{kind=link}
![[I support RFC 3023 t-shirt]](http://feedparser.org/img/feedparser.jpg)
您在這里: 主頁 ‣ 深入Python 3 ‣
難度等級: ♦♦♦♦♢
❝ A ruffled mind makes a restless pillow. ❞
— Charlotte Brontë
簡單地講,HTTP web 服務是指以編程的方式直接使用 HTTP 操作從遠程服務器發送和接收數據。如果你要從服務器獲取數據,使用HTTP GET;如果你要向服務器發送新數據,使用HTTP POST. 一些更高級的HTTP Web 服務 API也允許使用HTTP PUT 和 HTTP DELETE來創建、修改和刪除數據。 換句話說,HTTP 協議中的“verbs (動作)” (GET, POST, PUT 和 DELETE) 可以直接對應到應用層的操作:獲取,創建,修改,刪除數據。
這個方法主要的優點是簡單, 它的簡單證明是受歡迎的。數據 — 通常是XML或JSON — 可以事先創建好并靜態的存儲下來 ,或者由服務器端腳本動態生成, 并且所有主要的編程語言(當然包括 Python)都包含HTTP 庫用于下載數據。調試也很方便; 由于HTTP web 服務中每一個資源都有一個唯一的地址(以URL的形式存在), 你可以在瀏覽器中加載它并且立即看到原始的數據.
HTTP web 服務示例:
Python 3 帶有兩個庫用于和HTTP web 服務交互:
http.client 是實現了RFC 2616, HTTP 協議的底層庫.
urllib.request 建立在http.client之上一個抽象層。 它為訪問HTTP 和 FTP 服務器提供了一個標準的API,可以自動跟隨HTTP 重定向, 并且處理了一些常見形式的HTTP 認證。
那么,你應該用哪個呢?兩個都不用。取而代之, 你應該使用 httplib2,一個第三方的開源庫,它比http.client更完整的實現了HTTP協議,同時比urllib.request提供了更好的抽象。
要理解為什么httplib2是正確的選擇,你必須先了解HTTP。
⁂
有五個重要的特性所有的HTTP客戶端都應該支持。
關于web服務最需要了解的一點是網絡訪問是極端昂貴的。我并不是指“美元”和“美分”的昂貴(雖然帶寬確實不是免費的)。我的意思是需要一個非常長的時間來打開一個連接,發送請求,并從遠程服務器響應。 即使在最快的寬帶連接上,延遲(從發送一個請求到開始在響應中獲得數據所花費的時間)仍然高于您的預期。路由器的行為不端,被丟棄的數據包,中間代理服務器被攻擊 — 在公共互聯網上沒有沉悶的時刻(never a dull moment),并且你對此無能為力。
HTTP在設計時就考慮到了緩存。有這樣一類的設備(叫做 “緩存代理服務器”) ,它們的唯一的任務是就是呆在你和世界的其他部分之間來最小化網絡請求。你的公司或ISP 幾乎肯定維護著這樣的緩存代理服務器, 只不過你沒有意識到而已。 它們的能夠起到作用是因為緩存是內建在HTTP協議中的。
這里有一個緩存如何工作的具體例子。 你通過瀏覽器訪問diveintomark.org。該網頁包含一個背景圖片, wearehugh.com/m.jpg。當你的瀏覽器下載那張圖片時,服務器的返回包含了下面的HTTP 頭:
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpegCache-Control 和 Expires 頭告訴瀏覽器(以及任何處于你和服務器之間的緩存代理服務器) 這張圖片可以緩存長達一年。 一年! 如果在明年,你訪問另外一個也包含這張圖片的頁面,你的瀏覽器會從緩存中加載這樣圖片而不會產生任何網絡活動.
等一下,情況實際上更好。比方說,你的瀏覽器由于某些原因將圖片從本地緩存中移除了。可能是因為沒有磁盤空間了或者是你清空了緩存,不管是什么理由。然而HTTP 頭告訴說這個數據可以被公共緩存代理服務器緩存(Cache-Control頭中public關鍵字說明這一點)。緩存代理服務器有非常龐大的存儲空間,很可能比你本地瀏覽器所分配的大的多。
如果你的公司或者ISP維護著這樣一個緩存代理服務器,它很可能仍然有這張圖片的緩存。 當你再次訪問diveintomark.org 時, 你的瀏覽器會在本地緩存中查找這張圖片, 它沒有找到, 所以它發出一個網絡請求試圖從遠程服務器下載這張圖片。但是由于緩存代理服務器仍然有這張圖片的一個副本,它將截取這個請求并從它的緩存中返回這張圖片。 這意味這你的請求不會到達遠程服務器; 實際上, 它根本沒有離開你公司的網絡。這意味著更快的下載(網絡躍點變少了) 和節省你公司的花費(從外部下載的數據變少了)。
只有當每一個角色都做按協議來做時,HTTP緩存才能發揮作用。一方面,服務器需要在響應中發送正確的頭。另一方面,客戶端需要在第二次請求同樣的數據前理解并尊重這些響應頭。 代理服務器不是靈丹妙藥,它們只會在客戶端和服務器允許的情況下盡可能的聰明。
Python的HTTP庫不支持緩存,而httplib2支持。
有一些數據從不改變,而另外一些則總是在變化。介于兩者之間,在很多情況下數據還沒變化但是將來可能會變化。 CNN.com 的供稿每隔幾分鐘就會更新,但我的博客的供稿可能幾天或者幾星期才會更新一次。在后面一種情況的時候,我不希望告訴客戶端緩存我的供稿幾星期,因為當我真的發表了點東西的時候,人們可能會幾個星期后才能閱讀到(由于他們遵循我的cache 頭—"幾個星期內都不用檢查這個供稿")。另一方面,如果供稿沒有改變我也不希望客戶端每隔1小時就來檢查一下!
