_top_words(lda, tf_feature_names, n_top_words)結果:
Topic #0:
based use similar modelling topic ldaLDA算法也是一種無監督學習算法,無需樣本訓練即可在目標上使用。不過由于其需要對詞頻進行計算,故算法在較長的文本中會有更好的效果。
聚類提取
聚類算法是一類無監督學習算法,主要指自動將沒有標記的數據劃分為幾類的方法。在前文中提到word2vec等詞向量模型可以在向量空間中更好的反應語義信息。故可以通過對文本中的詞向量進行聚類分析,將文本中的詞匯劃分為不同類別,并根據詞頻從不同的類別中選取關鍵詞。目前主要的聚類算法分為基于劃分、基于層次、基于密度、基于網格和基于模型等類型。在詞向量聚類的場景下,詞向量通過余弦相似度(即兩個詞向量的cos值)反映了語義的相似度,而由于歸一化后的cos距離和歐式距離(即兩個坐標點的直線距離)線性相關,故可以通過基于劃分的方法對數據進行聚類(基于劃分的方法主要依靠計算距離來評估兩個數據間的相關性),在此對其中較知名的kmeans方法做介紹。
-
選取k個對象作為每一個簇的中心;
-
計算其他對象與各簇中心的距離,并將其歸類到最近的簇;
-
計算每個簇的距離平均值,更新簇中心;
-
不斷重復2、3
一個demo如下:
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
#語料
sentences = [['this', 'is', 'a', 'pear'],
['this', 'is', 'a','banana'],
['this', 'is', 'an','apple'],
['this','is','a','lemon'],
['this','is','a','melon'],
['this','is','a','cherry']]
#訓練詞向量
model = Word2Vec(sentences, min_count=1)
wordvector = []
for key in model.wv.vocab.keys():
#逐一獲取每個詞匯的對應詞向量
wordvector.append(model[key])
#通過余弦相似度獲取與apple最近義的詞
print (model.most_similar(positive=['apple'], negative=[], topn=2))
#結果為[('is', 0.19642898440361023), ('pear', 0.15730774402618408)]
#可見出現了pear,但仍有改善的余地
#使用kmeans算法對語料進行聚類,共分為2類
clf = KMeans(n_clusters=2)
clf.fit(wordvector)
labels = clf.labels_
classCollects={}
keys = model.wv.vocab.keys()
for i in range(len(keys)):
if labels[i] in list(classCollects.keys()):
classCollects[labels[i]].append(list(keys)[i])
else:
classCollects={0:[],1:[]}
print(classCollects[0])
print(classCollects[1]))
'''
結果為:
['pear', 'banana', 'apple', 'lemon', 'melon']
['is', 'a', 'an', 'cherry']
'''對詞向量聚類在理論上有很好的潛力,但在實踐中也存在問題(在demo中也有體現)。其一是kmeans算法中初始選取的中心對最后的結果有一定影響;其二是詞向量一般維度很高,而基于距離的聚類算法在高維空間的表現會有所下降(降維過度又會造成向量損失必要的信息)。故而詞向量聚類在實際使用中需要根據具體場景做優化。
命名實體識別
命名實體識別是NLP技術中的重要組成部分,其目的是識別出文本當中的特定實體,并進而將其中的關鍵信息抽取出來,從而將非結構化的文本數據轉換為結構化的可機讀數據,為各類自動化任務提供數據支撐。在威脅建模或情報分析當中,命名實體識別可以快速的把關鍵信息從多個來源,不同格式的文本中抽取出來。
命名實體識別的方法基本可分為三類:
- 基于規則/字典識別
通過指定的字典或預先設定的正則表達式匹配文本中的實體,這一方法主要用于識別特定格式的數據,如版本號,CVE編號等。目前往往會將規則與其他方法一起使用進行實體識別工作。
- 基于統計識別
通過對不同詞性,不同特征的詞匯進行統計,計算特定實體在其位置上出現的概率和上下文轉換概率等。目前常用的方法有最大熵模型,隱式馬爾科夫(HMM),支持向量機(SVM)等。
- 基于深度學習識別
深度學習方法本質也可歸為統計識別的一種,實體識別本質上也可視為一個分類問題(即識別詞匯是否屬于特定的命名實體),故也可以使用圖像識別領域常用的神經網絡技術。通過使用人工標注了實體的文本對進行神經網絡進行訓練,即可獲得一個用于識別命名實體的深度學習模型。目前常見的模型有CNN-CRF,RNN-CRF等。

上圖為一個demo,可見一個訓練過的神經網絡,可以從漏洞描述信息中識別出漏洞類型(VULN),產品名稱(PRODUCT),產品版本(VERSION),漏洞危害(CAPIBILITY),漏洞處發點(SINK),payload(PAYLOAD)等,從而將文本轉化為一份可機讀的數據。這一技術也是試圖通過NLP進行信息收集和數據分析的關鍵所在,高水平的命名實體識別可以對自動化威脅情報分析和威脅建模有很大幫助。
結語
NLP領域還有多個技術概念,如詞性標注,詞干分析,文本情感判定等,由于此類技術在安全領域應用有限,受限于篇幅,本文不做更多介紹,可以根據自身需求做更多了解。
 本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1256/
本文由 Seebug Paper 發布,如需轉載請注明來源。本文地址:http://www.bjnorthway.com/1256/