Dialectizer 是 BaseHTMLProcessor 的簡單 (和拙劣) 的派生類。它通過一系列的替換對文本塊進行了處理,但是它確保在 <pre>...</pre> 塊之間的任何東西不被修改地通過。
為了處理 <pre> 塊,我們在 Dialectizer 中定義了兩個方法:start_pre 和 end_pre。
例 8.17. 處理特別標記
def start_pre(self, attrs): 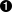 self.verbatim += 1
self.verbatim += 1 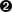 self.unknown_starttag("pre", attrs)
self.unknown_starttag("pre", attrs)  def end_pre(self):
def end_pre(self):  self.unknown_endtag("pre")
self.unknown_endtag("pre")  self.verbatim -= 1
self.verbatim -= 1 
| 每當 SGMLParser 在 HTML 源代碼中發現一個 <pre> 時,都會調用 start_pre。(馬上我們就會確切地看到它是如何發生的。) 這個方法使用單個參數:attrs,這個參數會包含標記的屬性 (如果存在的話) 。attrs 是一個鍵/值 tuple 的 list,就像 unknown_starttag 中所使用的。 | |
| 在 reset 方法中,我們初始化了一個數據屬性,它作為 <pre> 標記的一個計數器。每當我們找到一個 <pre> 標記,我們增加計數器的值;每當我們找到一個 </pre> 標記,我們將減少計數器的值。(我們本可以把它實現為一個標志,即或把它設為 1,或重置為 0,但這樣做只是為了方便,并且這樣做可以處理古怪 (但有可能) 的 <pre> 標記嵌套的情況。) 馬上我們將會看到這個計數器是多么的好用。 | |
| 不錯,這就是我們對 <pre> 標記所做的唯一的特殊處理。現在我們將屬性列表傳給 unknown_starttag,由它來進行缺省的處理。 | |
| 每當 SGMLParser 找到一個 </pre> 標記時,會調用 end_pre。因為結束標記不能包含屬性,因此這個方法沒有參數。 | |
| 首先我們要進行缺省處理,就像其它結束標記做的一樣。 | |
| 其次我們將計數器減少,標記這個 <pre> 塊已經被關閉了。 |
到了這個地方,有必要對 SGMLParser 更深入一層。我已經多次聲明 (到目前為止您應已經把它做為信條了) ,就是 SGMLParser 查找每一個標記并且如果存在特定的方法就調用它們。例如:我們剛剛看到處理 <pre> 和 </pre> 的 start_pre 和 end_pre 的定義。但這是如何發生的呢?嗯,也沒什么神奇的,只不過是出色的 Python 編碼。
例 8.18. SGMLParser
def finish_starttag(self, tag, attrs):
try:
method = getattr(self, 'start_' + tag)
except AttributeError:
try:
method = getattr(self, 'do_' + tag)
except AttributeError:
self.unknown_starttag(tag, attrs)
return -1
else:
self.handle_starttag(tag, method, attrs)
return 0
else:
self.stack.append(tag)
self.handle_starttag(tag, method, attrs)
return 1  def handle_starttag(self, tag, method, attrs):
method(attrs)
def handle_starttag(self, tag, method, attrs):
method(attrs) 
| 此處,SGMLParser 已經找到了一個開始標記,并且分析出屬性列表。唯一要做的事情就是檢查對于這個標記是否存在一個特別的處理方法,否則我們就應該求助于缺省方法 (unknown_starttag) 。 | |