HTTP 對于這個問題也有一個解決方案。當你第一次請求數據時,服務器返回一個Last-Modified頭。 顧名思義:數據最后修改的時間。diveintomark.org引用的這張背景圖片包含一個Last-Modified頭。
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
如果第二(第三,第四)次請求同樣一個資源,你可以在你的請求中發送一個If-Modified-Since頭,其值為你上次從服務器返回的時間。如果從那時開始,數據已經發成過變化,服務器會忽略If-Modified-Since頭并返回新數據和200狀態碼給你。否則的話,服務器將發回一個特殊的HTTP 304 狀態碼, 它的含義是“從上次請求到現在數據沒有發生過變化.” 你可以在命令行上使用curl來測試:
you@localhost:~$ curl -I -H "If-Modified-Since: Fri, 22 Aug 2008 04:28:16 GMT" http://wearehugh.com/m.jpg HTTP/1.1 304 Not Modified Date: Sun, 31 May 2009 18:04:39 GMT Server: Apache Connection: close ETag: "3075-ddc8d800" Expires: Mon, 31 May 2010 18:04:39 GMT Cache-Control: max-age=31536000, public
為什么這是一個進步?因為服務器發送304時, 它沒有重新發送數據。你得到的僅僅是狀態碼。即使你的緩存副本已經過期,最后修改時間檢查保證你不會在數據沒有變化的情況下重新下載它。 (額外的好處是,這個304 響應同樣也包含了緩存頭。代理服務器會在數據已經“過期”的情況下仍然保留數據的副本; 希望數據實際上還沒有改變,并且下一個請求以304狀態碼返回,并更新緩存信息。)
Python的HTTP 庫不支持最后修改時間檢查,而httplib2 支持。
ETag 是另一個和最后修改時間檢查達到同樣目的的方法。使用ETag時,服務器在返回數據的同時在ETag頭里返回一個哈希碼(如何生成哈希碼完全取決于服務器,唯一的要求是數據改變時哈希碼也要改變) diveintomark.org引用的背景圖片包含有ETag 頭.
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
當你再次請求同樣的數據時,你在If-None-Match頭里放入ETag值。如果數據沒有發生改變,服務器將會返回304狀態碼。同最后修改時間檢查一樣,服務器發回的只有304 狀態碼,不會再一次給你發送同樣的數據。通過在請求中包含ETag 哈希碼,你告訴服務器如果哈希值匹配就不需要重新發送同樣的數據了,因為你仍然保留著上次收到的數據.
再一次使用curl:
you@localhost:~$ curl -I -H "If-None-Match: \"3075-ddc8d800\"" http://wearehugh.com/m.jpg ①
HTTP/1.1 304 Not Modified
Date: Sun, 31 May 2009 18:04:39 GMT
Server: Apache
Connection: close
ETag: "3075-ddc8d800"
Expires: Mon, 31 May 2010 18:04:39 GMT
Cache-Control: max-age=31536000, public
ETag頭里面唯一的分隔符是ETag 和 "3075-ddc8d800"之間的冒號。這意味著你也需要將引號放在If-None-Match頭發回給服務器。
Python HTTP庫不支持ETag,而httplib2支持.
當我們談論HTTP web 服務的時候, 你總是會討論到在線路上來回運送文本數據。可能是XML,也可能是JSON,抑或僅僅是純文本。不管是什么格式,文本的壓縮性能很好。XML 章節中的示例供稿在沒壓縮的情況下是3070 字節,然而在gzip 壓縮后只有941 字節。僅僅是原始大小的30%!
HTTP支持若干種壓縮算法。最常見的兩種是gzip 和 deflate。當你通過HTTP請求資源時,你可以要求服務器以壓縮格式返回資源。你在請求中包含一個Accept-encoding頭,里面列出了你支持的壓縮算法。如果服務器也支持其中的某一種算法,它就會返回給你壓縮后的數據(同時通過Content-encoding頭標識它使用的算法)。接下來的事情就是由你去解壓數據了。
Python的 HTTP庫不支持壓縮,但httplib2支持。
好的 URI不會變化,但是有很多URI并沒有那么好。網站可能會重新組織,頁面移動到新位置。即使是web 服務也可能重新安排。一個聯合供稿http://example.com/index.xml 可能會移動到http://example.com/xml/atom.xml。或者當一個機構擴張和重組的時候,整個域名都可能移動; http://www.example.com/index.xml 變成 http://server-farm-1.example.com/index.xml.
每一次你向HTTP服務器請求資源的時候, 服務器都會在響應中包含一個狀態碼。 狀態碼200的意思是一切正常,這就是你請求的頁面; 狀態碼404的意思是找不到頁面; (你很可能在瀏覽網頁的時候碰到過404)。300 系列的狀態碼意味著某種形式的重定向。
HTTP 有多種方法表示一個資源已經被移動。最常見兩個技術是狀態碼302 和 301。 狀態碼 302 是一個 臨時重定向; 它意味著, 資源被被臨時從這里移動走了; (并且臨時地址在Location 頭里面給出)。狀態碼301是永久重定向; 它意味著,資源被永久的移動了; (并且在Location頭里面給出了新的地址)。如果你得到302狀態碼和一個新地址, HTTP規范要求你訪問新地址來獲得你要的資源,但是下次你要訪問同樣的資源的時候你應該重新嘗試舊的地址。但是如果你得到301狀態碼和新地址, 你從今以后都應該使用新的地址。
urllib.request模塊在從HTTP服務器收到對應的狀態碼的時候會自動“跟隨”重定向, 但它不會告訴你它這么干了。你最后得到了你請求的數據,但是你永遠也不會知道下層的庫友好的幫助你跟隨了重定向。結果是,你繼續訪問舊的地址,每一次你都會得到新地址的重定向,每一次urllib.request模塊都會友好的幫你跟隨重定向。換句話說,它將永久重定向當成臨時重定向來處理。這意味著兩個來回而不是一個,這對你和服務器都不好。
httplib2 幫你處理了永久重定向。它不僅會告訴你發生了永久重定向,而且它會在本地記錄這些重定向,并且在發送請求前自動重寫為重定向后的URL。
⁂
我們來舉個例子,你想要通過HTTP下載一個資源, 比如說一個Atom 供稿。作為一個供稿, 你不會只下載一次,你會一次又一次的下載它。 (大部分的供稿閱讀器會美一小時檢查一次更新。) 讓我們先用最粗糙和最快的方法來實現它,接著再來看看怎樣改進。
>>> import urllib.request >>> a_url = 'http://diveintopython3.org/examples/feed.xml' >>> data = urllib.request.urlopen(a_url).read() ① >>> type(data) ② <class 'bytes'> >>> print(data) <?xml version='1.0' encoding='utf-8'?> <feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'> <title>dive into mark</title> <subtitle>currently between addictions</subtitle> <id>tag:diveintomark.org,2001-07-29:/</id> <updated>2009-03-27T21:56:07Z</updated> <link rel='alternate' type='text/html' /> …
urllib.request模塊有一個方便的函數urlopen() ,它接受你所要獲取的頁面地址,然后返回一個類文件對象,您只要調用它的read()方法就可以獲得網頁的全部內容。沒有比這更簡單的了。
urlopen().read()方法總是返回bytes對象,而不是字符串。記住字節僅僅是字節,字符只是一種抽象。 HTTP 服務器不關心抽象的東西。如果你請求一個資源,你得到字節。 如果你需要一個字符串,你需要確定字符編碼,并顯式的將其轉化成字符串。
那么,有什么問題呢?作為開發或測試中的快速試驗,沒有什么不妥的地方。我總是這么干。我需要供稿的內容,然后我拿到了它。相同的技術對任何網頁都有效。但一旦你考慮到你需要定期訪問Web服務的時候,(例如 每隔1小時請求一下這個供稿), 這樣的做法就顯得很低效和粗暴了。
⁂
為了說明為什么這是低效和粗暴的,我們來打開Python的HTTP庫的調試功能,看看什么東西被發送到了線路上(即網絡上).
>>> from http.client import HTTPConnection >>> HTTPConnection.debuglevel = 1 ① >>> from urllib.request import urlopen >>> response = urlopen('http://diveintopython3.org/examples/feed.xml') ② send: b'GET /examples/feed.xml HTTP/1.1 ③ Host: diveintopython3.org ④ Accept-Encoding: identity ⑤ User-Agent: Python-urllib/3.1' ⑥ Connection: close reply: 'HTTP/1.1 200 OK' …further debugging information omitted…
urllib.request 依賴另一個標準Python庫, http.client。正常情況下你不需要直接接觸http.client。 (urllib.request 模塊會自動導入它。) 我們在這里導入它是為了讓我們能夠打開HTTPConnection類的調試開關,urllib.request 使用這個類去連接HTTP服務器。
urllib.request模塊向服務器發送了5行數據。
urllib.request 默認不支持壓縮。
Python-urllib加上版本號。urllib.request和httplib2都支持更改用戶代理, 直接向請求里面加一個User-Agent頭就可以了(默認值會被覆蓋).
現在讓我們來看看服務器返回了什么。
# continued from previous example >>> print(response.headers.as_string()) ① Date: Sun, 31 May 2009 19:23:06 GMT ② Server: Apache Last-Modified: Sun, 31 May 2009 06:39:55 GMT ③ ETag: "bfe-93d9c4c0" ④ Accept-Ranges: bytes Content-Length: 3070 ⑤ Cache-Control: max-age=86400 ⑥ Expires: Mon, 01 Jun 2009 19:23:06 GMT Vary: Accept-Encoding Connection: close Content-Type: application/xml >>> data = response.read() ⑦ >>> len(data) 3070
urllib.request.urlopen()函數返回的response對象包含了服務器返回的所有HTTP頭。它也提供了下載實際數據的方法,這個我們等一下講。
Last-Modified頭。
ETag頭。
Content-encoding頭。你的請求表示你只接受未壓縮的數據,(Accept-encoding: identity), 然后當然,響應確實包含未壓縮的數據。
response.read()下載實際的數據. 你從len()函數可以看出,一下子就把整個3070個字節下載下來了。
正如你所看見的,這個代碼已經是低效的了;它請求(并接收)了未壓縮的數據。我知道服務器實際上是支持gzip 壓縮的, 但HTTP 壓縮是一個可選項。我們不主動要求,服務器不會執行。這意味這在可以只下載941字節的情況下我們下載了3070個字節。Bad dog, no biscuit.
別急,還有更糟糕的。為了說明這段代碼有多么的低效,讓我再次請求一下同一個供稿。
# continued from the previous example
>>> response2 = urlopen('http://diveintopython3.org/examples/feed.xml')
send: b'GET /examples/feed.xml HTTP/1.1
Host: diveintopython3.org
Accept-Encoding: identity
User-Agent: Python-urllib/3.1'
Connection: close
reply: 'HTTP/1.1 200 OK'
…further debugging information omitted…
注意到這個請求有什么特別之處嗎?它沒有變化。它同第一個請求完全一樣。沒有If-Modified-Since頭. 沒有If-None-Match頭. 沒有尊重緩存頭,也仍然沒有壓縮。
然后,當你發送同樣的請求的時候會發生什么呢?你又一次得到同樣的響應。
# continued from the previous example >>> print(response2.headers.as_string()) ① Date: Mon, 01 Jun 2009 03:58:00 GMT Server: Apache Last-Modified: Sun, 31 May 2009 22:51:11 GMT ETag: "bfe-255ef5c0" Accept-Ranges: bytes Content-Length: 3070 Cache-Control: max-age=86400 Expires: Tue, 02 Jun 2009 03:58:00 GMT Vary: Accept-Encoding Connection: close Content-Type: application/xml >>> data2 = response2.read() >>> len(data2) ② 3070 >>> data2 == data ③ True
Cache-Control 和 Expires 用于允許緩存, Last-Modified 和 ETag用于“是否變化”的跟蹤。甚至是Vary: Accept-Encoding頭暗示只要你請求,服務器就能支持壓縮。但是你沒有。
HTTP 設計的能比這樣工作的更好。 urllib使用HTTP就像我說西班牙語一樣 — 可以表達基本的意思,但是不足以保持一個對話。HTTP 是一個對話。是時候更新到一個可以流利的講HTTP的庫了。
⁂
httplib2在你使用httplib2前, 你需要先安裝它。 訪問code.google.com/p/httplib2/ 并下載最新版本。httplib2對于Python 2.x 和 Python 3.x都有對應的版本; 請確保你下載的是Python 3 的版本, 名字類似httplib2-python3-0.5.0.zip。
解壓該檔案,打開一個終端窗口, 然后切換到剛生成的httplib2目錄。在Windows 上,請打開開始菜單, 選擇運行, 輸入cmd.exe 最后按回車(ENTER).
c:\Users\pilgrim\Downloads> dir
Volume in drive C has no label.