| SGMLParser 的 “神奇” 之處除了我們的老朋友 getattr 之外就沒有什么了。您以前可能沒注意到,getattr 將查找定義在一個對象的繼承者中或對象自身的方法。這里對象是 self,即當前實例。所以,如果 tag 是 'pre',這里對 getattr 的調用將會在當前實例 (它是 Dialectizer 類的一個實例) 中查找一個名為 start_pre 的方法。 | |
| 如果 getattr 所查找的方法在對象或它的任何繼承者中不存在的話,它會引發一個 AttributeError 的異常。但沒有關系,因為我們把對 getattr 的調用包裝到一個 try...except 塊中了,并且顯式地捕捉 AttributeError 異常。 | |
| 因為我們沒有找到一個 start_xxx 方法,在放棄之前,我們將還要查找一個 do_xxx 方法。這個可替換的命名模式一般用于單獨的標記,如 <br>,這些標記沒有相應的結束標記。但是您可以使用任何一種模式,正如您看到的,SGMLParser 對每個標記嘗試兩次。(您不應該對相同的標記同時定義 start_xxx 和 do_xxx 處理方法,因為這樣的話只有 start_xxx 方法會被調用。) | |
| 另一個 AttributeError 異常,它是說用 do_xxx 來調用 getattr 失敗了。因為對同一個標記我們既沒有找到 start_xxx 也沒有找到 do_xxx 處理方法,這樣我們捕捉到了異常并且求助于缺省方法:unknown_starttag。 | |
| 記得嗎?try...except 塊可以有一個 else 子句,當在 try...except 塊中沒有異常被引發時,它將被調用。邏輯上,意味著我們確實 找到了這個標記的 do_xxx 方法,所以我們將要調用它。 | |
| 順便說,不要為這些不同的返回值而擔心;理論上他們有意義,但實際上它們沒有任何用處。也不要擔心 self.stack.append(tag) ; SGMLParser 內部會知曉您的開始標記是否有合適的結束標記與之匹配,但是它不會對這些信息做任何操作。理論上,您能使用這個模塊校驗您的標記是否完全匹配,但是這或許沒有多大價值,并且這樣的內容已經超出了本章所要討論的范疇。現在有您更需要擔心的問題。 | |
| start_xxx 和 do_xxx 方法并不被直接調用;標記名、方法和屬性被傳給 handle_starttag 這個方法,以便繼承者可以覆蓋它,并改變全部 開始標記分發的方式。我們不需要控制這個層面,所以我們只讓這個方法做它自已的事,就是用屬性 list 來調用方法 (start_xxx 或 do_xxx) 。記住 method 是一個從 getattr 返回的函數,而函數是對象。(我知道您已經聽膩了,我發誓,一旦我們停止尋找新的使用方法來為我們服務時,我就決不再提它了。) 這時,函數對象作為一個參數傳入這個分發方法,這個方法反過來再調用這個函數。在這里,我們不需要知道函數是什么,叫什么名字,或是在哪時定義的;我們只需要知道用一個參數 attrs 調用它。 |
現在回到我們已經計劃好的程序:Dialectizer。當我們跑題時,我們定義了特別的處理方法來處理 <pre> 和 </pre> 標記。還有一件事沒有做,那就是用我們預定義的替換處理來處理文本塊。為了實現它,我們需要覆蓋 handle_data 方法。
例 8.19. 覆蓋 handle_data 方法
def handle_data(self, text):
self.pieces.append(self.verbatim and text or self.process(text)) | handle_data 在調用時只使用一個參數:要處理的文本。 | |
| 在祖先類 BaseHTMLProcessor 中,handle_data 方法只是將文本追加到輸出緩沖區 self.pieces 之后。這里的邏輯稍微有點復雜。如果我們處于 <pre>...</pre> 塊的中間,self.verbatim 將是大于 0 的某個值,接著我們想要將文本不作改動地傳入輸出緩沖區。否則,我們將調用另一個單獨的方法來進行替換處理,然后將處理結果放入輸出緩沖區中。在 Python 中,這是一個一行代碼,它使用了and-or 技巧。 |
我們已經接近了對 Dialectizer 的全面理解。唯一缺少的一個環節是文本替換的特性。如果您知道點 Perl,您就會知道當需要復雜的文本替換時,唯一有效的解決方法就是正則表達式。在 dialect.py 文件后面的幾個類中定義了一連串的正則表達式來操作 HTML 標記中的文本。我們已經學習過了正則表達式中的所有字符。我們不必重復學習正則表達式的艱難歷程了,不是嗎?上帝知道我反正不需要。我想現在這章您已經學得差不多了。