Volume Serial Number is DED5-B4F8
Directory of c:\Users\pilgrim\Downloads
07/28/2009 12:36 PM <DIR> .
07/28/2009 12:36 PM <DIR> ..
07/28/2009 12:36 PM <DIR> httplib2-python3-0.5.0
07/28/2009 12:33 PM 18,997 httplib2-python3-0.5.0.zip
1 File(s) 18,997 bytes
3 Dir(s) 61,496,684,544 bytes free
c:\Users\pilgrim\Downloads> cd httplib2-python3-0.5.0
c:\Users\pilgrim\Downloads\httplib2-python3-0.5.0> c:\python31\python.exe setup.py install
running install
running build
running build_py
running install_lib
creating c:\python31\Lib\site-packages\httplib2
copying build\lib\httplib2\iri2uri.py -> c:\python31\Lib\site-packages\httplib2
copying build\lib\httplib2\__init__.py -> c:\python31\Lib\site-packages\httplib2
byte-compiling c:\python31\Lib\site-packages\httplib2\iri2uri.py to iri2uri.pyc
byte-compiling c:\python31\Lib\site-packages\httplib2\__init__.py to __init__.pyc
running install_egg_info
Writing c:\python31\Lib\site-packages\httplib2-python3_0.5.0-py3.1.egg-info
在Mac OS X上, 運行位于/Applications/Utilities/目錄下的Terminal.app程序。在Linux上,運行終端(Terminal)程序, 該程序一般位于你的應用程序菜單,在Accessories 或者 系統(System)下面。
you@localhost:~/Desktop$ unzip httplib2-python3-0.5.0.zip Archive: httplib2-python3-0.5.0.zip inflating: httplib2-python3-0.5.0/README inflating: httplib2-python3-0.5.0/setup.py inflating: httplib2-python3-0.5.0/PKG-INFO inflating: httplib2-python3-0.5.0/httplib2/__init__.py inflating: httplib2-python3-0.5.0/httplib2/iri2uri.py you@localhost:~/Desktop$ cd httplib2-python3-0.5.0/ you@localhost:~/Desktop/httplib2-python3-0.5.0$ sudo python3 setup.py install running install running build running build_py creating build creating build/lib.linux-x86_64-3.1 creating build/lib.linux-x86_64-3.1/httplib2 copying httplib2/iri2uri.py -> build/lib.linux-x86_64-3.1/httplib2 copying httplib2/__init__.py -> build/lib.linux-x86_64-3.1/httplib2 running install_lib creating /usr/local/lib/python3.1/dist-packages/httplib2 copying build/lib.linux-x86_64-3.1/httplib2/iri2uri.py -> /usr/local/lib/python3.1/dist-packages/httplib2 copying build/lib.linux-x86_64-3.1/httplib2/__init__.py -> /usr/local/lib/python3.1/dist-packages/httplib2 byte-compiling /usr/local/lib/python3.1/dist-packages/httplib2/iri2uri.py to iri2uri.pyc byte-compiling /usr/local/lib/python3.1/dist-packages/httplib2/__init__.py to __init__.pyc running install_egg_info Writing /usr/local/lib/python3.1/dist-packages/httplib2-python3_0.5.0.egg-info
要使用httplib2, 請創建一個httplib2.Http 類的實例。
>>> import httplib2
>>> h = httplib2.Http('.cache') ①
>>> response, content = h.request('http://diveintopython3.org/examples/feed.xml') ②
>>> response.status ③
200
>>> content[:52] ④
b"<?xml version='1.0' encoding='utf-8'?>\r\n<feed xmlns="
>>> len(content)
3070
httplib2的主要接口是Http對象。你創建Http對象時總是應該傳入一個目錄名,具體原因你會在下一節看見。目錄不需要事先存在,httplib2會在必要的時候創建它。
Http對象, 獲取數據非常簡單,以你要的數據的地址作為參數調用request()方法就可以了。這會對該URL執行一個HTTP GET請求. (這一章下面你會看見怎樣執行其他HTTP 請求, 比如 POST。)
request() 方法返回兩個值。第一個是一個httplib2.Response對象,其中包含了服務器返回的所有HTTP頭。比如, status為200 表示請求成功。
bytes對象返回,不是字符串。 如果你需要一個字符串,你需要確定字符編碼并自己進行轉換。
☞你很可能只需要一個
httplib2.Http對象。當然存在足夠的理由來創建多個,但是只有當你清楚創建多個的原因的時候才應該這樣做。從不同的URL獲取數據不是一個充分的理由,重用Http對象并調用request()方法兩次就可以了。
httplib2返回字節串而不是字符串的簡短解釋字節串。字符串。真麻煩啊。為什么httplib2不能替你把轉換做了呢?由于決定字符編碼的規則依賴于你請求的資源的類型,導致自動轉化很復雜。httplib2怎么知道你要請求的資源的類型呢?通常類型會在Content-Type HTTP 頭里面列出,但是這是HTTP的可選特性,并且并非所有的HTTP服務器都支持。如果HTTP響應沒有包含這個頭,那就留給客戶端去猜了。(這通常被稱為“內容嗅探(content sniffing)” ,但它從來就不是完美的。)
如果你知道你期待的資源是什么類型的(這個例子中是XML文檔), 也許你應該直接將返回的字節串(bytes)對象傳給xml.etree.ElementTree.parse() 函數。只要(像這個文檔一樣)XML 文檔自己包含字符編碼信息,這是可以工作的。但是字符編碼信息是一個可選特性并非所有XML文檔包含這樣的信息。如果一個XML文檔不包含編碼信息,客戶端應該去查看Content-Type HTTP 頭, 里面應該包含一個charset參數。
但問題更糟糕。現在字符編碼信息可能在兩個地方:在XML文檔自己內部,在Content-Type HTTP 頭里面。如果信息在兩個地方都出現了,哪個優先呢?根據RFC 3023 (我發誓,這不是我編的), 如果在Content-Type HTTP頭里面給出的媒體類型(media type)是application/xml, application/xml-dtd, application/xml-external-parsed-entity, 或者是任何application/xml的子類型,比如application/atom+xml 或者 application/rss+xml 亦或是 application/rdf+xml, 那么編碼是
Content-Type HTTP頭的charset參數給出的編碼, 或者
encoding屬性給出的編碼, 或者
相反,如果在Content-Type HTTP頭里面給出的媒體類型(media type)是text/xml, text/xml-external-parsed-entity, 或者任何text/AnythingAtAll+xml這樣的子類型, 那么文檔內的XML聲明的encoding屬性完全被忽略,編碼是
Content-Type HTTP頭的charset參數給出的編碼, 或者
us-ascii
而且這還只是針對XML文檔的規則。對于HTML文檔,網頁瀏覽器創造了用于內容嗅探的復雜規則(byzantine rules for content-sniffing) [PDF], 我們正試圖搞清楚它們。.
“歡迎提交補丁.”
httplib2怎樣處理緩存。還記的在前一節我說過你總是應該在創建httplib2.Http對象是提供一個目錄名嗎? 緩存就是這樣做的目的。
# continued from the previous example
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed.xml') ①
>>> response2.status ②
200
>>> content2[:52] ③
b"<?xml version='1.0' encoding='utf-8'?>\r\n<feed xmlns="
>>> len(content2)
3070
狀態(status)碼同上次一樣還是200。
誰關心這些東西啊?退出你的Python交互shell 然后打開一個新的會話,我來給你演示。
# NOT continued from previous example! # Please exit out of the interactive shell # and launch a new one. >>> import httplib2 >>> httplib2.debuglevel = 1 ① >>> h = httplib2.Http('.cache') ② >>> response, content = h.request('http://diveintopython3.org/examples/feed.xml') ③ >>> len(content) ④ 3070 >>> response.status ⑤ 200 >>> response.fromcache ⑥ True
httplib2打開http.client調試開關的方法. httplib2會打印出發給服務器的所有數據以及一些返回的關鍵信息。
httplib2.Http對象。
httplib2的本地緩存構造出來的。你創建httplib2.Http對象是傳入的目錄里面保存了所有httplib2執行過的操作的緩存。
☞如果你想要打開
httplib2的調試開關,你需要設置一個模塊級的常量(httplib2.debuglevel), 然后再創建httplib2.Http對象。如果你希望關閉調試,你需要改變同一個模塊級常量, 接著創建一個新的httplib2.Http對象。
你剛剛請求過這個URL的數據。那個請求是成功的(狀態碼: 200)。該響應不僅包含feed數據,也包含一系列緩存頭,告訴那些關注著的人這個資源可以緩存長達24小時(Cache-Control: max-age=86400, 24小時所對應的秒數)。 httplib2 理解并尊重那些緩存頭,并且它會在.cache目錄(你在創建Http對象時提供的)保存之前的響應。緩存還沒有過期,所以你第二次請求該URL的數據時, httplib2不會去訪問網絡,直接返回緩存著的數據。
我說的很簡單,但是很顯然在這簡單后面隱藏了很多復雜的東西。httplib2會自動處理HTTP緩存,并且這是默認的行為. 如果由于某些原因你需要知道響應是否來自緩存,你可以檢查 response.fromcache. 否則的話,它工作的很好。
現在,假設你有數據緩存著,但是你希望跳過緩存并且重新請求遠程服務器。瀏覽器有時候會應用戶的要求這么做。比如說,按F5刷新當前頁面,但是按Ctrl+F5會跳過緩存并向遠程服務器重新請求當前頁面。你可能會想“嗯,我只要從本地緩存刪除數據,然后再次請求就可以了。” 你可以這么干,但是請記住, 不只是你和遠程服務器會牽扯其中。那些中繼代理服務器呢? 它們完全不受你的控制,并且它們可能還有那份數據的緩存,然后很高興的將其返回給你, 因為(對它們來說)緩存仍然是有效的。
你應該使用HTTP的特性來保證你的請求最終到達遠程服務器,而不是修改本地緩存然后聽天由命。
# continued from the previous example
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed.xml',
... headers={'cache-control':'no-cache'}) ①
connect: (diveintopython3.org, 80) ②
send: b'GET /examples/feed.xml HTTP/1.1
Host: diveintopython3.org
user-agent: Python-httplib2/$Rev: 259 $
accept-encoding: deflate, gzip
cache-control: no-cache'
reply: 'HTTP/1.1 200 OK'
…further debugging information omitted…
>>> response2.status
200
>>> response2.fromcache ③
False
>>> print(dict(response2.items())) ④
{'status': '200',
'content-length': '3070',
'content-location': 'http://diveintopython3.org/examples/feed.xml',
'accept-ranges': 'bytes',
'expires': 'Wed, 03 Jun 2009 00:40:26 GMT',
'vary': 'Accept-Encoding',
'server': 'Apache',
'last-modified': 'Sun, 31 May 2009 22:51:11 GMT',
'connection': 'close',
'-content-encoding': 'gzip',
'etag': '"bfe-255ef5c0"',
'cache-control': 'max-age=86400',
'date': 'Tue, 02 Jun 2009 00:40:26 GMT',
'content-type': 'application/xml'}
httplib2 允許你添加任意的HTTP頭部到發出的請求里。為了跳過所有緩存(不僅僅是你本地的磁盤緩存,也包括任何處于你和遠程服務器之間的緩存代理服務器), 在headers字典里面加入no-cache頭就可以了。
httplib2初始化了一個網絡請求。httplib2 理解并尊重兩個方向的緩存頭, — 作為接受的響應的一部分以及作為發出的請求的一部分. 它注意到你加入了一個no-cache頭,所以它完全跳過了本地的緩存,然后不得不去訪問網絡來請求數據。
httplib2會使用它來更新它的本地緩存,希望你下次請求該供稿時能夠避免網絡請求。HTTP緩存被設計為盡量最大化緩存命中率和最小化網絡訪問。即使你這一次跳過了緩存,服務器仍非常樂意你能緩存結果以備下一次請求
httplib2怎么處理Last-Modified和ETag頭Cache-Control和Expires 緩存頭 被稱為新鮮度指標(freshness indicators)。他們毫不含糊告訴緩存,你可以完全避免所有網絡訪問,直到緩存過期。而這正是你在前一節所看到的: 給出一個新鮮度指標, httplib2 不會產生哪怕是一個字節的網絡活動 就可以提供緩存了的數據(當然除非你顯式的要求跳過緩存).
那如果數據可能已經改變了, 但實際沒有呢? HTTP 為這種目的定義了Last-Modified和Etag頭。 這些頭被稱為驗證器(validators)。如果本地緩存已經不是新鮮的,客戶端可以在下一個請求的時候發送驗證器來檢查數據實際上有沒有改變。如果數據沒有改變,服務器返回304狀態碼,但不返回數據。 所以雖然還會在網絡上有一個來回,但是你最終可以少下載一點字節。
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> response, content = h.request('http://diveintopython3.org/') ①
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
>>> print(dict(response.items())) ②
{'-content-encoding': 'gzip',
'accept-ranges': 'bytes',
'connection': 'close',
'content-length': '6657',
'content-location': 'http://diveintopython3.org/',
'content-type': 'text/html',
'date': 'Tue, 02 Jun 2009 03:26:54 GMT',
'etag': '"7f806d-1a01-9fb97900"',
'last-modified': 'Tue, 02 Jun 2009 02:51:48 GMT',
'server': 'Apache',
'status': '200',
'vary': 'Accept-Encoding,User-Agent'}
>>> len(content) ③
6657
httplib2沒什么能做的,它在請求中發出最少量的頭。
ETag 和 Last-Modified頭。
# continued from the previous example
>>> response, content = h.request('http://diveintopython3.org/') ①
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
if-none-match: "7f806d-1a01-9fb97900" ②
if-modified-since: Tue, 02 Jun 2009 02:51:48 GMT ③
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 304 Not Modified' ④
>>> response.fromcache ⑤
True
>>> response.status ⑥
200
>>> response.dict['status'] ⑦
'304'
>>> len(content) ⑧
6657
Http對象(以及同一個本地緩存)。
httplib2 將ETag validator 通過If-None-Match頭發送回服務器。
httplib2 也將Last-Modified validator 通過If-Modified-Since頭發送回服務器。
304 狀態碼不帶數據.
httplib2 注意到304狀態碼并從它的緩存加載頁面的內容。
304 (服務器這次返回的, 導致httplib2查看它的緩存), 和 200 (服務器上次返回的, 并和頁面數據一起保存在httplib2的緩存里)。response.status返回緩存里的那個。
response.dict里面找到, 它是包含服務器返回的真實頭部的字典.
httplib2 足夠聰明,允許你傻瓜一點。) request()返回的時候, httplib2就已經更新了緩存并把數據返回給你了。
http2lib怎么處理壓縮HTTP支持兩種類型的壓縮。httplib2都支持。
>>> response, content = h.request('http://diveintopython3.org/')
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip ①
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
>>> print(dict(response.items()))
{'-content-encoding': 'gzip', ②
'accept-ranges': 'bytes',
'connection': 'close',
'content-length': '6657',
'content-location': 'http://diveintopython3.org/',
'content-type': 'text/html',
'date': 'Tue, 02 Jun 2009 03:26:54 GMT',
'etag': '"7f806d-1a01-9fb97900"',
'last-modified': 'Tue, 02 Jun 2009 02:51:48 GMT',
'server': 'Apache',
'status': '304',
'vary': 'Accept-Encoding,User-Agent'}
httplib2 發送請求,它包含了Accept-Encoding頭來告訴服務器它能夠處理deflate 或者 gzip壓縮。
request()方法返回的時候,httplib2就已經解壓縮了響應的體(body)并將其放在 content變量里。如果你想知道響應是否壓縮過, 你可以檢查response['-content-encoding']; 否則,不用擔心了.
httplib2怎樣處理重定向HTTP 定義了 兩種類型的重定向: 臨時的和永久的。對于臨時重定向,除了跟隨它們其他沒有什么特別要做的, httplib2 會自動處理跟隨。
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> response, content = h.request('http://diveintopython3.org/examples/feed-302.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-302.xml HTTP/1.1 ②
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 302 Found' ③
send: b'GET /examples/feed.xml HTTP/1.1 ④
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
302 Found。這里沒有顯示出來,這個響應也包含由一個Location頭給出實際的URL.
httplib2 馬上轉身并跟隨重定向,發出另一個到在Location頭里面給出的URL: http://diveintopython3.org/examples/feed.xml 的請求。
“跟隨” 一個重定向就是這個例子展示的那么多。httplib2 發送一個請求到你要求的URL。服務器返回一個響應說“不,不, 看那邊.” httplib2 給新的URL發送另一個請求.
# continued from the previous example >>> response ① {'status': '200', 'content-length': '3070', 'content-location': 'http://diveintopython3.org/examples/feed.xml', ② 'accept-ranges': 'bytes', 'expires': 'Thu, 04 Jun 2009 02:21:41 GMT', 'vary': 'Accept-Encoding', 'server': 'Apache', 'last-modified': 'Wed, 03 Jun 2009 02:20:15 GMT', 'connection': 'close', '-content-encoding': 'gzip', ③ 'etag': '"bfe-4cbbf5c0"', 'cache-control': 'max-age=86400', ④ 'date': 'Wed, 03 Jun 2009 02:21:41 GMT', 'content-type': 'application/xml'}
request()方法返回的response是最終URL的響應。
httplib2 會將最終的 URL以 content-location加入到 response字典中。這不是服務器返回的頭,它特定于httplib2。
你得到的response給了你最終 URL的相關信息。如果你希望那些最后重定向到最終URL的中間URL的信息呢?httplib2 也能幫你。
# continued from the previous example >>> response.previous ① {'status': '302', 'content-length': '228', 'content-location': 'http://diveintopython3.org/examples/feed-302.xml', 'expires': 'Thu, 04 Jun 2009 02:21:41 GMT', 'server': 'Apache', 'connection': 'close', 'location': 'http://diveintopython3.org/examples/feed.xml', 'cache-control': 'max-age=86400', 'date': 'Wed, 03 Jun 2009 02:21:41 GMT', 'content-type': 'text/html; charset=iso-8859-1'} >>> type(response) ② <class 'httplib2.Response'> >>> type(response.previous) <class 'httplib2.Response'> >>> response.previous.previous ③ >>>
httplib2跟隨那個響應獲得了當前的響應對象。
httplib2.Response 對象。
None.
如果我們再次請求同一個URL會發生什么?
# continued from the previous example
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed-302.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-302.xml HTTP/1.1 ②
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 302 Found' ③
>>> content2 == content ④
True
httplib2.Http 對象 (所以也是同一個緩存)。
302 響應沒有緩存,所以httplib2 對同一個 URL發送了另一個請求。
302響應。但是請注意什么沒有 發生: 沒有第二個到最終URL, http://diveintopython3.org/examples/feed.xml 的請求。原因是緩存 (還記的你在前一個例子中看到的Cache-Control頭嗎?)。 一旦 httplib2 收到302 Found 狀態碼, 它在發出新的請求前檢查它的緩存. 緩存中有http://diveintopython3.org/examples/feed.xml的一份新鮮副本, 所以不需要重新請求它了。
request()方法返回的時候,它已經從緩存中讀取了feed數據并返回了它。當然,它和你上次收到的數據是一樣的。
換句話說,對于臨時重定向你不需要做什么特別的處理。httplib2 會自動跟隨它們,而一個URL重定向到另一個這個事實上不會影響httplib2對壓縮,緩存, ETags, 或者任何其他HTTP特性的支持。
永久重定向同樣也很簡單。
# continued from the previous example
>>> response, content = h.request('http://diveintopython3.org/examples/feed-301.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-301.xml HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 301 Moved Permanently' ②
>>> response.fromcache ③
True
http://diveintopython3.org/examples/feed.xml.
301。 但是再次注意什么沒有發生: 沒有發送到重定向后的URL的請求。為什么沒有? 因為它已經在本地緩存了。
httplib2 “跟隨” 重定向到了它的緩存里面。
但是等等! 還有更多!
# continued from the previous example
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed-301.xml') ①
>>> response2.fromcache ②
True
>>> content2 == content ③
True
httplib2跟隨了一個永久重定向, 所有后續的對這個URL的請求會被透明的重寫到目標URL 而不會接觸網絡來訪問原始的URL。 記住, 調試還開著, 但沒有任何網絡活動的輸出。
HTTP. 它可以工作。
⁂
HTTP web 服務并不限于GET請求。當你要創建點東西的時候呢?當你在論壇上發表一個評論,更新你的博客,在Twitter 或者 Identi.ca這樣的微博客上面發表狀態消息的時候, 你很可能已經使用了HTTP POST.
Twitter 和 Identi.ca 都提供一個基于HTTP的簡單的API來發布并更新你狀態(不超過140個字符)。讓我們來看看Identi.ca的關于更新狀態的API文檔 :
Identi.ca 的REST API 方法: statuses/update
更新已認證用戶的狀態。需要下面格式的status參數。請求必須是POST.
- URL
https://identi.ca/api/statuses/update.format- Formats
xml,json,rss,atom- HTTP Method(s)
POST- Requires Authentication
- true
- Parameters
status. Required. The text of your status update. URL-encode as necessary.
怎么操作呢?要在Identi.ca 發布一條消息, 你需要提交一個HTTP POST請求到http://identi.ca/api/statuses/update.format. (format字樣不是URL的一部分; 你應該將其替換為你希望服務器返回的請求的格式。所以如果需要一個XML格式的返回。你應該向https://identi.ca/api/statuses/update.xml發送請求。) 請求需要一個參數status, 包含了你的狀態更新文本。并且請求必須是已授權的。
授權? 當然。要在Identi.ca上發布你的狀態更新, 你得證明你的身份。Identi.ca 不是一個維基; 只有你自己可以更新你的狀態。Identi.ca 使用建立在SSL之上的HTTP Basic Authentication (也就是RFC 2617) 來提供安全但方便的認證。httplib2 支持SSL 和 HTTP Basic Authentication, 所以這部分很簡單。
POST 請求同GET 請求不同, 因為它包含負荷(payload). 負荷是你要發送到服務器的數據。這個API方法必須的參數是status, 并且它應該是URL編碼過的。 這是一種很簡單的序列化格式,將一組鍵值對(比如字典)轉化為一個字符串。
>>> from urllib.parse import urlencode ① >>> data = {'status': 'Test update from Python 3'} ② >>> urlencode(data) ③ 'status=Test+update+from+Python+3'
urllib.parse.urlencode().
status, 對應值是狀態更新文本。
POST 請求中的負荷 .
>>> from urllib.parse import urlencode
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> data = {'status': 'Test update from Python 3'}
>>> h.add_credentials('diveintomark', 'MY_SECRET_PASSWORD', 'identi.ca') ①
>>> resp, content = h.request('https://identi.ca/api/statuses/update.xml',
... 'POST', ②
... urlencode(data), ③
... headers={'Content-Type': 'application/x-www-form-urlencoded'}) ④
httplib2處理認證的方法。 add_credentials()方法記錄你的用戶名和密碼。當httplib2 試圖執行請求的時候,服務器會返回一個401 Unauthorized狀態碼, 并且列出所有它支持的認證方法(在 WWW-Authenticate 頭中). httplib2會自動構造Authorization頭并且重新請求該URL.
POST.
☞
add_credentials()方法的第三個參數是該證書有效的域名。你應該總是指定這個參數! 如果你省略了這個參數,并且之后重用這個httplib2.Http對象訪問另一個需要認證的站點,可能會導致httplib2將一個站點的用戶名密碼泄漏給其他站點。
發送到線路上的數據:
# continued from the previous example send: b'POST /api/statuses/update.xml HTTP/1.1 Host: identi.ca Accept-Encoding: identity Content-Length: 32 content-type: application/x-www-form-urlencoded user-agent: Python-httplib2/$Rev: 259 $ status=Test+update+from+Python+3' reply: 'HTTP/1.1 401 Unauthorized' ① send: b'POST /api/statuses/update.xml HTTP/1.1 ② Host: identi.ca Accept-Encoding: identity Content-Length: 32 content-type: application/x-www-form-urlencoded authorization: Basic SECRET_HASH_CONSTRUCTED_BY_HTTPLIB2 ③ user-agent: Python-httplib2/$Rev: 259 $ status=Test+update+from+Python+3' reply: 'HTTP/1.1 200 OK' ④
401 Unauthorized狀態碼返回。httplib2從不主動發送認證頭,除非服務器明確的要求。這就是服務器要求認證頭的方法。
httplib2 馬上轉個身,第二次請求同樣的URL 。
add_credentials()方法加入的用戶名和密碼。
請求成功后服務器返回什么?這個完全由web 服務 API決定。 在一些協議里面(就像 Atom Publishing Protocol), 服務器會返回201 Created狀態碼,并通過Location提供新創建的資源的地址。Identi.ca 返回200 OK 和一個包含新創建資源信息的XML 文檔。
# continued from the previous example
>>> print(content.decode('utf-8')) ①
<?xml version="1.0" encoding="UTF-8"?>
<status>
<text>Test update from Python 3</text> ②
<truncated>false</truncated>
<created_at>Wed Jun 10 03:53:46 +0000 2009</created_at>
<in_reply_to_status_id></in_reply_to_status_id>
<source>api</source>
<id>5131472</id> ③
<in_reply_to_user_id></in_reply_to_user_id>
<in_reply_to_screen_name></in_reply_to_screen_name>
<favorited>false</favorited>
<user>
<id>3212</id>
<name>Mark Pilgrim</name>
<screen_name>diveintomark</screen_name>
<location>27502, US</location>
<description>tech writer, husband, father</description>
<profile_image_url>http://avatar.identi.ca/3212-48-20081216000626.png</profile_image_url>
<url>http://diveintomark.org/</url>
<protected>false</protected>
<followers_count>329</followers_count>
<profile_background_color></profile_background_color>
<profile_text_color></profile_text_color>
<profile_link_color></profile_link_color>
<profile_sidebar_fill_color></profile_sidebar_fill_color>
<profile_sidebar_border_color></profile_sidebar_border_color>
<friends_count>2</friends_count>
<created_at>Wed Jul 02 22:03:58 +0000 2008</created_at>
<favourites_count>30768</favourites_count>
<utc_offset>0</utc_offset>
<time_zone>UTC</time_zone>
<profile_background_image_url></profile_background_image_url>
<profile_background_tile>false</profile_background_tile>
<statuses_count>122</statuses_count>
<following>false</following>
<notifications>false</notifications>
</user>
</status>
httplib2返回的數據總是字節串(bytes), 不是字符串。為了將其轉化為字符串,你需要用合適的字符編碼進行解碼。Identi.ca的 API總是返回UTF-8編碼的結果, 所以這部分很簡單。
下面就是這條消息:
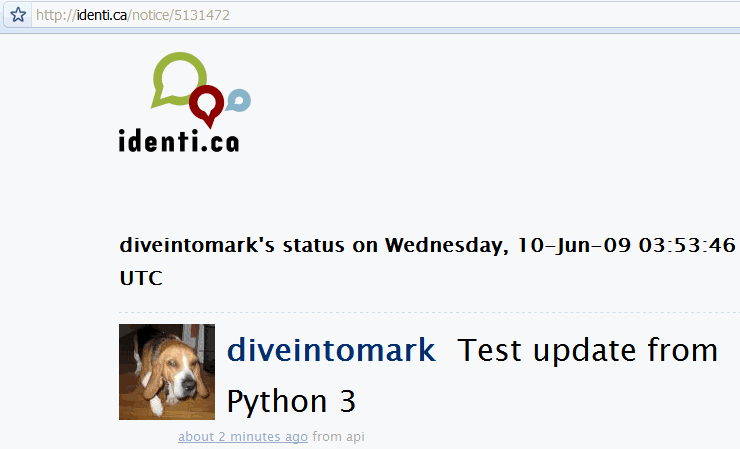
⁂
HTTP 并不只限于GET 和 POST。 它們當然是最常見的請求類型,特別是在web瀏覽器里面。 但是web服務API會使用GET和POST之外的東西, 對此httplib2也能處理。
# continued from the previous example >>> from xml.etree import ElementTree as etree >>> tree = etree.fromstring(content) ① >>> status_id = tree.findtext('id') ② >>> status_id '5131472' >>> url = 'https://identi.ca/api/statuses/destroy/{0}.xml'.format(status_id) ③ >>> resp, deleted_content = h.request(url, 'DELETE') ④
findtext()方法找到對應表達式的第一個實例并抽取出它的文本內容。在這個例子中,我們查找<id>元素.
<id>元素的文本內容,我們可以構造出一個URL用于刪除我們剛剛發布的狀態消息。
DELETE請求就可以了。
這就是發送到線路上的東西:
send: b'DELETE /api/statuses/destroy/5131472.xml HTTP/1.1 ① Host: identi.ca Accept-Encoding: identity user-agent: Python-httplib2/$Rev: 259 $ ' reply: 'HTTP/1.1 401 Unauthorized' ② send: b'DELETE /api/statuses/destroy/5131472.xml HTTP/1.1 ③ Host: identi.ca Accept-Encoding: identity authorization: Basic SECRET_HASH_CONSTRUCTED_BY_HTTPLIB2 ④ user-agent: Python-httplib2/$Rev: 259 $ ' reply: 'HTTP/1.1 200 OK' ⑤ >>> resp.status 200
證明確實是這樣的,它不見了。
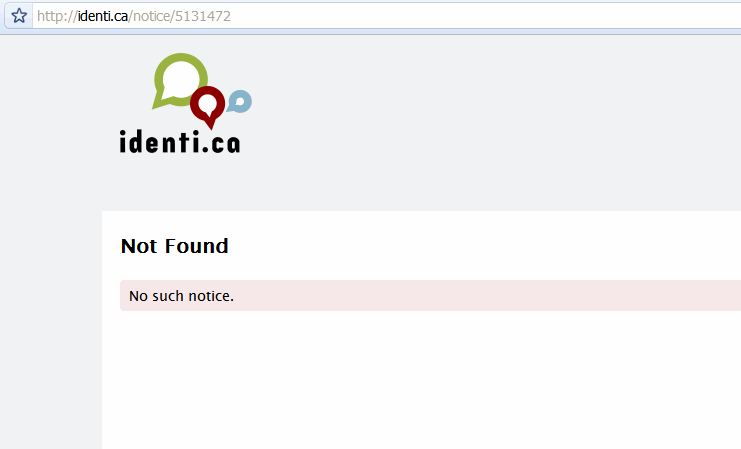
⁂
httplib2:
HTTP 緩存:
RFCs:
© 2001–9 Mark Pilgrim